
golang 基础笔记二
2022-04-01 08:40 天心PHP 阅读(153) 评论(0) 编辑 收藏 举报网络编程
网络编程有两种:
1) TCP socket 编程,是网络编程的主流。之所以叫 Tcp socket 编程,是因为底层是基于 Tcp/ip 协 议的.
比如: QQ 聊天 [示意图]
2) b/s 结构的 http 编程,我们使用浏览器去访问服务器时,使用的就是 http 协议,而 http 底层依 旧是用 tcp socket 实现的。比如: 京东商城 【这属于 go web 开发范畴 】
端口:
1)0 是保留端口
2)1-1024 是固定端口,例如:22是SSH远程登录端口,23是telnet使用
3)1025 - 65535 是动态端口,程序员可以使用的端口
TCP编程
service.go

package main import ( "fmt" "io" "net" ) func process(conn net.Conn) { defer conn.Close() for{ buf :=make([]byte,1024) //1.等待客户端通过conn发送消息 //2.如果客户端没有wrtie[发送],那么协程就会阻塞在这里 n,err:=conn.Read(buf) //从conn读取 if err ==io.EOF{ fmt.Println("客户端退出了") return } //3.显示客户端发送的内容到服务器的终端 fmt.Print(string(buf[:n])) } } func main() { fmt.Println("服务器开始监听.....") listen,err :=net.Listen("tcp","127.0.0.1:8888") if err !=nil{ fmt.Println("listen err = ",err) return } defer listen.Close()//延时关闭链接 for{ //等待客户端链接 conn,err:=listen.Accept() if err!=nil{ fmt.Println("链接失败 err=",err) }else { fmt.Printf("客户端来链接了,客户端的IP=%v\n",conn.RemoteAddr().String()) } go process(conn) } }
client.go
package main import ( "bufio" "fmt" "net" "os" "strings" ) func main() { conn,err := net.Dial("tcp","127.0.0.1:8888") if err!=nil{ fmt.Println("客户端链接失败 err=",err) return } defer conn.Close() reader :=bufio.NewReader(os.Stdin) //从终端读取一行用户输入,并准备发送给服务器 for{ line,err:=reader.ReadString('\n') if err !=nil{ fmt.Println("readstring err=",err) } line = strings.Trim(line,"\r\n") if line=="exit"{ fmt.Println("客户端退出了") break } //再将line 发送给服务器 _,err = conn.Write([]byte(line+"\n")) if err!=nil{ fmt.Println("发送信息失败err=",err) } } }
go 链接 MYsql
golang数据类型和mysql数据类型的对应
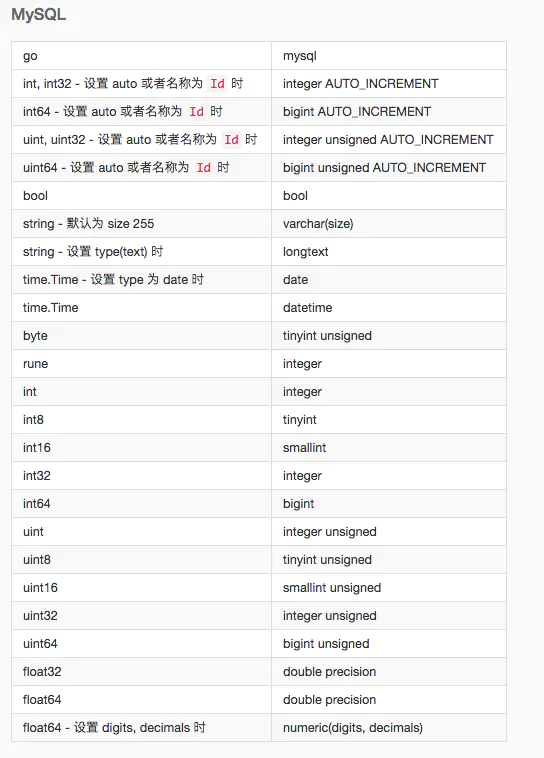
Golang 提供了database/sql包用于对SQL数据库的访问, 作为操作数据库的入口对象sql.DB, 主要为我们提供了两个重要的功能:
- sql.DB 通过数据库驱动为我们提供管理底层数据库连接的打开和关闭操作.
- sql.DB 为我们管理数据库连接池
需要注意的是,sql.DB表示操作数据库的抽象访问接口,而非一个数据库连接对象;它可以根据driver打开关闭数据库连接,管理连接池。正在使用的连接被标记为繁忙,用完后回到连接池等待下次使用。所以,如果你没有把连接释放回连接池,会导致过多连接使系统资源耗尽。
1.导入mysql数据库驱动
import ( "database/sql" _ "github.com/go-sql-driver/mysql" )
通常来说, 不应该直接使用驱动所提供的方法, 而是应该使用 sql.DB, 因此在导入 mysql 驱动时, 这里使用了匿名导入的方式(在包路径前添加 _), 当导入了一个数据库驱动后, 此驱动会自行初始化并注册自己到Golang的database/sql上下文中, 因此我们就可以通过 database/sql 包提供的方法访问数据库了.
2.连接数据库
type DbWorker struct { //mysql data source name Dsn string } func main() { dbw := DbWorker{ Dsn: "user:password@tcp(127.0.0.1:3306)/test", } db, err := sql.Open("mysql", dbw.Dsn) if err != nil { panic(err) return } defer db.Close() }
格式
db, err := sql.Open("mysql", "user:password@tcp(localhost:5555)/dbname?charset=utf8")
通过调用sql.Open函数返回一个sql.DB指针; sql.Open函数原型如下:
func Open(driverName, dataSourceName string) (*DB, error)
driverName: 使用的驱动名. 这个名字其实就是数据库驱动注册到 database/sql 时所使用的名字.
dataSourceName: 数据库连接信息,这个连接包含了数据库的用户名, 密码, 数据库主机以及需要连接的数据库名等信息.
- sql.Open并不会立即建立一个数据库的网络连接, 也不会对数据库链接参数的合法性做检验, 它仅仅是初始化一个sql.DB对象. 当真正进行第一次数据库查询操作时, 此时才会真正建立网络连接;
- sql.DB表示操作数据库的抽象接口的对象,但不是所谓的数据库连接对象,sql.DB对象只有当需要使用时才会创建连接,如果想立即验证连接,需要用Ping()方法;
- sql.Open返回的sql.DB对象是协程并发安全的.
- sql.DB的设计就是用来作为长连接使用的。不要频繁Open, Close。比较好的做法是,为每个不同的datastore建一个DB对象,保持这些对象Open。如果需要短连接,那么把DB作为参数传入function,而不要在function中Open, Close。
3.数据库基本操作
数据库查询的一般步骤如下:
- 调用 db.Query 执行 SQL 语句, 此方法会返回一个 Rows 作为查询的结果
- 通过 rows.Next() 迭代查询数据.
- 通过 rows.Scan() 读取每一行的值
- 调用 db.Close() 关闭查询
现有users数据库表如下:
CREATE TABLE `users` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(20) DEFAULT '', `age` int(11) DEFAULT '0', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4
MySQL 5.5 之前, UTF8 编码只支持1-3个字节,从MYSQL5.5开始,可支持4个字节UTF编码utf8mb4,一个字符最多能有4字节,utf8mb4兼容utf8,所以能支持更多的字符集;关于emoji表情的话mysql的utf8是不支持,需要修改设置为utf8mb4,才能支持。
查询数据
func (dbw *DbWorker) QueryData() { dbw.QueryDataPre() rows, err := dbw.Db.Query(`SELECT * From users where age >= 20 AND age < 30`) defer rows.Close() if err != nil { fmt.Printf("insert data error: %v\n", err) return } for rows.Next() { rows.Scan(&dbw.UserInfo.Id, &dbw.UserInfo.Name, &dbw.UserInfo.Age) if err != nil { fmt.Printf(err.Error()) continue } if !dbw.UserInfo.Name.Valid { dbw.UserInfo.Name.String = "" } if !dbw.UserInfo.Age.Valid { dbw.UserInfo.Age.Int64 = 0 } fmt.Println("get data, id: ", dbw.UserInfo.Id, " name: ", dbw.UserInfo.Name.String, " age: ", int(dbw.UserInfo.Age.Int64)) } err = rows.Err() if err != nil { fmt.Printf(err.Error()) } }
- rows.Scan 参数的顺序很重要, 需要和查询的结果的column对应. 例如 “SELECT * From user where age >=20 AND age < 30” 查询的行的 column 顺序是 “id, name, age” 和插入操作顺序相同, 因此 rows.Scan 也需要按照此顺序 rows.Scan(&id, &name, &age), 不然会造成数据读取的错位.
- 因为golang是强类型语言,所以查询数据时先定义数据类型,但是查询数据库中的数据存在三种可能:存在值,存在零值,未赋值NULL 三种状态, 因为可以将待查询的数据类型定义为sql.Nullxxx类型,可以通过判断Valid值来判断查询到的值是否为赋值状态还是未赋值NULL状态.
- 每次db.Query操作后, 都建议调用rows.Close(). 因为 db.Query() 会从数据库连接池中获取一个连接, 这个底层连接在结果集(rows)未关闭前会被标记为处于繁忙状态。当遍历读到最后一条记录时,会发生一个内部EOF错误,自动调用rows.Close(),但如果提前退出循环,rows不会关闭,连接不会回到连接池中,连接也不会关闭, 则此连接会一直被占用. 因此通常我们使用 defer rows.Close() 来确保数据库连接可以正确放回到连接池中; 不过阅读源码发现rows.Close()操作是幂等操作,即一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同, 所以即便对已关闭的rows再执行close()也没关系.
单行查询
var name string err = db.QueryRow("select name from users where id = ?", 1).Scan(&name) if err != nil { log.Fatal(err) } fmt.Println(name)
- err在Scan后才产生,上述链式写法是对的
- 需要注意Scan()中变量和顺序要和前面Query语句中的顺序一致,否则查出的数据会映射不一致.
插入数据
func (dbw *DbWorker) insertData() { ret, err := dbw.Db.Exec(`INSERT INTO users (name, age) VALUES ("xys", 23)`) if err != nil { fmt.Printf("insert data error: %v\n", err) return } if LastInsertId, err := ret.LastInsertId(); nil == err { fmt.Println("LastInsertId:", LastInsertId) } if RowsAffected, err := ret.RowsAffected(); nil == err { fmt.Println("RowsAffected:", RowsAffected) } }
通过 db.Exec() 插入数据,通过返回的err可知插入失败的原因,通过返回的ret可以进一步查询本次插入数据影响的行数RowsAffected和最后插入的Id(如果数据库支持查询最后插入Id).
db.Exec 和db.Query 的区别
1)从 db.Exec 返回的结果可以告诉您查询影响了多少行
2)而 db.Query 将返回 rows 对象.
下面是将上述案例用Prepared Statement 修改之后的完整代码
package main import ( "database/sql" "fmt" _ "github.com/go-sql-driver/mysql" ) type DbWorker struct { Dsn string Db *sql.DB UserInfo userTB } type userTB struct { Id int Name sql.NullString Age sql.NullInt64 } func main() { var err error dbw := DbWorker{ Dsn: "root:123456@tcp(localhost:3306)/golang?charset=utf8mb4", } dbw.Db, err = sql.Open("mysql", dbw.Dsn) if err != nil { panic(err) return } defer dbw.Db.Close() dbw.insertData() dbw.queryData() } func (dbw *DbWorker) insertData() { stmt, _ := dbw.Db.Prepare(`INSERT INTO users (name, age) VALUES (?, ?)`) defer stmt.Close() ret, err := stmt.Exec("xys", 23) if err != nil { fmt.Printf("insert data error: %v\n", err) return } if LastInsertId, err := ret.LastInsertId(); nil == err { fmt.Println("LastInsertId:", LastInsertId) } if RowsAffected, err := ret.RowsAffected(); nil == err { fmt.Println("RowsAffected:", RowsAffected) } } func (dbw *DbWorker) queryDataPre() { dbw.UserInfo = userTB{} } func (dbw *DbWorker) queryData() { stmt, _ := dbw.Db.Prepare(`SELECT * From users where age >= ? AND age < ?`) defer stmt.Close() dbw.queryDataPre() rows, err := stmt.Query(20, 30) defer rows.Close() if err != nil { fmt.Printf("insert data error: %v\n", err) return } for rows.Next() { rows.Scan(&dbw.UserInfo.Id, &dbw.UserInfo.Name, &dbw.UserInfo.Age) if err != nil { fmt.Printf(err.Error()) continue } if !dbw.UserInfo.Name.Valid { dbw.UserInfo.Name.String = "" } if !dbw.UserInfo.Age.Valid { dbw.UserInfo.Age.Int64 = 0 } fmt.Println("get data, id: ", dbw.UserInfo.Id, " name: ", dbw.UserInfo.Name.String, " age: ", int(dbw.UserInfo.Age.Int64)) } err = rows.Err() if err != nil { fmt.Printf(err.Error()) } }
db.Prepare()返回的statement使用完之后需要手动关闭,即defer stmt.Close()
4.预编译语句(Prepared Statement)
预编译语句(PreparedStatement)提供了诸多好处, 因此我们在开发中尽量使用它. 下面列出了使用预编译语句所提供的功能:
- PreparedStatement 可以实现自定义参数的查询
- PreparedStatement 通常来说, 比手动拼接字符串 SQL 语句高效.
- PreparedStatement 可以防止SQL注入攻击
一般用 Prepared Statements 和 Exec() 完成 INSERT, UPDATE, DELETE 操作。
实例二
mysql.go
package dbs import ( "database/sql" "fmt" _ "github.com/go-sql-driver/mysql" "log" "time" ) var MysqlDb *sql.DB var MysqlDbErr error const ( USER_NAME = "root" PASS_WORD = "root" HOST = "localhost" PORT = "3306" DATABASE = "demo" CHARSET = "utf8" ) // 初始化链接 func init() { dbDSN := fmt.Sprintf("%s:%s@tcp(%s:%s)/%s?charset=%s", USER_NAME, PASS_WORD, HOST, PORT, DATABASE, CHARSET) // 打开连接失败 MysqlDb, MysqlDbErr = sql.Open("mysql", dbDSN) //defer MysqlDb.Close(); if MysqlDbErr != nil { log.Println("dbDSN: " + dbDSN) panic("数据源配置不正确: " + MysqlDbErr.Error()) } // 最大连接数 MysqlDb.SetMaxOpenConns(100) // 闲置连接数 MysqlDb.SetMaxIdleConns(20) // 最大连接周期 MysqlDb.SetConnMaxLifetime(100*time.Second) if MysqlDbErr = MysqlDb.Ping(); nil != MysqlDbErr { panic("数据库链接失败: " + MysqlDbErr.Error()) } }
user.go
package dbs import ( "fmt" ) // 用户表结构体 type User struct { Id int64 `db:"id"` Name string `db:"name"` Age int `db:"age"` } // 查询数据,指定字段名 func StructQueryField() { user := new(User) row := MysqlDb.QueryRow("select id, name, age from users where id=?",1) if err :=row.Scan(&user.Id,&user.Name,&user.Age); err != nil{ fmt.Printf("scan failed, err:%v",err) return } fmt.Println(user.Id,user.Name,user.Age) } // 查询数据,取所有字段 func StructQueryAllField() { // 通过切片存储 users := make([]User, 0) rows, _:= MysqlDb.Query("SELECT * FROM `users` limit ?",100) // 遍历 var user User for rows.Next(){ rows.Scan(&user.Id, &user.Name, &user.Age) users=append(users,user) } fmt.Println(users) } // 插入数据 func StructInsert() { ret,_ := MysqlDb.Exec("insert INTO users(name,age) values(?,?)","小红",23) //插入数据的主键id lastInsertID,_ := ret.LastInsertId() fmt.Println("LastInsertID:",lastInsertID) //影响行数 rowsaffected,_ := ret.RowsAffected() fmt.Println("RowsAffected:",rowsaffected) } // 更新数据 func StructUpdate() { ret,_ := MysqlDb.Exec("UPDATE users set age=? where id=?","100",1) upd_nums,_ := ret.RowsAffected() fmt.Println("RowsAffected:",upd_nums) } // 删除数据 func StructDel() { ret,_ := MysqlDb.Exec("delete from users where id=?",1) del_nums,_ := ret.RowsAffected() fmt.Println("RowsAffected:",del_nums) } // 事务处理,结合预处理 func StructTx() { //事务处理 tx, _ := MysqlDb.Begin(); // 新增 userAddPre, _ := MysqlDb.Prepare("insert into users(name, age) values(?, ?)"); addRet, _ := userAddPre.Exec("zhaoliu", 15); ins_nums, _ := addRet.RowsAffected(); // 更新 userUpdatePre1, _ := tx.Exec("update users set name = 'zhansan' where name=?", "张三"); upd_nums1, _ := userUpdatePre1.RowsAffected(); userUpdatePre2, _ := tx.Exec("update users set name = 'lisi' where name=?", "李四"); upd_nums2, _ := userUpdatePre2.RowsAffected(); fmt.Println(ins_nums); fmt.Println(upd_nums1); fmt.Println(upd_nums2); if ins_nums > 0 && upd_nums1 > 0 && upd_nums2 > 0 { tx.Commit(); }else{ tx.Rollback(); } } // 查询数据,指定字段名,不采用结构体 func RawQueryField() { rows, _ := MysqlDb.Query("select id,name from users"); if rows == nil { return } id := 0; name := ""; fmt.Println(rows) fmt.Println(rows) for rows.Next() { rows.Scan(&id, &name); fmt.Println(id, name); } } // 查询数据,取所有字段,不采用结构体 func RawQueryAllField() { //查询数据,取所有字段 rows2, _ := MysqlDb.Query("select * from users"); //返回所有列 cols, _ := rows2.Columns(); //这里表示一行所有列的值,用[]byte表示 vals := make([][]byte, len(cols)); //这里表示一行填充数据 scans := make([]interface{}, len(cols)); //这里scans引用vals,把数据填充到[]byte里 for k, _ := range vals { scans[k] = &vals[k]; } i := 0; result := make(map[int]map[string]string); for rows2.Next() { //填充数据 rows2.Scan(scans...); //每行数据 row := make(map[string]string); //把vals中的数据复制到row中 for k, v := range vals { key := cols[k]; //这里把[]byte数据转成string row[key] = string(v); } //放入结果集 result[i] = row; i++; } fmt.Println(result); }
入口调用测试
main.go
package main import "packago/mysql/dbs" func main() { dbs.StructInsert() //插入数据 dbs.StructUpdate() //修改数据 dbs.StructQueryField() //查询数据,指定字段名 dbs.StructQueryAllField()// 查询数据,取所有字段 dbs.StructDel()// 删除数据 dbs.StructTx()// 事务处理,结合预处理 dbs.RawQueryField()// 查询数据,指定字段名,不采用结构体 dbs.RawQueryAllField()// 查询数据,取所有字段,不采用结构体 }
结构
├── dbs
│ ├── mysql.go 连接mysql
│ └── user.go user表操作
├── main.go 入口文件
查询
var name string var age int rows, err := db.Query("select name,age from user where id = ? ", 1) if err != nil { fmt.Println(err) } defer rows.Close() for rows.Next() { err := rows.Scan(&name, &age) if err != nil { fmt.Println(err) } } err = rows.Err() if err != nil { fmt.Println(err) } fmt.Println("name:", url, "age:", description)
增删改
stmt, err := db.Prepare("insert into user(name,age)values(?,?)") if err != nil { log.Println(err) } rs, err := stmt.Exec("go-test", 12) if err != nil { log.Println(err) } //我们可以获得插入的id id, err := rs.LastInsertId() //可以获得影响行数 affect, err := rs.RowsAffected()
参考来自:https://www.cnblogs.com/youxin/p/16028622.html
go 链接 redis 一
安装第三方开源 Redis 库
1) 使用第三方开源的 redis 库: github.com/garyburd/redigo/redis
2) 在使用 Redis 前,先安装第三方 Redis 库,在 GOPATH 路径下执行安装指令: D:\goproject>go get github.com/garyburd/redigo/redis
特别说明: 在安装 Redis 库前,确保已经安装并配置了 Git, 因为 是从 github 下载安装 Redis 库的, 需要使用到 Git。 如果没有安装配置过 Git,请参考: 如何安装配置 Git
redis 链接操作 Set Get
package main import ( "fmt" "github.com/garyburd/redigo/redis" ) func main() { c,err:=redis.Dial("tcp","localhost:6379") if err!=nil{ fmt.Println("redis conn err = ",err) return } defer c.Close() _,err=c.Do("Set","key1",998) if err!=nil{ fmt.Println("写入错误err=",err) return } r,err :=redis.Int(c.Do("Get","key1")) //r 返回的是 interface{} if err!=nil{ fmt.Println("get key failed err=",err) } fmt.Println(r) }
对redis hash 的操作
package main import ( "fmt" "github.com/garyburd/redigo/redis" ) func main() { c,err:=redis.Dial("tcp","localhost:6379") if err!=nil{ fmt.Println("redis conn err = ",err) return } defer c.Close() _,err=c.Do("HSet","user01","name","tianxin") if err!=nil{ fmt.Println("hset err=",err) return } _,err=c.Do("HSet","user01","age",18) if err!=nil{ fmt.Println("hset err=",err) return } name,err :=redis.String(c.Do("HGet","user01","name")) //r 返回的是 interface{} if err!=nil{ fmt.Println("HGet key failed err=",err) } fmt.Println(name) age,err :=redis.Int(c.Do("HGet","user01","age")) //r 返回的是 interface{} if err!=nil{ fmt.Println("HGet key failed err=",err) } fmt.Println(age) }
批量的Set Get数据
package main import ( "fmt" "github.com/garyburd/redigo/redis" ) func main() { c,err:=redis.Dial("tcp","localhost:6379") if err!=nil{ fmt.Println("redis conn err = ",err) return } defer c.Close() _,err=c.Do("HMSet","user02","name","tianxingege","age",30) if err!=nil{ fmt.Println("HMSet err=",err) return } r,err :=redis.Strings(c.Do("HMGet","user02","name","age")) //r 返回的是 interface{} if err!=nil{ fmt.Println("HGet key failed err=",err) } for i,v:=range r{ fmt.Printf("r[%d]=%s\n",i,v) } }
redis 链接池
说明:通过Golang 对Redis操作,还可以通过Redis连接池,流程如下:
1) 事先初始化一定数量的链接,放入连接池
2) 当GO需要操作Redis时,直接从Redis连接池取出链接即可。
3) 这样可以节省临时获取Redis链接的实际,从而提高效率。
package main import ( "fmt" "github.com/garyburd/redigo/redis" ) //定义一个全局的pool var pool *redis.Pool //当启动程序时,就初始化连接池 func init() { pool = &redis.Pool{ Dial: func() (redis.Conn,error) { return redis.Dial("tcp","localhost:6379") }, MaxIdle: 8,//最大空闲连接数 MaxActive: 0,//表示和数据库的最大链接数,0 表示没有限制 IdleTimeout: 100,//最大空闲实际 } } func main() { //pool.Close() //如果连接池关闭了就不能取到链接了 //先从pool 取出一个链接 conn := pool.Get() defer conn.Close() _,err :=conn.Do("Set","name","中华人民共和国") if err !=nil{ fmt.Println("conn.Do err= ",err) } //取出 r,err := redis.String(conn.Do("Get","name")) if err !=nil{ fmt.Println("conn.Do GET err= ",err) } fmt.Println(r) }
go 链接 redis 二
使用的是 https://github.com/go-redis/redis 这个 golang 客户端, 因此安装方式如下:
go get gopkg.in/redis.v4
package main import ( "fmt" "gopkg.in/redis.v4" "sync" "time" ) func main() { client := createClient() defer client.Close() stringOperation( client ) listOperation( client ) setOperation( client ) hashOperation( client ) connectPool( client ) } // 创建 redis 客户端 func createClient() *redis.Client { client := redis.NewClient( &redis.Options{ Addr: "localhost:6379", Password: "", DB: 0, PoolSize: 5, } ) pong, err := client.Ping().Result() fmt.Println( pong, err ) return client } // String 操作 func stringOperation( client *redis.Client ) { // 第三个参数是过期时间, 如果是 0, 则表示没有过期时间. err := client.Set( "name", "xys", 0 ).Err() if err != nil { panic( err ) } val, err := client.Get( "name" ).Result() if err != nil { panic( err ) } fmt.Println( "name", val ) // 这里设置过期时间. err = client.Set( "age", "20", 1 * time.Second ).Err() if err != nil { panic( err ) } client.Incr( "age" ) // 自增 client.Incr( "age" ) // 自增 client.Decr( "age" ) // 自减 val, err = client.Get( "age" ).Result() if err != nil { panic( err ) } fmt.Println( "age", val ) // age 的值为21 // 因为 key "age" 的过期时间是一秒钟, 因此当一秒后, 此 key 会自动被删除了. time.Sleep( 1 * time.Second ) val, err = client.Get( "age" ).Result() if err != nil { // 因为 key "age" 已经过期了, 因此会有一个 redis: nil 的错误. fmt.Printf( "error: %v\n", err ) } fmt.Println( "age", val ) } // list 操作 func listOperation( client *redis.Client ) { client.RPush( "fruit", "apple" ) // 在名称为 fruit 的list尾添加一个值为value的元素 client.LPush( "fruit", "banana" ) // 在名称为 fruit 的list头添加一个值为value的 元素 length, err := client.LLen( "fruit" ).Result() // 返回名称为 fruit 的list的长度 if err != nil { panic( err ) } fmt.Println( "length: ", length ) // 长度为2 value, err := client.LPop( "fruit" ).Result() //返回并删除名称为 fruit 的list中的首元素 if err != nil { panic(err) } fmt.Println( "fruit: ", value ) value, err = client.RPop( "fruit" ).Result() // 返回并删除名称为 fruit 的list中的尾元素 if err != nil { panic(err) } fmt.Println( "fruit: ", value ) } // set 操作 func setOperation( client *redis.Client ) { client.SAdd( "blacklist", "Obama" ) // 向 blacklist 中添加元素 client.SAdd( "blacklist", "Hillary" ) // 再次添加 client.SAdd( "blacklist", "the Elder" ) // 添加新元素 client.SAdd( "whitelist", "the Elder" ) // 向 whitelist 添加元素 // 判断元素是否在集合中 isMember, err := client.SIsMember( "blacklist", "Bush" ).Result() if err != nil { panic(err) } fmt.Println( "Is Bush in blacklist: ", isMember ) // 求交集, 即既在黑名单中, 又在白名单中的元素 names, err := client.SInter( "blacklist", "whitelist" ).Result() if err != nil { panic(err) } // 获取到的元素是 "the Elder" fmt.Println( "Inter result: ", names ) // 获取指定集合的所有元素 all, err := client.SMembers( "blacklist" ).Result() if err != nil { panic(err) } fmt.Println( "All member: ", all ) } // hash 操作 func hashOperation( client *redis.Client ) { client.HSet( "user_xys", "name", "xys" ); // 向名称为 user_xys 的 hash 中添加元素 name client.HSet( "user_xys", "age", "18" ); // 向名称为 user_xys 的 hash 中添加元素 age // 批量地向名称为 user_test 的 hash 中添加元素 name 和 age client.HMSet( "user_test", map[string]string{"name": "test", "age":"20"} ) // 批量获取名为 user_test 的 hash 中的指定字段的值. fields, err := client.HMGet( "user_test", "name", "age" ).Result() if err != nil { panic(err) } fmt.Println( "fields in user_test: ", fields ) // 获取名为 user_xys 的 hash 中的字段个数 length, err := client.HLen( "user_xys" ).Result() if err != nil { panic(err) } fmt.Println( "field count in user_xys: ", length ) // 字段个数为2 // 删除名为 user_test 的 age 字段 client.HDel( "user_test", "age" ) age, err := client.HGet( "user_test", "age" ).Result() if err != nil { fmt.Printf( "Get user_test age error: %v\n", err ) } else { fmt.Println( "user_test age is: ", age ) // 字段个数为2 } } // redis.v4 的连接池管理 func connectPool( client *redis.Client ) { wg := sync.WaitGroup{} wg.Add( 10 ) for i := 0; i < 10; i++ { go func() { defer wg.Done() for j := 0; j < 100; j++ { client.Set( fmt.Sprintf( "name%d", j ), fmt.Sprintf( "xys%d", j ), 0 ).Err() client.Get( fmt.Sprintf( "name%d", j ) ).Result() } fmt.Printf( "PoolStats, TotalConns: %d, FreeConns: %d\n", client.PoolStats().TotalConns, client.PoolStats().FreeConns ); }() } wg.Wait() }
RabbitMQ链接
ch.QueueDeclare
queue, err = ch.QueueDeclare( "hello", // name false, // durable false, // delete when unused false, // exclusive false, // no-wait nil, // arguments )
| 参数名 | 参数类型 | 解释 |
|---|---|---|
| name | string | 队列名称 |
| durable | bool | 是否持久化,队列的声明默认是存放到内存中的,如果rabbitmq重启会丢失,如果想重启之后还存在就要使队列持久化,保存到Erlang自带的Mnesia数据库中,当rabbitmq重启之后会读取该数据库 |
| autoDelete | bool | 是否自动删除队列,当最后一个消费者断开连接之后队列是否自动被删除,可以通过RabbitMQ Management,查看某个队列的消费者数量,当consumers = 0时队列就会自动删除 |
| exclusive | bool | 是否排外的,有两个作用, 1:当连接关闭时该队列是否会自动删除; 2:该队列是否是私有的private,如果不是排外的,可以使用两个消费者都访问同一个队列,没有任何问题,如果是排外的,会对当前队列加锁,其他通道channel是不能访问的,如果强制访问会报异常; 一般等于true的话用于一个队列只能有一个消费者来消费的场景 |
| no-wait | bool | 是否等待服务器返回 |
| arguments | map[string]interface{} | 设置队列的其他一些参数,如 x-rnessage-ttl 、x-expires 、x-rnax-length 、x-rnax-length-bytes、 x-dead-letter-exchange、 x-deadletter-routing-key 、 x-rnax-priority 等。 |
ch.Publish
ch.Publish( "", // exchange "hello", // routing key false, // mandatory false, // immediate body, // msg )
| 参数名 | 参数类型 | 解释 |
|---|---|---|
| exchange | string | 交换机 |
| routing key | string | 路由键,#匹配0个或多个单词,*匹配一个单词,在topic exchange做消息转发用 |
| mandatory | bool | true:如果exchange根据自身类型和消息routeKey无法找到一个符合条件的queue,那么会调用basic.return方法将消息返还给生产者。 false:出现上述情形broker会直接将消息扔掉 |
| immediate | bool | true:如果exchange在将消息route到queue(s)时发现对应的queue上没有消费者,那么这条消息不会放入队列中。当与消息routeKey关联的所有queue(一个或多个)都没有消费者时,该消息会通过basic.return方法返还给生产者。 |
| msg | 消息内容 |
ch.Consume
ch.Consume( "hello", // queue "", // consumer true, // auto-ack false, // exclusive false, // no-local false, // no-wait nil, // args )
| 参数名 | 参数类型 | 解释 |
|---|---|---|
| queue | string | |
| consumer | string | |
| auto-ack | bool | 是否自动ack,如果不自动ack,需要使用channel.ack、channel.nack、channel.basicReject 进行消息应答 |
| exclusive | bool | |
| no-local | bool | |
| no-wait | bool | 是否等待服务器返回 |
| args |
ch.ExchangeDeclare
ch.ExchangeDeclare( "logs", // name "fanout", // type true, // durable false, // auto-deleted false, // internal false, // no-wait nil, // arguments )
| 参数名 | 参数类型 | 解释 |
|---|---|---|
| name | string | |
| type | string | 交换机类型: direct fanout topic headers其中一种 |
| durable | bool | 是否持久化,durable设置为true表示持久化,反之是非持久化,持久化的可以将交换器存盘,在服务器重启的时候不会丢失信息 |
| auto-deleted | bool | 是否自动删除,设置为TRUE则表是自动删除,自删除的前提是至少有一个队列或者交换器与这交换器绑定,之后所有与这个交换器绑定的队列或者交换器都与此解绑,一般都设置为fase |
| internal | bool | 是否内置,如果设置 为true,则表示是内置的交换器,客户端程序无法直接发送消息到这个交换器中,只能通过交换器路由到交换器的方式 |
| no-wait | bool | 是否等待服务器返回 |
| arguments | 其它一些结构化参数比如alternate-exchange |
数据结构
稀疏数组

package main import ( "bufio" "fmt" "io" "os" "strconv" "strings" ) type ValNode struct { row int col int val int } func main() { //原始数组 var chessMap [11][11]int chessMap[1][2] = 1 //黑子 chessMap[2][3] = 2 //篮子 for _,v := range chessMap{ for _,v2 := range v{ fmt.Printf("%d\t",v2) } fmt.Println() } //稀疏数组 var sparseArr []ValNode sparseArr = append(sparseArr,ValNode{11,11,0})//初始规模 for i,v := range chessMap{ for j,v2 := range v{ if v2!=0{ sparseArr = append(sparseArr,ValNode{i,j,v2}) } } } //fmt.Println(sparseArr) //将稀疏数组存入文件 filepath :="c:/goprojects/arr.data" file,err :=os.OpenFile(filepath,os.O_WRONLY|os.O_TRUNC,0666) //2.写 和 清空 的模式 if err != nil{ fmt.Printf("打开文件错误,err=",err) } //及时关闭file句柄 defer file.Close() var str string for _,valNode:=range sparseArr{ str += strconv.Itoa(valNode.row)+" "+strconv.Itoa(valNode.col)+" "+strconv.Itoa(valNode.val)+"\n" } //fmt.Println(str) writer := bufio.NewWriter(file) writer.WriteString(str) writer.Flush() //从文件取出数据恢复数组 file1,err :=os.OpenFile(filepath,os.O_RDONLY,0666) //.读写 和 追加 的模式 defer file1.Close() reader :=bufio.NewReader(file1) var strarr []ValNode for { str,err := reader.ReadString('\n') if err == io.EOF{ break } if str!="\n"{ arr := strings.Fields(str) row,_:=strconv.Atoi(arr[0]) col,_:=strconv.Atoi(arr[1]) val,_:=strconv.Atoi(arr[2]) strarr = append(strarr,ValNode{row,col,val}) } } fmt.Println(strarr) var cheeMap2 [11][11]int for i,valNode:=range strarr{ if i!=0{ cheeMap2[valNode.row][valNode.col] = valNode.val } } for _,v := range cheeMap2{ for _,v2 := range v{ fmt.Printf("%d\t",v2) } fmt.Println() } }
队列
1) 队列是一个有序列表,可以用数组或者链表来实现
2) 先入先出的原则,即:先存入队列的数据,要先取出,后存入的要后取出
数组模拟队列
1) 队列本身是有序表,若使用数组的结构来存储队列的数据,则队列数组的声明如下 其中 maxSize 是该队列的最大容量
2) 因为队列的输出,输入时分别从前后端来处理,因此需要两个变量front 及 rear 分别记录队列前后端的下标,front会随着数据输出而改变
而rear则是随着数据输入而改变
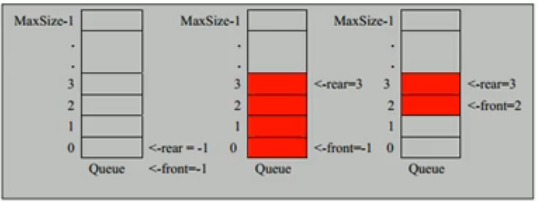
先完成一个非环形的队列(数组来实现)
package main import ( "errors" "fmt" "os" ) //使用一个结构体管理队列 type Queue struct { maxSize int //队列最大长度 array [5]int //数组 front int //指向前的标识 rear int //指向尾的标识 } //添加数据到队列 func (this *Queue) AddQueue(val int) (err error) { //先判断队列是否已满 if this.rear == this.maxSize-1 { //重要提示 rear 是队列尾部 包含最后元素 return errors.New("queue full") } this.rear++ this.array[this.rear] = val return } //从队列里面取出数据 func (this *Queue)GetQueue()(val int,err error) { //先判断是否为空 if this.front==this.rear{ return -1,errors.New("Queue empty") } this.front++ return this.array[this.front],nil } //显示当前队列 func (this *Queue) ShowQueue() { fmt.Println("队列当前的情况是:") //首标识不包含元素,尾标识包含元素 for i := this.front + 1; i <= this.rear; i++ { fmt.Printf("array[%d]=%d\n", i, this.array[i]) } } func main() { queue := &Queue{ maxSize: 5, array: [5]int{}, front: -1, rear: -1, } var key string var val int for { fmt.Println("1.输入add 表示添加数据到队列") fmt.Println("2.输入get 表示从队列获取数据") fmt.Println("3.输入show 表示显示队列") fmt.Println("4.输入exit 表示对出队列") fmt.Scanln(&key) switch key { case "add": fmt.Println("输入你要入队列数") fmt.Scanln(&val) err := queue.AddQueue(val) if err != nil { fmt.Println(err.Error()) } else { fmt.Println("加入队列成功") } case "get": val,err:=queue.GetQueue() if err !=nil{ fmt.Println("取出数据出错 err=",err) }else { fmt.Println("从队列取出了一个数据 =",val) } case "show": queue.ShowQueue() case "exit": os.Exit(0)//Exit让当前程序以给出的状态码code退出。一般来说,状态码0表示成功,非0表示出错。程序会立刻终止,defer的函数不会被执行。 } } }
数组模拟环形队列
对前面的数组模拟队列优化,充分利用数组,因此将数组看做是一个环形的(通过取模的方法来实现即可)
提醒:
1) 尾索引的下一个为头索引时,表示队列 满,即将队列容量空出一个作为约定,这个在做判断队列满的时候需要注意(tail+1)%maxsize == head 满]
2) tail == head[空]
分析思路:
分析思路:
1) 什么时候表示队列满(rear+1)%maxSize = front
2) front = rear 空
3) 初始化 front = rear = 0
4) 怎么统计该队列有多少个元素 (rear+maxSize-front)%maxSize
package main import ( "errors" "fmt" "os" ) //使用一个结构体管理队列 type Queue struct { maxSize int //队列最大长度 array [5]int //数组 front int //指向前的标识 rear int //指向尾的标识 } //添加数据到队列 func (this *Queue) AddQueue(val int) (err error) { //先判断队列是否已满 if (this.rear+1)%this.maxSize == this.front { return errors.New("queue full") } this.array[this.rear] = val this.rear++ //rear没有包含最后元素 return } //从队列里面取出数据 func (this *Queue)GetQueue()(val int,err error) { //先判断是否为空 if this.front==this.rear{ return 0,errors.New("Queue empty") } val = this.array[this.front] //front包含首元素 this.front++ return } //显示当前队列 func (this *Queue) ShowQueue() { fmt.Println("队列当前的情况是:") size := this.Size() if(size==0){ fmt.Println("队列为空") } tempHead :=this.front for i := 0; i < size; i++ { fmt.Printf("array[%d]=%d\n", tempHead, this.array[tempHead]) tempHead = (tempHead+1)%this.maxSize } fmt.Println() } //取出环形队列又多少个元素 func (this *Queue) Size() int { return (this.rear+this.maxSize-this.front)%this.maxSize } func main() { queue := &Queue{ maxSize: 5, array: [5]int{}, front: 0, rear: 0, } var key string var val int for { fmt.Println("1.输入add 表示添加数据到队列") fmt.Println("2.输入get 表示从队列获取数据") fmt.Println("3.输入show 表示显示队列") fmt.Println("4.输入exit 表示对出队列") fmt.Scanln(&key) switch key { case "add": fmt.Println("输入你要入队列数") fmt.Scanln(&val) err := queue.AddQueue(val) if err != nil { fmt.Println(err.Error()) } else { fmt.Println("加入队列成功") } case "get": val,err:=queue.GetQueue() if err !=nil{ fmt.Println("取出数据出错 err=",err) }else { fmt.Println("从队列取出了一个数据 =",val) } case "show": queue.ShowQueue() case "exit": os.Exit(0)//Exit让当前程序以给出的状态码code退出。一般来说,状态码0表示成功,非0表示出错。程序会立刻终止,defer的函数不会被执行。 } } }
知识点:
return 结束当前函数,并返回指定值runtime.Goexit结束当前goroutine,其他的goroutine不受影响,主程序也一样继续运行os.Exit 会结束当前程序,不管你三七二十一
链表
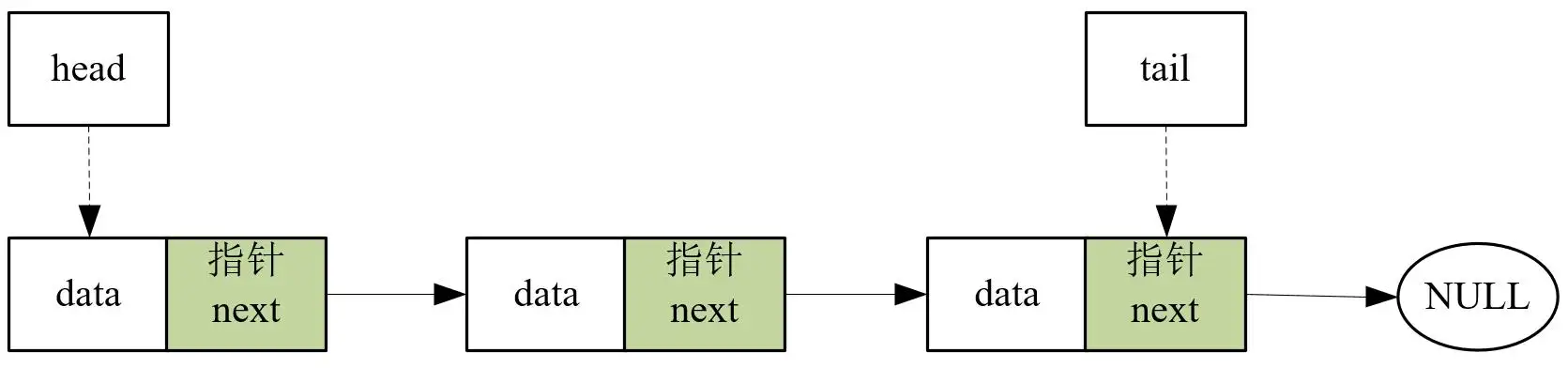
单向链表
头节点一般 不存放数据
package main import "fmt" type HeroNode struct { no int name string nickname string next *HeroNode //这个表示指向下一个节点 } //给链表尾部插入一个节点 func InsertHeroNode(head *HeroNode,newHeroNode *HeroNode) { //找到最后节点 temp :=head for{ if temp.next == nil{ //找到了最后一个 break } temp = temp.next //往下找 } //将元素加入到最后 temp.next = newHeroNode } //根据no 从小到大排序的插入 func InsertHeroNode2(head *HeroNode,newHeroNode *HeroNode) { temp :=head //让插入的节点的no 和 temp的下一个节点的no比较 flag :=true for{ if temp.next == nil{ //找到了最后一个 break }else if(temp.next.no>newHeroNode.no){ break }else if temp.next.no==newHeroNode.no{ flag = false break } temp = temp.next } if !flag{ fmt.Println("已经存在改排名 no=",newHeroNode.no) }else { newHeroNode.next = temp.next temp.next = newHeroNode } } //删除节点 func DelHeroNode(head *HeroNode,id int) { temp :=head flag :=false for{ if temp.next == nil{ break }else if(temp.next.no == id){ flag = true break } temp = temp.next } if flag{ temp.next = temp.next.next }else { fmt.Println("没有找到节点 id=",id) } } //显示链表的所有信息 func ListHeroNode(head *HeroNode) { temp :=head if temp.next == nil{ fmt.Println("空链表") } for{ fmt.Printf("[%d,%s,%s]==>\n",temp.next.no,temp.next.name,temp.next.nickname) temp = temp.next if temp.next==nil{ break } } } func main() { //头节点 head :=&HeroNode{} //创建一个新的HeroNode hero1 :=&HeroNode{ no: 1, name: "宋江", nickname: "及时雨", next: nil, } hero2 :=&HeroNode{ no: 2, name: "卢俊义", nickname: "玉麒麟", next: nil, } hero3 :=&HeroNode{ no: 3, name: "林冲", nickname: "豹子头", next: nil, } hero4 :=&HeroNode{ no: 4, name: "吴用", nickname: "智多星", next: nil, } InsertHeroNode2(head,hero4) InsertHeroNode2(head,hero3) InsertHeroNode2(head,hero2) InsertHeroNode2(head,hero1) DelHeroNode(head,5) ListHeroNode(head) }
双向链表
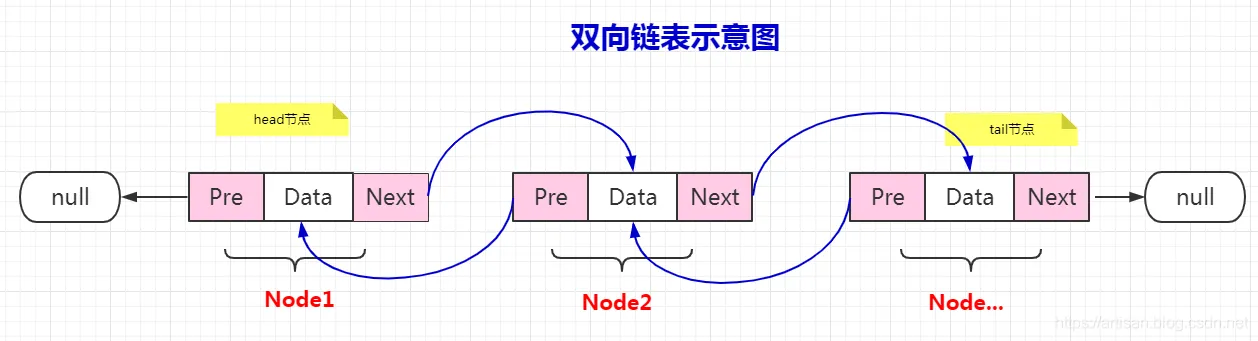
package main import "fmt" type HeroNode struct { no int name string nickname string next *HeroNode //这个表示指向下一个节点 pre *HeroNode } //给链表尾部插入一个节点 func InsertHeroNode(head *HeroNode, newHeroNode *HeroNode) { //找到最后节点 temp := head for { if temp.next == nil { //找到了最后一个 break } temp = temp.next //往下找 } //将元素加入到最后 temp.next = newHeroNode newHeroNode.pre = temp } //根据no 从小到大排序的插入 func InsertHeroNode2(head *HeroNode, newHeroNode *HeroNode) { temp := head //让插入的节点的no 和 temp的下一个节点的no比较 flag := true for { if temp.next == nil { //找到了最后一个 break } else if (temp.next.no > newHeroNode.no) { break } else if temp.next.no == newHeroNode.no { flag = false break } temp = temp.next } if !flag { fmt.Println("已经存在改排名 no=", newHeroNode.no) } else { newHeroNode.pre = temp newHeroNode.next = temp.next if temp.next != nil { //后面还有节点 temp.next.pre = newHeroNode } temp.next = newHeroNode } } //删除节点 func DelHeroNode(head *HeroNode, id int) { temp := head flag := false for { if temp.next == nil { break } else if (temp.next.no == id) { flag = true break } temp = temp.next } if flag { //找到并删除 temp.next = temp.next.next if temp.next != nil { //判断不然导致空指针 temp.next.pre = temp } } else { fmt.Println("没有找到节点 id=", id) } } //显示链表的所有信息 func ListHeroNode(head *HeroNode) { temp := head if temp.next == nil { fmt.Println("空链表") } for { fmt.Printf("[%d,%s,%s]==>\n", temp.next.no, temp.next.name, temp.next.nickname) temp = temp.next if temp.next == nil { break } } } //逆序打印 func ListHeroNode2(head *HeroNode) { temp := head //把temp移动到链表最后面 for { if temp.next == nil { break } temp = temp.next } i := 1 for { fmt.Printf("[%d,%s,%s]==>\n", temp.no, temp.name, temp.nickname) temp = temp.pre if temp.pre == nil { break } i++ } } func main() { //头节点 head := &HeroNode{} //创建一个新的HeroNode hero1 := &HeroNode{ no: 1, name: "宋江", nickname: "及时雨", } hero2 := &HeroNode{ no: 2, name: "卢俊义", nickname: "玉麒麟", } hero3 := &HeroNode{ no: 3, name: "林冲", nickname: "豹子头", } hero4 := &HeroNode{ no: 4, name: "吴用", nickname: "智多星", } /*InsertHeroNode(head,hero1) InsertHeroNode(head,hero2) InsertHeroNode(head,hero3) InsertHeroNode(head,hero4) fmt.Println("顺序打印:") ListHeroNode(head) fmt.Println("逆序打印:") ListHeroNode2(head)*/ InsertHeroNode2(head, hero1) InsertHeroNode2(head, hero2) InsertHeroNode2(head, hero3) InsertHeroNode2(head, hero4) DelHeroNode(head, 2) ListHeroNode2(head) }
其中 GO提供了环形链表 container/ring
func New(n int) *Ring // 创建一个有n个元素的环形链表,返回一个元素指针 func (r *Ring) Next() *Ring // 获取下一个元素 func (r *Ring) Prev() *Ring // 获取上一个元素 func (r *Ring) Move(n int) *Ring // 获取当前位置移动n个位置后的元素
func main() { r := ring.New(5) // 创建长度为5的环形链表 // 遍历链表赋值,环形链表的遍历比较特殊 for i, now := 0, r.Next(); i < r.Len(); now, i = now.Next(), i+1 { now.Value = i } // 遍历链表的值 for i, now := 0, r.Next(); i < r.Len(); now, i = now.Next(), i+1 { log.Printf("%v = %v", i, now.Value) } // 上面的遍历已经将r这个指针指向了值为4的这个元素 log.Println("r:", r.Value) // 打印 4 log.Println("next:", r.Next().Value) // 打印 0 log.Println("prev", r.Prev().Value) // 打印 3 log.Println("move:", r.Move(2).Value) // 打印 1 }
上面介绍了链表的基础查询移动,下面最后再介绍链表的其余几个方法:
func (r *Ring) Link(s *Ring) *Ring // 将r和s两个环形链表相加,也就是讲两个链表合成为一个链表,返回r这个元素的下一个元素 func (*Ring) Unlink // 删除链表中n % r.Len()个元素,从r.Next()开始删除。如果n % r.Len() == 0,不修改r。返回删除的元素构成的链表,r不能为空。 func (r *Ring) Do(f func(interface{})) // 对链表中的每个元素都执行f方法
func main() { r := ring.New(5) // 创建长度为5的环形链表 // 遍历链表赋值,环形链表的遍历比较特殊 for i, now := 0, r.Next(); i < r.Len(); now, i = now.Next(), i+1 { now.Value = i } log.Println("=========我是漂亮的分割线=======") rmR := r.Unlink(2) // 2对5取余等于2,也就是移除2个元素,从r的下一个元素开始移除,返回删除的元素构成的链表 log.Println(r.Len()) // 移除了2个,打印 3 log.Println("=========我也是漂亮的分割线=======") // 将上一步删除的元素再加进链表中 r.Link(rmR) // 遍历链表的值 for i, now := 0, r.Next(); i < r.Len(); now, i = now.Next(), i+1 { log.Printf("%v = %v", i, now.Value) } // 遍历链表的元素,转换为int后,打印+1的值 r.Do(func(i interface{}) { log.Println(i.(int) + 1) }) }
排序
排序的介绍
排序是将一组数据,依指定的顺序进行的排序的过程,常见的排序: 1)冒泡排序 2)选择排序 3)插入排序 4)快速排序 (速度最快)
选择排序简洁:
选择式排序也属于内部排序法,是从欲排序的数据中,按指定的规则选出某一元素,经过和其他元素重整,再依原则
交换位置后达到的排序目的。
思想:
选择排序(select sorting)也是一种简单的排序方法,它的基本思想是:第一次从R[0]~R[n-1]中选取最小值,与R[0]交换,
第二次从R[1]~R[n-1]中选取最小值,与R[2]交换....第i次从R[i-1]~R[n-1]中选取最小值,与R[i-1]交换,...第n-1次从
R[n-2]~R[n-1]中选取最小值,与R[n-2]交换,总共通过n-1次,得到一个按排序码从小到大排序的有序序列。
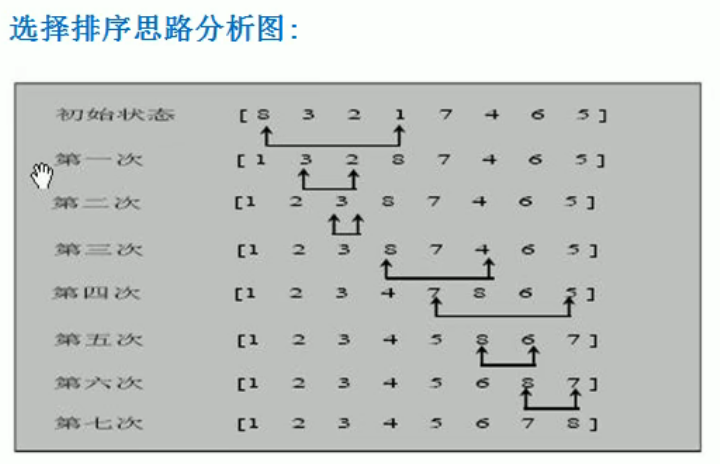
package main import "fmt" func SelectSort(arr *[9]int) { //(*arr)[1] = 600 等价于 arr[1]=600 for j:=0;j<len(arr)-1;j++{ max :=arr[j] maxIndex :=j for i:=j+1;i<len(arr);i++{ if max<arr[i]{ max = arr[i] maxIndex = i } } //交换 if maxIndex!=j{ arr[j],arr[maxIndex] = arr[maxIndex],arr[j] } fmt.Printf("第%d次 %v\n",j+1,*arr) } } func main() { arr :=[9]int{10,34,19,100,80,48,69,84,11} SelectSort(&arr) fmt.Println(arr) }
结果:
第1次 [100 34 19 10 80 48 69 84 11] 第2次 [100 84 19 10 80 48 69 34 11] 第3次 [100 84 80 10 19 48 69 34 11] 第4次 [100 84 80 69 19 48 10 34 11] 第5次 [100 84 80 69 48 19 10 34 11] 第6次 [100 84 80 69 48 34 10 19 11] 第7次 [100 84 80 69 48 34 19 10 11] 第8次 [100 84 80 69 48 34 19 11 10] [100 84 80 69 48 34 19 11 10]
插入排序法思想:
插入排序的基本思想是:把N个待排序的元素看成为一个有序表和一个无序表,开始时有序表中只包含一个元素,无序表中
包含有N-1个元素,排序过程中每次从无序表中取出第一个元素,把它的排序码一次与有序元素的排序码进行比较,将它插入
到有序表中的适当位置,使之成为新的有序表
package main import "fmt" func InsertSort(arr *[5]int) { for i:=1;i<len(arr);i++{ insertVal :=arr[i] inserIndex :=i-1; //从大到小 for inserIndex>=0 && arr[inserIndex]<insertVal{ arr[inserIndex+1] = arr[inserIndex] //数据后移 inserIndex-- } //插入 if inserIndex+1 != i{ arr[inserIndex+1] = insertVal } fmt.Printf("第%d次插入后 %v\n",i,*arr) } } func main() { arr :=[5]int{23,0,12,56,34} fmt.Println("原始数组=",arr) InsertSort(&arr) fmt.Println("main 函数") fmt.Println(arr) }
结果:
原始数组= [23 0 12 56 34] 第1次插入后 [23 0 12 56 34] 第2次插入后 [23 12 0 56 34] 第3次插入后 [56 23 12 0 34] 第4次插入后 [56 34 23 12 0] main 函数 [56 34 23 12 0]
快速排序
快速排序(Quicksort)是对冒泡排序的一种改进。基本思想是:
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比
另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,
整个排序过程可以递归进行,以此达到整个数据变成有序序列。
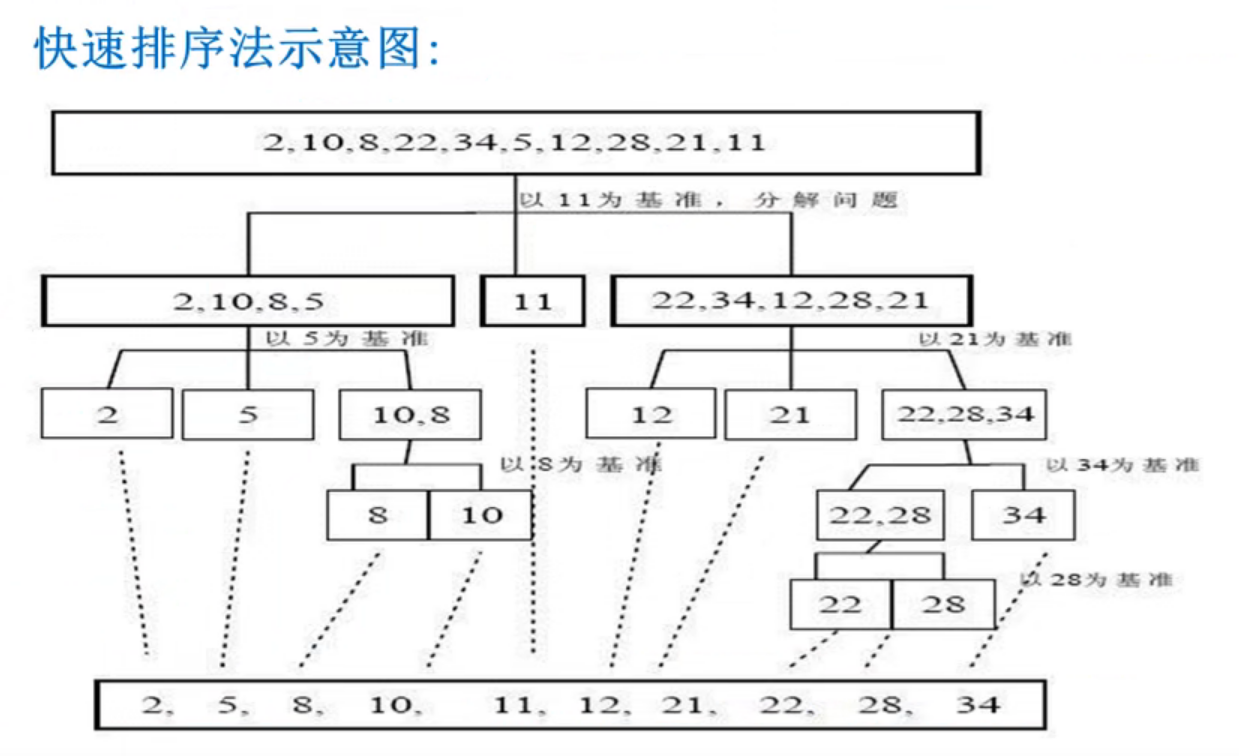
package main import ( "fmt" "math/rand" "time" ) //快速排序 //说明 //1. left 表示 数组左边的下标 //2. right 表示数组右边的下标 //3 array 表示要排序的数组 func QuickSort(left int, right int, array *[8000000]int) { l := left r := right // pivot 是中轴, 支点 pivot := array[(left + right) / 2] temp := 0 //for 循环的目标是将比 pivot 小的数放到 左边 // 比 pivot 大的数放到 右边 for ; l < r; { //从 pivot 的左边找到大于等于pivot的值 for ; array[l] < pivot; { l++ } //从 pivot 的右边边找到小于等于pivot的值 for ; array[r] > pivot; { r-- } // 1 >= r 表明本次分解任务完成, break if l >= r { break } //交换 temp = array[l] array[l] = array[r] array[r] = temp //优化 if array[l]== pivot { r-- } if array[r]== pivot { l++ } } // 如果 1== r, 再移动下 if l == r { l++ r-- } // 向左递归 if left < r { QuickSort(left, r, array) } // 向右递归 if right > l { QuickSort(l, right, array) } } func main() { // arr := [9]int {-9,78,0,23,-567,70, 123, 90, -23} // fmt.Println("初始", arr) var arr [8000000]int for i := 0; i < 8000000; i++ { arr[i] = rand.Intn(900000)//随机数 } //fmt.Println(arr) start := time.Now().Unix() //调用快速排序 QuickSort(0, len(arr) - 1, &arr) end := time.Now().Unix() fmt.Println("main..") fmt.Printf("快速排序法耗时%d秒", end - start) //fmt.Println(arr) }
栈
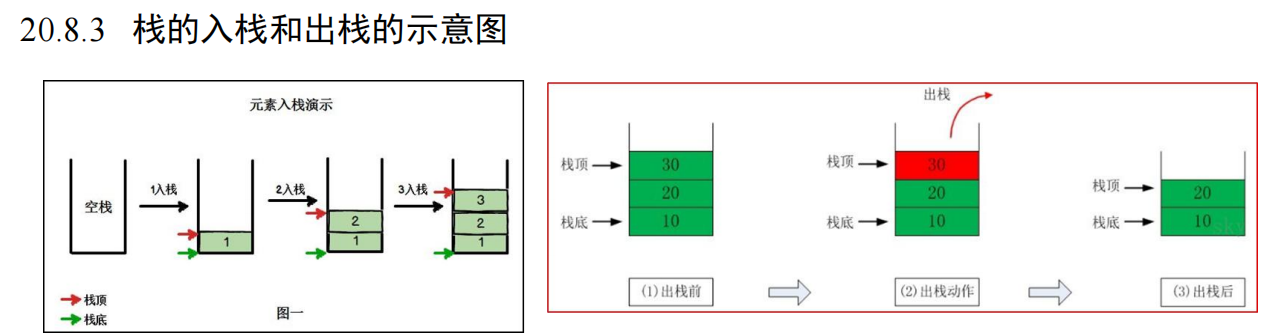
栈的介绍
1)有些程序员也把栈称为堆栈,即栈和堆栈是同一个概念
2)栈的英文为 stack
3)栈是一个先入后出(FILO-FIRST IN LAST OUT)的有序列表
4)栈是限制线性表中元素的插入和删除只能在线性的同一段进行的一种特殊线性表。
允许插入和删除的一端,为变化的一端,称为栈顶(Top),另一端为固定的一端,称为栈底(Bottom)
5)根据堆栈的定义可知,最先放入栈中的元素在栈底,最后放入的元素在栈顶,而且删除元素刚好相反,
最后放入的元素最先删除,最先放入的元素最后删除
栈的应用场景
1)子程序的调用:在跳往子程序前,会先将下个指令的地址存到堆栈中,直到子程序执行完后再将地址取出,以回到原来的程序中
2)处理递归调用:和子程序的调用类似,只是除了存储下一个指令的地址外,也将参数,区域变量等数据存入堆栈中
3)表达式的转换与求值
4)二叉树的遍历
5)图形的深度优先(depth-first)搜索法
package main import ( "errors" "fmt" ) type Stack struct { MaxTop int //表示我们栈最大可以存放数的个数 Top int //表示栈顶,因为栈底是固定的 arr [5]int //数组模拟栈 } //入栈 func (this *Stack)Push(val int)(err error) { //先判断栈是否满了 if this.Top == this.MaxTop-1{//下标从0开始的 fmt.Println("stack full") return errors.New("stack full") } this.Top++ //放入数据 this.arr[this.Top] = val return } //遍历栈,注意需要从栈顶开始遍历 func (this *Stack)List() { //先判断栈是否为空 if this.Top==-1{ fmt.Println("stack empty") return } fmt.Println("栈的清空如下:") for i:=this.Top;i>=0;i--{ fmt.Printf("arr[%d]=%d\n",i,this.arr[i]) } } //出栈 func (this *Stack)Pop()(val int,err error) { //判断栈是否为空 if this.Top==-1{ fmt.Println("stack empty!") return 0,errors.New("stack empty!") } //先取值,再this.Top-- val =this.arr[this.Top] this.Top-- return val,nil } func main() { stack :=Stack{ MaxTop: 5, Top: -1, arr: [5]int{}, } //入栈 stack.Push(1) stack.Push(2) stack.Push(3) stack.Push(4) stack.Push(5) stack.List() fmt.Println("-------------------------") //出栈 val,_ := stack.Pop() fmt.Println("出栈val=",val) stack.List() fmt.Println("-------------------------") //出栈 val,_ = stack.Pop() fmt.Println("出栈val=",val) val,_ = stack.Pop() fmt.Println("出栈val=",val) stack.List() }
结果:
栈的清空如下: arr[4]=5 arr[3]=4 arr[2]=3 arr[1]=2 arr[0]=1 ------------------------- 出栈val= 5 栈的清空如下: arr[3]=4 arr[2]=3 arr[1]=2 arr[0]=1 ------------------------- 出栈val= 4 出栈val= 3 栈的清空如下: arr[1]=2 arr[0]=1
栈实现综合计算器

package main import ( "errors" "fmt" "strconv" ) //使用数组来模拟一个栈的使用 type Stack struct { MaxTop int // 表示我们栈最大可以存放数个数 Top int // 表示栈顶, 因为栈顶固定,因此我们直接使用Top arr [20]int // 数组模拟栈 } //入栈 func (this *Stack) Push(val int) (err error) { //先判断栈是否满了 if this.Top == this.MaxTop - 1 { fmt.Println("stack full") return errors.New("stack full") } this.Top++ //放入数据 this.arr[this.Top] = val return } //出栈 func (this *Stack) Pop() (val int, err error) { //判断栈是否空 if this.Top == -1 { fmt.Println("stack empty!") return 0, errors.New("stack empty") } //先取值,再 this.Top-- val = this.arr[this.Top] this.Top-- return val, nil } //遍历栈,注意需要从栈顶开始遍历 func (this *Stack) List() { //先判断栈是否为空 if this.Top == -1 { fmt.Println("stack empty") return } fmt.Println("栈的情况如下:") for i := this.Top; i >= 0; i-- { fmt.Printf("arr[%d]=%d\n", i, this.arr[i]) } } //判断一个字符是不是一个运算符[+, - , * , /] func (this *Stack) IsOper(val int) bool { if val == 42 || val == 43 || val == 45 || val == 47 { return true } else { return false } } //运算的方法 func (this *Stack) Cal(num1 int, num2 int, oper int) int{ res := 0 switch oper { case 42 : res = num2 * num1 case 43 : res = num2 + num1 case 45 : res = num2 - num1 case 47 : res = num2 / num1 default : fmt.Println("运算符错误.") } return res } //编写一个方法,返回某个运算符的优先级[程序员定义] //[* / => 1 + - => 0] func (this *Stack) Priority(oper int) int { res := 0 if oper == 42 || oper == 47 { res = 1 } else if oper == 43 || oper == 45 { res = 0 } return res } func main() { //数栈 numStack := &Stack{ MaxTop : 20, Top : -1, } //符号栈 operStack := &Stack{ MaxTop : 20, Top : -1, } exp := "30+30*6-4-6" //定义一个index ,帮助扫描exp index := 0 //为了配合运算,我们定义需要的变量 num1 := 0 num2 := 0 oper := 0 result := 0 keepNum := "" for { //这里我们需要增加一个逻辑, //处理多位数的问题 ch := exp[index:index+1] // 字符串. //ch ==>"+" ===> 43 temp := int([]byte(ch)[0]) // 就是字符对应的ASCiI码 if operStack.IsOper(temp) { // 说明是符号 //如果operStack 是一个空栈, 直接入栈 if operStack.Top == -1 { //空栈 operStack.Push(temp) }else { //如果发现opertStack栈顶的运算符的优先级大于等于当前准备入栈的运算符的优先级 //,就从符号栈pop出,并从数栈也pop 两个数,进行运算,运算后的结果再重新入栈 //到数栈, 当前符号再入符号栈 if operStack.Priority(operStack.arr[operStack.Top]) >= operStack.Priority(temp) { num1, _ = numStack.Pop() num2, _ = numStack.Pop() oper, _ = operStack.Pop() result = operStack.Cal(num1,num2, oper) //将计算结果重新入数栈 numStack.Push(result) //当前的符号压入符号栈 operStack.Push(temp) }else { operStack.Push(temp) } } } else { //说明是数 //处理多位数的思路 //1.定义一个变量 keepNum string, 做拼接 keepNum += ch //2.每次要向index的后面字符测试一下,看看是不是运算符,然后处理 //如果已经到表达最后,直接将 keepNum if index == len(exp) - 1 { val, _ := strconv.ParseInt(keepNum, 10, 64)//将字符串转换为数字 numStack.Push(int(val)) } else { //向index 后面测试看看是不是运算符 [index] if operStack.IsOper(int([]byte(exp[index+1:index+2])[0])) {// 字符串也式切片 切片转换为 byte 取第一位 再转换为 int类型 val, _ := strconv.ParseInt(keepNum, 10, 64)//将字符串转换为数字 numStack.Push(int(val)) keepNum = "" } } } //继续扫描 //先判断index是否已经扫描到计算表达式的最后 if index + 1 == len(exp) { break } index++ } //如果扫描表达式 完毕,依次从符号栈取出符号,然后从数栈取出两个数, //运算后的结果,入数栈,直到符号栈为空 for { if operStack.Top == -1 { break //退出条件 } num1, _ = numStack.Pop() num2, _ = numStack.Pop() oper, _ = operStack.Pop() result = operStack.Cal(num1,num2, oper) //将计算结果重新入数栈 numStack.Push(result) } //如果我们的算法没有问题,表达式也是正确的,则结果就是numStack最后数 res, _ := numStack.Pop() fmt.Printf("表达式%s = %v", exp, res) }
结果:
表达式30+30*6-4-6 = 200
递归的概念
简单的说:递归就是函数/方法自己调用自己,每次调用时传入不同的变量,递归有助于编程者解决复杂的问题,
同时可以让代码变得简洁
递归需要遵守的重要原则
1)执行一个函数时,就创建一个新的受保护的独立空间(新函数栈)
2)函数的局部变量式独立的,不会相互影响,如果希望各个函数栈使用同一个数据,使用引用传递。
3)递归必须向退出递归的条件逼近,否则就是无限递归,死归了
4)当一个函数执行完毕,或者遇到return,就会返回,遵守谁调用,就将结果返回给谁,同时
当函数执行完毕或者返回时,该函数本身也会被系统销毁


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?