论文笔记-StableCascade
资料
- paper:
a. arxiv:http://arxiv.org/abs/2306.00637
b. ICLR版本:https://openreview.net/pdf?id=gU58d5QeGv - stability.ai版本(模型效果更好?)
a. code:https://github.com/Stability-AI/StableCascade/
b. huggingface model:https://huggingface.co/stabilityai/stable-cascade - wuerstchen原始
a. Wuerstchen:https://github.com/dome272/wuerstchen/
b. huggingface model:https://huggingface.co/dome272/wuerstchen
简介
文生图中,当前主要有两类方法,encoder-based和upsampler-based,具体的:
- encoder-based:将像素空间转为低维latent空间,训练扩散模型,再decoder到像素空间,代表作如:SD系列、DALL-E、CogView、MUSE等
- upsampler-based:将像素空间转为低维latent空间,训练扩散模型,并直接生成低维像素空间图像,再用模型upscale,如Stable UnCLlip、Imagen
当前,生图质量好的模型(如sd2.x、SDXL等)其训练成本大、推理耗时长,主打轻量快速的模型(如sdxl turbo等)生图质量仍有待提升;在扩散模型中,latent space的大小对训练、推理速度影响也至关重要,因此该方法从降低latent space大小上入手(提高压缩比)。
论文详情
方法
概述
- 动机:提升文生图质量,降低训练资源消耗
- 方案:设计三阶段框架(Wustchen,两个LDM和一个image decoder),使得latent space压缩比最大到42x(1024->24),加速训练和推理
![框架设计]()
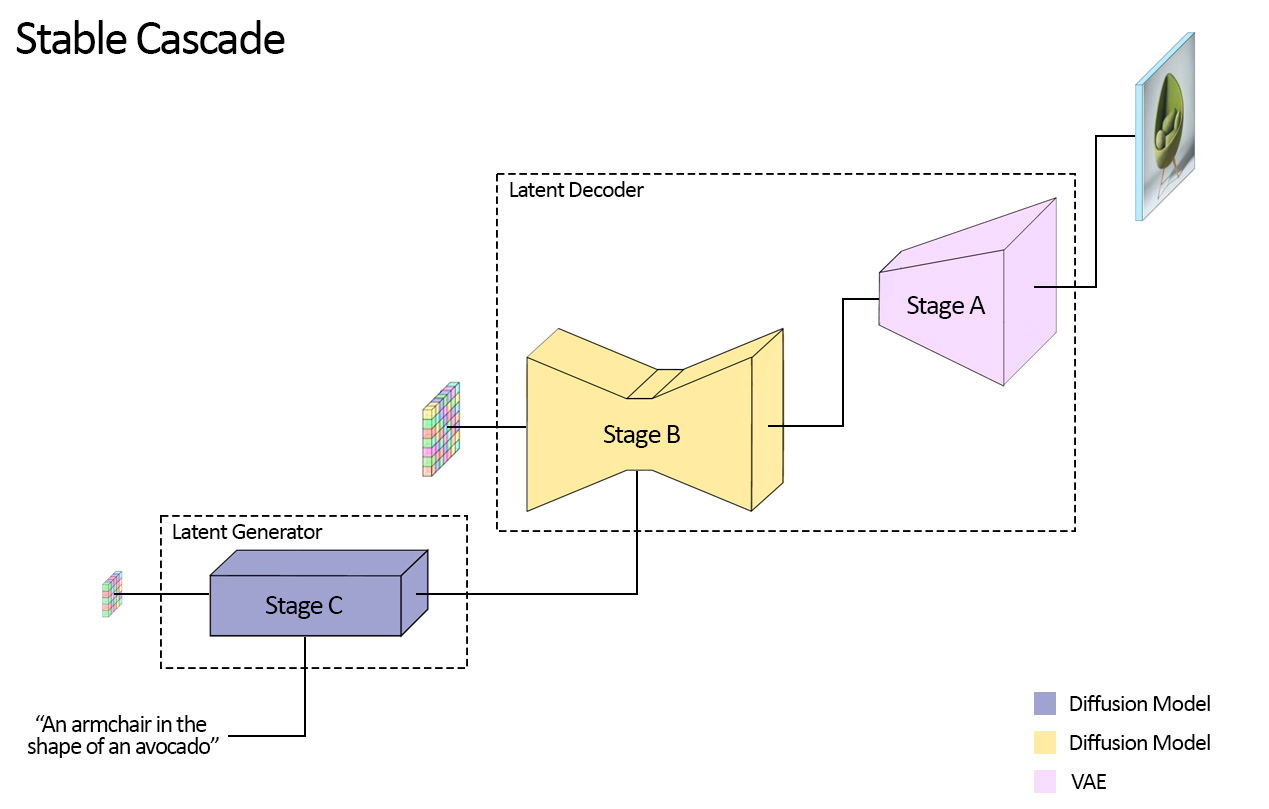
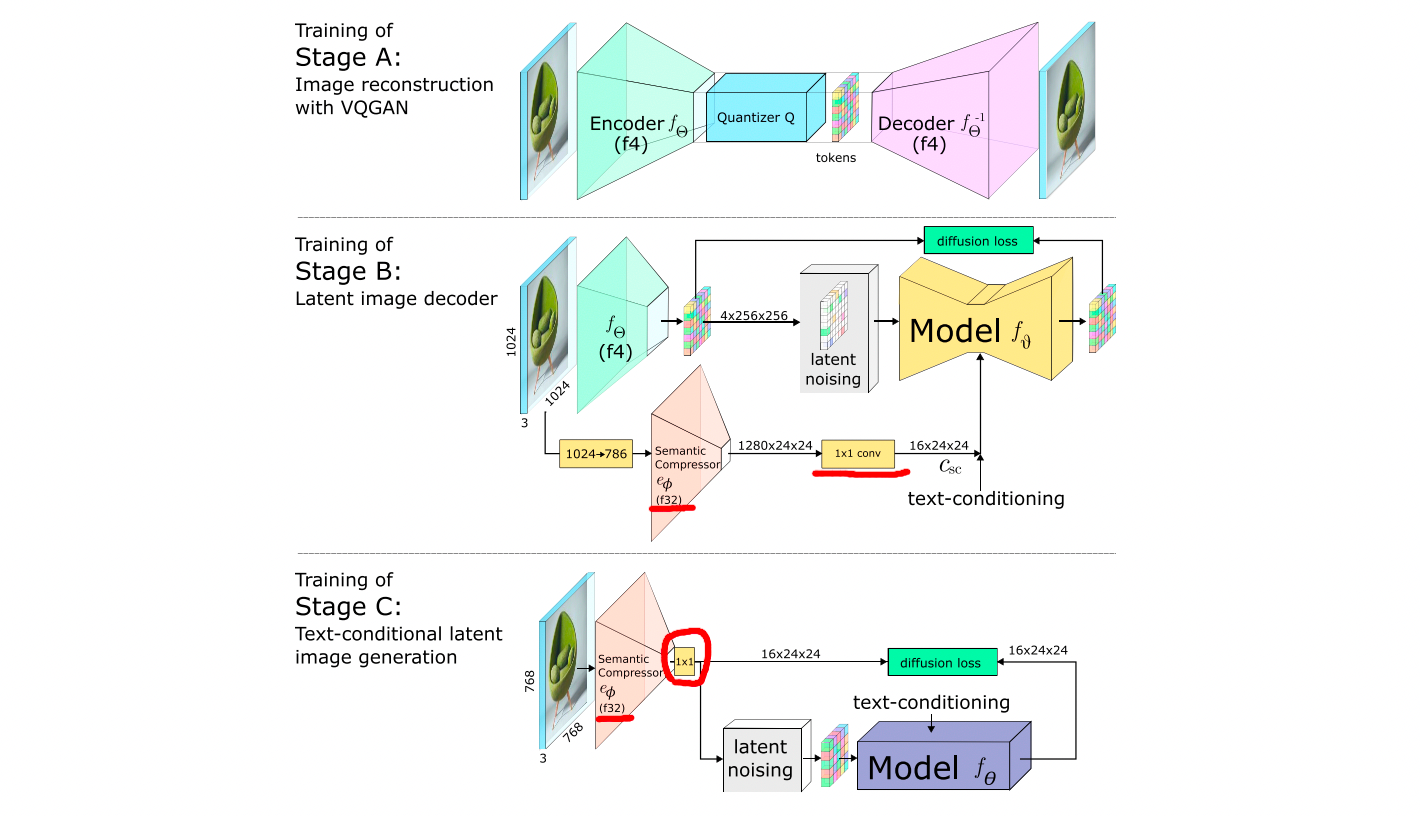
训练
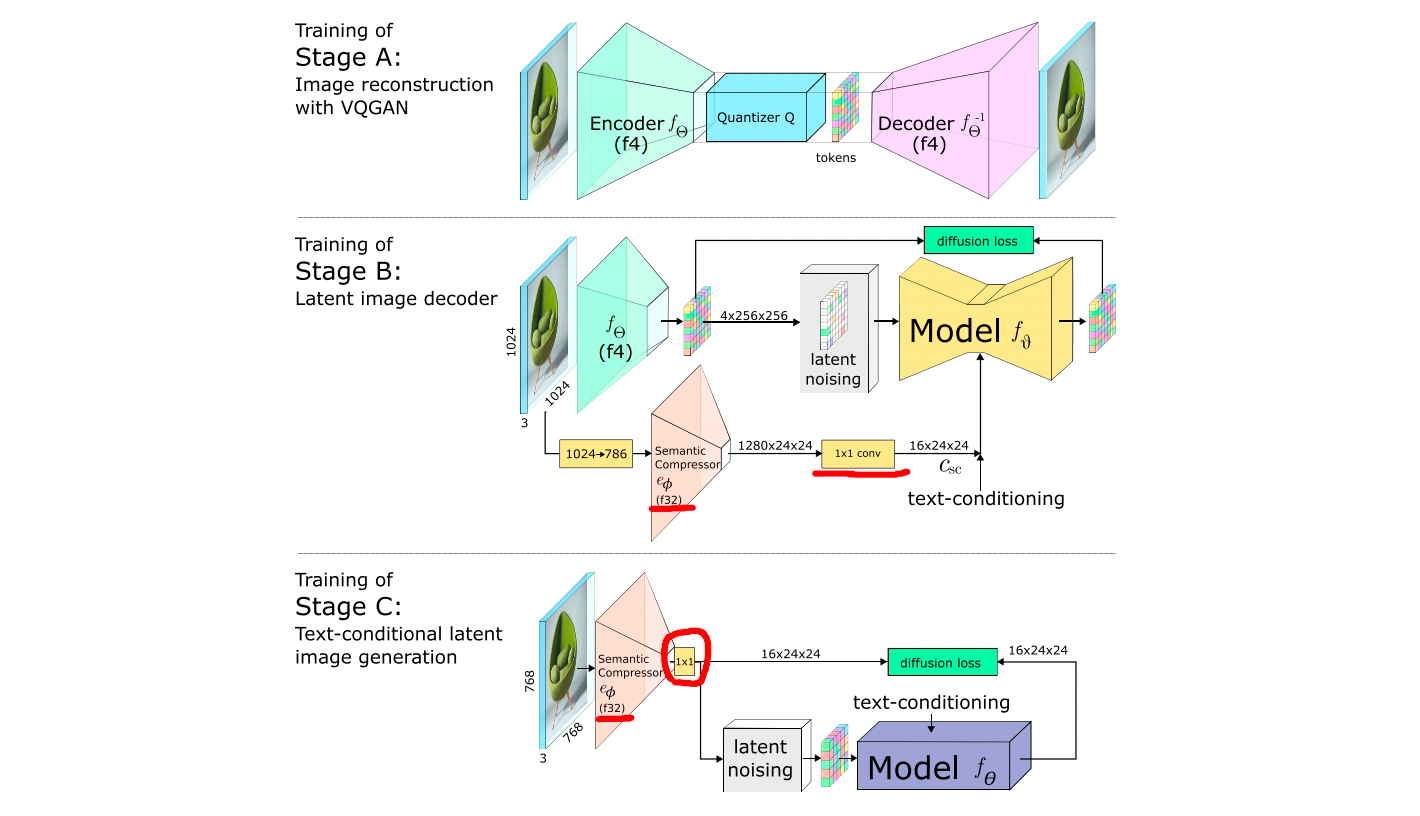
- 顺序:StageA -> StageB -> StageC
- StageA:图像重建任务,VQGAN,压缩比4x(训练后,在后续的操作中就丢弃量化操作)
a. 输入:原图
b. 输出:重建后的图像,保留encoder和decoder
c. Loss:MSE、AL(Adverserial loss)、PL(Perceptual loss) - StageB:有条件latent image decoder任务,在4倍压缩比的latent空间训练diffusion模型
a. 输入:
i. A encoder得到的img emb并加噪(类似引入image prompt)
ii. 原图经过SC得到的img emb(原图resize到786,适配原始的SC模型)
iii. text emb
b. 输出:latent emb
c. Loss:diffusion loss - StageC:有条件text-to-image任务,在42倍压缩比的latent空间训练diffusion模型
a. backbone:16 ConvNeXt-block(无downsampling)
b. 输入:
i. 原图(1024x1024 resize到 768x768)经过SC提取img emb并加噪
ii. text emb(OpenCLIP ViT-G,token emb(77x1280) + pooled emb(1x1280))
c. 输出:
i. latent emb
d. Loss:优化后的diffusion loss,p_2(t) || \epsilon - \hat{\epsilon} ||^2
i. 预测噪音优化为:\hat{\epsilon} = \frac{\bold{X_{sc,t}} - \bold{A}}{|1-\bold{B}| + 1e^{-5}}
ii. 引入p2 loss weighting:噪音更大时权重更大,p_2(t) = \frac{1-\hat{\alpha_t}}{1+\hat{\alpha_t}} - Semantic Compressor:微调(只在Stage C阶段),注意:
a. backbone:EfficientNetV2 S
b. 在StageB阶段SC的emb也会随机加噪
推理
- 顺序:Stage C -> Stage B -> Stage A
- StageC:扩散模型,压缩比42:1
a. 输入:noise、text emb
b. 输出:latent emb - StageB:扩散模型,压缩比4:1
a. 输入:noise、text emb + C输出的latent emb
b. 输出:latent emb - StageC:VQGAN的decoder
a. 输入:B输出的latent emb
b. 输出:图像
实验
数据
- 训练:improved-aesthetic Laion-5B的子集(5B过滤后保留103M)
- 评测:
a. 数据:COCO-30K、Parti-prompts( https://github.com/google-research/parti )
b. 指标:FID、PickScore(https://github.com/yuvalkirstain/PickScore (PickScore开源pairwise的数据,可作为相关训练数据)) - 训练方式:
a. StageA:VQGAN,256x256,三个Loss,MSG、Adverserial Loss、Perceptual Loss
b. StageB:Unet(ConvNeXt),递进式训练(2次,512x512 -> 1024x1024)
c. StageC:Unet(ConvNeXt),递进式训练(4次,12x12 -> 24x24 -> 不同分辨率训练 -> 专业人士进一步过滤美观度后的数据训练 -> 模型插值(3和4 50:50插值,模型未公布))
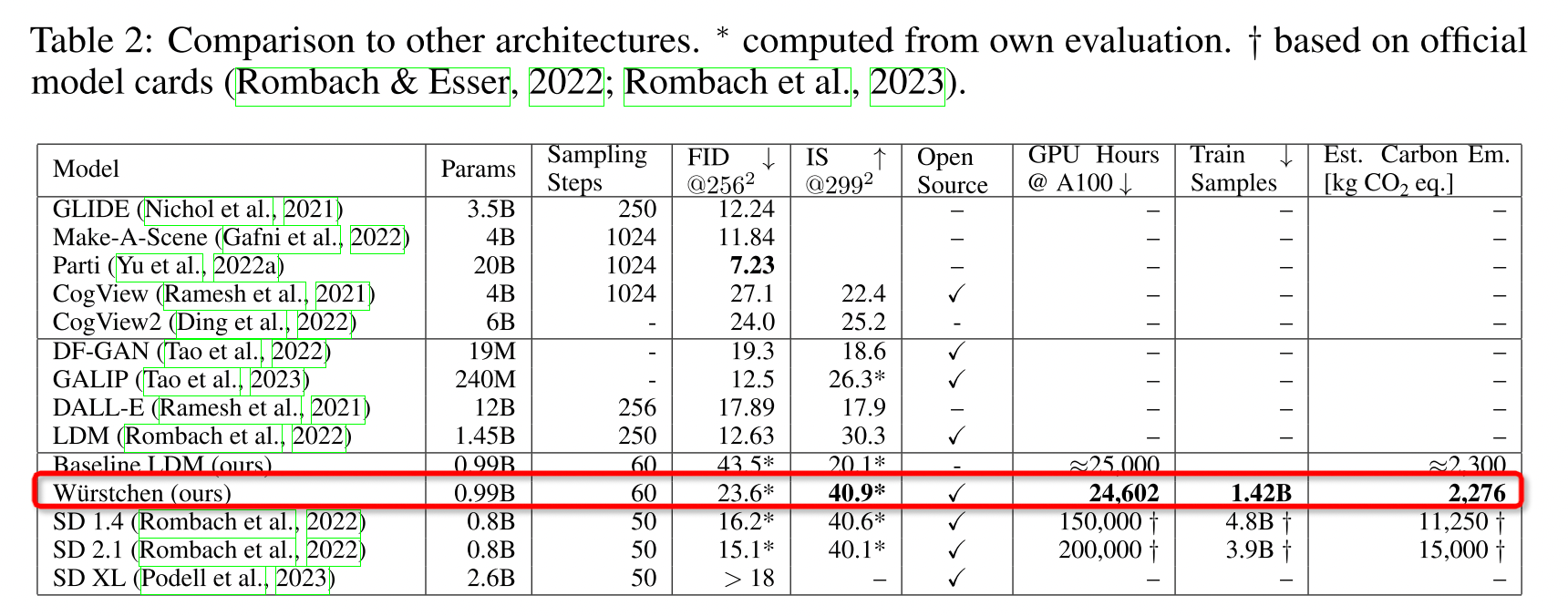
评测指标
-
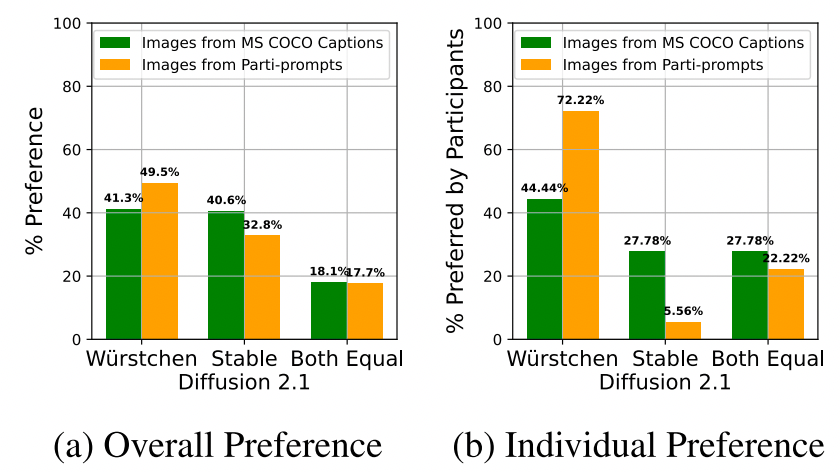
生图效果
![]()
![]()
![]()
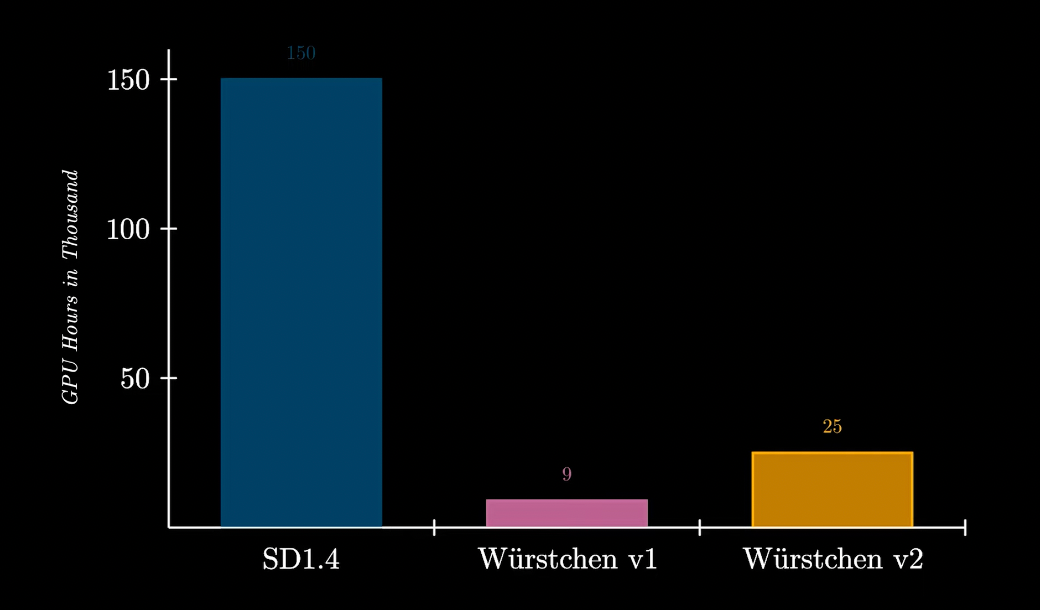
-
训练成本(v1:512x512,v2:1024x1024)
![]()
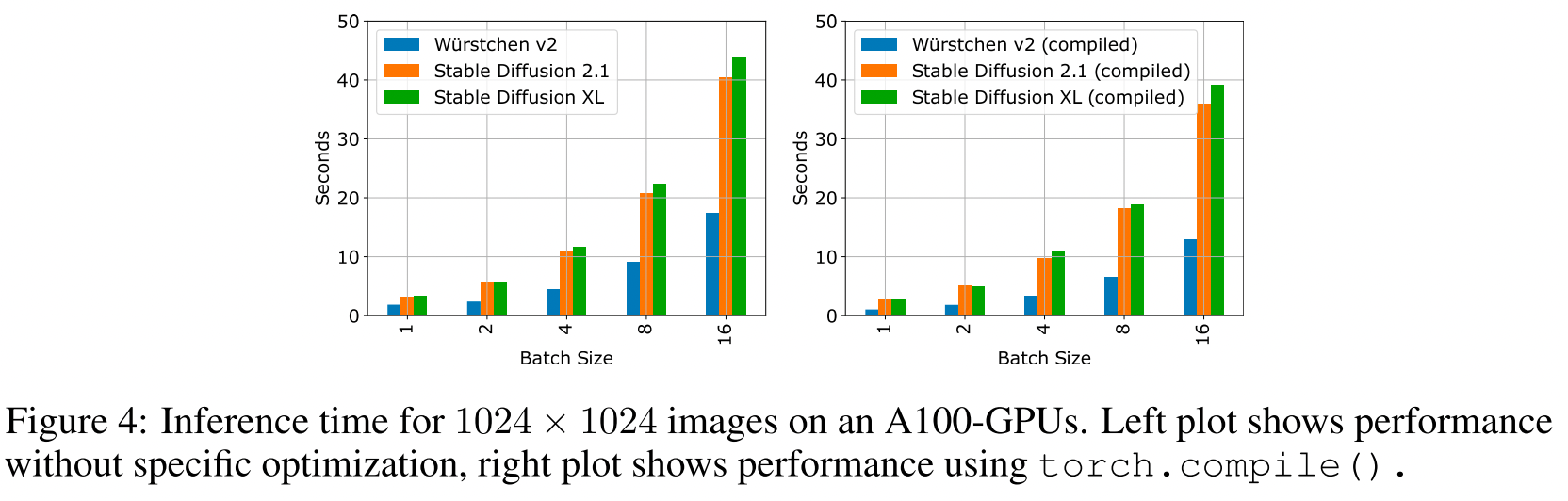
-
生图速度
![]()
![]()
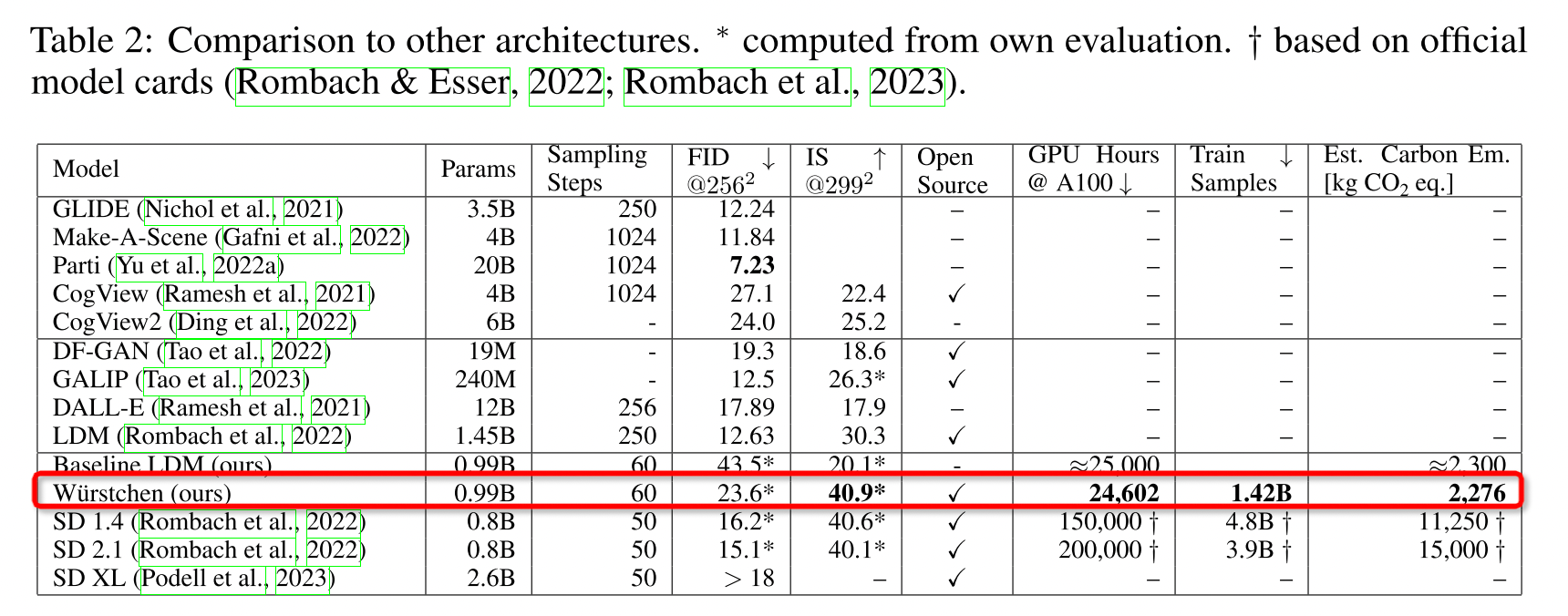
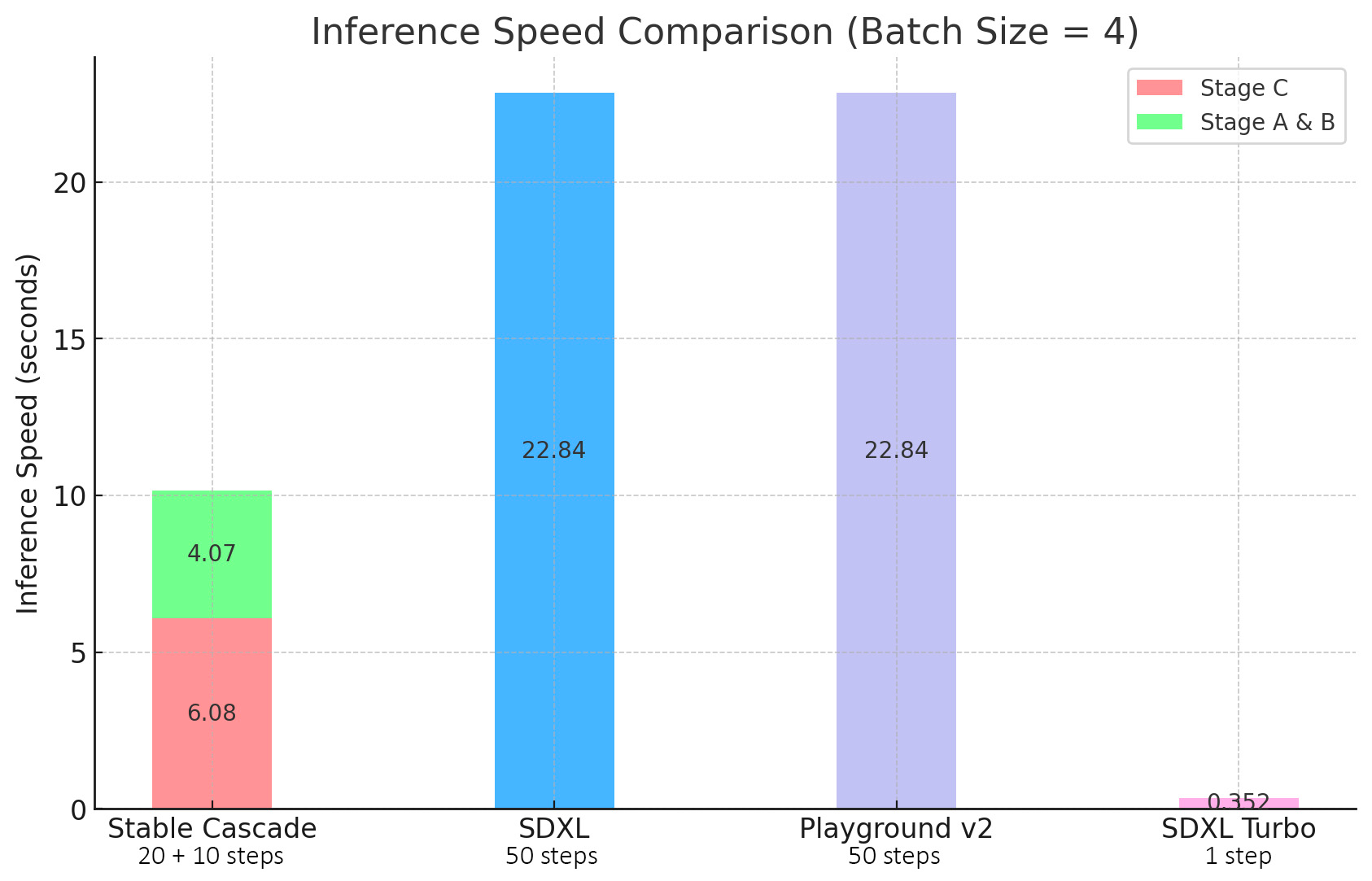
消融实验
- StageB和StageC的区别:StageC是文生图的关键,StageB是refiner精修效果;因此,训练controlnet、lora等只需要训练StageC即可
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号