论文笔记-ERFNet: Efficient Residual Factorized ConvNet for Real-time Semantic Segmentation
paper: ERFNet: Efficient Residual Factorized ConvNet for Real-time Semantic Segmentation
code: PyTorch
Abstract
- ERFNet可以看作是对ResNet结构的又一改变,同时也是对ENet的改进。相对ENet,其网络结构的改进,一方面是将residual module改成non-bottleneck module,同时内部全部使用1D的cov(非对称卷积)。另一方面,移除encode中的层和decode层之间的long-range链接,同时所有的downsampling模块都是一组并行的max pooling和conv。
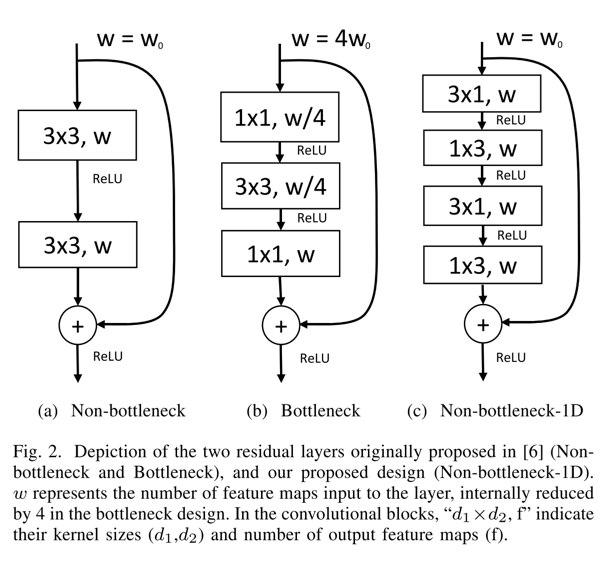
- ERFNet的non-bottleneck module示意图如下:
![]()
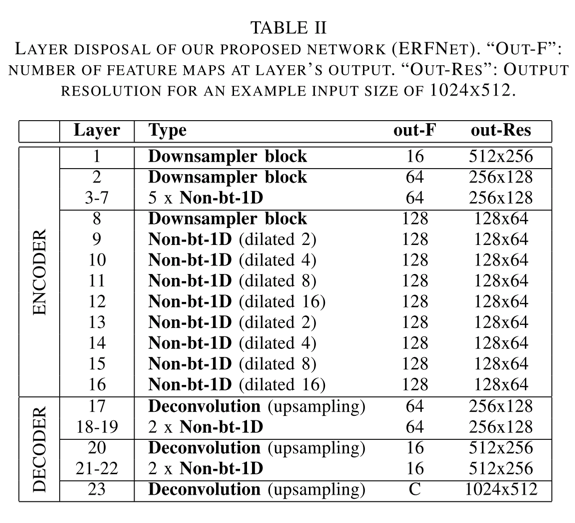
- ERFNet的整体网络结构示意图如下:
![]()
- 由整体网络结构可以发现,ERFNet也是encode较大、decode较小的模式。encode模块全部有non-bottleneck module组成,且每个non-bottleneck module的第二组非对称卷积都用到了不同比例的dilated conv
Details
- 为什么选择non-bottleneck module?为什么在non-bottleneck module中全部使用非对称卷积?
- 前者,论文中一言以蔽之:随着网络深度的增强,non-bottleneck的ResNet是能够比bottleneck获得更大的accuracy的(但是论文中,表格3可以看出,实际只在validation数据上有一处是non-bottleneck结构的精度比bottleneck结构高的,但是模型参数和inference time均减少了不少)
- 如上一条最后所述,将标准的conv转成两个非对称conv的组合,能够降低参数量,且提速很多,同时精度也不会有很多损失。(论文中,也理论分析了一下)
- 同时,作者也阐述了,这种non-bottleneck-1D结构,也同样可以迁移到其他任务中,且取得不错的效果
- 模型结构
- 模型也是Encode-Decode结构,前者较大,后者较小。同时,Encode模块主要有non-bottleneck-1D和downsampling模块组成,Decode模块主要有upsampling和non-bottleneck-1D模块组成。
- non-bottleneck-1D模块大部分都采用了dilated conv。注意,不同层dilated conv的dilated rate不同,而且,都是non-bottleneck-1D的第二组非对称conv中使用的。(这应该是能够一定程度上规避dilated conv的棋盘效应)
- downsample全部是一组并行的maxpooling和conv操作
- decode模块就是简单的deconv操作
- 评估准则和训练方式
- 使用的是IoU标准,即\(IoU = TP / (TP + FP + TN)\)
- 训练方式:
- 作者的训练过程分为两步,第一步是训练encode模块,第二步是训练decode模块。而Encode模块的训练,又实验了两种,一种是from scratch,一种是pretrain,结果对比如下:
![]()
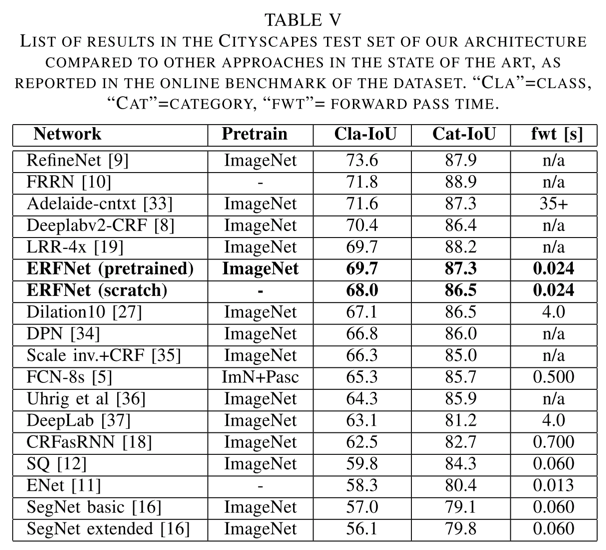
- 和其他模型的对比如下(在同等精度下,速度具有很大的优势):
![]()
- 作者的训练过程分为两步,第一步是训练encode模块,第二步是训练decode模块。而Encode模块的训练,又实验了两种,一种是from scratch,一种是pretrain,结果对比如下:

写在后面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号