论文笔记-ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
paper: ENet: A Deep Neural Network Architecture for Real-Time
code: caffe
Abstract
- ENet是16年初的一篇工作了,能够达到实时的语义分割,包括在嵌入式设备NVIDIA TX1,同时还能够保证网络的效果。整体结构是Encode-Decode的形式,但是其Encode部分和Decode部分是有链接的,类似于UNet,将Encode中的某一层执行deconv,然后和Decode过程中相同大小的层融合到一起(element-wise)。
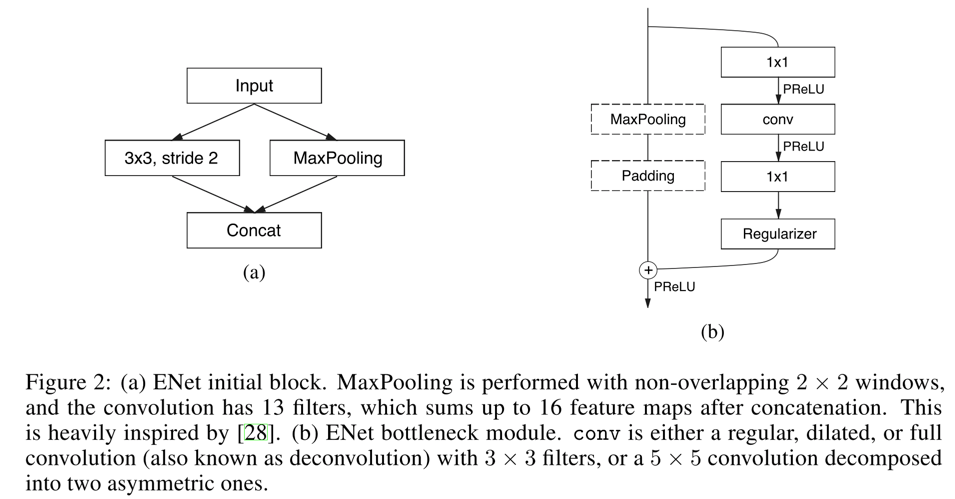
- ENet的基础模块包括如下图中的两部分
![]()
- 图a,是网络的初始化阶段的结构,并行的conv和pool
- 图b,是网络的后续结构的基本组成单元,相对于也是ResNet的变种,左侧虚框包围的maxpooling和padding两层,是代表不是每一个单元skip connection时都加入这个层了
- 整体的网络结构如下表格所示:
![]()
- initial阶段就是上面说的图a
- stage1是5个普通的bottleneck结构;stage2中,加入了dilated conv,同时有两个bottleneck结构中把\(3\times\)conv改成非对称的\(5\times1\)和\(1\times5\)的conv;stage3和stage一致,只是不会进行降采样
- stage4和stage5是decode的组成部分

Details
如下的细节分析,根据论文中讲述的细节进行讨论
- feature map resolution
- 大的feature map对精度提升有帮助,但同样需要较大的内存。最终,用dilated conv保证大的感受野和小的内存占用
- early downsample
- 作者认为,encode模块应该更关注于提取更加鲁棒的特征,而不用关注分类的效果。因此,ENet在前面两个bottleneck结构就把input size降到很低来,同时使用较少的kernel个数。(作者在Cityscape数据上测试将前几层的kernel个数从16改为32,并没有很明显提升精度)
- decode size
- 作者认为,decode模块主要功能是finetuning一些细节,所以不需要将decode模块像SegNet一样和Encode模块完全的对称。最终的ENet结构,encode模块较大,decode模块较小
- nonlinear operation
- ENet用PReLU代替ReLu,个人没太理解作者的分析
- information-preversing dimensionality changes
- 将串行的conv和pooling改成并行的形式,如论文所述,这种方式能够将initial block的前向过程提速10倍左右,非常amazing
- ResNet的bottleneck模块的第一个conv是\(1 \times 1\)的,为了能够把更多的信息带入进来,ENet的bottleneck模块的第一部分,都是采用的\(2 \times 2\)的conv
- factorizing filters
- 使用非对称卷积降低参数,同时还能提速
- dilated conv && regularization
- dilated conv增大感受野,不多说了
- regularization,ENet在执行element-wise操作前使用了Spatial Dropout
- 结果
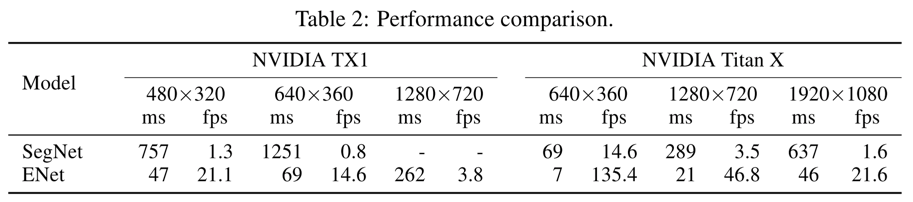
- ENet的速度比SegNet快了很多,同时模型的参数量也降低了很多很多
- 速度比较
![]()
- 参数量比较
![]()

写在后面
- ENet对嵌入式设备很友好的,保证精度的同时,提升速度,同时模型的参数量也很小

 浙公网安备 33010602011771号
浙公网安备 33010602011771号