论文笔记-FCOS: Fully Convolutional One-Stage Object Detection
paper: FCOS: Fully Convolutional One-Stage Object Detection
code: https://github.com/tianzhi0549/FCOS/
Abstract
- FCOS是ICCV2019的一篇anchor-free的one-stage目标检测工作,coco minival上能够达到40.3mAP和47FPS。所谓的anchor-free,即在该方法中不需要对具体每个位置提前设置多种anchor box,然后再去判断这些anchor box那些最准确之类的,而是直接将最终输出的feature map的一个点作为训练样本,回归目标的位置和类别信息。
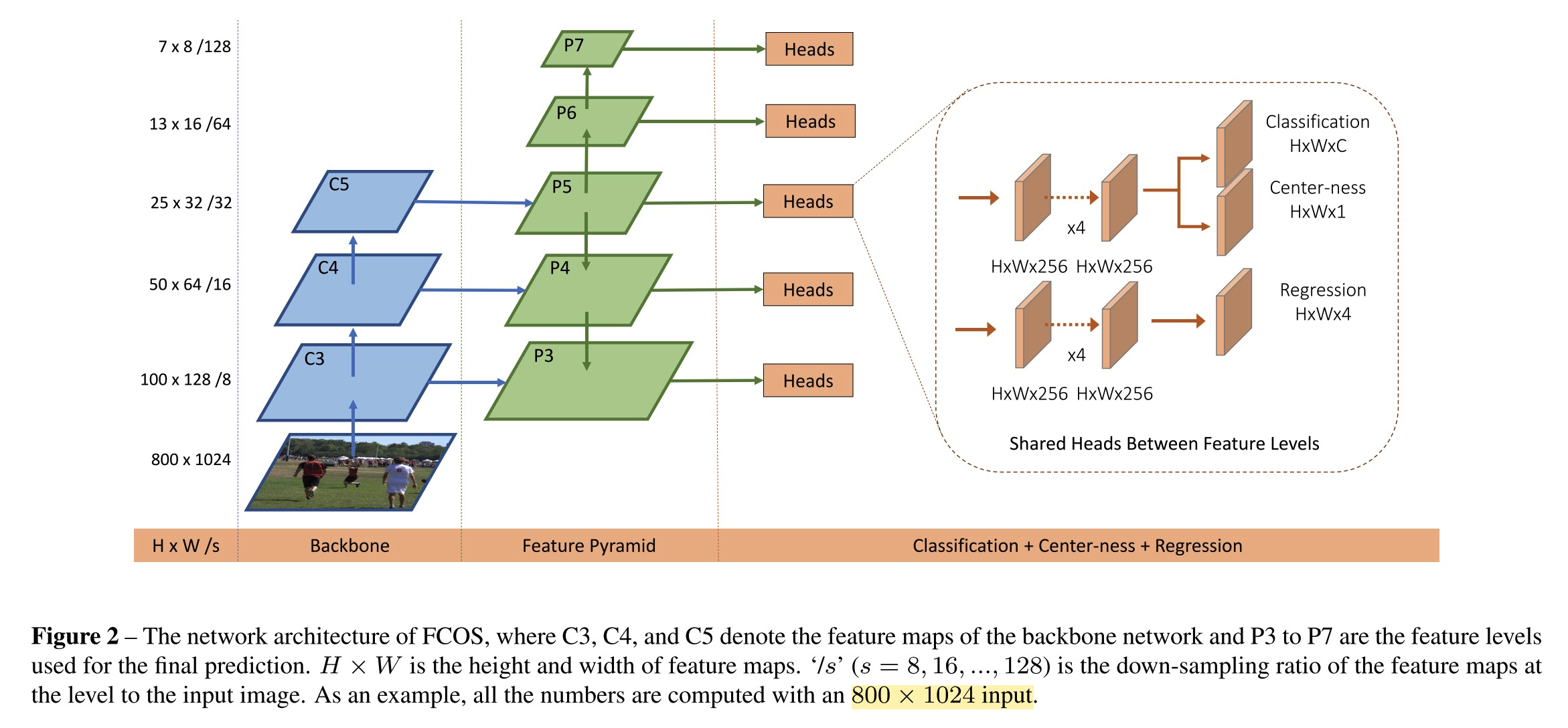
- 整体的网络框架结构如论文图示,见下图:
![]()
Details
下面根据个人的理解,逐步分析论文如何实现不需要anchor box便能够实现目标检测的,以及如何处理这种改变方式带来的问题
-
如用anchor box,网络如何区分样本并训练的?
- 先考虑网络的backbone的输出是只有一个尺度的feature map(即上面框架图中的一个level),feature map的维度是\(H \times W \times C\)
- FCOS是将fm中的每一个位置\((x, y)\)当作训练样本,如此,便引来一个问题,如何对这个训练样本打标签?
- anchor-based的方式则是以这个点作为一批anchor box的中心点,然后去匹配anchor box
- 为解决上述的打标签问题,FCOS的做法是,依据位置\((x, y)\)和所有gt的位置关系进行处理,即如果该点落在任意一个gt框内,则该点就作为正样本,对应的目标类别就是gt的类别,不然就是负样本。但是,如此又带来一个问题,如果目标离得比较近,可能会该位置点回落在两个gt框中,如何处理?
- anchor-based的方式,是根据目标框和anchor box的IoU来确定anchor box是正样本还是负样本的,这样使得anchor-based方法中的正样本数量并不多。
- 为进一步解决上面的问题,FCOS按如下的方式进行优化:
- multi-level feature,如上图所示,类似于FPN的结构(只不过\(P_6\)和\(P_7\)层是直接从\(P_5\)进行降采样得到的)。
- 首先,计算预测所有位置点在在所有level的特征图上的距离(即该点到框的四边的距离,加下文)
- 其次,预先给每个level分配了其所应该负责的目标distance最大值,如果某个位置的点预测的目标在当前level的fm上大于其能够预测的最大距离,那么该level上这个点就是负样本
- 这里,作者认为如果一个点落在两个框内,只有这两个框不代表同样的类型时,才是ambiguous samples,因为如果是同样的类型,无论匹配哪一个,都不算错
- 最后,如果通过上面一步还是会存在一个点落在两个以上的gt框内的情况,则直接选择gt框面积最小的进行匹配。
- 作者在实验分析中表明,选择面积最小的框,这样只会导致存在漏掉大目标框的风险,但是大目标的检测应该相对会更容易一些的
- multi-level feature,如上图所示,类似于FPN的结构(只不过\(P_6\)和\(P_7\)层是直接从\(P_5\)进行降采样得到的)。
- 解决了预测目标的label的问题,还有一个问题需要解决,即,上面只是找到了目标的一个位置,但是并没有确定目标的具体位置和size。因为打标签时,落在gt内的点都算是这一类,那么一个gt框内会有很多个点,希望网络预测的目标具体处在什么位置才能更好呢?
- 答案:希望预测的目标中心点处于gt框的中心点。这一个优化对性能提升很大。如下图:
![]()
- 因此,作者在网络的输出中加入了一个4D的特征向量\((l, r, t, b)\),表征该位置距离gt框四边的距离(前文所述的每一个level的fm所能预测的最大距离便是用来限制这四个值中的最大值的)
- 同时,作者引入centerness的loss,用于惩罚网络输出,使得拟合的目标点更加趋近于实际目标的中心点,实际公式如下,采用BCE loss。
![]()
- 答案:希望预测的目标中心点处于gt框的中心点。这一个优化对性能提升很大。如下图:
-
网络输出
- 如上面图例所示,最终的网络输出包含两个分之,一个分类、一个回归,然后分类分支中包含一个类别预测的分支,一个centerness的得分分支
- 训练时,centerness的分支是用BCE loss进行训练的
- 测试时,对所有预测出来的框按照置信度排序时,使用的是预测的类别得分和centerness得分的乘积
- 如上面图例所示,最终的网络输出包含两个分之,一个分类、一个回归,然后分类分支中包含一个类别预测的分支,一个centerness的得分分支
-
其他
- 实际inference时,会再执行一次nms,把每个点中的多余的框过滤掉
- 同FPN和RetinaNet一样,FCOS也是不同level之间共享了网络中的heads部分的参数,但是最终的激活输出,从\(exp(x)\)改成了\(exp(sx)\),即增加了一个学习的参数去微调每一个level的输出
- 再者就是一些实验细节了,这里不再赘述

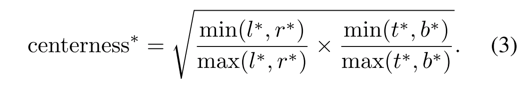
写在后面
- 这里引用FCOS中论文的分析,对比一些anchor-based方法和anchor-free方法
- anchor-based方法,因为引入了anchor,所以对anchor的size/scale/aspect ratio等参数比较敏感(yolo v2后开始使用聚类的方式设计这些参数);再者,即便精巧的设计好anchor,对应形状变化差异较大的新目标,anchor-based的方法还是心有余而力不足;其次,anchor-based的方法都需要设计大量的anchor,但是实际使用时这些anchor大部分都是negative sample,导致正负样本比例失衡;最后,anchor-based方法频繁的IoU等操作也是占用算力的
- 一顿“批判”anchor-based的不足后,引入anchor-free的方式,这里的FCOS其实是采用semantic segmentation的方式进行dense prediction。尽管他不需要面对前面所述的anchor-based方法的各种问题,但是如果图像中目标较为密集的话,anchor-free应该也是心有余力不足的
- 个人愚见,万事万物最后都是走向大道至简的,所以。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号