论文笔记-ResNeSt-Split-Attention Networks
paper: ResNeSt: Split-Attention Networks
code: ResNeSt Mxnet&PyTorch版本
Abstract
- ResNeSt是对ResNext的又一个魔改的变种,亚马逊李沐团队的作品,其中S代表split,可以理解为按channel切分的feature map。ResNeSt是在ResNeXt的cardinality基础上又引入一个radix(R),来表示每个cardinality group中的split的个数
- 简单理解,ResNeXt的cardinality将一组channel分成不同的组(这里称为cardinality group),ResNeSt是将一组cardinality group中的channel分成不同的split
- 从实验结果上开,效果还是很amazing的
- ResNeSt-50在ImageNet上的top-1 error为81.13%,超过ResNet-50大概1%
- ResNeSt-50替换Faster rcnn中的backbone,coco的mAP从39.25%提升到42.33%
- ResNeSt-50替换DeepLabV3中的backbone,ADE20K上的分割mIoU从42.1%提升到45.1%
Details
Split-Attention
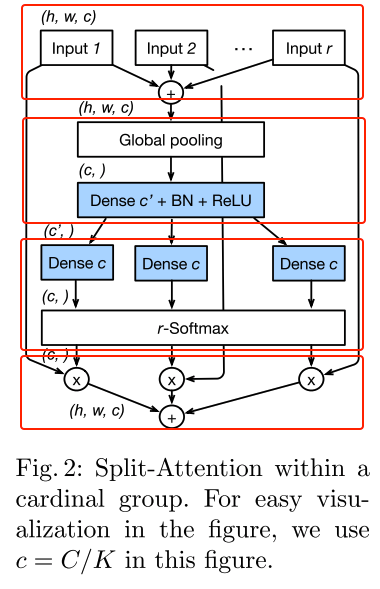
- 按照个人的理解,将每个cardinality group中的split-attention拆解为四个关键步骤,如下图中的4个红框
![split-attention]()
- 其实,最主要的就是名字所述的一个是split的过程(第一个红框)、一个是attention的过程(剩下3个红框)
- 注:准确的说split应该对应论文中的图一右图,而这里第一个红框部分是每个split经过一些transfromation(\(1\times1\) conv + \(3\times3\) conv)后的输出
- step1,将该cardinality group的输入分成r个split,每个split经过一些变换后,进入到split-attention中,先用element-wise sum的方式将特征图融合到一起(输出维度:\( H \times W\ times C\))
- step2,将融合后的feature map指向global average pooling,即将图像空间维度压缩(输出维度:\( C \) )
- step3,结合softmax计算出每个split的权重
- 图中的dense c实现方式是用两个全连接层
- step4,将每个split-attention模块输入的每个split的feature map和计算出来的每个split的权重相乘,得到一个cardinality group的weighted fusion(输出维度:\( H \times W\ times C\))
- 其实,最主要的就是名字所述的一个是split的过程(第一个红框)、一个是attention的过程(剩下3个红框)
- 可见,split-attention其实就是给每一组split的feature map计算其对应的权重,然后再融合。
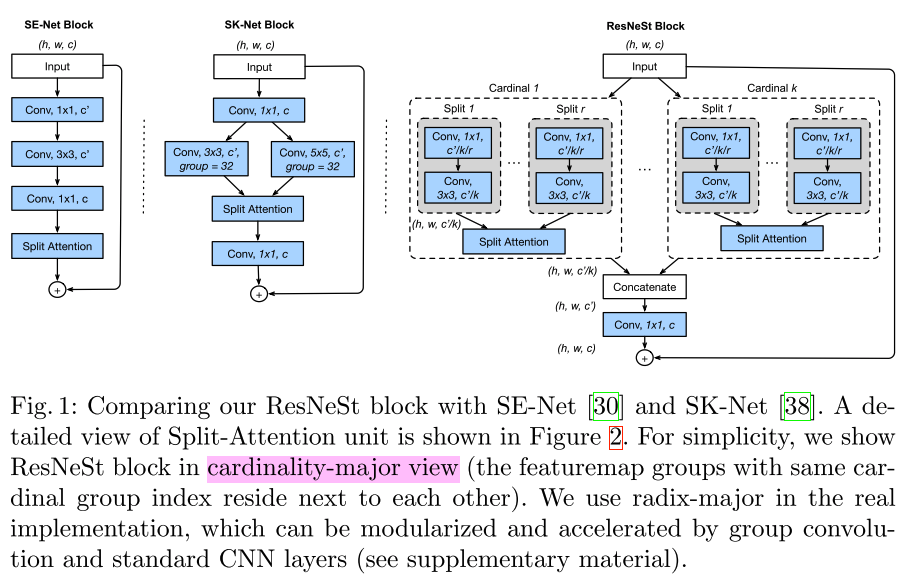
ResNeSt Block
- ResNeSt block的流程如下
- 将输入的所有feature map分成不同的cardinality group,
- 然后,每个cardinality group再分成不同的split,
- 然后,再用split-attention计算每个split的权重,再融合后作为每个cardinality group的输出,
- 然后,将所有的cardinality group的feature map在channel维度concate到一起,
- 然后,再执行一次conv(改变channel个数)用skip connection将ResNeSt Block的原始输入特征融合进来(融合方式为element-wise sum)。具体实现如下图:
![]()
实现细节及技巧
- 使用的resnet结构是ResNet-D,结构如下
![]()
- 训练策略
- large mini-batch distributed training
- label smoothing
- auto augmentation
- mixup training
- large crop size: 224(ResNet变种对比),256(和其他模型对比)
- Regularization: Dropout、DropBlock、weight decay
- cosine schedule
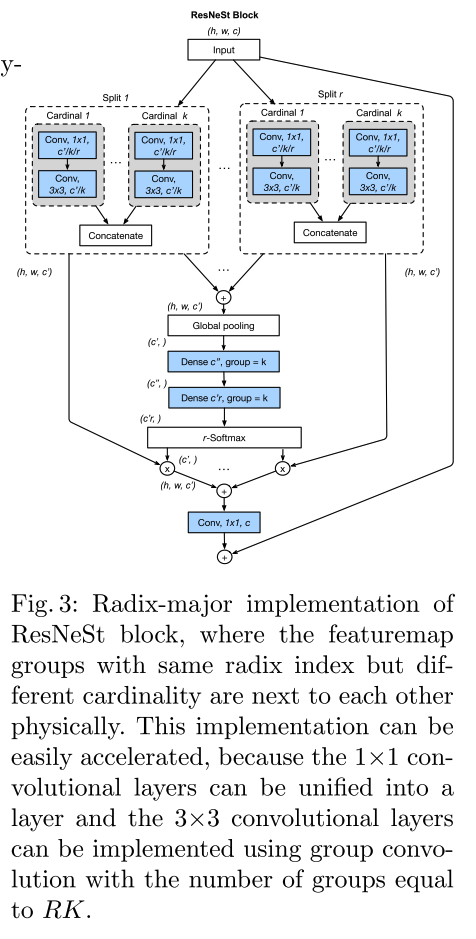
- 实际实现时用的是radix-major的方式,这种方式的话,计算起来更方便一些(这样布局,相同radix-index的group在内存中布局一样),从布局上看相对于把前面图中的cardinality和split两个转换一下,如下图
![]()
写在后面
- 看ResNeSt,以及其他一些最新的文章,都能够看到attention的身影,给每个feature map分配一个权重,想到以前用传统方法做多模态目标跟踪的权重融合方式,何其相似。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号