

论文笔记-HRNet-Deep High-Resolution Representation Learning for Visual Recognition
paper: Deep High-Resolution Representation Learning for Visual Recognition
code: HRNet
Abstract
-
HRNet,这里用的是PAMI2020的工作,整合了human pose estimation、object detection、semantic segmentation、image classification、facial landmark detection等多个视觉任务,目前Cityscapes test的分割任务中,精度最高的是HRNetV2+OCR,参考这里。下文会以semantic segmentaion的HRNetV2为主
-
主流的网络结构一般是多个conv实现encode(得了low-resolution的fm),再用deconv进行decode(得到high-resolution的fm),HRNet的pipeline是在网络整个处理过程中始终保持high-resolution的fm,同时并行加入encode的low-resolution的fm,框架图如下:

- 上图是HRNet-Semantic-Segmentation里的插图,论文中的是插图是作为backbone的结构,即不同的视觉任务,在这个backbone后面加上对应的后续处理操作即可,原文backbone如下
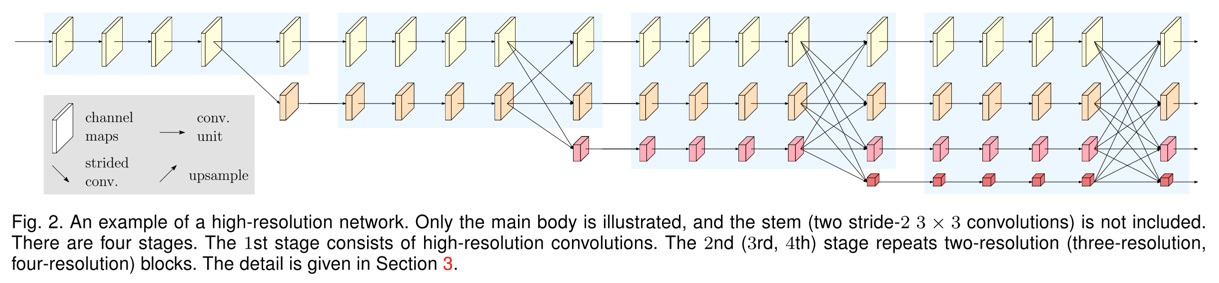
- 上图是HRNet-Semantic-Segmentation里的插图,论文中的是插图是作为backbone的结构,即不同的视觉任务,在这个backbone后面加上对应的后续处理操作即可,原文backbone如下
Details
-
HRNet的结构
- 整体深度看,HRNet由4个stage组成,每个stage中的每部分都是由N个bottleneck的residual unit组成和一个用于改变channel个数\(3\times3\)的conv组成(代码中4个stage中,每个branch的N都是4)
- HRNetV2的backbone的总conv层数大概是:\((4+8+12+16)\times 3 + (2+3+4+4) = 133\)(这个计算没有考虑每个stage的输出fuse所涉及到的conv和deconv个数)
- 整体宽度看,HRNet每个stage的宽度数不同,stage1只有一个branch,stage2有2个branch(一个high-resolution的branch,一个resolution缩小一倍的branch),而两个branch只在最后一个residual unit的输出才会有交互(fm之间互相concate,具体concate方式见下文),以此类推,stage4中有4个branch。(这里说的branch等同于论文中的不同resolution)
- 最终输出,stage4的4个branch的输出channel个数依次为C/2C/3C/4C(代码中为:32/64/128/256)
- 对于不同的任务,在stage4的输出后接上后续的一些conv或deconv,输出改成需要的输出即可,如Abstract中图一所示的用于分割的网络结构
- 首先,将stage4的4个branch分别进行deconv,返回到原始图像尺寸
- 其次,将上述deconv后的特征在channel维度concate到一起得到15C个fm
- 然后,接上conv + BN + ReLU + conv,conv的kernel大小都是\( 1 \times 1\),最后一个conv的输出channel个数是类别个数
- 最后,在channel用softmax对每个pixel分类,得到segmentation map
- 整体深度看,HRNet由4个stage组成,每个stage中的每部分都是由N个bottleneck的residual unit组成和一个用于改变channel个数\(3\times3\)的conv组成(代码中4个stage中,每个branch的N都是4)
-
如何生成不同resolution的fm,不同resolution的fm又是如何fuse的?
- 具体实现降低图像尺寸的操作使用stride-2的\(3\times3 \)的conv,降两倍的话,则再添加一个这样的conv,诸如此。
- 以HRNet的stage2为例,输出3个不同resolution的特征图(个数分别是C、2C、3C),每个resolution的特征图都是将前面三个resolution的fm进行fuse的结果,fuse的方式直接求和。
- 例如,最上面的high-resolution的输出,由原始的high-resolution加上两个low-resolution进行deconv后的结果组成,如下图:
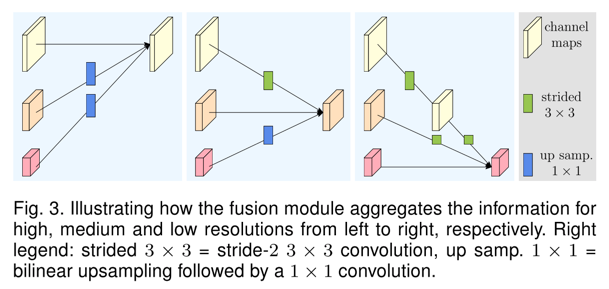
- 例如,最上面的high-resolution的输出,由原始的high-resolution加上两个low-resolution进行deconv后的结果组成,如下图:
写在后面
- 关于HRNet系列的速度,参考这篇博文
