

Netty源码分析第五章: ByteBuf
第二节: ByteBuf的分类
上一小节简单介绍了AbstractByteBuf这个抽象类, 这一小节对其子类的分类做一个简单的介绍
ByteBuf根据不同的分类方式, 会有不同的分类结果
我们首先看第一种分类方式:
1.Pooled和Unpooled:
pooled是从一块内存里去取一段连续内存封装成byteBuf
具体标志是类名以Pooled开头的ByteBuf, 通常就是Pooled类型的ByteBuf, 比如: PooledDirectByteBuf或者pooledHeapByteBuf
有关如何分配一块连续的内存, 我们之后的章节会讲到
Unpooled是分配的时候直接调用系统api进行实现, 具体标志是以Unpooled开头的ByteBuf, 比如UnpooledDirectByteBuf, UnpooledHeapByteBuf
再看第二种分类方式:
2.基于直接内存的ByteBuf和基于堆内存的ByteBuf
基于直接内存的ByteBuf, 具体标志是类名中包含单词Direct的ByteBuf, 比如UnpooledDirectByteBuf, PooledDirectByteBuf等
基于堆内存的ByteBuf, 具体标志是类名中包含单词heap的ByteBuf, 比如UnpooledHeapByteBuf, PooledHeapByteBuf
结合以上两种方式, 这里通过其创建的方式去简单对其分类做个解析
这里第一种分类的Pooled, 也就是分配一块连续内存创建byteBuf, 这一小节先不进行举例, 会在之后的小节讲到
这里主要就看Unpooled, 也就是调用系统api的方式创建byteBuf, 在直接内存和堆内存中有什么区别
这里以UnpooledDirectByteBuf和UnpooledHeapByteBuf这两种为例, 简单介绍其创建方式:
首先看UnpooledHeapByteBuf的byetBuf, 这是基于内存创建ByteBuf, 并且是直接调用系统api
我们看UnpooledHeapByteBuf的byetBuf的构造方法:
protected UnpooledHeapByteBuf(ByteBufAllocator alloc, int initialCapacity, int maxCapacity) {
this(alloc, new byte[initialCapacity], 0, 0, maxCapacity);
}
这里调用了自身的构造方法, 参数中创建了新的字节数组, 初始长度为初始化的内存大小, 读写指针初始位置都是0, 并传入了最大内存大小
从这里看出, 有关堆内存的Unpooled类型的分配, 是通过字节数组进行实现的
再往下跟:
protected UnpooledHeapByteBuf(ByteBufAllocator alloc, byte[] initialArray, int maxCapacity) {
this(alloc, initialArray, 0, initialArray.length, maxCapacity);
}
继续跟:
private UnpooledHeapByteBuf(
ByteBufAllocator alloc, byte[] initialArray, int readerIndex, int writerIndex, int maxCapacity) {
super(maxCapacity);
//忽略验证代码
this.alloc = alloc;
setArray(initialArray);
setIndex(readerIndex, writerIndex);
}
跟到setAarry方法中:
private void setArray(byte[] initialArray) {
array = initialArray;
tmpNioBuf = null;
}
将新创建的数组赋值为自身的array属性
回到构造函数中, 跟进setIndex方法:
public ByteBuf setIndex(int readerIndex, int writerIndex) {
//忽略验证代码
setIndex0(readerIndex, writerIndex);
return this;
}
这里实际上是调用了AbstractByteBuf的setIndex方法
我们跟进setIndex0方法中:
final void setIndex0(int readerIndex, int writerIndex) {
this.readerIndex = readerIndex;
this.writerIndex = writerIndex;
}
这里设置了读写指针, 根据之前的调用链我们知道, 这里将读写指针位置都设置为了0
介绍完UnpooledHeapByteBuf的初始化, 我们继续看UnpooledDirectByteBuf这个类的构造, 顾明思议, 是基于堆外内存, 并且同样也是调用系统api的方式进行实现的
我们看其构造方法:
protected UnpooledDirectByteBuf(ByteBufAllocator alloc, int initialCapacity, int maxCapacity) {
super(maxCapacity);
//忽略验证代码
this.alloc = alloc;
setByteBuffer(ByteBuffer.allocateDirect(initialCapacity));
}
我们关注下setByteBuffer中的参数ByteBuffer.allocateDirect(initialCapacity)
我们在这里看到, 这里通过jdk的ByteBuffer直接调用静态方法allocateDirect分配了一个基于直接内存的ByteBuffer, 并设置了初始内存
再跟到setByteBuffer方法中:
private void setByteBuffer(ByteBuffer buffer) {
ByteBuffer oldBuffer = this.buffer;
if (oldBuffer != null) {
//代码忽略
}
this.buffer = buffer;
tmpNioBuf = null;
capacity = buffer.remaining();
}
我们看到在这里将分配的ByteBuf设置到当前类的成员变量中
以上两种实例, 我们会对上面所讲到的两种分类有个初步的了解
这里要注意一下, 基于堆内存创建ByteBuf, 可以不用考虑对象回收, 因为虚拟机会进行垃圾回收, 但是堆外内存在虚拟机的垃圾回收机制的作用域之外, 所以这里要考虑手动回收对象
最后, 我们看第三种分类方式:
3.safe和unsafe
首先从名字上看, safe代表安全的, unsafe代表不安全的
这个安全与不安全的定义是什么呢
其实在我们jdk里面有unsafe对象, 可以通过unsafe对象直接拿到内存地址, 基于内存地址可以进行读写操作
如果是Usafe类型的byteBuf, 则可以直接拿到byteBuf在jvm中的具体内存, 可以通过调用jdk的Usafe对象进行读写, 所以这里代表不安全
而非Usafe不能拿到jvm的具体内存, 所以这里代表安全
具体标志是如果类名中包含unsafe这个单词的ByteBuf, 可以认为是一个unsafe类型的ByteBuf, 比如PooledUnsafeHeapByteBuf或者PooledUnsafeDirectByteBuf
以PooledUnsafeHeapByteBuf的_getByte方法为例:
protected byte _getByte(int index) {
return UnsafeByteBufUtil.getByte(memory, idx(index));
}
这里memory代表byebuffer底层分配内存的首地址, idx(index)代表当前指针index距内存memory的偏移地址, UnsafeByteBufUtil的getByte方法, 就可以直接通过这两个信息通过jdk底层的unsafe对象拿到jdk底层的值
有关AbstractByteBuf的主要实现类和继承关系, 如下图所示:
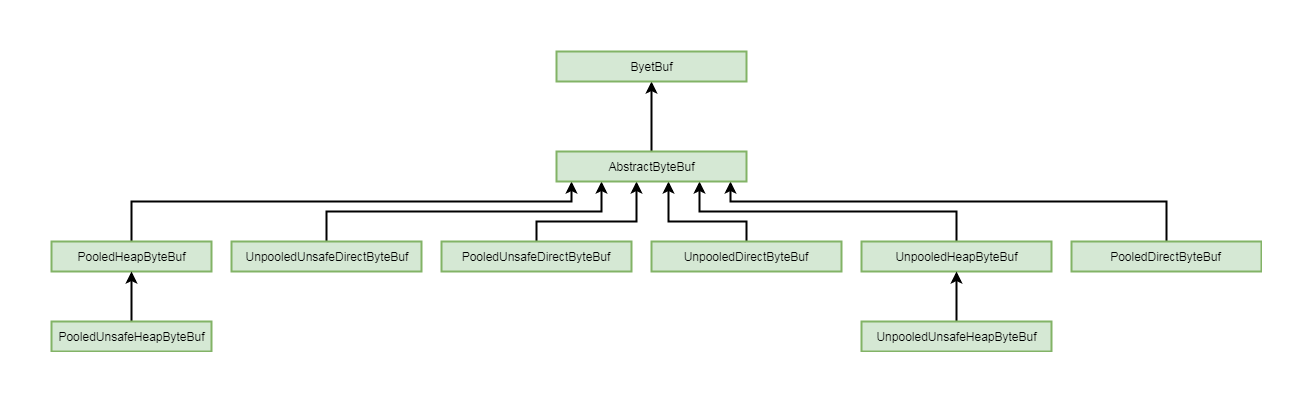
5-2-1
