
Hadoop学习笔记(1)-Hadoop在Ubuntu的安装和使用
由于小编在本学期有一门课程需要学习hadoop,需要在ubuntu的linux系统下搭建Hadoop环境,在这个过程中遇到一些问题,写下这篇博客来记录这个过程,并把分享给大家。
Hadoop的安装方式
- 单机模式:Hadoop默认模式为非分布式模式(本地模式),无需 进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试
- 伪分布式模式:Hadoop可以在单节点上以伪分布式的方式运行, Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也 作为 DataNode,同时,读取的是 HDFS 中的文件
- 分布式模式:使用多个节点构成集群环境来运行Hadoop
创建Hadoop用户(可选)
如果安装 Ubuntu 的时候不是用的 “hadoop” 用户,那么需要增加一个名为hadoop 的用户,首先按打开终端窗口,输入如下命令创建新用户 :
sudo useradd –m hadoop –s /bin/bash
上面这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell 接着使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:
sudo passwd hadoop
可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘 手的权限问题:
sudo adduser hadoop sudo
SSH登录权限设置
SSH是什么?
SSH 为 Secure Shell 的缩写,是建立在应用层和传输层基础上的安全协议。 SSH 是目前较可靠、专为远程登录会话和其他网络服务提供安全性的协议。 利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。SSH最初是 UNIX系统上的一个程序,后来又迅速扩展到其他操作平台。 SSH是由客 户端和服务端的软件组成,服务端是一个守护进程(daemon),它在后台运 行并响应来自客户端的连接请求,客户端包含ssh程序以及像scp(远程拷 贝)、slogin(远程登陆)、sftp(安全文件传输)等其他的应用程序.
配置SSH的原因
Hadoop名称节点(NameNode)需要启动集群中所有机器的Hadoop守护进程,这个过 程需要通过SSH登录来实现。Hadoop并没有提供SSH输入密码登录的形式,因此,为 了能够顺利登录每台机器,需要将所有机器配置为名称节点可以无密码登录它们。
配置SSH的无密码登录
安装openssh-server( 通常Linux系统会默认安装openssh的客户端软件openssh-client),所以需要自己安装一下服务端。
sudo apt-get install openssh-server
输入 cd .ssh目录下,如果没有.ssh文件 输入 ssh localhost生成。
cd ~/.ssh/
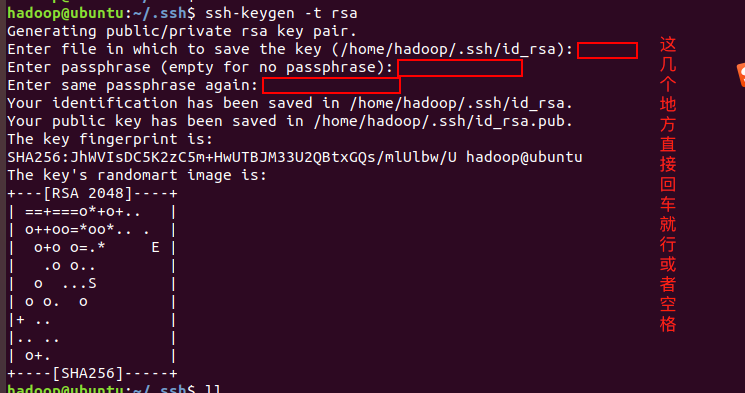
生成秘钥
ssh-keygen -t rsa
将Master中生成的密钥加入授权(authorized_keys)
cat id_rsa.pub # 查看生成的公钥

cat id_rsa.pub >> authorized_keys # 加入授权
chmod 600 authorized_keys # 修改文件权限,如果不修改文件权限,那么其它用户就能查看该授权
完成后,直接键入“ssh localhost”,能无密码登录即可,
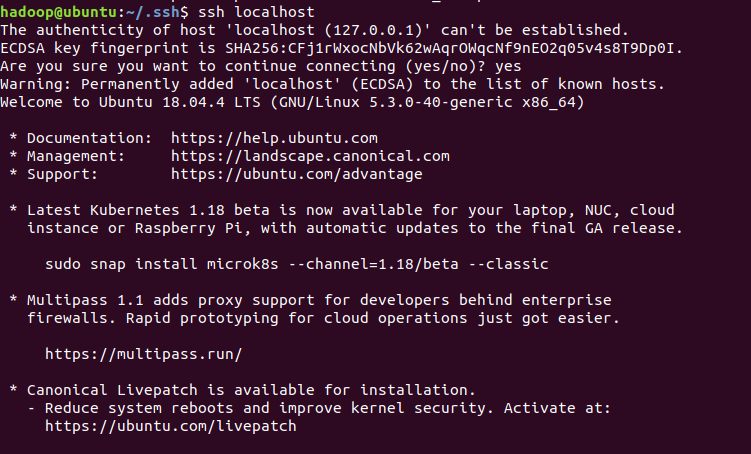
键入“exit”退出,到此SSH无密码登录配置就成功了。
安装Java环境
scp命令传输Mac的文件到ubuntu
因为老师给了我们的java的jdk安装包,想着不用去ubuntu重新下载,所以就想到了利用scp命令传输Mac的文件到ubuntu,利用这个命令前提是Ubuntu安装了SSH服务器,在之前我们已经有了这步操作。
利用ifconfig查看ubuntu服务器的局域网IP地址
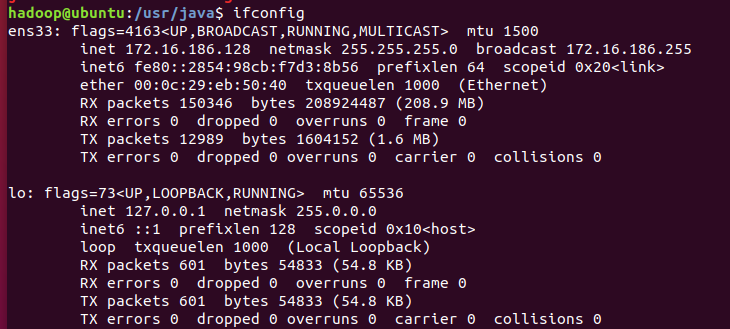
以下是利用scp命令传输文件的基本格式:
1. 本地文件传输到服务器
| 从本地将文件传输到服务器 | 从本地将文件夹传输到服务器 |
|---|---|
| scp[本地文件的路径] [服务器用户名]@[服务器地址]:[服务器上存放文件的路径] | scp -r[本地文件的路径] [服务器用户名]@[服务器地址]:[服务器上存放文件的路径] |
| scp /Users/mac/Desktop/test.txt root@192.168.1.1:/root | scp -r /Users/mac/Desktop/test root@192.168.1.1:/root |
2. 服务器文件传输到本地
| 将服务器上的文件传输到本地 | 将服务器上的文件夹传输到本地 |
|---|---|
| scp [服务器用户名]@[服务器地址]:[服务器上存放文件的路径] [本地文件的路径] | scp -r [服务器用户名]@[服务器地址]:[服务器上存放文件的路径] [本地文件的路径] |
| scp root@192.168.1.1:/root/default/test.txt /Users/mac/Desktop | scp -r root@192.168.1.1:/root/default/test /Users/mac/Desktop |
mac客户端执行传输命令
在选择Linux服务器端的储存文件地址时,由于权限原因,默认的是在/tmp有权限,可以先把文件放到tmp文件目录下,然后在进行mv 或者scp到其他目录,即可。
scp /Users/xjh/Desktop/jdk-8u221-linux-x64.tar.gz hadoop@172.16.186.128:/tmp
传输速度还是蛮快的,如下图:

在Ubuntu将jdk移动到我们新建的java目录下(没建的新建一个就是),到此传输文件成功,可以开始配置Java环境了。
sudo mv /tmp/jdk-8u221-linux-x64.tar.gz usr/java
在java目录中,使用sudo tar命令解压jdk文件;
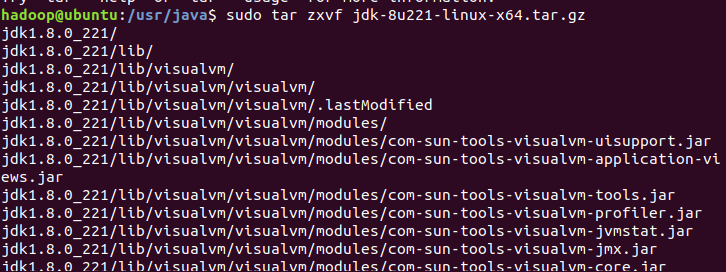
解压成功后,java目录中会有对应的目录文件存在
配置Java环境
使用命令“sudo gedit ~/.bashrc”打开配置文件,在末尾添加以下几行文字,注意自己的jdk版本号。
#set java env
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_221
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
使用命令“source ~/.bashrc”使环境变量生效。
source ~/.bashrc
配置软连接,软连接相当于windows系统中的快捷键,部分软件可能会从/usr/bin目录下查找Java,因此添加该软连接防止其他软件查找不到的情况。
sudo update-alternatives --install /usr/bin/java java /usr/java/jdk1.8.0_221/bin/java 300
sudo update-alternatives --install /usr/bin/javac javac /usr/java/jdk1.8.0_221/bin/javac 300

测试java是否安装成功

Hadoop单机安装配置
将我们下载的Hadoop解压到 /usr/local/ 中
sudo tar zxvf tmp/hadoop-3.2.1.tar.gz -C /usr/local
利用cd /usr/local/ 命令切换操作空间,将文件夹名改为hadoop
sudo mv ./hadoop-3.2.1/ ./hadoop

修改文件权限
sudo chown -R hadoop:hadoop ./hadoop
Hadoop 解压后,在Hadoop目录下的etc/hadoop/hadoop-env.sh文件中添加如下的 Java环境信息。
export JAVA_HOME=/usr/java/jdk1.8.0_221
然后,保存hadoop-env.sh文件,即完成单机模式的Hadoop基本安装。测试Hadoop是否安装成功,如出现如下图所示的版本信息,即可。
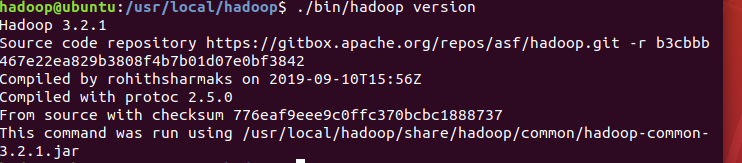
默认情况下,单机模式的Hadoop以Java进程的方式运行,可依次运行如下命令进行进一步测试。
sudo mkdir input
sudo cp etc/hadoop/*.xml input
执行下列命令,运行MapReduce程序,完成测试计算。
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
执行下列命令,查看计算结果。
cat output/*

Hadoop目录下,会有input和output两个新建的文件,output中有上述程序 的运算结果,到此Hadoop单机安装配置成功。
Hadoop伪分布式安装配置
- Hadoop可以在单节点上以伪分布式的方式运行,Hadoop进程以分 离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode, 同时,读取的是 HDFS 中的文件
- Hadoop的配置文件位于/usr/local/hadoop/etc/hadoop/中,伪分布式 需要修改2个配置文件 core-site.xml 和 hdfs-site.xml
- Hadoop的配置文件是xml格式,每个配置以声明property的name 和 value 的方式来实现
hadoop目录认识
hadoop下的目录
修改配置文件之前,先看一下hadoop下的目录:
- bin:hadoop最基本的管理脚本和使用脚本所在目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用hadoop
- etc:配置文件存放的目录,包括core-site.xml,hdfs-site.xml,mapred-site.xml等从hadoop1.x继承而来的配置文件和yarn-site.xml等hadoop2.x新增的配置文件
- include:对外提供的编程库头文件(具体动态库和静态库在lib目录中,这些头文件军事用c++定义的,通常用于c++程序访问hdfs或者编写mapreduce程序)
- Lib:该目录包含了hadoop对外提供的才变成动态库和静态库,与include目录中的头文件结合使用
- libexec:各个服务对应的shell配置文件所在目录,可用于配置日志输出目录、启动参数等信息
- sbin:hadoop管理脚本所在目录,主要包含hdfs和yarn中各类服务的启动、关闭脚本
- share:hadoop各个模块编译后的jar包所在目录。
修改配置文件 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
- hadoop.tmp.dir表示存放临时数据的目录,即包括NameNode的数据,也包 括DataNode的数据。该路径任意指定,只要实际存在该文件夹即可
- name为fs.defaultFS的值,表示hdfs路径的逻辑名称
修改配置文件 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
- dfs.replication表示副本的数量,伪分布式要设置为1
- dfs.namenode.name.dir表示本地磁盘目录,是存储fsimage文件的地方
- dfs.datanode.data.dir表示本地磁盘目录,HDFS数据存放block的地方
| 文件名称 | 格式 | 描述 |
|---|---|---|
| hadoop-env.sh | Bash脚本 | 记录配置Hadoop运行所需的环境变量,以运行 Hadoop |
| core-site.xml | Hadoop配置XML | Hadoop core的配置项,例如HDFS和MapReduce 常用的I/O设置等 |
| hdfs-site.xml | Hadoop配置XML | Hadoop的守护进程的配置项,包括NameNode、 SecondaryNameNode和DataNode等 |
| mapred-site.xml | Hadoop配置XML | MapReduce守护进程的配置项,包括JobTracker 和TaskTracker |
| masters | 纯文本 | 运行SecondaryNameNode的机器列表(每行一 个) |
| slaves | 纯文本 | |
| hadoop- metrics.properties | Java属性 | 控制metrics在Hadoop上如何发布的属性 |
至此,配置完毕,但是还不能启动,要对hdfs先进行格式化。类似以前的软盘,使用前要先格式化,执行命令:
sudo ./bin/hdfs namenode -format
看到日志信息:即格式化成功。
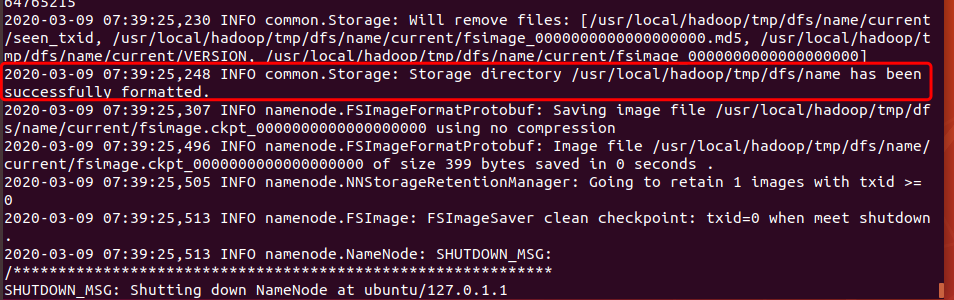
在我们name目录(这个目录是我们自己配置的时候指定的)下也会出现映像文件(fsimage),用于将数据持久化 。

启动Hadoop
输入以下命令启动Hadoop:
sbin/start-dfs.sh

安装jps
sudo apt install openjdk-11-jdk-headless
安装好之后jps检查角色如果有多个角色,就启动成功。

浏览器访问localhost:9870
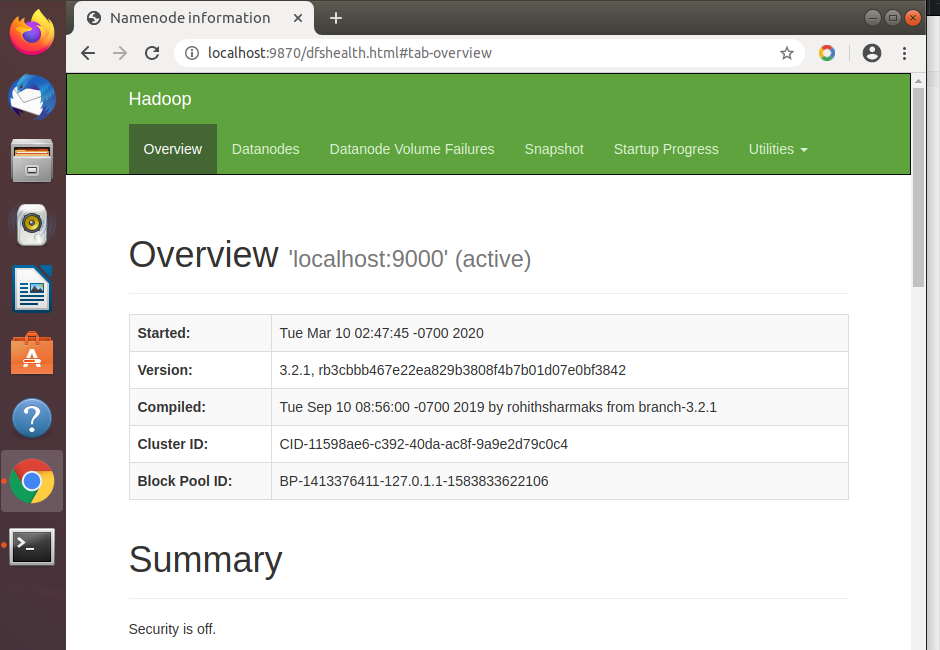
本次给大家分享的内容就到这里啦,觉得还不错的点个赞支持一下小编,你的肯定就是小编前进的动力。另外如果想了解更多计算机专业的知识和技巧的,献上我的个人博客北徯,另外需要各种资料的童鞋,可以关注我的微信公众号北徯,免费的PPT模板,各种资料等你来领。


