Hadoop集群(三) HDFS搭建
一.前言
HDFS只是Hadoop最基本的一个服务,很多其他服务,都是基于HDFS展开的。所以部署一个HDFS集群,是很核心的一个动作,也是大数据平台的开始。安装Hadoop集群,首先需要有Zookeeper才可以完成安装。如果没有Zookeeper,请先部署一套Zookeeper。另外,JDK以及物理主机的一些设置等。
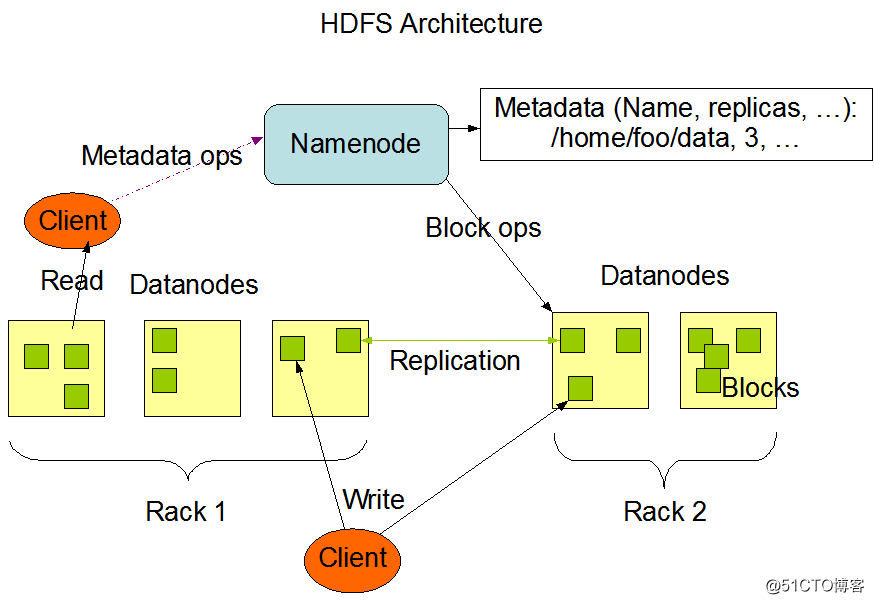
HDFS采用主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。NameNode作为主服务器,管理文件系统命名空间和客户端对文件的访问操作。DataNode管理存储的数据。HDFS支持文件形式的数据。
从内部来看,文件被分成若干个数据块,这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写,并在NameNode的统一调度下进行数据库的创建、删除和复制工作。NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。
二.安装和部署
1.下载安装
#下载cdh版本zookeeper wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.9.3.tar.gz
# 解压安装包 tar xf hadoop-2.6.0-cdh5.9.3.tar.gz -C /opt&& mv hadoop-2.6.0-cdh5.9.3 /opt/hadoop # 创建目录 mkdir -p /opt/hadoop/{temp,hdfs,log,journal} mkdir -p /opt/hadoop/hdfs/{name,data} #修改权限 chown -R hadoop:hadoop /opt/hadoop #我这里普通用户hadoop启动,可用root
2.修改hadoop-env.sh配置
vim /opt/hadoop/etc/hadoop/hadoop-env.sh
#JDK环境 JAVA_HOME=/usr/local/jdk1.8.0_11
3. 修改core-site.xml对应的参数
vim /opt/hadoop/etc/hadoop/core-site.xml
<configuration> <!-- 指定hdfs的nameservice为ns --> <property> <name>fs.defaultFS</name> <value>hdfs://ns</value> </property> <!--指定hadoop数据临时存放目录--> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/temp</value> </property> <property> <name>io.file.buffer.size</name> <value>4096</value> </property> <!--指定zookeeper地址--> <property> <name>ha.zookeeper.quorum</name> <value>zkh01:2181,zkh02:2181,zkh03:2181,</value> </property> </configuration>
4. 修改hdfs-site.xml对应的参数
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致,并且ns如果改,整个文件中,全部的ns要都修改,保持统一 --> <property> <name>dfs.nameservices</name> <value>ns</value> </property> <!-- ns下面有两个NameNode,分别是nn1,nn2 --> <property> <name>dfs.ha.namenodes.ns</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns.nn1</name> <value>zkh01:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.ns.nn1</name> <value>zkh01:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns.nn2</name> <value>zkh02:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.ns.nn2</name> <value>zkh02:50070</value> </property> <!-- 指定NameNode的元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://zkh01:8485;zkh02:8485;zkh03:8485/ns</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/hadoop/journal</value> </property> <!-- 开启NameNode故障时自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.ns</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hadoop/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- 在NN和DN上开启WebHDFS (REST API)功能,不是必须 --> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
注:以下配置项请根据自己实际情况修改
<property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property>
4.添加slaves文件
cat /opt/hadoop/etc/hadoop/slaves
zkh01
zkh02
zkh03
5.拷贝软件到其他节点
scp -r /opt/hadoop zkh02:/opt
scp -r /opt/hadoop zkh03:/opt
6.启动三个节点的journalnode
/opt/hadoop/sbin/hadoop-daemon.sh start journalnode
检查状态
$ jps 3958 Jps 3868 JournalNode
7. 然后启动namenode,首次启动namenode之前,先在主节点zkh01 format namenode信息,信息会存在于dfs.namenode.name.dir指定的路径中
/opt/hadoop/bin/hdfs namenode -format
8.zkh02 执行bootstrapstandby
/opt/hadoop/bin/hdfs namenode -bootstrapstandby
9. 检查状态,namenode还没有启动
./hdfs zkfc -formatZK
12. zkh01,zkh02启动zkfc,这个就是为namenode使用的
./hadoop-daemon.sh start zkfc
13. 启动所有datanode,主节点zkh01上启动即可
/opt/hadoop/sbin/start-dfs.sh
14.检查状态
$ jps 4981 Jps 4935 DFSZKFailoverController 4570 NameNode 3868 JournalNode
三、Hadoop 的使用
1 查看fs帮助命令: hadoop fs -help 2 查看HDFS磁盘空间: hadoop fs -df -h 3 创建目录: hadoop fs -mkdir 4 上传本地文件: hadoop fs -put 5 查看文件: hadoop fs -ls 6 查看文件内容: hadoop fs –cat 7 复制文件: hadoop fs -cp 8 下载HDFS文件到本地: hadoop fs -get 9 移动文件: hadoop fs -mv 10 删除文件: hadoop fs -rm -r -f 11 删除文件夹: hadoop fs -rm –r
HDFS只是Hadoop最基本的一个模块,这里已经安装完成,可以为后面的Hbase提供服务了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号