

PostgreSQL高可用方案-patroni+etcd+vipmanager(二)
1 前言
1.1概述
Patroni + etcd + vipmanager 是cybertec推出的postgresql 高可用方案。其中, Etcd 用于存放集群状态信息。Patroni 负责为PostgreSQL 集群提供故障转移和高可用服务。vipmanager 根据etcd或Consul中保存的状态管理虚拟IP用于提供和管理虚拟ip,用于对外提供访问地址。
3 方案验证
3.1 验证数据库主备功能
1. 在主数据库上的操作
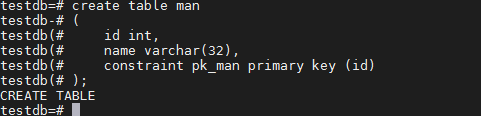
1.1 创建表 man:
create table man
(
id int,
name varchar(32),
constraint pk_man primary key (id)
);
结果如下:
1.2 插入数据到表man:
insert into man (id, name) values (1, 'Amy');
结果如下:

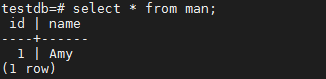
1.3 查询表 man:
select * from man;
2. 后备数据库上的操作
2.1 从表man 中查询数据
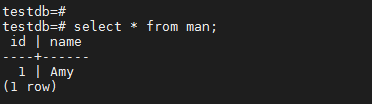
可以看出,发现主数据库中的数据已经同步到后备数据库。
2.2 尝试向后备数据库插入数据
insert into man (id, name) values (2, 'Bob');
结果如下:

可以看出,无法向后备数据库插入数据。
3.2 通过虚拟 ip 访问数据库
1. 通过虚拟ip 10.19.134.140 连接数据库
[root@node134 bin]# cd /opt/postgresql-12/bin
[root@node134 bin]# su postgres
[postgres@node135 bin]$ ./psql -h 10.19.134.140 -U postgres -p 5432 -d testdb
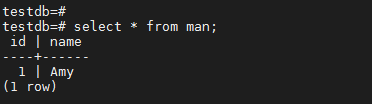
2. 执行如下查询:
select * from man;
3. 查看流复制状态,可以确定虚拟ip映射到了主数据库所在的节点上。
select * from pg_stat_replication;

3.3 验证PostgreSQL的高可用
1. 手动关闭主数据库。在postgresql 的bin 目录中,以用户postgres 执行如下命令:
[postgres@node134 bin]# ./pg_ctl stop -D ../data/

2. 过10秒后,再查看主数据库上PostgreSQL的状态
[postgres@node134 bin]$ ./pg_ctl status -D ../data/
发现 PostgreSQL 已经启动:

3. 在主数据库中查询流复制状态:
select * from pg_stat_replication;

如图所示,流复制正常。
3.4 验证停止和启动patroni的影响
3.4.1 在后备服务器上停止 patroni
1. 在后备服务器上停止patroni
[root@node135 bin]# systemctl stop patroni
之后,查看postgresql 服务的状态:
[root@node135 bin]# cd /opt/postgresql-12/bin
[root@node135 bin]# su postgres
[postgres@node135 bin]$ ./pg_ctl status -D ../data/
pg_ctl: no server running
可以看出,PostgreSQL 跟随patroni停止。
2. 通过虚拟IP 10.19.134.140 访问数据库
[postgres@node134 bin]$ ./psql -h 10.19.134.140 -U postgres -p 5432 -d testdb
查看复制状态
select * from pg_stat_replication;

可以发现,流复制已经断开。
3. 后备服务器上启动patroni
[root@node135 bin]# systemctl start patroni
之后查看PostgreSQL 的状态,发现它已经启动:
[postgres@node135 bin]$ ./pg_ctl status -D ../data/

4. 再次在主数据库上查看复制状态:
select * from pg_stat_replication;

可以发现,流复制恢复正常。
3.4.2 在主服务器上停止 patroni
1. 在主服务器上停止patroni
[root@node134 bin]# systemctl stop patroni
之后,查看postgresql 服务的状态:
[root@node134 bin]# cd /opt/postgresql-12/bin
[root@node134 bin]# su postgres
[postgres@node134 bin]$ ./pg_ctl status -D ../data/
pg_ctl: no server running
可以看出,PostgreSQL 跟随patroni停止。
2. 在这台服务器上重启patroni
[root@node134 bin]# systemctl start patroni
3. 在原后备服务器的数据库上查看复制状态
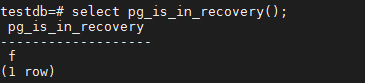
select pg_is_in_recovery();
它现在不是后备数据库了。
4. 通过虚拟IP 10.19.134.140 访问数据库
[postgres@node134 bin]$ ./psql -h 10.19.134.140 -U postgres -p 5432 -d testdb
5. 查看流复制状态
select * from pg_stat_replication;
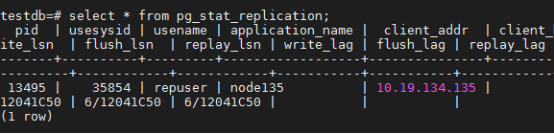
可以看出,位于 10.19.134.135 上的原后备数据库提升为了新的主数据库,而位于10.19.134.135的原主数据库则降级为后备数据库。虚拟ip则漂移到了 10.19.134.135 ,新主数据库所在的节点上。
3.5 手工切换PostgreSQL 主节点
1. 在切换之前,查看Patroni 集群的状态信息。
[postgres@node135 ~]$ patronictl -c /etc/patroni/patroni_postgresql.yml list

可以看出,此时,node135 是数据库集群的主结点,而 node134是数据库集群的备节点。
2. 我们将node 135 降级为备节点,将node134 提升为主结点。执行下面的命令:
[postgres@node135 ~]$ patronictl -c /etc/patroni/patroni_postgresql.yml switchover postgresql12
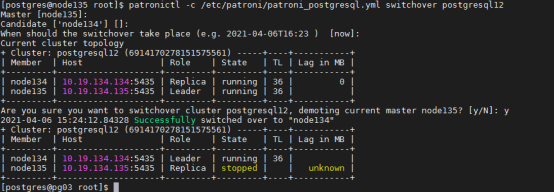
3. 再查看切换后的结果:
[postgres@node135 root]$ patronictl -c /etc/patroni/patroni_postgresql.yml list

如图所示,此时,node134 已经提升为数据库集群的主结点,而时间线TL 则增加了1。
3.6 重新初始化后备数据库
1. 在备节点node135上,删除postgresql的 data目录。
[postgres@node135 ~]$ cd /opt/postgresql-12
[postgres@node135 postgresql-12]$ rm -rf data
现在,node135上的数据库无法正常访问。我们可以使用如下命令来重新初始化数据库:
patronictl reinit [OPTIONS] CLUSTER_NAME [MEMBER_NAMES]...
这里,CLUSTER_NAME 是patroni_postgresql.yml 中 scope的值,而 MEMBER_NAME,集群的成员名,是patroni_postgresql.yml 中 name的值。
2. 为了重新初始化 node135 节点,我们执行如下命令:
[postgres@node135 postgresql-12]$ patronictl -c /etc/patroni/patroni_postgresql.yml reinit postgresql12 node135

如上图所示,数据库重新初始化成功。
参考
[1] 你离开我真会死. PostgreSQL-11.3+etcd+patroni构建高可用数据库集群. 2019-11-29
[2] 学无止境. centos7部署postgresql集群高可用 patroni + etcd 之patroni篇. 2019-08-25
[3] How to Set Up a Highly Available PostgreSQL Cluster Using Patroni and HAProxy on Ubuntu?November 16, 2020
[4] Cybertec. patroni
[5] Cybertec. vip-manager
