

ClickHouse 简单使用(二)
4 ClickHouse 启动和关闭
4.1 通过系统命令
启动
systemctl start clickhouse-server
关闭
systemctl stop clickhouse-server
重启
systemctl restart clickhouse-server
4.2 通过原生命令
启动
/etc/init.d/clickhouse-server start
关闭
/etc/init.d/clickhouse-server stop
重启
/etc/init.d/clickhouse-server stop
5 登录方法
5.1 用clickhouse-client登录本地服务器
clickhouse-client -h 127.0.0.1 --port 9000 -u default -d default --ask-password
下面解释这些参数的含义:
-h 127.0.0.1 表示连接到本地
--port 9000是表示 clickhouse接收TPC/IP连接的端口是9000;
-u default 表示用户名是 default;
-d default 表示连接到的数据库的名称是 default;
我们推荐用putty或 XShell来访问linux 客户端。
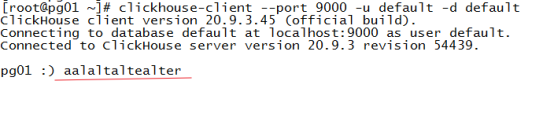
注意BUG:用SecureCRT 访问会出错。例如:
输入“alter”,会显示成下面这样:
5.2 用图形化客户端
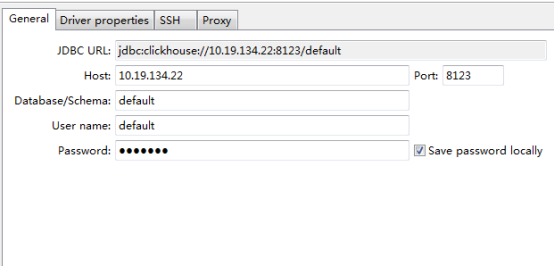
dbeaver 提供了连接 clickhouse 的能力。它在连接clickhouse 服务端时会自动下载需要的驱动。
如图所示,是一个连接的配置。注意clickhouse jdbc 是基于 HTTP协议的,而clickhouse接受HTTP连接的端口是8123。
6 常用 sql 语句
ClickHouse与MySQL语法相似。这里列出一些常用的sql 语句。参见官方手册的章节statement。
6.1 创建
这一节的内容来自官方手册中的Create Queries.
6.1.1 创建数据库
基本语法:
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster] [ENGINE = engine(...)]
ClickHouse 的引擎(ENGINE)有这些:
1. 默认引擎
默认情况下,ClickHouse使用自身的数据库引擎,该引擎可以提供表引擎配置( table engines )和SQL(SQL dialect.)
2. MySQL引擎
允许连接到远程MySQL服务器上的数据库,并执行INSERT和SELECT查询以在ClickHouse和MySQL之间交换数据。
创建数据库语法:
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')
3. Lazy引擎
在最后一次访问之后,仅在expiration_time_in_seconds秒内将表保留在RAM中。只有Log引擎的表可以使用。
该引擎针对存储很多小型Log引擎表的情况进行了优化。因为对于这些表而言,两次访问之间的时间间隔很长。
创建数据库语法:
CREATE DATABASE testlazy ENGINE = Lazy(expiration_time_in_seconds);
6.1.2 创建表
基本语法:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [compression_codec] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [compression_codec] [TTL expr2],
...
) ENGINE = engine;
ClickHouse 的表的引擎很多,在第7章会详细介绍。
6.1.3 创建视图
创建普通视图:
CREATE [OR REPLACE] VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER] AS SELECT ...
创建物化视图:
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER] [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT ...
6.1.4 创建用户
基本语法:
CREATE USER [IF NOT EXISTS | OR REPLACE] name [ON CLUSTER cluster_name]
[
IDENTIFIED
[WITH
{NO_PASSWORD|PLAINTEXT_PASSWORD|SHA256_PASSWORD|SHA256_HASH|DOUBLE_SHA1_PASSWORD|DOUBLE_SHA1_HASH}]
BY {'password'|'hash'}
]
[HOST {LOCAL | NAME 'name' | REGEXP 'name_regexp' | IP 'address' | LIKE 'pattern'} [,...] | ANY | NONE]
[DEFAULT ROLE role [,...]]
[SETTINGS variable [= value] [MIN [=] min_value] [MAX [=] max_value] [READONLY|WRITABLE] | PROFILE 'profile_name'] [,...]
身份识别——identification
定义身份识别的方法有多种:
- IDENTIFIED WITH no_password
- IDENTIFIED WITH plaintext_password BY 'qwerty'
- IDENTIFIED WITH sha256_password BY 'qwerty' or IDENTIFIED BY 'password'
- IDENTIFIED WITH sha256_hash BY 'hash'
- IDENTIFIED WITH double_sha1_password BY 'qwerty'
- IDENTIFIED WITH double_sha1_hash BY 'hash'
注意,上面的 ‘qwerty’ 是明文密码,而 ‘hash’ 是密码被hash算法处理后的结果。
6.1.5 创建角色
基本语法:
CREATE ROLE [IF NOT EXISTS | OR REPLACE] name
[SETTINGS variable [= value] [MIN [=] min_value] [MAX [=] max_value] [READONLY|WRITABLE] | PROFILE 'profile_name'] [,...]
6.2 删除
这一节的内容来自官方手册中的DROP Statements
6.2.1 删除数据库
基本语法:
DROP DATABASE [IF EXISTS] db [ON CLUSTER cluster]
6.2.2 删除表
基本语法:
DROP [TEMPORARY] TABLE [IF EXISTS] [db.]name [ON CLUSTER cluster]
6.2.3 删除视图
基本语法:
DROP VIEW [IF EXISTS] [db.]name [ON CLUSTER cluster]
6.2.4 删除用户
基本语法:
DROP USER [IF EXISTS] name [,...] [ON CLUSTER cluster_name]
6.2.5 删除角色
基本语法:
DROP ROLE [IF EXISTS] name [,...] [ON CLUSTER cluster_name]
6.3 修改
这一节的内容来自官方手册中的ALTER Statements
6.3.1 修改表的字段
基本语法:
ALTER TABLE [db].name [ON CLUSTER cluster] ADD|DROP|CLEAR|COMMENT|MODIFY COLUMN ...
支持以下操作:
- ADD COLUMN —— 将新列添加到表中。
- DROP COLUMN —— 删除列。
- CLEAR COLUMN —— 重置列值。
- COMMENT COLUMN ——在该列中添加文本注释。
- MODIFY COLUMN——更改列的类型,默认表达式和TTL。
6.3.2 处理分区
基本语法:
ALTER TABLE [db].name [ON CLUSTER cluster] DETACH|DROP|ATTACH|ATTACH|REPLACE|MOVE|CLEAR COLUMN IN|CLEAR INDEX IN|FREEZE|FETCH|MOVE PARTITION ...
支持以下操作:
- DETACH PARTITION —将分区移动到detached目录并忘记它。
- DROP PARTITION —删除分区。
- ATTACH PART | PARTITION —将detached目录中的零件或分区添加到表中。
- ATTACH PARTITION FROM —将数据分区从一个表复制到另一个表并添加。
- REPLACE PARTITION —将数据分区从一个表复制到另一个表并进行替换。
- MOVE PARTITION TO TABLE—将数据分区从一个表移动到另一个表。
- CLEAR COLUMN IN PARTITION—重置分区中指定列的值。
- CLEAR INDEX IN PARTITION —重置分区中的指定二级索引。
- FREEZE PARTITION —创建分区的备份。
- FETCH PARTITION —从另一台服务器下载分区。
- MOVE PARTITION | PART —将分区/数据部分移动到另一个磁盘或卷。
在8.1节有这些命令的使用案例。
下面我们详细解释这些命令:
ATTACH PART | PARTITION
语法:
ALTER TABLE table_name DETACH PARTITION|PART partition_expr
将指定分区的所有数据移动到detached目录中。服务器会忘记分离的数据分区,就好像它不存在一样。在您进行ATTACH查询之前,服务器将不知道此数据。
例如:
ALTER TABLE mt DETACH PARTITION '2020-11-21';
ALTER TABLE mt DETACH PART 'all_2_2_0';
可以在如何指定分区表达式一节中阅读有关设置分区表达式的更多信息。
执行上述查询后,您可以对detached目录中的数据执行任何操作-将其从文件系统中删除,或将其保留。
此查询已复制–将数据移动到detached所有副本上的目录中。请注意,你只能在领导者副本上执行此查询。若要确定副本是否为领导者,请查询system.replicas。
DROP PARTITION|PART
语法:
ALTER TABLE table_name DROP PARTITION|PART partition_expr
从表中删除指定的分区。该查询将分区标记为非活动状态,并大约在10分钟内完全删除数据。
可以在如何指定分区表达式一节中阅读有关设置分区表达式的更多信息。
语法:
ALTER TABLE mt DROP PARTITION '2020-11-21';
ALTER TABLE mt DROP PART 'all_4_4_0';
从detached的分区中删除指定分区或所有分区。
可以在如何指定分区表达式一节中阅读有关设置分区表达式的更多信息。
ATTACH PARTITION|PART
语法:
ALTER TABLE table_name ATTACH PARTITION|PART partition_expr
从detached目录将数据添加到表中。可以为整个分区或单独的部分添加数据。例子:
ALTER TABLE visits ATTACH PARTITION 201901;
ALTER TABLE visits ATTACH PART 201901_2_2_0;
在“如何指定分区表达式”一节中阅读有关设置分区表达式的更多信息。
此查询被复制。复制启动器检查detached目录中是否有数据。如果数据存在,查询将检查其完整性。如果一切正确,则查询会将数据添加到表中。所有其他副本都从副本启动器下载数据。
因此,您可以将数据detached放在一个副本上的目录中,然后使用ALTER ... ATTACH查询将其添加到所有副本上的表中。
ATTACH PARTITION FROM
语法:
ALTER TABLE table2 ATTACH PARTITION partition_expr FROM table1
此查询从复制数据分区,table1以table2将数据添加到中存在的数据table2。请注意,不会从中删除数据table1。
为了使查询成功运行,必须满足以下条件:
两个表必须具有相同的结构。
两个表必须具有相同的分区键。
REPLACE PARTITION
语法:
ALTER TABLE table2 REPLACE PARTITION partition_expr FROM table1
此查询将的数据分区从复制table1到,table2并替换中的现有分区table2。请注意,不会从中删除数据table1。
为了使查询成功运行,必须满足以下条件:
两个表必须具有相同的结构。
两个表必须具有相同的分区键。
MOVE PARTITION TO TABLE
语法:
ALTER TABLE table_source MOVE PARTITION partition_expr TO TABLE table_dest
此查询将数据分区从table_source移至table_dest,并从table_source中删除这些数据。
为了使查询成功运行,必须满足以下条件:
两个表必须具有相同的结构。
两个表必须具有相同的分区键。
两个表都必须是相同的引擎系列(已复制或未复制)。
两个表必须具有相同的存储策略。
CLEAR COLUMN IN PARTITION
语法:
ALTER TABLE table_name CLEAR COLUMN column_name IN PARTITION partition_expr
重置分区中指定列中的所有值。如果DEFAULT子句在创建表时已确定,则此查询会将列值设置为指定的默认值。
例如:
ALTER TABLE visits CLEAR COLUMN hour in PARTITION 201902;
FREEZE PARTITION:
ALTER TABLE table_name FREEZE [PARTITION partition_expr]
该查询创建指定分区的本地备份(冻结并不影响分区的使用)。如果PARTITION省略该子句,则查询将立即创建所有分区的备份。
6.3.3 删除数据
ALTER TABLE [db.]table [ON CLUSTER cluster] DELETE WHERE filter_expr
删除与指定过滤表达式匹配的数据。
6.3.4 修改表中数据
修改数据在OLAP数据库中通常是不受欢迎的。ClickHouse也不例外。像其他一些OLAP产品一样,ClickHouse最初甚至不支持更新。后来,更新被ClickHouse支持了,但也是异步的,这使得它们很难在交互式应用程序中使用。因此不建议在应用中使用clickhouse的更新功能。
语法:
ALTER TABLE [db.]table UPDATE column1 = expr1 [, ...] WHERE filter_expr
操作与指定表达式匹配的数据。
6.4 查看各项系统信息
ClickHouse 的系统表位于 system 数据库中。下列列举常用的系统表。
6.4.1 查看分布式集群信息
select * from system.clusters;
6.4.2 查看数据库版本信息等
select * from system.build_options;
6.4.3 查看有哪些进程
select * from system.processes;
6.4.4 查看有哪些表
select * from system.tables;
6.4.5 查看有哪些用户
select * from system.users;
