
基于pgpool-II的PostgreSQL双机高可用和负载均衡方案
1 前言
1.1 概述
pgpool-II是位于PostgreSQL服务器和 PostgreSQL数据库客户端之间的代理软件,它提供了功能它连接池,负载均衡,自动故障转移,在线恢复等功能。本文介绍一种基于pgpool-II的方案,实现双机条件下,pgpool-II服务的高可用,PostgreSQL的高可用和负载均衡等功能。
1.2 软件介绍
1.2.1 pgpool-II
pgpool-II是位于PostgreSQL服务器和 PostgreSQL数据库客户端之间的代理软件。它提供以下功能:
连接池
Pgpool-II维护与PostgreSQL 服务器的已建立连接,并在出现具有相同属性(即用户名,数据库,协议版本和其他连接参数,如果有)的新连接时重用它们。它减少了连接开销并改善了系统的整体吞吐量。
负载均衡
如果复制了数据库(因为以复制模式或主/从模式运行),则在任何服务器上执行SELECT查询都将返回相同的结果。Pgpool-II 利用复制功能来减少每个PostgreSQL服务器上的负载。它通过在可用服务器之间分配SELECT查询来做到这一点,从而提高了系统的整体吞吐量。在理想情况下,读取性能可以与PostgreSQL服务器的数量成比例地提高。在许多用户同时执行许多只读查询的情况下,负载平衡效果最佳。
自动故障转移
如果其中一台数据库服务器出现故障或无法访问,则 Pgpool-II会将其分离,并将继续使用其余的数据库服务器进行操作。有一些复杂的功能可以帮助自动故障转移,包括超时和重试。
在线恢复
Pgpool-II可以通过执行一个命令来执行数据库节点的联机恢复。当联机恢复与自动故障转移一起使用时,可以通过故障转移将分离的节点自动添加为备用节点。也可以同步并添加新的 PostgreSQL服务器。
复制
Pgpool-II可以管理多个PostgreSQL 服务器。激活复制功能可以在两个或多个PostgreSQL群集上创建实时备份,因此,如果其中一个群集发生故障,服务可以继续运行而不会中断。
看门狗
看门狗可以协调多个Pgpool-II,创建强大的群集系统,并避免单点故障或大脑裂开。看门狗可以对其他pgpool-II节点执行生命检查,以检测Pgpoll-II的故障。如果活动Pgpool-II发生故障,则备用 Pgpool-II可以提升为活动状态,并接管虚拟IP。
内存中查询缓存
在内存中查询缓存允许保存一对SELECT语句及其结果。如果出现相同的SELECT,则Pgpool-II从缓存中返回该值。由于不 涉及SQL解析或对PostgreSQL的访问,因此在内存缓存中使用非常快。另一方面,在某些情况下,它可能比正常路径慢,因为它增加了存储缓存数据的开销。
Pgpool-II使用 PostgreSQL的后端和前端协议,并在后端和前端之间中继消息。因此,数据库应用程序(前端)认为Pgpool-II是实际的PostgreSQL服务器,而服务器(后端)将Pgpool-II视为其客户端之一。由于 Pgpool-II对服务器和客户端都是透明的,因此现有数据库应用程序几乎可以与Pgpool-II一起使用,而无需更改其源代码。
1.2.2 PostgreSQL
PostgreSQL是一个功能强大的开源对象关系数据库系统,拥有30多年的积极开发经验,在可靠性,功能强大和性能方面赢得了极高的声誉。
1.3 方案架构
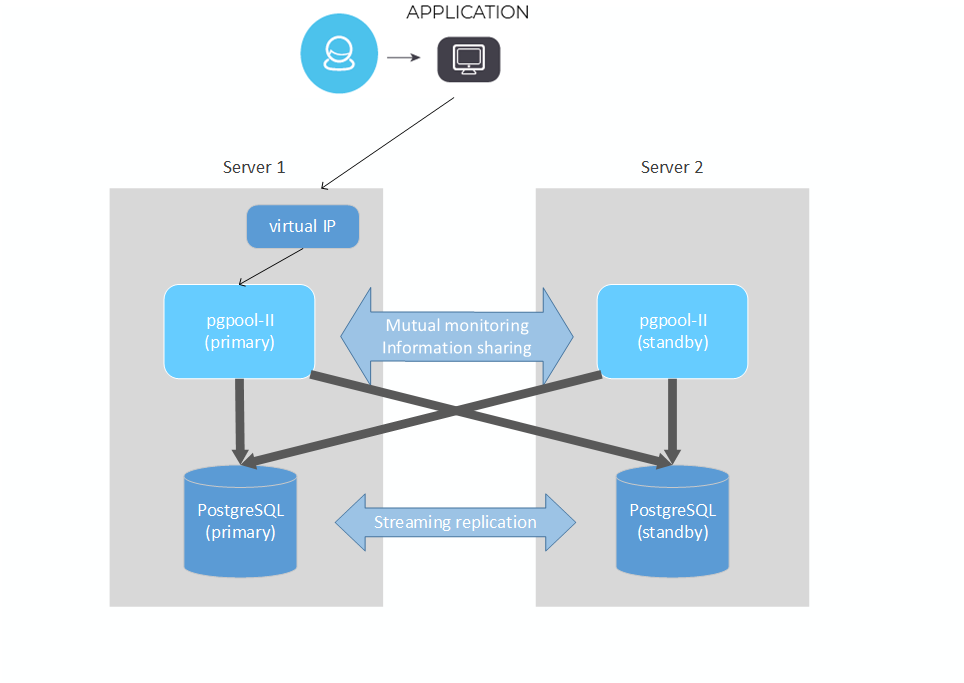
如图,我们在两台服务器上,分别部署PostgreSQL和pgpool-II 。两套PostgreSQL 通过流复制(streaming replication)实现数据同步。pgpool-II 监控数据库集群的状态,管理数据库集群,并将用户请求分发到数据库节点上。 此外Pgpool-II节点互相监控,并共享信息。而pgpool-II的主节点启动虚拟IP,作为对外访服务的地址。
1.4 方案的功能
1. 实现 pgpool-II 服务的高可用
在本方案中,当pgpool-II的主节点停止后,另一个节点会立即取代它并对外提供服务,除非两个节点上的pgpool服务都是异常的。
2. 实现PostgreSQL的高可用和在线恢复
若主数据库停止,则进行主备切换,即原备库切换为新主库,原主库切换为新主库的备库。在将原主库切换为备库的过程中,若发现原主库切换失败,则从新主库中全量拉取数据。
若主库所在服务器宕机,则备库切换为主库,当原主库服务器启动后自动切换为新主库的备库。
若备库服务停止,则自动拉起备库服务;
若备库服务停止,且无法正常拉起服务,则从主库中全量拉取数据;
若备库所在服务器宕机,不做任何处理,当备库服务器启动后自动切换为备库。
3. 负载均衡
客户端通过pgpool-II 访问PostgreSQL的写请求被发送给主库,而读请求可以随机发送给主库或备库。
1.5 运行环境
本方案需要两台服务器。配置信息如下:
硬件
内存:32G
CPU:16个逻辑CPU
操作系统:
CentOS 7.4
主要软件:
yum 3.4.3
python 2.7.6
PostgreSQL 11.4
pgpool-II 4.1
主服务器的ip地址是10.40.239.228,主机名是node228
备服务器的ip地址是10.40.239.229,主机名是node229
集群对外提供服务的虚拟IP 是10.40.239.240。
2 方案实现
2.1 安装 PostgreSQL
在两台服务器上进行如下操作。
1. 关闭防火墙和selinex:
[root@node228 ~]# systemctl disable --now firewalld
[root@node228 ~]# sed -e '/^ \{0,\}SELINUX=/c\SELINUX=disabled' -i /etc/selinux/config
[root@node228 ~]# setenforce 0
2. 创建用户postgres,它所属的用户组是postgres,用户的主目录是 /var/lib/pgsql:
[root@node228 ~]# useradd -m -d /var/lib/pgsql postgres
3. 为用户postgres 设置密码,我们在2.3节配置免密认证会需要:
[root@node228 ~]# passwd postgres
4. 安装PostgreSQL数据库的依赖包:
[root@node228 ~]# yum -y install readline-devel.x86_64 zlib-devel.x86_64 gcc.x86_64
[root@node228 ~]# yum -y install python python-devel
5. 下载PostgreSQL 11.4源码。
6. 在CentOS 服务器上,解压下载的文件:
[root@node228 ~]# tar zcxf postgresql-11.4.tar.gz
7. 进入解压后的目录,编译并安装postgresql,这里,在本文中,安装目录是/opt/pg114。
[root@node228 ~]# cd postgresql-11.4
[root@node228 postgresql-11.4]# ./configure --prefix=/opt/pg114/ --with-perl --with-python
[root@node228 postgresql-11.4]# make world
[root@node228 postgresql-11.4]# make install-world
8. 修改目录的属主为postgres:
[root@node228 postgresql-11.4]# chown -R postgres.postgres /opt/pg114/
9. 使用用户postgres创建数据库数据目录:
[root@node228 postgresql-11.4]# su postgres
[postgres@node228 postgresql-11.4]# cd /opt/pg114/bin
[postgres@node228 bin]# ./initdb -D /opt/pg114/data -E utf8 --lc-collate='en_US.UTF-8' --lc-ctype='en_US.UTF-8'
10. 登录数据库,修改postgres用户的密码,这里我们设置密码为abc12345:
[postgres@node228 bin]# ./psql -h 127.0.0.1 -U postgres -p 5432
连接成功后,在数据库中执行下列命令:
alter user postgres password 'abc12345';
\q
11. 修改 /data/pg_hba.conf,设置允许访问的ip地址,设置访问方式是 md5。
#TYPE DATABASE USER ADDRESS METHOD
local all all md5
host all all 127.0.0.1/32 md5
host all all ::1/128 md5
可根据实际情况添加其他访问控制项。
12. 根据需要,修改 postgresql.conf 中的一些参数。例如:
listen_addresses = '*'
logging_collector = on
2.2 搭建 PostgreSQL 主备环境
2.2.1 主节点上的操作
1. 确保服务已经启动。执行下面的命令,切换用户为postgres,进入PostgreSQL 的bin目录,并启动服务:
[root@node228 ~]# su postgres
[postgres@node228 root]# cd /opt/pg114/bin/
[postgres@node228 bin]# . /pg_ctl start -D ../data
2. 创建用于流复制的用户和用于检查pgpool集群状态的用户。执行下面的命令进入postgresql的控制台:
[postgres@node228 postgres]# ./psql -h 127.0.0.1 -p 5432 -U postgres
这里, 127.0.0.1 代表本机的回环地址, 5432代表数据库的端口, postgres代表连接数据库的用户。
执行如下语句创建用户:
create user repuser with login replication password 'repuser123';
create user checkuser with login password 'checkuser123';
这里,用户repuser用于流复制,它的密码是“repuser123”。
用户checkuser用于检查pgpool集群状态,它的密码是“checkuser123”。
3. 修改pg_hba.conf 文件,添加如下内容,允许两台计算机上的复制用户repuser和超级用户postgres登录:
host replication repuser 10.40.239.228/32 md5
host replication repuser 10.40.239.229/32 md5
host all all 10.40.239.228/32 md5
host all all 10.40.239.229/32 md5
可根据实际情况添加其他访问控制项。
4. 在主节点的数据库的配置文件 postgresql.conf(位于安装目录下data目录中) 中设置这些参数:
listen_addresses = '*'
max_wal_senders = 10
wal_level = replica
wal_log_hints = on
wal_keep_segments = 128
wal_receiver_status_interval = 5s
hot_standby_feedback = on
hot_standby = on
这些参数中的含义如下:
listen_addresses 表示服务器监听的地址,*表示任意地址;
max_wal_senders表示来自后备服务器或流式基础备份客户端的并发连接的最大数量;
wal_level 表示日志级别,对于流复制,它的值应设置为replica;
wal_log_hints = on表示,在PostgreSQL服务器一个检查点之后页面被第一次修改期间,把该磁盘页面的整个内容都写入 WAL,即使对所谓的提示位做非关键修改也会这样做;
wal_keep_segments 指定在后备服务器需要为流复制获取日志段文件的情况下,pg_wal (PostgreSQL 9.6 以下版本的是pg_xlog)目录下所能保留的过去日志文件段的最小数目;
log_connections 表示是否在日志中记录客户端对服务器的连接;
wal_receiver_status_interval 指定在后备机上的 WAL 接收者进程向主服务器或上游后备机发送有关复制进度的信息的最小周期;
hot_standby_feedback 指定一个热后备机是否将会向主服务器或上游后备机发送有关于后备机上当前正被执行的查询的反馈,这里设置为on;
hot_standby 这个参数对流复制中的后备服务器有效,表示在恢复期间,是否允许用户连接并查询备库。on 表示允许。
关于详细内容,可以参考postgresql官方文档。
5. 重启主节点:
[postgres@node228 bin]# ./pg_ctl restart -D /opt/pg114/data
6. 重启之后,连接数据库,执行下面的sql为主服务器和后备服务器创建复制槽:
select * from pg_create_physical_replication_slot('node228');
select * from pg_create_physical_replication_slot('node229');
复制槽 replication slot 的作用是:
1. 在流复制中,当一个备节点断开连接是时,备节点通过hot_standby_feedback 提供反馈数据数据会丢失。当备节点重新连接时,它可能因为被主节点发送清理记录而引发查询冲突。复制槽即使在备节点断开时仍然会记录下备节点的xmin(复制槽要需要数据库保留的最旧事务ID)值,从而确保不会有清理冲突。
2. 当一个备节点断开连接时,备节点需要的WAL文件信息也丢失了。如果没有复制槽,当备节点重连时,我们可能已经丢弃了所需要的WAL文件,因此需要完全重建备节点。
复制槽确保这个节点保留所有下游节点需要的wal文件。
2.2.2 备节点上的操作
1. 切换用户为postgres,并确保备节点上数据库服务是停止的:
[root@node228 ~]# su postgres
[postgres@node228 root]# cd /opt/pg114/bin/
[postgres@node228 bin]# . /pg_ctl stop -D ../data
关闭服务。
2. 首先删除备节点中的数据目录中的文件:
[postgres@node229 bin]# rm -rf /opt/pg114/data/*
然后使用pg_basebackup将主机的数据备份到备机:
[postgres@node229 bin]# ./pg_basebackup -Xs -d "hostaddr=10.40.239.228 port=5432 user=repuser password=repuser123" -D /opt/pg114/data -v -Fp
这里,-Xs 表示复制方式是流式的(stream),这种方式不会复制在此次备份开始前,已经归档完成的WAL文件;-d 后面是一个连接字符串,其中“hostaddr=10.40.239.228”表示主服务器的ip地址是10.40.239.228,“port=5432”表示数据库的端口是5432,“user=repuser”表示用于流复制的用户是repuser, “password=repuser123”表示密码是repuser123;“-D ../data”表示将备份内容输入到本地的 /opt/pg114/data 目录;“-v”表示打印详细信息,–Fp 表示复制结果输出位普通(plain)文件。
3. 将 /opt/postgresql11/share/ 中的 recovery.conf.sample 拷贝到 /opt/pg114/data 下,重命名为 recovery.conf:
[postgres@node229 bin]# cp /opt/postgresql11/share/recovery.conf.sample /opt/pg114/data/recovery.conf
修改/opt/pg114/data/recovery.conf,设置如下参数:
recovery_target_timeline = 'latest'
standby_mode = on
primary_conninfo = 'host=10.40.239.228 port=5432 user=repuser password=repuser123'
primary_slot_name = 'node229'
trigger_file = 'tgfile'
这些参数的含义如下:
recovery_target_timeline 表示恢复到数据库时间线的上的什么时间点,这里设置为latest,即最新。
standby_mode 表示是否将PostgreSQL服务器作为一个后备服务器启动,这里设置为on,即后备模式。
primary_conninfo指定后备服务器用来连接主服务器的连接字符串,其中“host=10.40.239.228”表示主服务器的ip地址是10.40.239.228;“port=5432”表示数据库的端口是5432;“user=repuser”表示用于流复制的用户是repuser; “password=repuser123”表示密码是repuser123。
primary_slot_name 指定通过流复制连接到主服务器时使用一个现有的复制槽来控制上游节点上的资源移除。这里我们指定3.2.1节创建的node229。如果没有在主服务器上创建复制槽,则不配置此参数。
trigger_file指定一个触发器文件,该文件的存在会结束后备机中的恢复,使它成为主机。
4. 启动备节点服务:
[postgres@node229 bin]# ./pg_ctl start -D /opt/pg114/data
2.2.3 主备环境检测
1. 在主节点的上创建一个表,并插入数据:
postgres=# create table man (id int, name text);
CREATE TABLE
postgres=# insert into man (id, name) values (1,'tom');
INSERT 0 1
2. 在备节点上检测:
postgres=# select * from man;
id | name
----+------
1 | tom
可以看到,主节点数据同步到了备机。
3. 同时,在备节点上写数据会失败:
postgres=# insert into man (id, name) values (2,'amy');
ERROR: cannot execute INSERT in a read-only transaction
2.3 配置ssh免密认证
在两台服务器上执行下面的操作。
1. 使用postgres生成ssh密钥,它包含公钥和私钥:
[root@node228 ~]# su -i postgres
[postgres@node228 ~]$ ssh-keygen -t rsa
2. 执行下面的命令,将这台服务器上的公钥(~/.ssh/id_rsa.pub中的内容)复制到两台服务器的认证文件(~/.ssh/authorized_keys) 中:
[postgres@node228 ~]# ssh-copy-id postgres@10.40.239.228
[postgres@node228 ~]# ssh-copy-id postgres@10.40.239.229
2.4 搭建 pgpool 主备环境
我们需要分别在node228 , node229上安装和配置pgpool-II,步骤如下:
2.4.1 安装 pgpool
1. 关闭防火墙:
[root@node228 ~]# systemctl disable --now firewalld
2. 关闭selinex:
[root@node228 ~]# sed -e '/^ \{0,\}SELINUX=/c\SELINUX=disabled' -i /etc/selinux/config
[root@node228 ~]# setenforce 0
3. 安装pgpool yum源(需要连接外网):
[root@node228 ~]# yum install http://www.pgpool.net/yum/rpms/4.1/redhat/rhel-7-x86_64/pgpool-II-release-4.1-1.noarch.rpm
4. 安装pgpool包:
[root@node228 ~]# yum -y install pgpool-II-pg11-debuginfo.x86_64 pgpool-II-pg11-devel.x86_64 pgpool-II-pg11-extensions.x86_64 pgpool-II-release.noarch
pgpool 安装成功后,会生成一个目录 /etc/pgpool-II/,包含pgpool 相关的客户端和服务端的配置文件。
5. 将此目录中文件的属主修改为postgres:
[root@node228 ~]# chown postgres.postgres /etc/pgpool-II/*
2.4.2 配置 pgpool
这一节的操作都使用用户postgres 完成。
1. 切换为用户postgres,并进入目录 /etc/pgpool-II/:
[root@node228 ~]# su postgres
[postgres@node228 ~]# cd /etc/pgpool-II/
2. 修改pgpool服务端的配置文件pcp.conf,并设置它的权限为仅允许所属用户读写。它的作用是记录用来管理pgpool-II集群的用户的名称和密码。它的内容格式为:
username:password(密文)
本文中,pcp用户是pgpool,密码是 pgpool。具体方法是执行下面的命令:
[postgres@node228 ~]# cd /etc/pgpool-II/
[postgres@node228 pgpool-II]# echo pgpool:$(pg_md5 -u pgpool pgpool) >/etc/pgpool-II/pcp.conf
[postgres@node228 pgpool-II]# chmod 600 /etc/pgpool-II/pcp.conf
3. 修改pgpool服务端的配置文件pool_hba.conf。它的作用是限制pgpool的访问权限,格式同PostgreSQL数据库的pg_hba.conf。我们可以先复制pg_hba.conf的内容到pool_hba.conf,并根据实际添加访问控制项。具体命令如下:
[postgres@node228 pgpool-II]# cp /opt/pg114/data/pg_hba.conf /etc/pgpool-II/pool_hba.conf
4. 修改pgpool服务端的配置文件pool_passwd,并设置它的权限为仅允许所属用户读写。它的作用是记录允许通过pgpool来访问数据库的用户的名称和密码(密文)。它的内容格式为:
username:password(密文)
具体方法是执行下面的命令:
[postgres@node228 pgpool-II]# /opt/pg114/bin/psql -U postgres -h 10.40.239.228 -p 5432 -t -c "select rolname || ':' || rolpassword from pg_authid where rolpassword is not null ;" > /etc/pgpool-II/pool_passwd
[postgres@node228 pgpool-II]# sed -e 's/ //g' -i /etc/pgpool-II/pool_passwd
[postgres@node228 pgpool-II]# chmod 600 /etc/pgpool-II/pool_passwd
5. 在当前目录下,配置PostgreSQL 的密码文件 .pgpass和 pcp(即管理pgpool-II 集群)用户的密码文件 .pcppass,并设置它们的权限为仅允许所属用户读写。它们分别为你访问数据库和管理pgpool-II 提供凭据。
注意,文件 .pgpass 的内容格式为:
hostname:port:database:username:password
文件 .pcppass的内容格式为:
hostname:port:username:password
编辑文件 .pgpass,内容如下:
10.40.239.228:5432:replication:repuser:repuser123
10.40.239.229:5432:replication:repuser:repuser123
node228:5432:*:repuser:repuser123
node229:5432:*:repuser:repuser123
127.0.0.1:5432:*:postgres:abc12345
localhost:5432:*:postgres:abc12345
10.40.239.228:5432:*:postgres:abc12345
10.40.239.229:5432:*:postgres:abc12345
node228:5432:*:postgres:abc12345
node229:5432:*:postgres:abc12345
编辑文件 .pcppass,内容如下:
localhost:9898:pgpool:pgpool
127.0.0.1:9898:pgpool:pgpool
设置它的权限为仅允许所属用户读写:
[postgres@node228 pgpool-II]# chmod 600 /etc/pgpool-II/.pgpass
[postgres@node228 pgpool-II]# chmod 600 /etc/pgpool-II/.pcppass
|
[小提示] 或许你也知道,如果 .pgpass和 .pcppass是配置在用户 postgres 的Home目录中的,那么它们也能被pgpool读取。但我们不建议这样做。这些密码文件应该只配置在 pgpool-II 的工作目录中,以防止被其他应用程序读取或修改。 |
6. 修改pgpool配置文件pgpool.conf,并设置它的权限为仅允许所属用户读写。这个文件默认在/etc/pgpool-II/目录下,作用为pgpool集群的配置文件。
上传配置文件pgpool.conf 到10.40.239.228节点的/etc/pgpool-II目录下;


# ----------------------------
# pgPool-II configuration file
# ----------------------------
#
# This file consists of lines of the form:
#
# name = value
#
# Whitespace may be used. Comments are introduced with "#" anywhere on a line.
# The complete list of parameter names and allowed values can be found in the
# pgPool-II documentation.
#
# This file is read on server startup and when the server receives a SIGHUP
# signal. If you edit the file on a running system, you have to SIGHUP the
# server for the changes to take effect, or use "pgpool reload". Some
# parameters, which are marked below, require a server shutdown and restart to
# take effect.
#
#------------------------------------------------------------------------------
# CONNECTIONS
#------------------------------------------------------------------------------
# - pgpool Connection Settings -
listen_addresses = '*'
# Host name or IP address to listen on:
# '*' for all, '' for no TCP/IP connections
# (change requires restart)
port = 9999
# Port number
# (change requires restart)
socket_dir = '/opt/pgpool/'
# Unix domain socket path
# The Debian package defaults to
# /var/run/postgresql
# (change requires restart)
reserved_connections = 0
# Number of reserved connections.
# Pgpool-II does not accept connections if over
# num_init_chidlren - reserved_connections.
# - pgpool Communication Manager Connection Settings -
pcp_listen_addresses = '*'
# Host name or IP address for pcp process to listen on:
# '*' for all, '' for no TCP/IP connections
# (change requires restart)
pcp_port = 9898
# Port number for pcp
# (change requires restart)
pcp_socket_dir = '/opt/pgpool/'
# Unix domain socket path for pcp
# The Debian package defaults to
# /var/run/postgresql
# (change requires restart)
listen_backlog_multiplier = 2
# Set the backlog parameter of listen(2) to
# num_init_children * listen_backlog_multiplier.
# (change requires restart)
serialize_accept = off
# whether to serialize accept() call to avoid thundering herd problem
# (change requires restart)
# - Backend Connection Settings -
backend_hostname0 = 'node228'
# Host name or IP address to connect to for backend 0
backend_port0 = 5432
# Port number for backend 0
backend_weight0 = 1
# Weight for backend 0 (only in load balancing mode)
backend_data_directory0 = '/opt/pg114/data/'
# Data directory for backend 0
backend_flag0 = 'ALLOW_TO_FAILOVER'
# Controls various backend behavior
# ALLOW_TO_FAILOVER, DISALLOW_TO_FAILOVER
# or ALWAYS_MASTER
backend_application_name0 = 'server0'
# walsender's application_name, used for "show pool_nodes" command
backend_hostname1 = 'node229'
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/opt/pg114/data/'
backend_flag1 = 'ALLOW_TO_FAILOVER'
backend_application_name1 = 'server1'
# - Authentication -
enable_pool_hba = on
# Use pool_hba.conf for client authentication
pool_passwd = 'pool_passwd'
# File name of pool_passwd for md5 authentication.
# "" disables pool_passwd.
# (change requires restart)
authentication_timeout = 60
# Delay in seconds to complete client authentication
# 0 means no timeout.
allow_clear_text_frontend_auth = off
# Allow Pgpool-II to use clear text password authentication
# with clients, when pool_passwd does not
# contain the user password
# - SSL Connections -
ssl = off
# Enable SSL support
# (change requires restart)
#ssl_key = './server.key'
# Path to the SSL private key file
# (change requires restart)
#ssl_cert = './server.cert'
# Path to the SSL public certificate file
# (change requires restart)
#ssl_ca_cert = ''
# Path to a single PEM format file
# containing CA root certificate(s)
# (change requires restart)
#ssl_ca_cert_dir = ''
# Directory containing CA root certificate(s)
# (change requires restart)
ssl_ciphers = 'HIGH:MEDIUM:+3DES:!aNULL'
# Allowed SSL ciphers
# (change requires restart)
ssl_prefer_server_ciphers = off
# Use server's SSL cipher preferences,
# rather than the client's
# (change requires restart)
ssl_ecdh_curve = 'prime256v1'
# Name of the curve to use in ECDH key exchange
ssl_dh_params_file = ''
# Name of the file containing Diffie-Hellman parameters used
# for so-called ephemeral DH family of SSL cipher.
#------------------------------------------------------------------------------
# POOLS
#------------------------------------------------------------------------------
# - Concurrent session and pool size -
num_init_children = 32
# Number of concurrent sessions allowed
# (change requires restart)
max_pool = 4
# Number of connection pool caches per connection
# (change requires restart)
# - Life time -
child_life_time = 300
# Pool exits after being idle for this many seconds
child_max_connections = 0
# Pool exits after receiving that many connections
# 0 means no exit
connection_life_time = 0
# Connection to backend closes after being idle for this many seconds
# 0 means no close
client_idle_limit = 0
# Client is disconnected after being idle for that many seconds
# (even inside an explicit transactions!)
# 0 means no disconnection
#------------------------------------------------------------------------------
# LOGS
#------------------------------------------------------------------------------
# - Where to log -
log_destination = 'syslog'
# Where to log
# Valid values are combinations of stderr,
# and syslog. Default to stderr.
# - What to log -
log_line_prefix = '%t: pid %p: ' # printf-style string to output at beginning of each log line.
log_connections = on
# Log connections
log_hostname = on
# Hostname will be shown in ps status
# and in logs if connections are logged
log_statement = off
# Log all statements
log_per_node_statement = off
# Log all statements
# with node and backend informations
log_client_messages = off
# Log any client messages
log_standby_delay = 'if_over_threshold'
# Log standby delay
# Valid values are combinations of always,
# if_over_threshold, none
# - Syslog specific -
syslog_facility = 'LOCAL0'
# Syslog local facility. Default to LOCAL0
syslog_ident = 'pgpool'
# Syslog program identification string
# Default to 'pgpool'
# - Debug -
#log_error_verbosity = default # terse, default, or verbose messages
#client_min_messages = notice # values in order of decreasing detail:
# debug5
# debug4
# debug3
# debug2
# debug1
# log
# notice
# warning
# error
#log_min_messages = warning # values in order of decreasing detail:
# debug5
# debug4
# debug3
# debug2
# debug1
# info
# notice
# warning
# error
# log
# fatal
# panic
#------------------------------------------------------------------------------
# FILE LOCATIONS
#------------------------------------------------------------------------------
pid_file_name = '/opt/pgpool/pgpool.pid'
# PID file name
# Can be specified as relative to the"
# location of pgpool.conf file or
# as an absolute path
# (change requires restart)
logdir = '/opt/pgpool/'
# Directory of pgPool status file
# (change requires restart)
#------------------------------------------------------------------------------
# CONNECTION POOLING
#------------------------------------------------------------------------------
connection_cache = on
# Activate connection pools
# (change requires restart)
# Semicolon separated list of queries
# to be issued at the end of a session
# The default is for 8.3 and later
reset_query_list = 'ABORT; DISCARD ALL'
# The following one is for 8.2 and before
#reset_query_list = 'ABORT; RESET ALL; SET SESSION AUTHORIZATION DEFAULT'
#------------------------------------------------------------------------------
# REPLICATION MODE
#------------------------------------------------------------------------------
replication_mode = off
# Activate replication mode
# (change requires restart)
replicate_select = off
# Replicate SELECT statements
# when in replication mode
# replicate_select is higher priority than
# load_balance_mode.
insert_lock = off
# Automatically locks a dummy row or a table
# with INSERT statements to keep SERIAL data
# consistency
# Without SERIAL, no lock will be issued
lobj_lock_table = ''
# When rewriting lo_creat command in
# replication mode, specify table name to
# lock
# - Degenerate handling -
replication_stop_on_mismatch = off
# On disagreement with the packet kind
# sent from backend, degenerate the node
# which is most likely "minority"
# If off, just force to exit this session
failover_if_affected_tuples_mismatch = off
# On disagreement with the number of affected
# tuples in UPDATE/DELETE queries, then
# degenerate the node which is most likely
# "minority".
# If off, just abort the transaction to
# keep the consistency
#------------------------------------------------------------------------------
# LOAD BALANCING MODE
#------------------------------------------------------------------------------
load_balance_mode = on
# Activate load balancing mode
# (change requires restart)
ignore_leading_white_space = on
# Ignore leading white spaces of each query
white_function_list = ''
# Comma separated list of function names
# that don't write to database
# Regexp are accepted
black_function_list = 'currval,lastval,nextval,setval,func_*,f_*'
# Comma separated list of function names
# that write to database
# Regexp are accepted
black_query_pattern_list = ''
# Semicolon separated list of query patterns
# that should be sent to primary node
# Regexp are accepted
# valid for streaming replicaton mode only.
database_redirect_preference_list = ''
# comma separated list of pairs of database and node id.
# example: postgres:primary,mydb[0-4]:1,mydb[5-9]:2'
# valid for streaming replicaton mode only.
app_name_redirect_preference_list = ''
# comma separated list of pairs of app name and node id.
# example: 'psql:primary,myapp[0-4]:1,myapp[5-9]:standby'
# valid for streaming replicaton mode only.
allow_sql_comments = off
# if on, ignore SQL comments when judging if load balance or
# query cache is possible.
# If off, SQL comments effectively prevent the judgment
# (pre 3.4 behavior).
disable_load_balance_on_write = 'transaction'
# Load balance behavior when write query is issued
# in an explicit transaction.
# Note that any query not in an explicit transaction
# is not affected by the parameter.
# 'transaction' (the default): if a write query is issued,
# subsequent read queries will not be load balanced
# until the transaction ends.
# 'trans_transaction': if a write query is issued,
# subsequent read queries in an explicit transaction
# will not be load balanced until the session ends.
# 'always': if a write query is issued, read queries will
# not be load balanced until the session ends.
statement_level_load_balance = off
# Enables statement level load balancing
#------------------------------------------------------------------------------
# MASTER/SLAVE MODE
#------------------------------------------------------------------------------
master_slave_mode = on
# Activate master/slave mode
# (change requires restart)
master_slave_sub_mode = 'stream'
# Master/slave sub mode
# Valid values are combinations stream, slony
# or logical. Default is stream.
# (change requires restart)
# - Streaming -
sr_check_period = 10
# Streaming replication check period
# Disabled (0) by default
sr_check_user = 'repuser'
# Streaming replication check user
# This is neccessary even if you disable streaming
# replication delay check by sr_check_period = 0
sr_check_password = 'repuser123'
# Password for streaming replication check user
# Leaving it empty will make Pgpool-II to first look for the
# Password in pool_passwd file before using the empty password
sr_check_database = 'postgres'
# Database name for streaming replication check
delay_threshold = 10000000
# Threshold before not dispatching query to standby node
# Unit is in bytes
# Disabled (0) by default
# - Special commands -
follow_master_command = '/etc/pgpool-II/follow_master.sh %d %h %D %H %r '
# Executes this command after master failover
# Special values:
# %d = failed node id
# %h = failed node host name
# %p = failed node port number
# %D = failed node database cluster path
# %m = new master node id
# %H = new master node hostname
# %M = old master node id
# %P = old primary node id
# %r = new master port number
# %R = new master database cluster path
# %N = old primary node hostname
# %S = old primary node port number
# %% = '%' character
#------------------------------------------------------------------------------
# HEALTH CHECK GLOBAL PARAMETERS
#------------------------------------------------------------------------------
health_check_period = 10
# Health check period
# Disabled (0) by default
health_check_timeout = 20
# Health check timeout
# 0 means no timeout
health_check_user = 'checkuser'
# Health check user
health_check_password = 'checkuser123'
# Password for health check user
# Leaving it empty will make Pgpool-II to first look for the
# Password in pool_passwd file before using the empty password
health_check_database = 'postgres'
# Database name for health check. If '', tries 'postgres' frist, then 'template1'
health_check_max_retries = 3
# Maximum number of times to retry a failed health check before giving up.
health_check_retry_delay = 1
# Amount of time to wait (in seconds) between retries.
connect_timeout = 10000
# Timeout value in milliseconds before giving up to connect to backend.
# Default is 10000 ms (10 second). Flaky network user may want to increase
# the value. 0 means no timeout.
# Note that this value is not only used for health check,
# but also for ordinary conection to backend.
#------------------------------------------------------------------------------
# HEALTH CHECK PER NODE PARAMETERS (OPTIONAL)
#------------------------------------------------------------------------------
#health_check_period0 = 0
#health_check_timeout0 = 20
#health_check_user0 = 'checkuser'
#health_check_password0 = ''
#health_check_database0 = ''
#health_check_max_retries0 = 0
#health_check_retry_delay0 = 1
#connect_timeout0 = 10000
#------------------------------------------------------------------------------
# FAILOVER AND FAILBACK
#------------------------------------------------------------------------------
failover_command = '/etc/pgpool-II/failover.sh %d %h %D %m %H %r %P %R '
# Executes this command at failover
# Special values:
# %d = failed node id
# %h = failed node host name
# %p = failed node port number
# %D = failed node database cluster path
# %m = new master node id
# %H = new master node hostname
# %M = old master node id
# %P = old primary node id
# %r = new master port number
# %R = new master database cluster path
# %N = old primary node hostname
# %S = old primary node port number
# %% = '%' character
failback_command = ''
# Executes this command at failback.
# Special values:
# %d = failed node id
# %h = failed node host name
# %p = failed node port number
# %D = failed node database cluster path
# %m = new master node id
# %H = new master node hostname
# %M = old master node id
# %P = old primary node id
# %r = new master port number
# %R = new master database cluster path
# %N = old primary node hostname
# %S = old primary node port number
# %% = '%' character
failover_on_backend_error = on
# Initiates failover when reading/writing to the
# backend communication socket fails
# If set to off, pgpool will report an
# error and disconnect the session.
detach_false_primary = off
# Detach false primary if on. Only
# valid in streaming replicaton
# mode and with PostgreSQL 9.6 or
# after.
search_primary_node_timeout = 3
# Timeout in seconds to search for the
# primary node when a failover occurs.
# 0 means no timeout, keep searching
# for a primary node forever.
#------------------------------------------------------------------------------
# ONLINE RECOVERY
#------------------------------------------------------------------------------
recovery_user = 'nobody'
# Online recovery user
recovery_password = ''
# Online recovery password
# Leaving it empty will make Pgpool-II to first look for the
# Password in pool_passwd file before using the empty password
recovery_1st_stage_command = ''
# Executes a command in first stage
recovery_2nd_stage_command = ''
# Executes a command in second stage
recovery_timeout = 90
# Timeout in seconds to wait for the
# recovering node's postmaster to start up
# 0 means no wait
client_idle_limit_in_recovery = 0
# Client is disconnected after being idle
# for that many seconds in the second stage
# of online recovery
# 0 means no disconnection
# -1 means immediate disconnection
auto_failback = on
# Dettached backend node reattach automatically
# if replication_state is 'streaming'.
auto_failback_interval = 30
# Min interval of executing auto_failback in
# seconds.
#------------------------------------------------------------------------------
# WATCHDOG
#------------------------------------------------------------------------------
# - Enabling -
use_watchdog = on
# Activates watchdog
# (change requires restart)
# -Connection to up stream servers -
trusted_servers = 'node228,node229'
# trusted server list which are used
# to confirm network connection
# (hostA,hostB,hostC,...)
# (change requires restart)
ping_path = '/bin'
# ping command path
# (change requires restart)
# - Watchdog communication Settings -
wd_hostname = 'node228'
# Host name or IP address of this watchdog
# (change requires restart)
wd_port = 9000
# port number for watchdog service
# (change requires restart)
wd_priority = 1
# priority of this watchdog in leader election
# (change requires restart)
wd_authkey = ''
# Authentication key for watchdog communication
# (change requires restart)
wd_ipc_socket_dir = '/opt/pgpool'
# Unix domain socket path for watchdog IPC socket
# The Debian package defaults to
# /var/run/postgresql
# (change requires restart)
# - Virtual IP control Setting -
delegate_IP = '10.40.239.240'
# delegate IP address
# If this is empty, virtual IP never bring up.
# (change requires restart)
if_cmd_path = '/usr/sbin'
# path to the directory where if_up/down_cmd exists
# If if_up/down_cmd starts with "/", if_cmd_path will be ignored.
# (change requires restart)
if_up_cmd = 'ip addr add $_IP_$/24 dev ens33 label ens33:0'
# startup delegate IP command
# (change requires restart)
if_down_cmd = 'ip addr del $_IP_$/24 dev ens33'
# shutdown delegate IP command
# (change requires restart)
arping_path = '/usr/sbin'
# arping command path
# If arping_cmd starts with "/", if_cmd_path will be ignored.
# (change requires restart)
arping_cmd = 'arping -U $_IP_$ -w 1 -I ens33'
# arping command
# (change requires restart)
# - Behaivor on escalation Setting -
clear_memqcache_on_escalation = on
# Clear all the query cache on shared memory
# when standby pgpool escalate to active pgpool
# (= virtual IP holder).
# This should be off if client connects to pgpool
# not using virtual IP.
# (change requires restart)
wd_escalation_command = ''
# Executes this command at escalation on new active pgpool.
# (change requires restart)
wd_de_escalation_command = ''
# Executes this command when master pgpool resigns from being master.
# (change requires restart)
# - Watchdog consensus settings for failover -
failover_when_quorum_exists = on
# Only perform backend node failover
# when the watchdog cluster holds the quorum
# (change requires restart)
failover_require_consensus = on
# Perform failover when majority of Pgpool-II nodes
# aggrees on the backend node status change
# (change requires restart)
allow_multiple_failover_requests_from_node = on
# A Pgpool-II node can cast multiple votes
# for building the consensus on failover
# (change requires restart)
enable_consensus_with_half_votes = on
# apply majority rule for consensus and quorum computation
# at 50% of votes in a cluster with even number of nodes.
# when enabled the existence of quorum and consensus
# on failover is resolved after receiving half of the
# total votes in the cluster, otherwise both these
# decisions require at least one more vote than
# half of the total votes.
# (change requires restart)
# - Lifecheck Setting -
# -- common --
wd_monitoring_interfaces_list = '' # Comma separated list of interfaces names to monitor.
# if any interface from the list is active the watchdog will
# consider the network is fine
# 'any' to enable monitoring on all interfaces except loopback
# '' to disable monitoring
# (change requires restart)
wd_lifecheck_method = 'heartbeat'
# Method of watchdog lifecheck ('heartbeat' or 'query' or 'external')
# (change requires restart)
wd_interval = 10
# lifecheck interval (sec) > 0
# (change requires restart)
# -- heartbeat mode --
wd_heartbeat_port = 9694
# Port number for receiving heartbeat signal
# (change requires restart)
wd_heartbeat_keepalive = 2
# Interval time of sending heartbeat signal (sec)
# (change requires restart)
wd_heartbeat_deadtime = 30
# Deadtime interval for heartbeat signal (sec)
# (change requires restart)
heartbeat_destination0 = 'node229'
# Host name or IP address of destination 0
# for sending heartbeat signal.
# (change requires restart)
heartbeat_destination_port0 = 9694
# Port number of destination 0 for sending
# heartbeat signal. Usually this is the
# same as wd_heartbeat_port.
# (change requires restart)
heartbeat_device0 = 'ens33'
# Name of NIC device (such like 'eth0')
# used for sending/receiving heartbeat
# signal to/from destination 0.
# This works only when this is not empty
# and pgpool has root privilege.
# (change requires restart)
#heartbeat_destination1 = ''
#heartbeat_destination_port1 = 9694
#heartbeat_device1 = 'ens33'
# -- query mode --
wd_life_point = 3
# lifecheck retry times
# (change requires restart)
wd_lifecheck_query = 'SELECT 1'
# lifecheck query to pgpool from watchdog
# (change requires restart)
wd_lifecheck_dbname = 'postgres'
# Database name connected for lifecheck
# (change requires restart)
wd_lifecheck_user = 'checkuser'
# watchdog user monitoring pgpools in lifecheck
# (change requires restart)
wd_lifecheck_password = 'checkuser123'
# Password for watchdog user in lifecheck
# Leaving it empty will make Pgpool-II to first look for the
# Password in pool_passwd file before using the empty password
# (change requires restart)
# - Other pgpool Connection Settings -
other_pgpool_hostname0 = 'node229'
# Host name or IP address to connect to for other pgpool 0
# (change requires restart)
other_pgpool_port0 = 9999
# Port number for other pgpool 0
# (change requires restart)
other_wd_port0 = 9000
# # Port number for other watchdog 0
# # (change requires restart)
#other_pgpool_hostname1 = ''
#other_pgpool_port1 = 9999
#other_wd_port1 = 9000
#------------------------------------------------------------------------------
# OTHERS
#------------------------------------------------------------------------------
relcache_expire = 0
# Life time of relation cache in seconds.
# 0 means no cache expiration(the default).
# The relation cache is used for cache the
# query result against PostgreSQL system
# catalog to obtain various information
# including table structures or if it's a
# temporary table or not. The cache is
# maintained in a pgpool child local memory
# and being kept as long as it survives.
# If someone modify the table by using
# ALTER TABLE or some such, the relcache is
# not consistent anymore.
# For this purpose, cache_expiration
# controls the life time of the cache.
relcache_size = 256
# Number of relation cache
# entry. If you see frequently:
# "pool_search_relcache: cache replacement happend"
# in the pgpool log, you might want to increate this number.
check_temp_table = catalog
# Temporary table check method. catalog, trace or none.
# Default is catalog.
check_unlogged_table = on
# If on, enable unlogged table check in SELECT statements.
# This initiates queries against system catalog of primary/master
# thus increases load of master.
# If you are absolutely sure that your system never uses unlogged tables
# and you want to save access to primary/master, you could turn this off.
# Default is on.
enable_shared_relcache = on
# If on, relation cache stored in memory cache,
# the cache is shared among child process.
# Default is on.
# (change requires restart)
relcache_query_target = master # Target node to send relcache queries. Default is master (primary) node.
# If load_balance_node is specified, queries will be sent to load balance node.
#------------------------------------------------------------------------------
# IN MEMORY QUERY MEMORY CACHE
#------------------------------------------------------------------------------
memory_cache_enabled = off
# If on, use the memory cache functionality, off by default
# (change requires restart)
memqcache_method = 'shmem'
# Cache storage method. either 'shmem'(shared memory) or
# 'memcached'. 'shmem' by default
# (change requires restart)
memqcache_memcached_host = 'localhost'
# Memcached host name or IP address. Mandatory if
# memqcache_method = 'memcached'.
# Defaults to localhost.
# (change requires restart)
memqcache_memcached_port = 11211
# Memcached port number. Mondatory if memqcache_method = 'memcached'.
# Defaults to 11211.
# (change requires restart)
memqcache_total_size = 67108864
# Total memory size in bytes for storing memory cache.
# Mandatory if memqcache_method = 'shmem'.
# Defaults to 64MB.
# (change requires restart)
memqcache_max_num_cache = 1000000
# Total number of cache entries. Mandatory
# if memqcache_method = 'shmem'.
# Each cache entry consumes 48 bytes on shared memory.
# Defaults to 1,000,000(45.8MB).
# (change requires restart)
memqcache_expire = 0
# Memory cache entry life time specified in seconds.
# 0 means infinite life time. 0 by default.
# (change requires restart)
memqcache_auto_cache_invalidation = on
# If on, invalidation of query cache is triggered by corresponding
# DDL/DML/DCL(and memqcache_expire). If off, it is only triggered
# by memqcache_expire. on by default.
# (change requires restart)
memqcache_maxcache = 409600
# Maximum SELECT result size in bytes.
# Must be smaller than memqcache_cache_block_size. Defaults to 400KB.
# (change requires restart)
memqcache_cache_block_size = 1048576
# Cache block size in bytes. Mandatory if memqcache_method = 'shmem'.
# Defaults to 1MB.
# (change requires restart)
memqcache_oiddir = '/tmp/oiddir'
# Temporary work directory to record table oids
# (change requires restart)
white_memqcache_table_list = ''
# Comma separated list of table names to memcache
# that don't write to database
# Regexp are accepted
black_memqcache_table_list = ''
# Comma separated list of table names not to memcache
# that don't write to database
# Regexp are accepted
上传配置文件 pgpool.conf 到10.40.239.229节点的/etc/pgpool-II目录下。
# ----------------------------
# pgPool-II configuration file
# ----------------------------
#
# This file consists of lines of the form:
#
# name = value
#
# Whitespace may be used. Comments are introduced with "#" anywhere on a line.
# The complete list of parameter names and allowed values can be found in the
# pgPool-II documentation.
#
# This file is read on server startup and when the server receives a SIGHUP
# signal. If you edit the file on a running system, you have to SIGHUP the
# server for the changes to take effect, or use "pgpool reload". Some
# parameters, which are marked below, require a server shutdown and restart to
# take effect.
#
#------------------------------------------------------------------------------
# CONNECTIONS
#------------------------------------------------------------------------------
# - pgpool Connection Settings -
listen_addresses = '*'
# Host name or IP address to listen on:
# '*' for all, '' for no TCP/IP connections
# (change requires restart)
port = 9999
# Port number
# (change requires restart)
socket_dir = '/opt/pgpool/'
# Unix domain socket path
# The Debian package defaults to
# /var/run/postgresql
# (change requires restart)
reserved_connections = 0
# Number of reserved connections.
# Pgpool-II does not accept connections if over
# num_init_chidlren - reserved_connections.
# - pgpool Communication Manager Connection Settings -
pcp_listen_addresses = '*'
# Host name or IP address for pcp process to listen on:
# '*' for all, '' for no TCP/IP connections
# (change requires restart)
pcp_port = 9898
# Port number for pcp
# (change requires restart)
pcp_socket_dir = '/opt/pgpool/'
# Unix domain socket path for pcp
# The Debian package defaults to
# /var/run/postgresql
# (change requires restart)
listen_backlog_multiplier = 2
# Set the backlog parameter of listen(2) to
# num_init_children * listen_backlog_multiplier.
# (change requires restart)
serialize_accept = off
# whether to serialize accept() call to avoid thundering herd problem
# (change requires restart)
# - Backend Connection Settings -
backend_hostname0 = 'node228'
# Host name or IP address to connect to for backend 0
backend_port0 = 5432
# Port number for backend 0
backend_weight0 = 1
# Weight for backend 0 (only in load balancing mode)
backend_data_directory0 = '/opt/pg114/data/'
# Data directory for backend 0
backend_flag0 = 'ALLOW_TO_FAILOVER'
# Controls various backend behavior
# ALLOW_TO_FAILOVER, DISALLOW_TO_FAILOVER
# or ALWAYS_MASTER
backend_application_name0 = 'server0'
# walsender's application_name, used for "show pool_nodes" command
backend_hostname1 = 'node229'
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/opt/pg114/data/'
backend_flag1 = 'ALLOW_TO_FAILOVER'
backend_application_name1 = 'server1'
# - Authentication -
enable_pool_hba = on
# Use pool_hba.conf for client authentication
pool_passwd = 'pool_passwd'
# File name of pool_passwd for md5 authentication.
# "" disables pool_passwd.
# (change requires restart)
authentication_timeout = 60
# Delay in seconds to complete client authentication
# 0 means no timeout.
allow_clear_text_frontend_auth = off
# Allow Pgpool-II to use clear text password authentication
# with clients, when pool_passwd does not
# contain the user password
# - SSL Connections -
ssl = off
# Enable SSL support
# (change requires restart)
#ssl_key = './server.key'
# Path to the SSL private key file
# (change requires restart)
#ssl_cert = './server.cert'
# Path to the SSL public certificate file
# (change requires restart)
#ssl_ca_cert = ''
# Path to a single PEM format file
# containing CA root certificate(s)
# (change requires restart)
#ssl_ca_cert_dir = ''
# Directory containing CA root certificate(s)
# (change requires restart)
ssl_ciphers = 'HIGH:MEDIUM:+3DES:!aNULL'
# Allowed SSL ciphers
# (change requires restart)
ssl_prefer_server_ciphers = off
# Use server's SSL cipher preferences,
# rather than the client's
# (change requires restart)
ssl_ecdh_curve = 'prime256v1'
# Name of the curve to use in ECDH key exchange
ssl_dh_params_file = ''
# Name of the file containing Diffie-Hellman parameters used
# for so-called ephemeral DH family of SSL cipher.
#------------------------------------------------------------------------------
# POOLS
#------------------------------------------------------------------------------
# - Concurrent session and pool size -
num_init_children = 32
# Number of concurrent sessions allowed
# (change requires restart)
max_pool = 4
# Number of connection pool caches per connection
# (change requires restart)
# - Life time -
child_life_time = 300
# Pool exits after being idle for this many seconds
child_max_connections = 0
# Pool exits after receiving that many connections
# 0 means no exit
connection_life_time = 0
# Connection to backend closes after being idle for this many seconds
# 0 means no close
client_idle_limit = 0
# Client is disconnected after being idle for that many seconds
# (even inside an explicit transactions!)
# 0 means no disconnection
#------------------------------------------------------------------------------
# LOGS
#------------------------------------------------------------------------------
# - Where to log -
log_destination = 'syslog'
# Where to log
# Valid values are combinations of stderr,
# and syslog. Default to stderr.
# - What to log -
log_line_prefix = '%t: pid %p: ' # printf-style string to output at beginning of each log line.
log_connections = on
# Log connections
log_hostname = on
# Hostname will be shown in ps status
# and in logs if connections are logged
log_statement = off
# Log all statements
log_per_node_statement = off
# Log all statements
# with node and backend informations
log_client_messages = off
# Log any client messages
log_standby_delay = 'if_over_threshold'
# Log standby delay
# Valid values are combinations of always,
# if_over_threshold, none
# - Syslog specific -
syslog_facility = 'LOCAL0'
# Syslog local facility. Default to LOCAL0
syslog_ident = 'pgpool'
# Syslog program identification string
# Default to 'pgpool'
# - Debug -
#log_error_verbosity = default # terse, default, or verbose messages
#client_min_messages = notice # values in order of decreasing detail:
# debug5
# debug4
# debug3
# debug2
# debug1
# log
# notice
# warning
# error
#log_min_messages = warning # values in order of decreasing detail:
# debug5
# debug4
# debug3
# debug2
# debug1
# info
# notice
# warning
# error
# log
# fatal
# panic
#------------------------------------------------------------------------------
# FILE LOCATIONS
#------------------------------------------------------------------------------
pid_file_name = '/opt/pgpool/pgpool.pid'
# PID file name
# Can be specified as relative to the"
# location of pgpool.conf file or
# as an absolute path
# (change requires restart)
logdir = '/opt/pgpool/'
# Directory of pgPool status file
# (change requires restart)
#------------------------------------------------------------------------------
# CONNECTION POOLING
#------------------------------------------------------------------------------
connection_cache = on
# Activate connection pools
# (change requires restart)
# Semicolon separated list of queries
# to be issued at the end of a session
# The default is for 8.3 and later
reset_query_list = 'ABORT; DISCARD ALL'
# The following one is for 8.2 and before
#reset_query_list = 'ABORT; RESET ALL; SET SESSION AUTHORIZATION DEFAULT'
#------------------------------------------------------------------------------
# REPLICATION MODE
#------------------------------------------------------------------------------
replication_mode = off
# Activate replication mode
# (change requires restart)
replicate_select = off
# Replicate SELECT statements
# when in replication mode
# replicate_select is higher priority than
# load_balance_mode.
insert_lock = off
# Automatically locks a dummy row or a table
# with INSERT statements to keep SERIAL data
# consistency
# Without SERIAL, no lock will be issued
lobj_lock_table = ''
# When rewriting lo_creat command in
# replication mode, specify table name to
# lock
# - Degenerate handling -
replication_stop_on_mismatch = off
# On disagreement with the packet kind
# sent from backend, degenerate the node
# which is most likely "minority"
# If off, just force to exit this session
failover_if_affected_tuples_mismatch = off
# On disagreement with the number of affected
# tuples in UPDATE/DELETE queries, then
# degenerate the node which is most likely
# "minority".
# If off, just abort the transaction to
# keep the consistency
#------------------------------------------------------------------------------
# LOAD BALANCING MODE
#------------------------------------------------------------------------------
load_balance_mode = on
# Activate load balancing mode
# (change requires restart)
ignore_leading_white_space = on
# Ignore leading white spaces of each query
white_function_list = ''
# Comma separated list of function names
# that don't write to database
# Regexp are accepted
black_function_list = 'currval,lastval,nextval,setval,func_*,f_*'
# Comma separated list of function names
# that write to database
# Regexp are accepted
black_query_pattern_list = ''
# Semicolon separated list of query patterns
# that should be sent to primary node
# Regexp are accepted
# valid for streaming replicaton mode only.
database_redirect_preference_list = ''
# comma separated list of pairs of database and node id.
# example: postgres:primary,mydb[0-4]:1,mydb[5-9]:2'
# valid for streaming replicaton mode only.
app_name_redirect_preference_list = ''
# comma separated list of pairs of app name and node id.
# example: 'psql:primary,myapp[0-4]:1,myapp[5-9]:standby'
# valid for streaming replicaton mode only.
allow_sql_comments = off
# if on, ignore SQL comments when judging if load balance or
# query cache is possible.
# If off, SQL comments effectively prevent the judgment
# (pre 3.4 behavior).
disable_load_balance_on_write = 'transaction'
# Load balance behavior when write query is issued
# in an explicit transaction.
# Note that any query not in an explicit transaction
# is not affected by the parameter.
# 'transaction' (the default): if a write query is issued,
# subsequent read queries will not be load balanced
# until the transaction ends.
# 'trans_transaction': if a write query is issued,
# subsequent read queries in an explicit transaction
# will not be load balanced until the session ends.
# 'always': if a write query is issued, read queries will
# not be load balanced until the session ends.
statement_level_load_balance = off
# Enables statement level load balancing
#------------------------------------------------------------------------------
# MASTER/SLAVE MODE
#------------------------------------------------------------------------------
master_slave_mode = on
# Activate master/slave mode
# (change requires restart)
master_slave_sub_mode = 'stream'
# Master/slave sub mode
# Valid values are combinations stream, slony
# or logical. Default is stream.
# (change requires restart)
# - Streaming -
sr_check_period = 10
# Streaming replication check period
# Disabled (0) by default
sr_check_user = 'repuser'
# Streaming replication check user
# This is neccessary even if you disable streaming
# replication delay check by sr_check_period = 0
sr_check_password = 'repuser123'
# Password for streaming replication check user
# Leaving it empty will make Pgpool-II to first look for the
# Password in pool_passwd file before using the empty password
sr_check_database = 'postgres'
# Database name for streaming replication check
delay_threshold = 10000000
# Threshold before not dispatching query to standby node
# Unit is in bytes
# Disabled (0) by default
# - Special commands -
follow_master_command = 'sh /etc/pgpool-II/follow_master.sh %d %h %D %H %r '
# Executes this command after master failover
# Special values:
# %d = failed node id
# %h = failed node host name
# %p = failed node port number
# %D = failed node database cluster path
# %m = new master node id
# %H = new master node hostname
# %M = old master node id
# %P = old primary node id
# %r = new master port number
# %R = new master database cluster path
# %N = old primary node hostname
# %S = old primary node port number
# %% = '%' character
#------------------------------------------------------------------------------
# HEALTH CHECK GLOBAL PARAMETERS
#------------------------------------------------------------------------------
health_check_period = 10
# Health check period
# Disabled (0) by default
health_check_timeout = 20
# Health check timeout
# 0 means no timeout
health_check_user = 'checkuser'
# Health check user
health_check_password = 'checkuser123'
# Password for health check user
# Leaving it empty will make Pgpool-II to first look for the
# Password in pool_passwd file before using the empty password
health_check_database = 'postgres'
# Database name for health check. If '', tries 'postgres' frist, then 'template1'
health_check_max_retries = 3
# Maximum number of times to retry a failed health check before giving up.
health_check_retry_delay = 1
# Amount of time to wait (in seconds) between retries.
connect_timeout = 10000
# Timeout value in milliseconds before giving up to connect to backend.
# Default is 10000 ms (10 second). Flaky network user may want to increase
# the value. 0 means no timeout.
# Note that this value is not only used for health check,
# but also for ordinary conection to backend.
#------------------------------------------------------------------------------
# HEALTH CHECK PER NODE PARAMETERS (OPTIONAL)
#------------------------------------------------------------------------------
#health_check_period0 = 0
#health_check_timeout0 = 20
#health_check_user0 = 'checkuser'
#health_check_password0 = ''
#health_check_database0 = ''
#health_check_max_retries0 = 0
#health_check_retry_delay0 = 1
#connect_timeout0 = 10000
#------------------------------------------------------------------------------
# FAILOVER AND FAILBACK
#------------------------------------------------------------------------------
failover_command = 'sh /etc/pgpool-II/failover.sh %d %h %D %m %H %r %P %R '
# Executes this command at failover
# Special values:
# %d = failed node id
# %h = failed node host name
# %p = failed node port number
# %D = failed node database cluster path
# %m = new master node id
# %H = new master node hostname
# %M = old master node id
# %P = old primary node id
# %r = new master port number
# %R = new master database cluster path
# %N = old primary node hostname
# %S = old primary node port number
# %% = '%' character
failback_command = ''
# Executes this command at failback.
# Special values:
# %d = failed node id
# %h = failed node host name
# %p = failed node port number
# %D = failed node database cluster path
# %m = new master node id
# %H = new master node hostname
# %M = old master node id
# %P = old primary node id
# %r = new master port number
# %R = new master database cluster path
# %N = old primary node hostname
# %S = old primary node port number
# %% = '%' character
failover_on_backend_error = on
# Initiates failover when reading/writing to the
# backend communication socket fails
# If set to off, pgpool will report an
# error and disconnect the session.
detach_false_primary = off
# Detach false primary if on. Only
# valid in streaming replicaton
# mode and with PostgreSQL 9.6 or
# after.
search_primary_node_timeout = 3
# Timeout in seconds to search for the
# primary node when a failover occurs.
# 0 means no timeout, keep searching
# for a primary node forever.
#------------------------------------------------------------------------------
# ONLINE RECOVERY
#------------------------------------------------------------------------------
recovery_user = 'nobody'
# Online recovery user
recovery_password = ''
# Online recovery password
# Leaving it empty will make Pgpool-II to first look for the
# Password in pool_passwd file before using the empty password
recovery_1st_stage_command = ''
# Executes a command in first stage
recovery_2nd_stage_command = ''
# Executes a command in second stage
recovery_timeout = 90
# Timeout in seconds to wait for the
# recovering node's postmaster to start up
# 0 means no wait
client_idle_limit_in_recovery = 0
# Client is disconnected after being idle
# for that many seconds in the second stage
# of online recovery
# 0 means no disconnection
# -1 means immediate disconnection
auto_failback = on
# Dettached backend node reattach automatically
# if replication_state is 'streaming'.
auto_failback_interval = 30
# Min interval of executing auto_failback in
# seconds.
#------------------------------------------------------------------------------
# WATCHDOG
#------------------------------------------------------------------------------
# - Enabling -
use_watchdog = on
# Activates watchdog
# (change requires restart)
# -Connection to up stream servers -
trusted_servers = 'node228,node229'
# trusted server list which are used
# to confirm network connection
# (hostA,hostB,hostC,...)
# (change requires restart)
ping_path = '/bin'
# ping command path
# (change requires restart)
# - Watchdog communication Settings -
wd_hostname = 'node229'
# Host name or IP address of this watchdog
# (change requires restart)
wd_port = 9000
# port number for watchdog service
# (change requires restart)
wd_priority = 1
# priority of this watchdog in leader election
# (change requires restart)
wd_authkey = ''
# Authentication key for watchdog communication
# (change requires restart)
wd_ipc_socket_dir = '/opt/pgpool'
# Unix domain socket path for watchdog IPC socket
# The Debian package defaults to
# /var/run/postgresql
# (change requires restart)
# - Virtual IP control Setting -
delegate_IP = '10.40.239.240'
# delegate IP address
# If this is empty, virtual IP never bring up.
# (change requires restart)
if_cmd_path = '/usr/sbin'
# path to the directory where if_up/down_cmd exists
# If if_up/down_cmd starts with "/", if_cmd_path will be ignored.
# (change requires restart)
if_up_cmd = 'ip addr add $_IP_$/24 dev ens33 label ens33:0'
# startup delegate IP command
# (change requires restart)
if_down_cmd = 'ip addr del $_IP_$/24 dev ens33'
# shutdown delegate IP command
# (change requires restart)
arping_path = '/usr/sbin'
# arping command path
# If arping_cmd starts with "/", if_cmd_path will be ignored.
# (change requires restart)
arping_cmd = 'arping -U $_IP_$ -w 1 -I ens33'
# arping command
# (change requires restart)
# - Behaivor on escalation Setting -
clear_memqcache_on_escalation = on
# Clear all the query cache on shared memory
# when standby pgpool escalate to active pgpool
# (= virtual IP holder).
# This should be off if client connects to pgpool
# not using virtual IP.
# (change requires restart)
wd_escalation_command = ''
# Executes this command at escalation on new active pgpool.
# (change requires restart)
wd_de_escalation_command = ''
# Executes this command when master pgpool resigns from being master.
# (change requires restart)
# - Watchdog consensus settings for failover -
failover_when_quorum_exists = on
# Only perform backend node failover
# when the watchdog cluster holds the quorum
# (change requires restart)
failover_require_consensus = on
# Perform failover when majority of Pgpool-II nodes
# aggrees on the backend node status change
# (change requires restart)
allow_multiple_failover_requests_from_node = on
# A Pgpool-II node can cast multiple votes
# for building the consensus on failover
# (change requires restart)
enable_consensus_with_half_votes = on
# apply majority rule for consensus and quorum computation
# at 50% of votes in a cluster with even number of nodes.
# when enabled the existence of quorum and consensus
# on failover is resolved after receiving half of the
# total votes in the cluster, otherwise both these
# decisions require at least one more vote than
# half of the total votes.
# (change requires restart)
# - Lifecheck Setting -
# -- common --
wd_monitoring_interfaces_list = '' # Comma separated list of interfaces names to monitor.
# if any interface from the list is active the watchdog will
# consider the network is fine
# 'any' to enable monitoring on all interfaces except loopback
# '' to disable monitoring
# (change requires restart)
wd_lifecheck_method = 'heartbeat'
# Method of watchdog lifecheck ('heartbeat' or 'query' or 'external')
# (change requires restart)
wd_interval = 10
# lifecheck interval (sec) > 0
# (change requires restart)
# -- heartbeat mode --
wd_heartbeat_port = 9694
# Port number for receiving heartbeat signal
# (change requires restart)
wd_heartbeat_keepalive = 2
# Interval time of sending heartbeat signal (sec)
# (change requires restart)
wd_heartbeat_deadtime = 30
# Deadtime interval for heartbeat signal (sec)
# (change requires restart)
heartbeat_destination0 = 'node228'
# Host name or IP address of destination 0
# for sending heartbeat signal.
# (change requires restart)
heartbeat_destination_port0 = 9694
# Port number of destination 0 for sending
# heartbeat signal. Usually this is the
# same as wd_heartbeat_port.
# (change requires restart)
heartbeat_device0 = 'ens33'
# Name of NIC device (such like 'eth0')
# used for sending/receiving heartbeat
# signal to/from destination 0.
# This works only when this is not empty
# and pgpool has root privilege.
# (change requires restart)
#heartbeat_destination1 = ''
#heartbeat_destination_port1 = 9694
#heartbeat_device1 = 'ens33'
# -- query mode --
wd_life_point = 3
# lifecheck retry times
# (change requires restart)
wd_lifecheck_query = 'SELECT 1'
# lifecheck query to pgpool from watchdog
# (change requires restart)
wd_lifecheck_dbname = 'postgres'
# Database name connected for lifecheck
# (change requires restart)
wd_lifecheck_user = 'checkuser'
# watchdog user monitoring pgpools in lifecheck
# (change requires restart)
wd_lifecheck_password = 'checkuser123'
# Password for watchdog user in lifecheck
# Leaving it empty will make Pgpool-II to first look for the
# Password in pool_passwd file before using the empty password
# (change requires restart)
# - Other pgpool Connection Settings -
other_pgpool_hostname0 = 'node228'
# Host name or IP address to connect to for other pgpool 0
# (change requires restart)
other_pgpool_port0 = 9999
# Port number for other pgpool 0
# (change requires restart)
other_wd_port0 = 9000
# # Port number for other watchdog 0
# # (change requires restart)
#other_pgpool_hostname1 = ''
#other_pgpool_port1 = 9999
#other_wd_port1 = 9000
#------------------------------------------------------------------------------
# OTHERS
#------------------------------------------------------------------------------
relcache_expire = 0
# Life time of relation cache in seconds.
# 0 means no cache expiration(the default).
# The relation cache is used for cache the
# query result against PostgreSQL system
# catalog to obtain various information
# including table structures or if it's a
# temporary table or not. The cache is
# maintained in a pgpool child local memory
# and being kept as long as it survives.
# If someone modify the table by using
# ALTER TABLE or some such, the relcache is
# not consistent anymore.
# For this purpose, cache_expiration
# controls the life time of the cache.
relcache_size = 256
# Number of relation cache
# entry. If you see frequently:
# "pool_search_relcache: cache replacement happend"
# in the pgpool log, you might want to increate this number.
check_temp_table = catalog
# Temporary table check method. catalog, trace or none.
# Default is catalog.
check_unlogged_table = on
# If on, enable unlogged table check in SELECT statements.
# This initiates queries against system catalog of primary/master
# thus increases load of master.
# If you are absolutely sure that your system never uses unlogged tables
# and you want to save access to primary/master, you could turn this off.
# Default is on.
enable_shared_relcache = on
# If on, relation cache stored in memory cache,
# the cache is shared among child process.
# Default is on.
# (change requires restart)
relcache_query_target = master # Target node to send relcache queries. Default is master (primary) node.
# If load_balance_node is specified, queries will be sent to load balance node.
#------------------------------------------------------------------------------
# IN MEMORY QUERY MEMORY CACHE
#------------------------------------------------------------------------------
memory_cache_enabled = off
# If on, use the memory cache functionality, off by default
# (change requires restart)
memqcache_method = 'shmem'
# Cache storage method. either 'shmem'(shared memory) or
# 'memcached'. 'shmem' by default
# (change requires restart)
memqcache_memcached_host = 'localhost'
# Memcached host name or IP address. Mandatory if
# memqcache_method = 'memcached'.
# Defaults to localhost.
# (change requires restart)
memqcache_memcached_port = 11211
# Memcached port number. Mondatory if memqcache_method = 'memcached'.
# Defaults to 11211.
# (change requires restart)
memqcache_total_size = 67108864
# Total memory size in bytes for storing memory cache.
# Mandatory if memqcache_method = 'shmem'.
# Defaults to 64MB.
# (change requires restart)
memqcache_max_num_cache = 1000000
# Total number of cache entries. Mandatory
# if memqcache_method = 'shmem'.
# Each cache entry consumes 48 bytes on shared memory.
# Defaults to 1,000,000(45.8MB).
# (change requires restart)
memqcache_expire = 0
# Memory cache entry life time specified in seconds.
# 0 means infinite life time. 0 by default.
# (change requires restart)
memqcache_auto_cache_invalidation = on
# If on, invalidation of query cache is triggered by corresponding
# DDL/DML/DCL(and memqcache_expire). If off, it is only triggered
# by memqcache_expire. on by default.
# (change requires restart)
memqcache_maxcache = 409600
# Maximum SELECT result size in bytes.
# Must be smaller than memqcache_cache_block_size. Defaults to 400KB.
# (change requires restart)
memqcache_cache_block_size = 1048576
# Cache block size in bytes. Mandatory if memqcache_method = 'shmem'.
# Defaults to 1MB.
# (change requires restart)
memqcache_oiddir = '/tmp/oiddir'
# Temporary work directory to record table oids
# (change requires restart)
white_memqcache_table_list = ''
# Comma separated list of table names to memcache
# that don't write to database
# Regexp are accepted
black_memqcache_table_list = ''
# Comma separated list of table names not to memcache
# that don't write to database
# Regexp are accepted
读者可以根据实际情况修改配置信息。请自行比较两个节点的配置文件差异。下面我们对重点配置项目进行说明。
设置它的权限为仅允许所属用户读写:
[postgres@node228 pgpool-II]# chmod 600 /etc/pgpool-II/pgpool.conf
#------------------------------------------------------------------------------
# CONNECTIONS
#------------------------------------------------------------------------------
# - pgpool 连接设置 -
listen_addresses = '*'
pgpool-II 监听的 TCP/IP 连接的主机名或者IP地址。'*'表示全部, '' 表示不接受任何ip地址连接。
port = 9999
pgpool-II的端口号
socket_dir = '/opt/pgpool/'
建立和接受 UNIX 域套接字连接的目录
# - pgpool 通信管理连接设置 -
pcp_listen_addresses = '*'
pcp 进程监听的主机名或者IP地址。'*'表示全部, '' 表示不接受任何ip地址连接。
pcp_port = 9898
pcp 的端口
pcp_socket_dir = '/opt/pgpool/'
pcp 的建立和接受 UNIX 域套接字连接的目录
# - 后端连接设置,即PostgreSQL服务的设置
backend_hostname0 = 'node228'
后台PostgreSQL 节点0的IP地址或主机名
backend_port0 = 5432
PostgreSQL后台PostgreSQL 节点0的端口
backend_weight0 = 1
PostgreSQL节点0的权重 仅在负载均衡模式)
backend_data_directory0 = '/opt/pg114/data/'
PostgreSQL节点0数据目录
backend_flag0 = 'ALLOW_TO_FAILOVER'
控制后台程序的行为,有三种值:
|
值 |
描述 |
|
ALLOW_TO_FAILOVER |
允许故障转移或者从后台程序断开。本值为默认值。指定本值后,不能同时指定 DISALLOW_TO_FAILOVER 。 |
|
DISALLOW_TO_FAILOVER |
不允许故障转移或从后台程序断开。当你使用Heartbeat或Pacemaker等HA(高可用性)软件保护后端时,此功能很有用。 你不能同时使用ALLOW_TO_FAILOVER指定。 |
|
ALWAYS_MASTER |
这仅在流复制模式下有用。如果将此标志设置为后端之一,则Pgpool-II将不会通过检查后端找到主节点。 而是始终将设置了标志的节点视为主要节点。 |
backend_application_name0 = 'server0'
walsender(日志发送进程)的application_name
下面的参数则是另一个PostgreSQL 后端的配置。这里不再赘述。
backend_hostname1 = 'node229'
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/opt/pg114/data/'
backend_flag1 = 'ALLOW_TO_FAILOVER'
backend_application_name1 = 'server1'
# - 池的认证 -
enable_pool_hba = on
使用 pool_hba.conf 来进行客户端认证,on表示同意
pool_passwd = 'pool_passwd'
指定用于 md5 认证的文件名。默认值为"pool_passwd";"" 表示禁止 pool_passwd.
authentication_timeout = 60
指定 pgpool 认证超时的时长。0 指禁用超时,默认值为 60 。
allow_clear_text_frontend_auth = off
如果PostgreSQL后端服务器需要md5或SCRAM身份验证来进行某些用户的身份验证,但是该用户的密码不在“ pool_passwd”文件中,则启用allow_clear_text_frontend_auth将允许Pgpool-II对前端客户端使用明文密码验证。 从客户端获取纯文本格式的密码,并将其用于后端身份验证。
#------------------------------------------------------------------------------
# LOGS
#------------------------------------------------------------------------------
log_destination = 'syslog'
pgpool-II 支持多种记录服务器消息的方式,包括 stderr 和 syslog。默认为记录到 stderr。Syslog 表示输出到系统日志中
log_line_prefix = '%t: pid %p: '
每行日志开头的打印样式字符串,默认值打印时间戳和进程号
log_connections = on
如果为 on,进入的连接将被打印到日志中。
log_hostname = on
如果为on,ps 命令和日志将显示客户端的主机名而不是 IP 地址。
log_statement = off
如果设置为 on ,所有 SQL 语句将被记录。
log_per_node_statement = off
针对每个 DB 节点记录各自的SQL查询,要知道一个 SELECT 的结果是不是从查询缓存获得,需要启用它
log_client_messages = off
如果设置为 on ,则记录客户端的信息
log_standby_delay = 'if_over_threshold'
指出如何记录后备服务器的延迟。如果指定 'none',则不写入日志。 如果为 'always',在每次执行复制延迟检查时记录延迟。 如果 'if_over_threshold' 被指定,只有当延迟到达 delay_threshold 时记录日志。 log_standby_delay 的默认值为 'none'。
# - Syslog 具体设置 -
syslog_facility = 'LOCAL0'
当记录日志到 syslog 被启用,本参数确定被使用的 syslog “设备”。 可以使用 LOCAL0, LOCAL1, LOCAL2,…, LOCAL7
syslog_ident = 'pgpool'
系统日志鉴别字符串,默认是'pgpool'
# - 文件位置 -
pid_file_name = '/opt/pgpool/pgpool.pid'
包含 pgpool-II 进程 ID 的文件的完整路径名
logdir = '/opt/pgpool/'
保存日志文件的目录。pgpool_status 将被写入这个目录。
#------------------------------------------------------------------------------
# REPLICATION MODE
#------------------------------------------------------------------------------
replication_mode = off
在复制模式(已淘汰)时设置为 on,在主/备模式中, replication_mode,必须被设置为 off,并且 master_slave_mode 为 on
#------------------------------------------------------------------------------
# LOAD BALANCING MODE
#------------------------------------------------------------------------------
load_balance_mode = on
当设置为 on时,SELECT 查询将被分发到每个后台程序上用于负载均衡。
ignore_leading_white_space = on
当设置为on时,在负载均衡模式中 pgpool-II 忽略 SQL 查询语句前面的空白字符。
white_function_list = ''
指定一系列用逗号隔开的不会更新数据库的函数名。
black_function_list = 'currval,lastval,nextval,setval,func_*,f_*'
指定一系列用逗号隔开的会更新数据库的函数名。在复制模式中,在本列表中指定的函数将即不会被负载均衡,也不会被复制。在主备模式中,这些 SELECT 语句只被发送到主节点。
black_query_pattern_list = ''
指定一系列用分号隔开的sql 模式,匹配这些模式的sql只会被发送到主结点。
#------------------------------------------------------------------------------
# MASTER/SLAVE MODE
#------------------------------------------------------------------------------
master_slave_mode = on
是否为主备模式
master_slave_sub_mode = 'stream'
使用 PostgreSQL 内置的复制系统(基于流复制)时被设置
# - 流复制 -
sr_check_period = 10
本参数指出基于流复制的延迟检查的间隔,单位为秒
sr_check_user = 'repuser'
执行流复制检查的用户。用户必须存在于所有的PostgreSQL后端上。
sr_check_password = 'repuser123'
执行流复制检测的用户的密码
sr_check_database = 'postgres'
执行流复制检查的数据库
delay_threshold = 10000000
指定能够容忍的备机上相对于主服务器上的 WAL 的复制延迟,单位为字节。 如果延迟到达了 delay_threshold,pgpool-II 不再发送 SELECT 查询到备机。 所有的东西都被发送到主服务器,即使启用了负载均衡模式,直到备机追赶上来。
# - 特殊命令 -
follow_master_command = 'bash /etc/pgpool-II/follow_master.sh %d %h %D %H %r '
本参数指定一个在主备流复制模式中发生主节点故障恢复后执行的命令。 pgpool-II 使用后台对应的信息代替以下的特别字符。
|
特殊字符 |
描述 |
|
%d |
断开连接的节点的后台 ID。 |
|
%h |
断开连接的节点的主机名。 |
|
%p |
断开连接的节点的端口号。 |
|
%D |
断开连接的节点的数据库实例所在目录。 |
|
%M |
旧的主节点 ID。 |
|
%m |
新的主节点 ID。 |
|
%H |
新的主节点主机名。 |
|
%P |
旧的第一节点 ID。 |
|
%r |
新的主节点的端口号。 |
|
%R |
新的主节点的数据库实例所在目录。 |
|
%% |
'%' 字符 |
如果你改变了这个值,需要重新加载 pgpool.conf 以使变动生效。
如果 follow_master_commnd 不为空,当一个主备流复制中的主节点的故障切换完成, pgpool 退化所有的除新的主节点外的所有节点并启动一个新的子进程, 再次准备好接受客户端的连接。 在这之后,pgpool 针对每个退化的节点运行 ‘follow_master_command’ 指定的命令。 通常,这个命令应该用于调用例如 pcp_recovery_node 命令来从新的主节点恢复备节点。
#------------------------------------------------------------------------------
# HEALTH CHECK GLOBAL PARAMETERS
#------------------------------------------------------------------------------
health_check_period = 10
pgpool-II 定期尝试连接到后台以检测服务器是否在服务器或网络上有问题。 这种错误检测过程被称为“健康检查”。如果检测到错误, 则 pgpool-II 会尝试进行故障恢复或者退化操作。本参数指出健康检查的间隔,单位为秒。
health_check_timeout = 20
本参数用于避免健康检查在例如网线断开等情况下等待很长时间。 超时值的单位为秒。默认值为 20 。0 禁用超时(一直等待到 TCP/IP 超时)。
health_check_user = 'checkuser'
用于执行健康检查的用户。用户必须存在于 PostgreSQL 后台中。health_check_password = 'checkuser123'
用于执行健康检查的用户的密码。
health_check_database = 'postgres'
执行健康检查的数据库名。
connect_timeout = 10000
使用 connect() 系统调用时候放弃连接到后端的超时毫秒值。 默认为 10000 毫秒。
#------------------------------------------------------------------------------
# FAILOVER AND FAILBACK
#------------------------------------------------------------------------------
failover_command = 'bash /etc/pgpool-II/failover.sh %d %h %D %m %H %r %P %R '
本参数指定当一个节点断开连接时执行的命令。 pgpool-II 使用后台对应的信息代替以下的特别字符。
|
特殊字符 |
描述 |
|
%d |
断开连接的节点的后台 ID。 |
|
%h |
断开连接的节点的主机名。 |
|
%p |
断开连接的节点的端口号。 |
|
%D |
断开连接的节点的数据库实例所在目录。 |
|
%M |
旧的主节点 ID。 |
|
%m |
新的主节点 ID。 |
|
%H |
新的主节点主机名。 |
|
%P |
旧的第一节点 ID。 |
|
%r |
新的主节点的端口号。 |
|
%R |
新的主节点的数据库实例所在目录。 |
|
%% |
'%' 字符 |
如果你改变了这个值,需要重新加载 pgpool.conf 以使变动生效。
当进行故障切换时,pgpool 杀掉它的所有子进程,这将顺序终止所有的到 pgpool 的会话。 然后,pgpool 调用 failover_command 并等待它完成。 然后,pgpool 启动新的子进程并再次开始从客户端接受连接。
failover_on_backend_error = on
如果为 on,当往后台进程的通信中写入数据时发生错误,pgpool-II 将触发故障处理过程。
#------------------------------------------------------------------------------
# WATCHDOG
#------------------------------------------------------------------------------
use_watchdog = on
如果为 on,则激活看门狗。
# - 连接到上游服务器 -
trusted_servers = 'node228,node229'
用于检测上游连接的可信服务器列表(即pgpool所在的服务器)。每台服务器都应能响应 ping。 指定一个用逗号分隔的服务器列表例如 "hostA,hostB,hostC"。 如果没有任何服务器可以 ping 通,则看门狗认为 pgpool-II 出故障了。
ping_path = '/bin'
# 本参数指定用于监控上游服务器的 ping 命令的路径。只需要设置路径例如 "/bin"
wd_hostname = 'node228'
指定 pgpool-II 的主机名或者 IP 地址。
wd_port = 9000
指定看门狗的通信端口
wd_priority = 1
本参数用于设定在主看门狗节点选举时本地看门狗节点的优先权。 在集群启动的时候或者旧的看门狗故障的时候,wd_priority 值较高的节点会被选为主看门狗节点。
wd_ipc_socket_dir = '/opt/pgpool'
建立 pgpool-II 看门狗 IPC 连接的本地域套接字建立的目录。
# - 虚拟IP控制设置 -
delegate_IP = '10.40.239.240'
指定客户端的服务(例如应用服务等)连接到的 pgpool-II 的虚拟 IP (VIP) 地址。
if_cmd_path = '/usr/sbin'
本参数指定用于切换 IP 地址的命令的所在路径。
if_up_cmd = 'ip addr add $_IP_$/24 dev ens33 label ens33:0'
本参数指定一个命令用以启用虚拟 IP。设置命令和参数,例如 "ip addr add $_IP_$/24 dev ens33 label ens33:0"。 参数 $_IP_$ 会被 delegate_IP 设置的值替换。ens33根据现场机器改掉。
if_down_cmd = 'ip addr del $_IP_$/24 dev ens33'
本参数指定一个命令用以停用虚拟 IP
arping_path = '/usr/sbin'
本参数指定用于arp地址解析的命令的所在路径。
arping_cmd = 'arping -U $_IP_$ -w 1 -I ens33'
本参数指定一个命令用以在发生虚拟 IP 切换后用于发送一个 ARP 请求的命令。
# - pgpool-II 存活情况检查 -
wd_lifecheck_method = 'heartbeat'
本参数指定存活检查的模式。
wd_interval = 10
参数指定 pgpool-II 进行存活检查的间隔,单位为秒。
# -- 心跳模式 --
wd_heartbeat_port = 9694
本选项指定接收心跳信号的端口号。默认为 9694。
wd_heartbeat_keepalive = 2
本选项指定发送心跳信号的间隔(秒)。默认值为 2。
wd_heartbeat_deadtime = 30
如果本选项指定的时间周期内没有收到心跳信号,则看门狗认为远端的 pgpool-II 发生故障。
heartbeat_destination0 = 'node229'
选项指定心跳信号发送的目标,即另一台安装pgpool的主机,可以是 IP 地址或主机名。设置其它pgpool节点的节点名。
heartbeat_destination_port0 = 9694
本选项指定由 heartbeat_destinationX 指定的心跳信号目标的端口号。
heartbeat_device0 = 'ens33'
本选项指定用于发送心跳信号到由 heartbeat_destinationX指定的目标的设备名。
# -- 查询模式 --
wd_lifecheck_dbname = 'postgres'
用于检查 pgpool-II 时连接到的数据库名。
wd_lifecheck_user = 'checkuser'
用于检查 pgpool-II 的用户名。
wd_lifecheck_password = 'checkuser123'
用于检查 pgpool-II 的用户的密码
# - 其他 pgpool 连接设置 -
other_pgpool_hostname0 = '10.40.239.229'
指定需要监控的 pgpool-II 的服务器主机
other_pgpool_port0 = 9999
指定需要监控的 pgpool-II 服务器的 pgpool 服务的端口
other_wd_port0 = 9000
指定需要监控的 pgpool-II 服务器的看门狗的端口。
- 使用root用户,修改命令ip,arping,ifup,ifconfig的权限
[root@node228 pgpool-II]# chmod +s /usr/sbin/ip
[root@node228 pgpool-II]# chmod +s /usr/sbin/arping
[root@node228 pgpool-II]# chmod +s /usr/sbin/ifup
[root@node228 pgpool-II]# chmod +s /usr/sbin/ifconfig
[root@node228 pgpool-II]# chmod u+s /usr/sbin/ip
[root@node228 pgpool-II]# chmod u+s /usr/sbin/arping
[root@node228 pgpool-II]# chmod u+s /usr/sbin/ifup
[root@node228 pgpool-II]# chmod u+s /usr/sbin/ifconfig
- 将文件failover.sh 和 follow_master.sh 上传至两台主机上的 /etc/pgpool-II 目录中。
1 #!/bin/bash 2 # This script is run by failover_command. 3 4 set -o xtrace 5 # exec > >(logger -i -p local1.info) 2>&1 6 7 # Special values: 8 # %d = failed node id 9 # %h = failed node hostname 10 # %p = failed node port number 11 # %D = failed node database cluster path 12 # %m = new master node id 13 # %H = new master node hostname 14 # %M = old master node id 15 # %P = old primary node id 16 # %r = new master port number 17 # %R = new master database cluster path 18 # %N = old primary node hostname 19 # %S = old primary node port number 20 # %% = '%' character 21 22 23 FAILED_NODE_ID="$1" 24 FAILED_NODE_HOST="$2" 25 FAILED_NODE_PGDATA="$3" 26 NEW_MASTER_NODE_ID="$4" 27 NEW_MASTER_NODE_HOST="$5" 28 NEW_MASTER_NODE_PORT="$6" 29 OLD_PRIMARY_NODE_ID="$7" 30 NEW_MASTER_NODE_PGDATA="$8" 31 32 PGHOME=/opt/pg114 33 REPL_USER=repuser 34 PCP_USER=pgpool 35 PGPOOL_PATH=/usr/bin 36 PCP_PORT=9898 37 PGPOOL_LOG_DIR=/opt/pgpool 38 39 RECOVERY_CONF=${FAILED_NODE_PGDATA}/recovery.conf 40 PGPASSFILE=/etc/pgpool-II/.pgpass 41 PCPPASSFILE=/etc/pgpool-II/.pcppass 42 43 declare -A parameter_list 44 45 parameter_list=( 46 ["FAILED_NODE_ID"]=${FAILED_NODE_ID} 47 ["FAILED_NODE_HOST"]=${FAILED_NODE_HOST} 48 ["FAILED_NODE_PGDATA"]=${FAILED_NODE_PGDATA} 49 ["NEW_MASTER_NODE_ID"]=${NEW_MASTER_NODE_ID} 50 ["NEW_MASTER_NODE_HOST"]=${NEW_MASTER_NODE_HOST} 51 ["NEW_MASTER_NODE_PORT"]=${NEW_MASTER_NODE_PORT} 52 ["OLD_PRIMARY_NODE_ID"]=${OLD_PRIMARY_NODE_ID} 53 ["NEW_MASTER_NODE_PGDATA"]=${NEW_MASTER_NODE_PGDATA} 54 ["PGHOME"]=${PGHOME} 55 ["REPL_USER"]=${REPL_USER} 56 ["PCP_USER"]=${PCP_USER} 57 ["PGPOOL_PATH"]=${PGPOOL_PATH} 58 ["PCP_PORT"]=${PCP_PORT} 59 ["PGPOOL_LOG_DIR"]=${PGPOOL_LOG_DIR} 60 ["RECOVERY_CONF"]=${RECOVERY_CONF} 61 ["PGPASSFILE"]=${PGPASSFILE} 62 ["PCPPASSFILE"]=${PCPPASSFILE} 63 ) 64 65 has_error=0 66 for parameter in ${!parameter_list[@]} 67 do 68 if [ -z ${parameter_list[$parameter]} ] 69 then 70 echo -e "ERROR: parameter \"$parameter\" is not defined. Exit" 71 has_error=1 72 fi 73 done 74 75 if [ ${has_error} -eq 1 ] 76 then 77 exit 1 78 fi 79 80 81 export PGPASSFILE 82 export PCPPASSFILE 83 84 #Get Hostname from ip address or Hostname 85 # parameters: 86 # $1: Hostname of the server 87 GetHostname () { 88 ## Test passwordless SSH 89 host_name=$(ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@"$1" -i ~/.ssh/id_rsa_pgpool "hostname") > /dev/null 90 echo $host_name 91 } 92 93 # Check if the postgresql node is running and is the master 94 # parameters: 95 # $1: Hostname of postgresql node 96 # $2: Port number of the PostgreSQL node 97 # $3: Home directory of PostgreSQL 98 CheckIfPostgresqlIsMaster () { 99 pg_node_host=$1 100 pg_node_port=$2 101 PGHOME=$3 102 103 is_master=$(ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@"$pg_node_host" -i ~/.ssh/id_rsa_pgpool "$PGHOME/bin/psql -h pg_node_host -p $pg_node_port -U postgres -t -c \"select case when pg_is_in_recovery() then 1 else 0 end\"") > /dev/null 2>&1 104 105 if [ $? -eq 0 ] && [ $is_master -eq 0 ] 106 then 107 echo "yes"; 108 else 109 echo "no" 110 fi 111 } 112 113 114 # do basebackup for postgresql by running pg_basebackup 115 # parameters: 116 # $1: Hostname of the detached node 117 # $2: Hostname of the new master node 118 # $3: Port number of the new master node 119 # $4: HOME directory of PostgreSQL 120 # $5: User for postgrsql replication 121 # $6: failed node database cluster path 122 # $7: Log directory of pgpool 123 DoPgBasebackup () { 124 failed_node_host=$1 125 new_master_node_host=$2 126 new_master_node_port=$3 127 PGHOME=$4 128 repl_user=$5 129 failed_node_pgdata=$6 130 PGPOOL_LOG_DIR=$7 131 132 RECOVERY_CONF=${failed_node_pgdata}/recovery.conf 133 134 master_is_real_master=$(CheckIfPostgresqlIsMaster ${new_master_node_host} ${new_master_node_port} ${PGHOME} ${PGPOOL_LOG_DIR}) > /dev/null 2>&1 135 if [ $master_is_real_master != 'yes' ] 136 then 137 echo "$(date +"%F %T") failover.sh ERROR: Postgres is not running as a master at ${new_master_node_host}. Exiting." 138 return 1 139 fi 140 141 ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${failed_node_host} -i ~/.ssh/id_rsa_pgpool " 142 143 set -o errexit 144 145 # Execute pg_basebackup 146 rm -rf ${failed_node_pgdata} 147 ${PGHOME}/bin/pg_basebackup -X stream -h ${new_master_node_host} -U ${repl_user} -p ${new_master_node_port} -D ${failed_node_pgdata} 148 149 cat > ${RECOVERY_CONF} << EOT 150 primary_conninfo = 'host=${new_master_node_host} port=${new_master_node_port} user=${repl_user} application_name=${failed_node_host} passfile=''/var/lib/pgsql/.pgpass''' 151 recovery_target_timeline = 'latest' 152 primary_slot_name = '${failed_node_host}' 153 standby_mode = 'on' 154 EOT 155 " 156 157 if [ $? -ne 0 ] 158 then 159 return 1 160 fi 161 return 0 162 } 163 164 echo "failover.sh: INFO: failed_node_id=${FAILED_NODE_ID} old_primary_node_id=${OLD_PRIMARY_NODE_ID} failed_host=${FAILED_NODE_HOST} new_master_host=${NEW_MASTER_NODE_HOST}" >> $PGPOOL_LOG_DIR/failover.log 165 166 FAILED_NODE_HOST=$(GetHostname ${FAILED_NODE_HOST}) 167 NEW_MASTER_NODE_HOST=$(GetHostname ${NEW_MASTER_NODE_HOST}) 168 169 ## If there's no master node anymore, skip failover. 170 if [ ${NEW_MASTER_NODE_ID} -lt 0 ]; then 171 echo "$(date +"%F %T") failover.sh ERROR: All nodes are down. Skipping failover." >> $PGPOOL_LOG_DIR/failover.log 172 exit 1 173 fi 174 175 ## Test passwordless SSH 176 ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${NEW_MASTER_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ls /tmp > /dev/null 2>&1 177 if [ $? -ne 0 ]; then 178 echo "$(date +"%F %T") failover.sh ERROR: passwordless SSH to postgres@${NEW_MASTER_NODE_HOST} failed. Please setup passwordless SSH." >> $PGPOOL_LOG_DIR/failover.log 179 exit 1 180 fi 181 182 ## If Standby node is down, start and attach it to pgpool. 183 if [ ${FAILED_NODE_ID} -ne ${OLD_PRIMARY_NODE_ID} ] 184 then 185 echo "$(date +"%F %T") failover.sh INFO: Standby node ${FAILED_NODE_ID} is down." >> $PGPOOL_LOG_DIR/failover.log 186 187 ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${FAILED_NODE_HOST} -i ~/.ssh/id_rsa_pgpool " 188 set -o errexit 189 cat > ${RECOVERY_CONF} << EOT 190 primary_conninfo = 'host=${NEW_MASTER_NODE_HOST} port=${NEW_MASTER_NODE_PORT} user=${REPL_USER} application_name=${FAILED_NODE_HOST} passfile=''/var/lib/pgsql/.pgpass''' 191 recovery_target_timeline = 'latest' 192 primary_slot_name = '${FAILED_NODE_HOST}' 193 standby_mode = 'on' 194 EOT 195 " 196 197 # start Standby node on ${FAILED_NODE_HOST} 198 ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${FAILED_NODE_HOST} -i ~/.ssh/id_rsa_pgpool \ 199 "${PGHOME}/bin/pg_ctl -l /dev/null -w -D ${FAILED_NODE_PGDATA} start" 200 201 if [ $? -eq 0 ] 202 then 203 echo "$(date +"%F %T") failover.sh INFO: node ${FAILED_NODE_ID} on ${FAILED_NODE_HOST} started as a standby node." 204 echo "$(date +"%F %T") failover.sh INFO: failover command complete." 205 else 206 echo "$(date +"%F %T") failover.sh INFO: Failed to start node ${FAILED_NODE_HOST}. Try pg_basebackup." 207 208 # Create replication slot "${FAILED_NODE_HOST}" 209 ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${new_master_node_host} -i ~/.ssh/id_rsa_pgpool " ${PGHOME}/bin/psql -h ${new_master_node_host} -p ${new_master_node_port} -c \"SELECT pg_create_physical_replication_slot('${failed_node_host}');\" " 210 211 DoPgBasebackup ${FAILED_NODE_HOST} ${NEW_MASTER_NODE_HOST} ${NEW_MASTER_NODE_PORT} ${PGHOME} ${REPL_USER} ${FAILED_NODE_PGDATA} ${PGPOOL_LOG_DIR} 212 if [ $? -ne 0 ] 213 then 214 echo "$(date +"%F %T") failover.sh ERROR: pg_basebackup failed" 215 # drop replication slot 216 ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${new_master_node_host} -i ~/.ssh/id_rsa_pgpool " ${PGHOME}/bin/psql -h ${new_master_node_host} -p ${NEW_MASTER_NODE_PORT} -c \"SELECT pg_drop_replication_slot('${FAILED_NODE_HOST}');\" " 217 echo "$(date +"%F %T") failover.sh INFO: failover command failed." 218 exit 1 219 fi 220 221 # start Standby node on ${FAILED_NODE_HOST} 222 ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${FAILED_NODE_HOST} -i ~/.ssh/id_rsa_pgpool \ 223 "${PGHOME}/bin/pg_ctl -l /dev/null -w -D ${FAILED_NODE_PGDATA} start" 224 225 # If Standby is running, attach this node 226 if [ $? -eq 0 ] 227 then 228 echo "$(date +"%F %T") failover.sh INFO: node ${FAILED_NODE_ID} on ${FAILED_NODE_HOST} started as a standby node." 229 echo "$(date +"%F %T") failover.sh INFO: failover command complete." 230 else 231 echo "$(date +"%F %T") failover.sh ERROR: failed to start standby node ${FAILED_NODE_HOST}" 232 ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${new_master_node_host} -i ~/.ssh/id_rsa_pgpool \ " 233 ${PGHOME}/bin/psql -h ${new_master_node_host} -p ${new_master_node_port} -c \"SELECT pg_drop_replication_slot('${failed_node_host}')\" " 234 235 echo "$(date +"%F %T") failover.sh ERROR: failover command failed" 236 exit 1 237 fi 238 239 # If start Standby failed, drop replication slot "${failed_node_host}" 240 fi 241 242 ${PGPOOL_PATH}/pcp_attach_node -h localhost -U ${PCP_USER} -p ${PCP_PORT} -n ${FAILED_NODE_ID} 243 if [ $? -eq 0 ] 244 then 245 echo "$(date +"%F %T") failover.sh INFO: pcp_attach_node complete." 246 echo "$(date +"%F %T") failover.sh INFO: follow master command complete." 247 return 0 248 else 249 echo "$(date +"%F %T") failover.sh ERROR: pcp_attach_node failed." >> ${PGPOOL_LOG_DIR}/failover.log 250 return 1 251 fi 252 exit 0 253 fi 254 255 ## Promote Standby node. 256 echo "failover.sh: Primary node is down, promote standby node ${NEW_MASTER_NODE_HOST}." 257 258 ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null \ 259 postgres@${NEW_MASTER_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ${PGHOME}/bin/pg_ctl -D ${NEW_MASTER_NODE_PGDATA} -w promote 260 261 if [ $? -ne 0 ] 262 then 263 echo "$(date +"%F %T") failover.sh ERROR: new_master_host=${NEW_MASTER_NODE_HOST} promote failed." 264 exit 1 265 fi 266 267 echo "failover.sh: INFO: node ${NEW_MASTER_NODE_ID} started as the primary node." 268 exit 0
#!/bin/bash # This script is run after failover_command to synchronize the Standby with the new Primary. # First try pg_rewind. If pg_rewind failed, use pg_basebackup. set -o xtrace #exec >> (logger -i -p local1.info) 2>&1 # Special values: # %d DB node ID of the detached node # %h Hostname of the detached node # %p Port number of the detached node # %D Database cluster directory of the detached node # %M Old master node ID # %m New master node ID # %H Hostname of the new master node # %P Old primary node ID # %r Port number of the new master node # %R Database cluster directory of the new master node # %N Hostname of the old primary node (Pgpool-II 4.1 or after) # %S Port number of the old primary node (Pgpool-II 4.1 or after) # %% '%' character FAILED_NODE_ID="$1" FAILED_NODE_HOST="$2" FAILED_NODE_PGDATA="$3" NEW_MASTER_NODE_HOST="$4" NEW_MASTER_NODE_PORT="$5" PGHOME="/opt/pg114" REPL_USER=repuser PCP_USER=pgpool PGPOOL_PATH=/usr/bin PCP_PORT=9898 PGPOOL_LOG_DIR=/opt/pgpool PGPASSFILE=/etc/pgpool-II/.pgpass PCPPASSFILE=/etc/pgpool-II/.pcppass declare -A parameter_list parameter_list=( ["FAILED_NODE_ID"]=${FAILED_NODE_ID} ["FAILED_NODE_HOST"]=${FAILED_NODE_HOST} ["FAILED_NODE_PGDATA"]=${FAILED_NODE_PGDATA} ["NEW_MASTER_NODE_HOST"]=${NEW_MASTER_NODE_HOST} ["NEW_MASTER_NODE_PORT"]=${NEW_MASTER_NODE_PORT} ["PGHOME"]=${PGHOME} ["REPL_USER"]=${REPL_USER} ["PCP_USER"]=${PCP_USER} ["PGPOOL_PATH"]=${PGPOOL_PATH} ["PCP_PORT"]=${PCP_PORT} ["PGPOOL_LOG_DIR"]=${PGPOOL_LOG_DIR} ["PGPASSFILE"]=${PGPASSFILE} ["PCPPASSFILE"]=${PCPPASSFILE} ) has_error=0 for parameter in ${!parameter_list[@]} do if [ -z ${parameter_list[$parameter]} ] then echo -e "ERROR: parameter \"$parameter\" is not defined. Exit" has_error=1 fi done if [ ${has_error} -eq 1 ] then exit 1 fi export PGPASSFILE export PCPPASSFILE #Check if passwordless SSH connections to a server can be made. # parameters: # $1: Hostname of the server CheckIfSSHIsPasswordless () { ## Test passwordless SSH ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@"$1" -i ~/.ssh/id_rsa_pgpool ls /tmp > /dev/null if [ $? -eq 0 ]; then echo "yes" else echo "no" fi } #Get Hostname from ip address or Hostname # parameters: # $1: Hostname of the server GetHostname () { ## Test passwordless SSH host_name=$(ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@"$1" -i ~/.ssh/id_rsa_pgpool "hostname") > /dev/null echo $host_name } # Check if the postgresql node is running # parameters: # $1: Hostname of postgresql node # $2: Home directory of PostgreSQL # $3: database cluster path CheckIfPostgresqlIsRunning () { pg_node_host=$1 PGHOME=$2 pgdata=$3 is_master=$(ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@"$pg_node_host" -i ~/.ssh/id_rsa_pgpool "$PGHOME/bin/pg_ctl -w -D ${pgdata} status") > /dev/null 2>&1 if [ $? -eq 0 ] then echo "yes"; else echo "no" fi } # Check if the postgresql node is running and is the master # parameters: # $1: Hostname of postgresql node # $2: Port number of the PostgreSQL node # $3: Home directory of PostgreSQL CheckIfPostgresqlIsMaster () { pg_node_host=$1 pg_node_port=$2 PGHOME=$3 is_master=$(ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@"$pg_node_host" -i ~/.ssh/id_rsa_pgpool "$PGHOME/bin/psql -h $pg_node_host -p $pg_node_port -U postgres -t -c \"select case when pg_is_in_recovery() then 1 else 0 end\"") > /dev/null 2>&1 if [ $? -eq 0 ] && [ $is_master -eq 0 ] then echo "yes"; else echo "no" fi } # do basebackup for postgresql by running pg_basebackup # parameters: # $1: Hostname of the detached node # $2: Hostname of the new master node # $3: Port number of the new master node # $4: HOME directory of PostgreSQL # $5: User for postgrsql replication # $6: database cluster path of failed node # $7: Log directory of pgpool RunPgrewind () { failed_node_host=$1 new_master_node_host=$2 new_master_node_port=$3 PGHOME=$4 repl_user=$5 failed_node_pgdata=$6 PGPOOL_LOG_DIR=$7 RECOVERY_CONF=${failed_node_pgdata}/recovery.conf master_is_real_master=$(CheckIfPostgresqlIsMaster ${new_master_node_host} ${new_master_node_port} ${PGHOME}) > /dev/null 2>&1 if [ $master_is_real_master != 'yes' ] then echo "$(date +"%F %T") follow_master.sh ERROR: PostgreSQL is not running as a master at ${new_master_node_host}. Exiting.." >> ${PGPOOL_LOG_DIR}/follow_master.log return 1 fi ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${failed_node_host} -i ~/.ssh/id_rsa_pgpool " set -o errexit ${PGHOME}/bin/pg_ctl -l /dev/null -w -D ${failed_node_pgdata} stop cat > ${RECOVERY_CONF} << EOT primary_conninfo = 'host=${new_master_node_host} port=${new_master_node_port} user=${repl_user} application_name=${failed_node_host} passfile=''/var/lib/pgsql/.pgpass''' recovery_target_timeline = 'latest' primary_slot_name = '${failed_node_host}' standby_mode = 'on' EOT ${PGHOME}/bin/pg_rewind -D ${failed_node_pgdata} --source-server=\"user=postgres host=${new_master_node_host} port=${new_master_node_port}\" " if [ $? -ne 0 ] then return 1 fi return 0 } # do basebackup for postgresql by running pg_basebackup # parameters: # $1: Hostname of the detached node # $2: Hostname of the new master node # $3: Port number of the new master node # $4: HOME directory of PostgreSQL # $5: User for postgrsql replication # $6: failed node database cluster path # $7: Log directory of pgpool DoPgBasebackup () { failed_node_host=$1 new_master_node_host=$2 new_master_node_port=$3 PGHOME=$4 repl_user=$5 failed_node_pgdata=$6 PGPOOL_LOG_DIR=$7 RECOVERY_CONF=${failed_node_pgdata}/recovery.conf master_is_real_master=$(CheckIfPostgresqlIsMaster ${new_master_node_host} ${new_master_node_port} ${PGHOME}) > /dev/null 2>&1 if [ $master_is_real_master != 'yes' ] then echo "$(date +"%F %T") follow_master.sh ERROR: Postgres is not running as a master at ${new_master_node_host}. Exiting." >> ${PGPOOL_LOG_DIR}/follow_master.log return 1 fi ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${failed_node_host} -i ~/.ssh/id_rsa_pgpool " set -o errexit # Execute pg_basebackup rm -rf ${failed_node_pgdata} ${PGHOME}/bin/pg_basebackup -X stream -h ${new_master_node_host} -U ${repl_user} -p ${new_master_node_port} -D ${failed_node_pgdata} cat > ${RECOVERY_CONF} << EOT primary_conninfo = 'host=${new_master_node_host} port=${new_master_node_port} user=${repl_user} application_name=${failed_node_host} passfile=''/var/lib/pgsql/.pgpass''' recovery_target_timeline = 'latest' primary_slot_name = '${failed_node_host}' standby_mode = 'on' EOT " if [ $? -ne 0 ] then return 1 fi return 0 } #Check if the supposed master is actually a master # parameters: # $1: DB node ID of the detached node # $2: Hostname of the detached node # $3: Database cluster directory of the detached node # $4: Hostname of the new master node # $5: port number of the new master node # $6: HOME directory of PostgreSQL # $7: User for postgrsql replication # $8: pcp user # $9: Path of pgpool # $10: pcp port # $11: Log directory of pgpool RecoverPostgresqlNode () { failed_node_id="$1" failed_node_host="$2" failed_node_pgdata="$3" new_master_node_host="$4" new_master_node_port="$5" PGHOME="$6" repl_user="$7" pcp_user="$8" pgpool_path="$9" pcp_port="${10}" PGPOOL_LOG_DIR="${11}" RECOVERY_CONF=${failed_node_pgdata}/recovery.conf # start Standby node on ${failed_node_host} ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${failed_node_host} -i ~/.ssh/id_rsa_pgpool "${PGHOME}/bin/pg_ctl -l /dev/null -w -D ${failed_node_pgdata} start" standby_is_running=$(CheckIfPostgresqlIsRunning ${failed_node_host} ${PGHOME} ${failed_node_pgdata}) > /dev/null 2>&1 master_is_real_master=$(CheckIfPostgresqlIsMaster ${new_master_node_host} ${new_master_node_port} ${PGHOME}) > /dev/null 2>&1 if [ $master_is_real_master != 'yes' ] then echo "$(date +"%F %T") follow_master.sh ERROR: PostgreSQL is not running as a master at ${new_master_node_host}. Exiting.." >> ${PGPOOL_LOG_DIR}/follow_master.log return 1 fi ## If Standby is running, synchronize it with the new Primary. if [ $standby_is_running == "yes" ] then echo "$(date +"%F %T") follow_master.sh INFO: Running pg_rewind for ${failed_node_host}" >> ${PGPOOL_LOG_DIR}/follow_master.log # Create replication slot "${failed_node_host}" ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${new_master_node_host} -i ~/.ssh/id_rsa_pgpool " ${PGHOME}/bin/psql -h ${new_master_node_host}-p ${new_master_node_port} -c \"SELECT pg_create_physical_replication_slot('${failed_node_host}');\" " RunPgrewind ${failed_node_host} ${new_master_node_host} ${new_master_node_port} ${PGHOME} ${repl_user} ${failed_node_pgdata} ${PGPOOL_LOG_DIR} if [ $? -ne 0 ] then echo "$(date +"%F %T") follow_master.sh INFO: pg_rewind failed. Try pg_basebackup." >> ${PGPOOL_LOG_DIR}/follow_master.log DoPgBasebackup ${failed_node_host} ${new_master_node_host} ${new_master_node_port} ${PGHOME} ${repl_user} ${failed_node_pgdata} ${PGPOOL_LOG_DIR} if [ $? -ne 0 ] then echo "$(date +"%F %T") follow_master.sh ERROR: pg_basebackup failed." >> ${PGPOOL_LOG_DIR}/follow_master.log # drop replication slot ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${new_master_node_host} -i ~/.ssh/id_rsa_pgpool " ${PGHOME}/bin/psql -h ${new_master_node_host} -p ${new_master_node_port} -c \"SELECT pg_drop_replication_slot('${failed_node_host}');\" " return 1 fi fi else echo "$(date +"%F %T") follow_master.sh INFO: ${failed_node_host} is not running. Try pg_basebackup." >> ${PGPOOL_LOG_DIR}/follow_master.log # Create replication slot "${failed_node_host}" ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${new_master_node_host} -i ~/.ssh/id_rsa_pgpool " ${PGHOME}/bin/psql -h ${new_master_node_host} -p ${new_master_node_port} -c \"SELECT pg_create_physical_replication_slot('${failed_node_host}');\" " DoPgBasebackup ${failed_node_host} ${new_master_node_host} ${new_master_node_port} ${PGHOME} ${repl_user} ${failed_node_pgdata} ${PGPOOL_LOG_DIR} if [ $? -ne 0 ] then echo "$(date +"%F %T") follow_master.sh ERROR: pg_basebackup failed." >> ${PGPOOL_LOG_DIR}/follow_master.log # drop replication slot ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${new_master_node_host} -i ~/.ssh/id_rsa_pgpool " ${PGHOME}/bin/psql -p ${new_master_node_port} -c \"SELECT pg_drop_replication_slot('${failed_node_host}');\" " return 1 fi fi # start Standby node on ${failed_node_host} ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${failed_node_host} -i ~/.ssh/id_rsa_pgpool \ "${PGHOME}/bin/pg_ctl -l /dev/null -w -D ${failed_node_pgdata} start" standby_is_running=$(CheckIfPostgresqlIsRunning ${failed_node_host} ${PGHOME} ${failed_node_pgdata}) > /dev/null 2>&1 # If Standby is running, attach this node if [ $standby_is_running == "yes" ] then # Run pcp_attact_node to attach Standby node to Pgpool-II. ${pgpool_path}/pcp_attach_node -h localhost -U ${pcp_user} -p ${pcp_port} -n ${failed_node_id} if [ $? -eq 0 ] then echo "$(date +"%F %T") follow_master.sh INFO: pcp_attach_node complete." >> ${PGPOOL_LOG_DIR}/follow_master.log echo "$(date +"%F %T") follow_master.sh INFO: follow master command complete." >> ${PGPOOL_LOG_DIR}/follow_master.log return 0 else echo "$(date +"%F %T") follow_master.sh ERROR: pcp_attach_node failed." >> ${PGPOOL_LOG_DIR}/follow_master.log return 1 fi # If start Standby failed, drop replication slot "${failed_node_host}" else ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${new_master_node_host} -i ~/.ssh/id_rsa_pgpool \ " ${PGHOME}/bin/psql -h ${new_master_node_host} -p ${new_master_node_port} -c \"SELECT pg_drop_replication_slot('${failed_node_host}')\" " echo "$(date +"%F %T") follow_master.sh ERROR: follow master command failed." >> ${PGPOOL_LOG_DIR}/follow_master.log return 1 fi } if [ $(CheckIfSSHIsPasswordless ${FAILED_NODE_HOST}) == "no" ] then echo 'follow_master.sh ERROR: passwordless SSH to postgres@"${FAILED_NODE_HOST}" failed. Please setup passwordless SSH.' >> ${PGPOOL_LOG_DIR}/follow_master.log exit 1 fi if [ $(CheckIfSSHIsPasswordless ${NEW_MASTER_NODE_HOST}) == "no" ] then echo 'follow_master.sh ERROR: passwordless SSH to postgres@"${NEW_MASTER_NODE_HOST}" failed. Please setup passwordless SSH.' >> ${PGPOOL_LOG_DIR}/follow_master.log exit 1 fi FAILED_NODE_HOST=$(GetHostname ${FAILED_NODE_HOST}) NEW_MASTER_NODE_HOST=$(GetHostname ${NEW_MASTER_NODE_HOST}) RecoverPostgresqlNode ${FAILED_NODE_ID} ${FAILED_NODE_HOST} ${FAILED_NODE_PGDATA} ${NEW_MASTER_NODE_HOST} ${NEW_MASTER_NODE_PORT} ${PGHOME} ${REPL_USER} ${PCP_USER} ${PGPOOL_PATH} ${PCP_PORT} ${PGPOOL_LOG_DIR} exit 0
2.4.3 设置 pgpool 服务
分别在两台主机上启动pool服务,并设置开机启动:
[root@node228 pgpool-II]# systemctl enable pgpool
[root@node228 pgpool-II]# systemctl start pgpool
日志会打印在 /var/log/messages 中.
3 方案验证
3.1 验证 pgpool-II 服务的高可用
1. 首先分别查看两台服务器上的IP地址,确定虚拟IP在哪台服务器上。命令如下:
[root@node228 ~]# ip addr show | grep -i "10.40.239.240"

如图, pgpool-II 集群的主节点在服务器node228上。
2. 停止pgpool-II主节点的服务:
[root@node228 ~]# systemctl stop pgpool
3. 查看虚拟ip是否在哪台服务器上:
[root@node228 ~]# ip addr show | grep -i "10.40.239.240"


如图,虚拟ip漂移到 node229 这台服务器上。
4. 在node229 上进入PostgreSQL 的bin目录,通过pgpool访问数据库,判断能否成功。下图表示访问成功。

3.2 验证 PostgreSQL 的高可用
1. 进入PostgreSQL 的bin目录,查看node228上的PostgreSQL的状态:
[root@node228 bin]# cd /opt/pg114/bin
[root@node228 bin]# ./psql -h 10.40.239.228 -p 5432 -U postgres -c "select pg_is_in_recovery();"
如图,node228 是PostgreSQL集群的主节点。

2. 查看node229上的PostgreSQL的状态:
[root@node228 bin]# ./psql -h 10.40.239.229 -p 5435 -U postgres -c "select pg_is_in_recovery();"
如图,node229 是PostgreSQL集群的备节点,处于在线恢复状态。

3. 查看流复制状态:
[root@node228 bin]# ./psql -h 10.40.239.228 -p 5432 -U postgres -c "select * from pg_stat_replication;"

4. 关闭node228上的主库:
[root@node229 bin]# su postgres
[postgres@node228 bin]$ ./pg_ctl stop -D ../data
5. 再查看node229上的数据库状态。如图,原来的备库已经切换为了主库。

6. 查看流复制状态。如图,node228 上的数据库已经作为备库运行。

7. 查看数据库节点是否加入到pgpool-II集群中:
[postgres@node228 bin]$ ./psql -h 10.40.239.240 -p 9999 -U postgres -c "show pool_nodes;"
如图,两个节点均由pgpool-II管理:

3.3 验证 pgpool-II 的负载均衡功能
1. 进入postgresql 的 bin 目录,多次执行下面的命令,观察结果:
./psql -h 10.40.239.240 -p 9999 -U postgres -c "select inet_server_addr()"
这条命令是通过pgpool 代理端口访问数据库,获取数据库IP 地址。可以看到,访问请求可能会被分发到两个数据库节点中的任何一个。
参考文献
[1] The Pgpool Global Development Group. pgpool-II 4.1.1 Documentation.2020-05-21
[2] The Pgpool Global Development Group. pgpool-II 3.5.4 Documentation. 2011-01-29
[3] PostgeSQL 全球开发小组. PostgreSQL 11.2 手册. 彭煜玮, 瀚高软件译.
[4] Francs. PostgreSQL 流复制 + Pgpool-II 实现高可用 HA. 2014-10-03
[5] 遥想公瑾当年. PGPool-II+PG流复制实现HA主备切换. 2016-12-21
