Mahout介绍
3.11简介
Mahout:是一个Apache的一个开源的机器学习库,主要实现了三大类算法Recommender
(collaborative filtering)、Clustering、classification。可扩展,用Java实现,用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
Mahout为数据分析人员,解决了大数据的门槛;为算法工程师提供了基础算法库;为Hadoop开发人员提供了数据建模的标准。
——张丹(Conan) http://blog.fens.me/hadoop-mahout-roadmap/
3.12Mahout历史演变
Mahout began life in 2008 as a project of Apache`s lucene project .Lucene provides advanced implementations of search ,text mining and information-retrival techniques.In the universe of computer science ,there concepts are adjacent to machine learning techniques like clustering and to an extent ,classification .As a result,some of the work of the Lucene committers that fell more into these machine learning areas was spun off into its own subproject. Soon after ,Mahout absorbed the Taste open source collaborative filtering project.As of April 2010 ,Mahout became a top-level Apache project in its own right, and get a bran-new elephant rider logo to boot.
——Mahout in Action
25 April 2014 - Goodbye MapReduce
The Mahout community decided to move its codebase onto modern data processing systems that offer a richer programming model and more efficient execution than Hadoop MapReduce. Mahout will therefore reject new MapReduce algorithm implementations from now on. We will however keep our widely used MapReduce algorithms in the codebase and maintain them.
We are building our future implementations on top of a DSL for linear algebraic operations which has been developed over the last months. Programs written in this DSL are automatically optimized and executed in parallel on Apache Spark.
——http://mahout.apache.org/
3.13Hadoop家族中Mahout的结构图
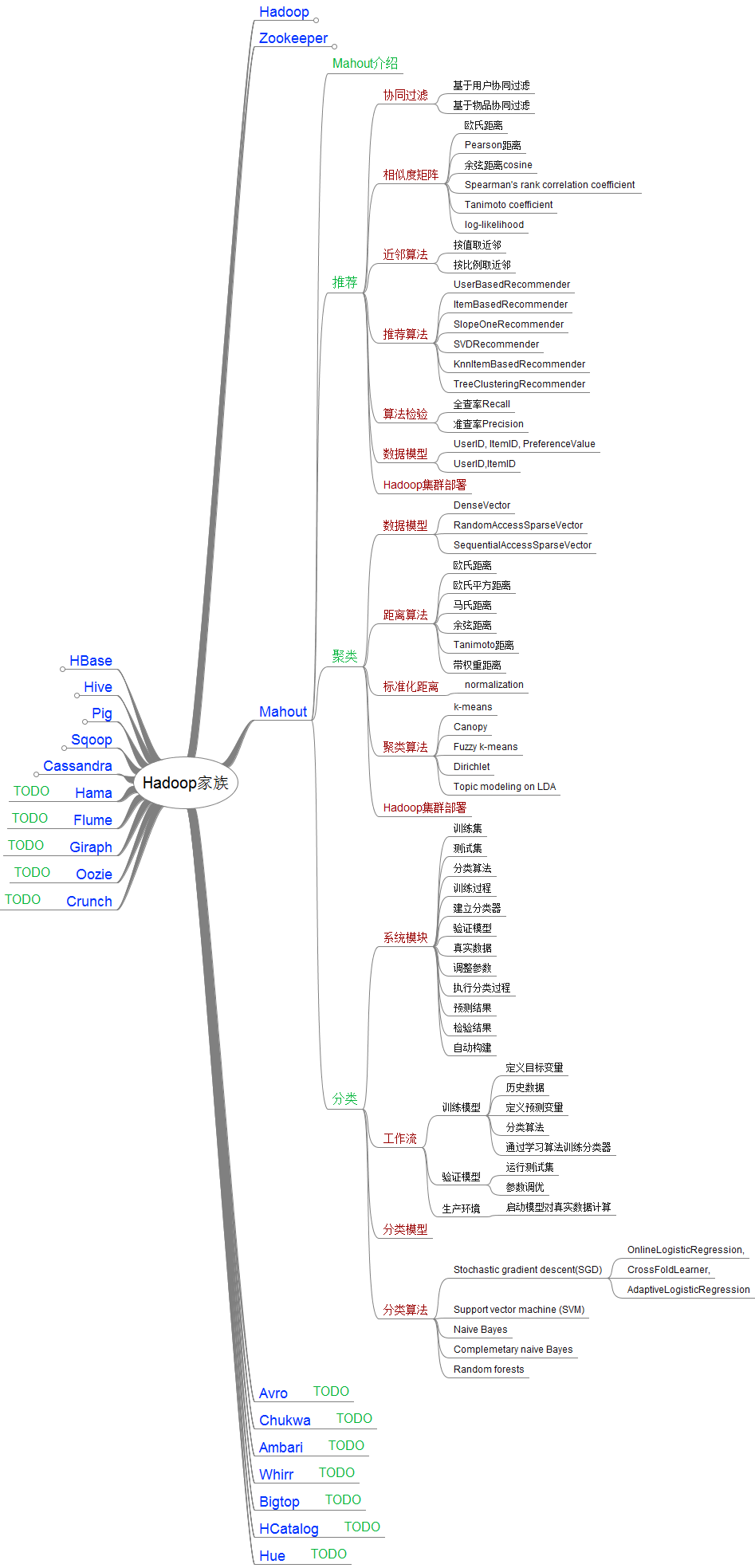
主要算法:
|
算法类 |
算法名 |
中文名 |
|
分类算法 |
Logistic Regression |
逻辑回归 |
|
Bayesian |
贝叶斯 |
|
|
SVM |
支持向量机 |
|
|
Perceptron |
感知器算法 |
|
|
Neural Network |
神经网络 |
|
|
Random Forests |
随机森林 |
|
|
Restricted Boltzmann Machines |
有限波尔兹曼机 |
|
|
聚类算法 |
Canopy Clustering |
Canopy聚类 |
|
K-means Clustering |
K均值算法 |
|
|
Fuzzy K-means |
模糊K均值 |
|
|
Expectation Maximization |
EM聚类(期望最大化聚类) |
|
|
Mean Shift Clustering |
均值漂移聚类 |
|
|
Hierarchical Clustering |
层次聚类 |
|
|
Dirichlet Process Clustering |
狄里克雷过程聚类 |
|
|
Latent Dirichlet Allocation |
LDA聚类 |
|
|
Spectral Clustering |
谱聚类 |
|
|
关联规则挖掘 |
Parallel FP Growth Algorithm |
并行FP Growth算法 |
|
回归 |
Locally Weighted Linear Regression |
局部加权线性回归 |
|
降维/维约简 |
Singular Value Decomposition |
奇异值分解 |
|
Principal Components Analysis |
主成分分析 |
|
|
Independent Component Analysis |
独立成分分析 |
|
|
Gaussian Discriminative Analysis |
高斯判别分析 |
|
|
进化算法 |
并行化了Watchmaker框架 |
|
|
推荐/协同过滤 |
Non-distributed recommenders |
Taste(UserCF, ItemCF, SlopeOne) |
|
Distributed Recommenders |
ItemCF |
|
|
向量相似度计算 |
RowSimilarityJob |
计算列间相似度 |
|
VectorDistanceJob |
计算向量间距离 |
|
|
非Map-Reduce算法 |
Hidden Markov Models |
隐马尔科夫模型 |
|
集合方法扩展 |
Collections |
扩展了java的Collections类 |
3.14Mahout在Hadoop 平台上的安装
1.下载mahout:http://archive.apache.org/dist/mahout/
2.下载Maven 一般ubuntu系统直接 sudo apt-get install maven
3.将mahout 的文件解压成文件夹mahout 并放入/usr文件夹
sudo tar -zxvf mahout-distribution-0.9.tar.gz
sudo mv mahout-distribution-0.9 /usr/mahout
4.创建一个脚本,配置mahout的环境。脚本内容
export JAVA_HOME=/usr/lib/jvm/jdk8/
export MAHOUT_HOME=/usr/mahout9
export MAHOUT_CONF_DIR=/usr/mahout9/conf
export PATH=$MAHOUT_HOME/bin:$MAHOUT_HOME/conf:$PATH
export HADOOP_HOME=/usr/hadoop
export HADOOP_CONF_DIR=/usr/hadoop/conf
export PATH=$PATH:$HADOOP_HOME/bin
5.运行脚本文件,运行mahout命令
6.到这里就表示安装成功,下面下载一个测书数据,是一下mahout 的Kmeans聚类方法。
Sudo wget http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data
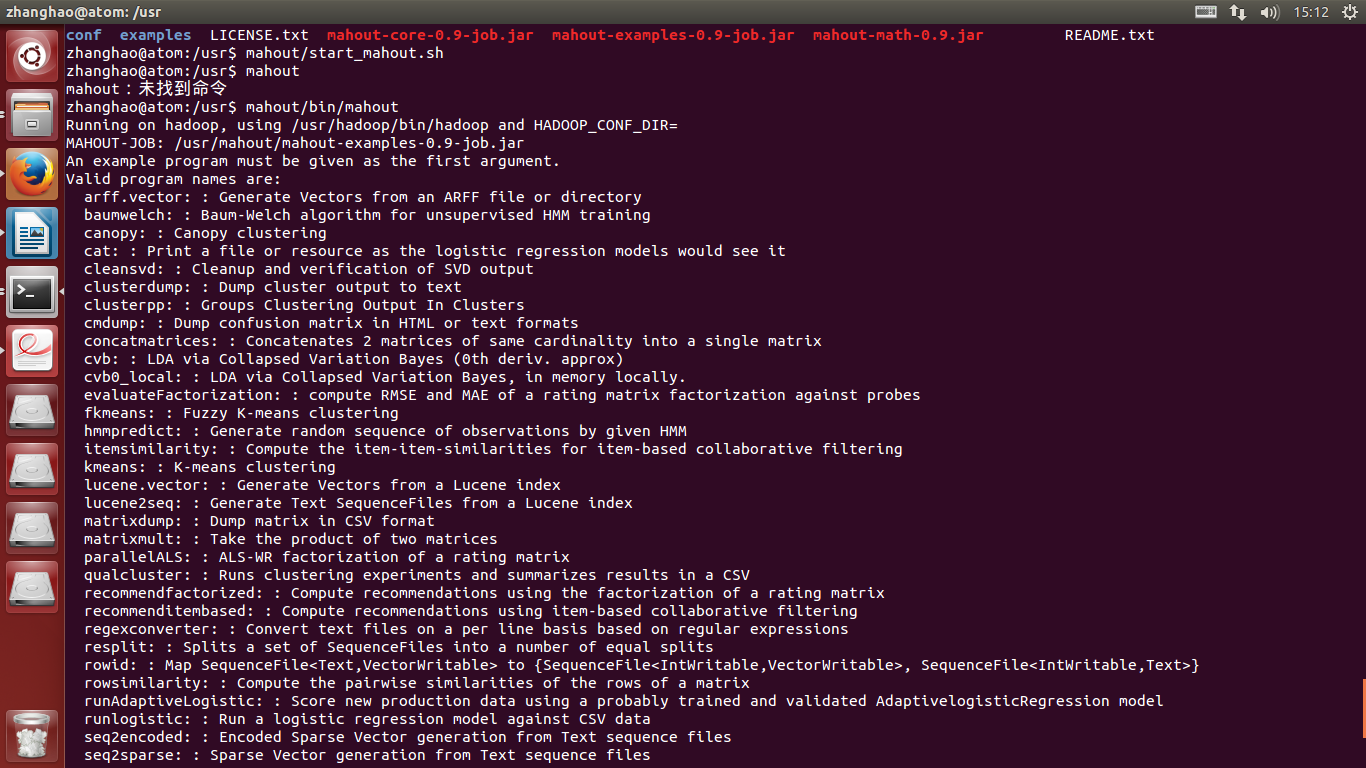
7.将数据上传到HDFS 上
hdfs fs -mkdir testdata
hdfs fs -put /usr/synthetic_control.data ./testdata
8.运行k-means聚类算法
mahout -core org.apache.clustering.syntheticcontrol.kmeans.Job
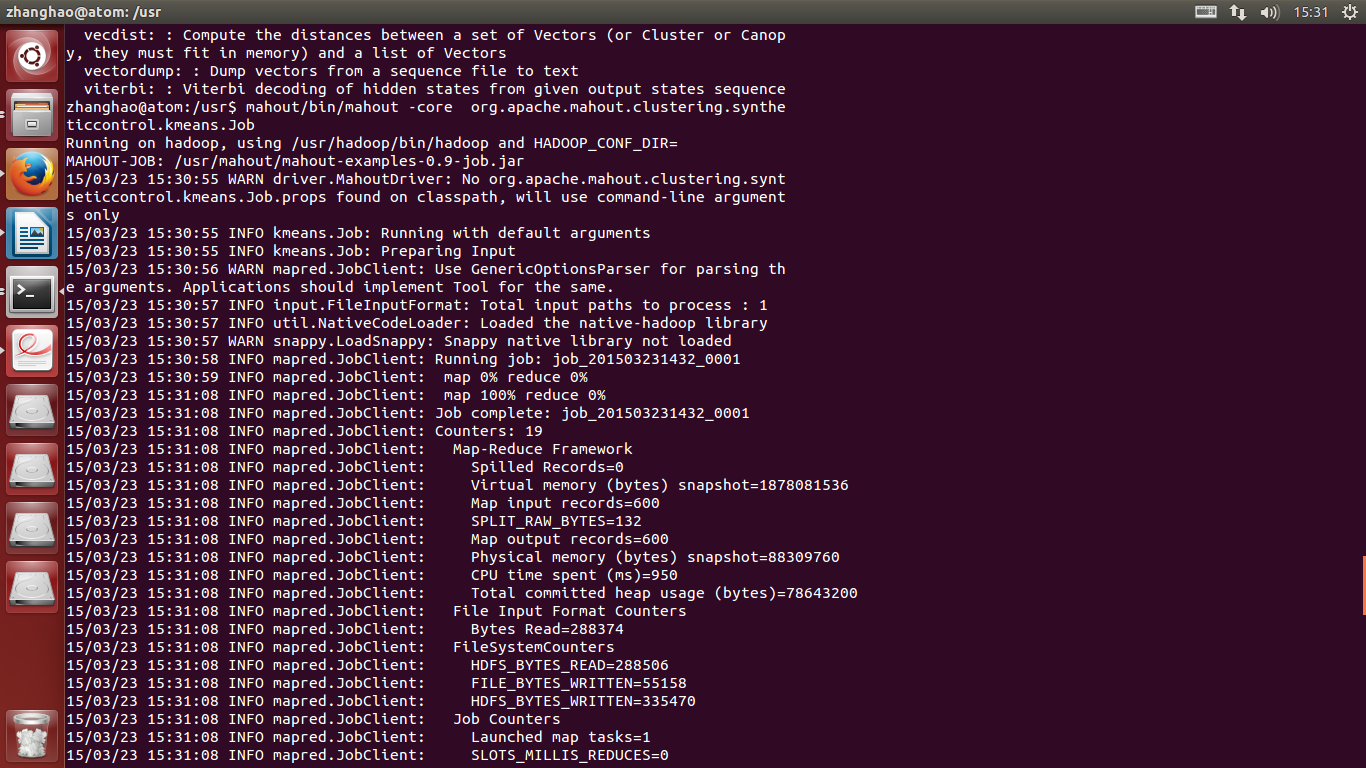

 浙公网安备 33010602011771号
浙公网安备 33010602011771号