级联架构-嵌入式深度学习2
嵌入式深度学习-优化的层次级联处理
本系列博客主要以Bert Moons《Embedded Deep Learning》翻译而成
Goetschalckx K, Moons B, Lauwereins S, Andraud M, Verhelst M (2018) Optimized hierarchical cascaded processing. IEEE J Emerging Sel Top Circuits Syst. https://doi.org/10.1109/JETCAS.2018.2839347
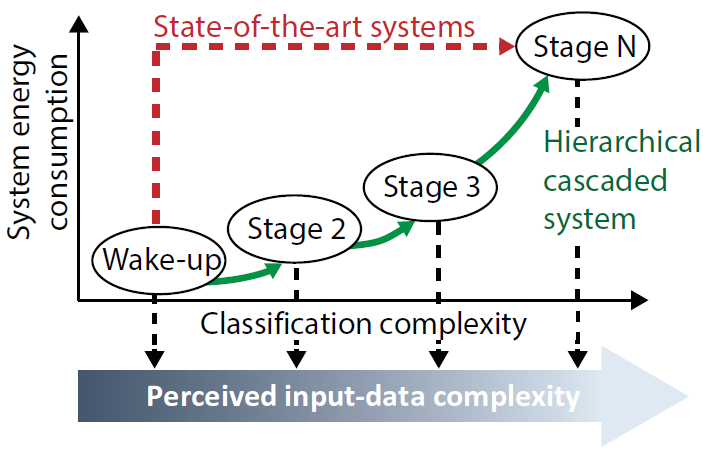
该系统的示意图见图2.1。多个分层阶段被级联并且可以在早期潜在地过滤数据,子任务的复杂性和成本都会在分层链的下方进一步增加。在语音识别中,“沉默”、“Alexa”或“你”等常见类别可以使用廉价分类器早期识别,从而可能防止最终昂贵的阶段开启。因此,即使后期阶段更昂贵,也由于早期阶段的判别功能而不会被过度使用。该提议的体系结构结合了级联和基于树的拓扑结构的优点。与线性级联方法一样,在最后一个或多个阶段之前消除了大部分负样本,从而在整个系统中节省了功率。与基于树的方法一样,支持多类问题。然而,早期错误检测仍然可以在后续阶段中被纠正。这项工作提供了一个框架,用于在这些分层级联中最小化总体能量消耗或计算成本,同时最大化或保持系统级别的精度。
该框架的主要贡献有:
- 将唤醒机制的系统推广为层次级联分类器:使用一个越来越复杂的分类器序列建立一个多分类系统
- 提出一个理论屋顶线模型(roofline model)以评估性能。
- 推导了通用分层模型的一般折中方法。讨论输入数据统计规律、使用的层级数目以及单层级性能等设计要点。
对两级唤醒系统进行泛化
层次级联系统通过构建针对系统能效进行优化的功能层级结构在不影响性能的情况下最小化总的计算开销。如果前面的层级开销很低,同时能处理大部分数据,让它们不经过后面开销较高的层级,并且还不会引入过多的不可恢复的错误,则这种层级结构就会比单层系统更高效。
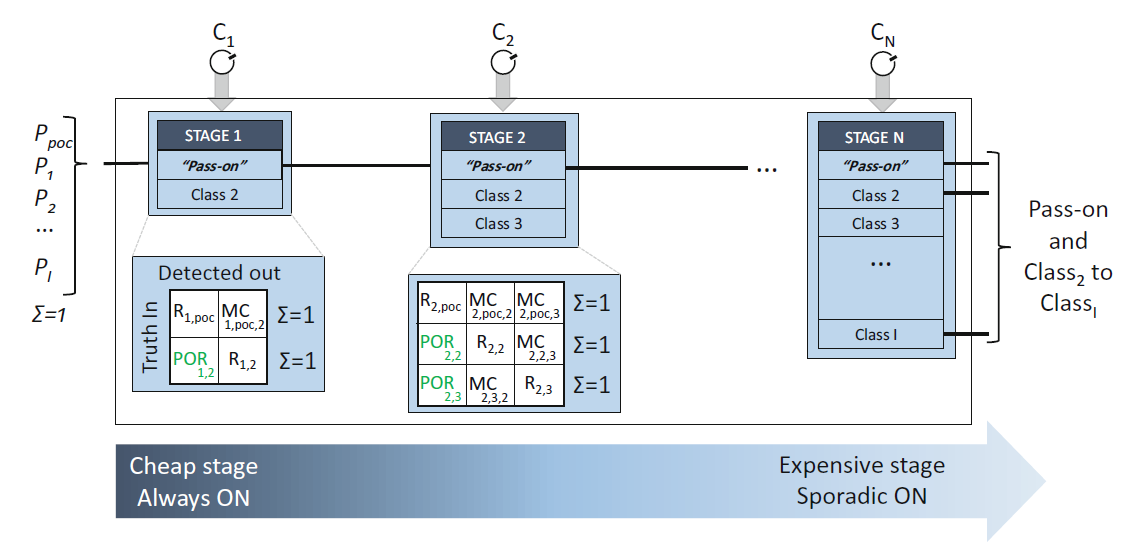
如图2.2所示,整个系统被划分为N个层级。假定最终任务是处理一个复杂的多类别识别任务,例如包含100张人脸的图像识别任务。第一个任务一般来说是一个二值的唤醒检测器。典型的层级结构的最开始是一个简单的二值分类器,将如背景图像或者声学噪声等明显的负样本移除。如果一个输入被判定为正样本(即传递类,pass-on-class,poc),表明图像有意义,那么下一级就会被激活并对输入进行进一步的识别。下一层级会执行更为复杂的分类任务,开销也因更高的复杂度和更好的分类性能以远超线性的趋势增长。
传递率(pass-on-rate,\(POR_{n,i}\))是在第n个阶段中,属于类别i的实例被传递到下一个分类器的概率。它表示在该阶段中,被正确分类为类别i的实例将继续传递给下一个分类器的概率。 $$POR_{n,i}=P(\hat{y}_n=poc|y=i)$$
式中,\(poc\)是传递类(pass-on-class)的缩写。
层次化指标
在分层级联系统中,每个阶段都有一个相关的成本、精确度和召回率。这些指标可以用来评估系统性能和效率。
召回率
召回率(Recall):也称为灵敏度(Sensitivity)或真阳性率(True Positive Rate)。给定类别\(i\)的实例被正确分类的概率可以通过召回率\(R_{n,i}\)来表示:
在优化的过程中,\(POR_{n,i}\) 和 \(R_{n,i}\) 都是设计中可以选择的变量,因为如果一个输入样本在第n层被错分为传递类,那么它仍然有机会在n+1到N层中测到正确的分类结果;如果一个样本在给定阶段被错误地分类为另一个类别(非传递类),那么后面的层都不会开启,结果也得不到修正。
故把第\(n\)层的一个属于第\(i\)类的样本被错判到其他类\(j\)的概率定义为错判率:$$MC_{n,i,j}=P(\hat{y}_n=j\notin{poc,i}|y=i)$$
代价
代价(Cost):系统的平均总代价为:$$C_{1\to N}=C_1+\sum_{i=1}^I (P_i \times \sum_{n=2}^N(C_n \times \prod_{\eta = 1}^{n-1} POR_{\eta, i})) $$
其中, \(\prod_{\eta = 1}^{n-1} POR_{\eta, i}\)代表第\(i\)类一直累积传递至第\(n
\)层的概率。此概率分别乘上\(P_i\)再对\(i\)求和就可以得到处理每个样本的系统平均总代价。
第\(i\)类的最终召回率\(R_{1→N,i}\)与输入的先验概率无关:
其中\(R_{n,i}\)是第\(i\)类在第\(n\)层的召回率。
如果第\(n\)层无法识别第\(i\)类,则将i视为传递类\(p\)的一部分,即\(R_{n,i}=0\)且\(POR_{n,i} = POR_{n,poc}\)。如果认为每类输出的召回率同等重要,则平均总召回率为:
公式表明,系统的高召回率可以通过每层的高传递率或高召回率实现,因为如果一个样本被传递到下一层,它仍可在后续阶段被正确分类。然而,较高的传递率会导致较高的总代价,因为这会导致后面的层次更容易被激活。
精确度
当优化系统的平均召回率时,系统对每一类的分类精度也会自动得到优化。
这两个公式将真阳性样本的数量$ tp_i $和误判样本数量 \(mc_{ij}\) 同总召回率 \(R_{1→N}\) 和总精度 \(PR_{1→N}\) 联系到一起。最大化总召回率和最大化总精度都要求最小化总假阳性样本数或误判数。
结果表明,对于任一多分类系统,都可以通过优化召回率获得更高的精度。
层次化分类器的 Roofline 模型
理想Roofline上限
参考博客:https://www.jianshu.com/p/e5c168a99ba8 与 https://zhuanlan.zhihu.com/p/34204282
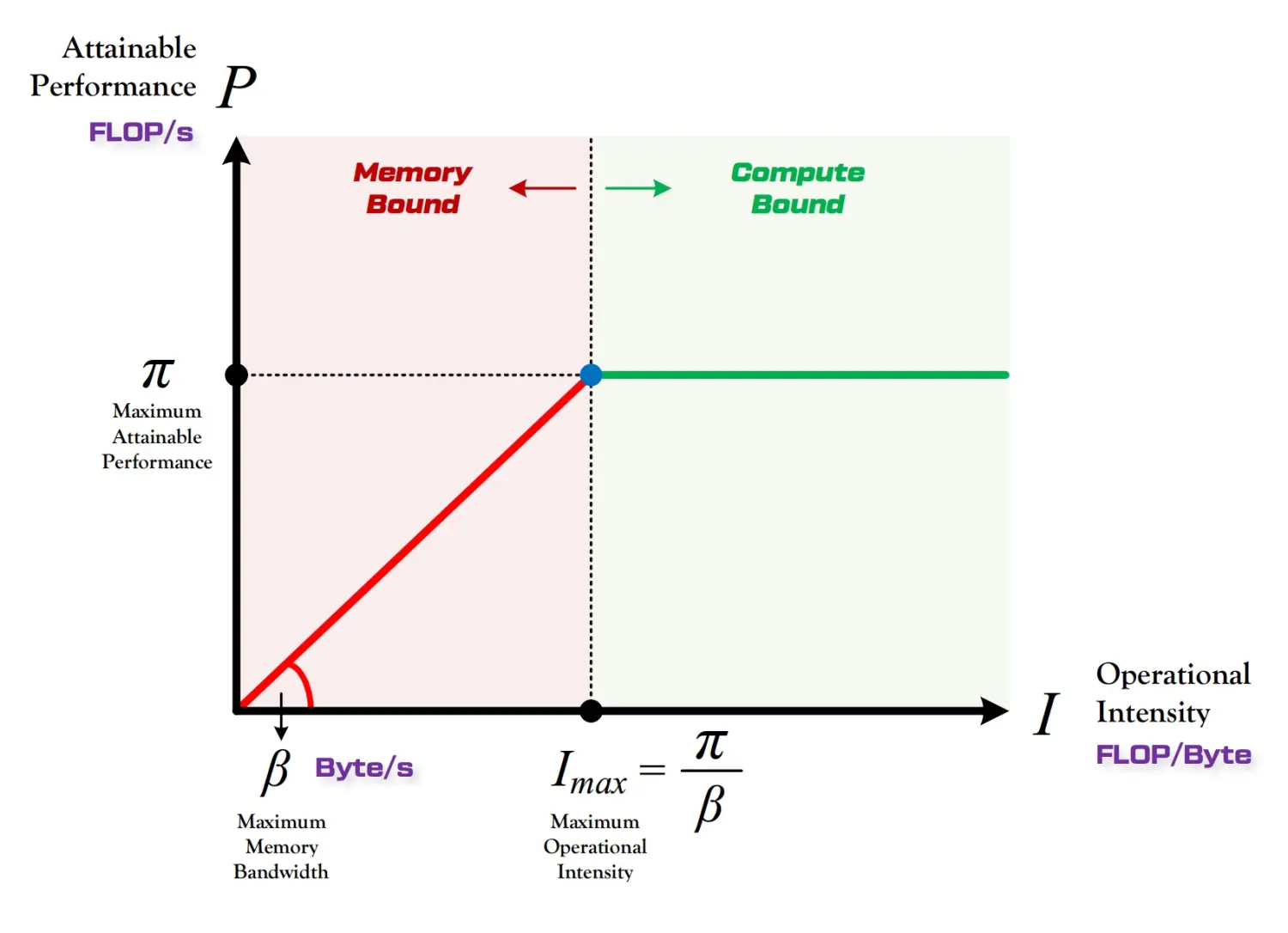
这条线表明,当这个应用程序的计算密度大于一定值之后,将会变成一个受算术逻辑单元的计算量所限制的程序;而这个计算密度如果小于一定值,将会变成一个受存储器带宽所限制的程序。
层次化分类器的 Roofline 模型
所有类的平均召回关系与所有类的平均传递率之间的关系为:
在最佳情况下, 所有分类都正确, 也就是说样本要么通过要么被正确分类。在这种情况下, 上式 (2-9) 可以达到它的 Roofline 上限, 即如 下式 (2-10) 和图 2-3 所示:
理想Roofline上限和真实曲线的示例在图2-3中给出,理想的Roofline曲线根据式(2-10)画出,而非理想情况下的曲线则是真实测得,它基本遵从式(2-9)。当第n层中的平均POR,即 \(avg_i (POR_{n,i})\) 低于 $ 1/I $ 时,这种情况是不理想的,因为如果这样就肯定有属于传递类的样本被错误地分类了。曲线在$ 1/I $ 处存在一个转折点。在这里,所有样本均恰好正确分类(它们的平均召回率为1),除了传递类的样本,没有一个样本被传递(它们的传递率等于0)。在 \(avg_i (POR_{n,i})\) 大于 $ 1/I $ 时,最佳平均召回率下降,这意味着更多的样本被传递到下一层。这不会导致灾难性的失败,因为在接下来的任何层级中,它们仍然可以得到正确的分类。在理想的Roofline上限情况下,转折点的位置仅是给定层级中类别数量的函数
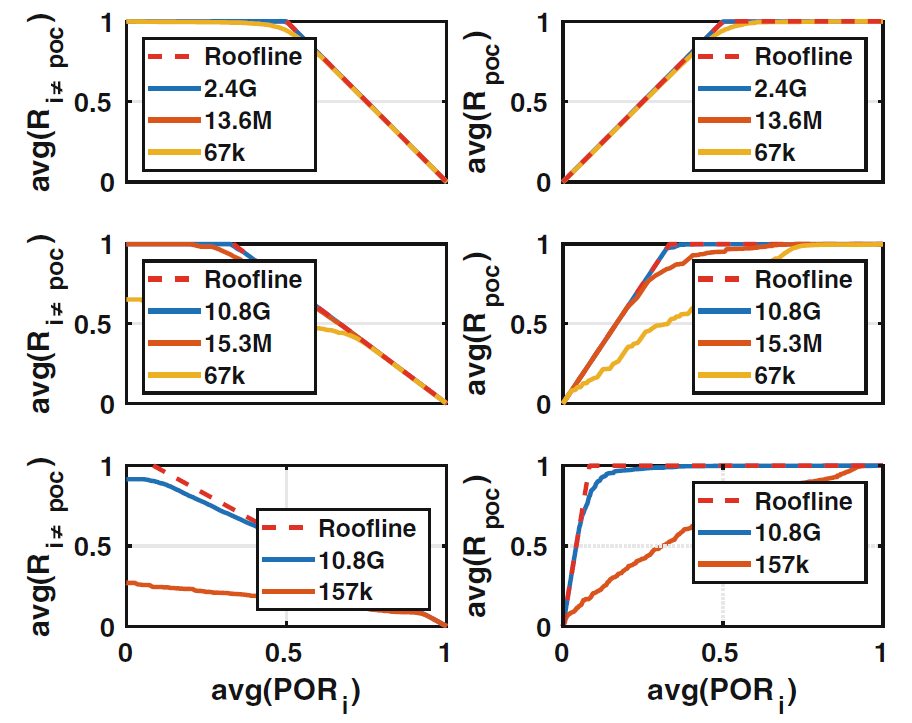
在图 2-3 中,每个 Roofline 曲线在 $ 1/I $ 处为转折点。这些图上的每条实线都代表一个真实的分类器。因为真实分类器会引入错误分类,这些真实分类器的结果与 Roofline 模型都不相同。但显然 Roofline 模型提供了很好的上限,并且与最复杂、成本最高的分类器结果非常匹配。分类器的复杂性和建模能力越强自然地它就越接近最佳的 Roofine模型。Roofline 的偏离主要是由于不希望有错分类,这种错误无法在层次结构的后续阶段进行补偿。
每个分类器在召回率与传递率之间存在着关联曲线。通过选择阈值 \(\tau\) 在该曲线上任意选择工作点。
- \(\tau=0\) 则该层将传递所有输人样本, $avg_i (POR_{n,i}) = 1 $
- \(\tau=1\) 则几乎不会传递任何样本,而是进行更多的独立分类
理想模型中无分类错误。一个不良模型也不一定会破坏整个系统的性能,因为可以将这一层级的阈值设置为高传递率。但是,这样也就意味着更多的数据被送到了代价较大的靠后的层级中,导致更高的总成本。
