译者评论:
微服务模式中最为头疼的问题就是——数据问题,因为数据会散布在多个微服务之间,这通常意味着数据被分散到多个数据库中,这时微服务必须自行保证跨微服务的数据一致性,而无法利用数据库本身的机制解决。随之而来的是微服务滚动升级时数据库同步升级的问题。
本系列文章的第九篇和第十篇会初步的呈现这个问题,之后的几篇文章会介绍问题的解决方案,但是这些解决方案实现起来比较复杂、学习门槛较高,远不够完美。在我们今后的工作中,也会对这部分问题做较大的投入,致力在实践中总结出更为完善的方案。
背景
如果用微服务模式开发网店应用,那么大部分的服务都需要用某种数据库保存数据。例如,订单服务存储订单信息,客户服务存储客户信息。
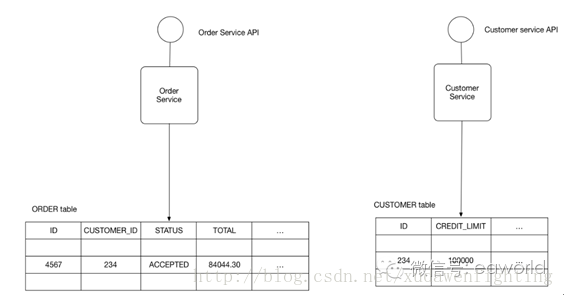
问题
在微服务应用中,应该采用什么数据库架构?
需求
服务必须松耦合,以确保可以独立进行开发,部署和扩展。
一些业务事务必须在多个服务之间保持数据一致性。例如,下单用例必须保证新的订单不会超过客户的信用限额。其他业务事务必须更新多个服务的数据。
一些业务事务需要查询多个服务的数据。例如,查询可用信用必须查询客户信息以获取客户的信用限额,并查询订单信息以获取该客户的全部未结订单(才可以得到该客户的剩余可用信用)。
一些查询必须Join来自多个服务的数据。例如,查询某一特点区域的客户和这些客户的近期订单,需要Join来自客户信息服务和订单信息服务的数据。
为进行扩展,数据库有时必须进行复制和Sharding。参见ScaleCube。
不同的服务有不同的数据存储需求。对于某些服务,关系型数据库就是最好的选择。其他一些服务可能会需要NoSQL数据库,如善于存储复杂、非结构化数据的MongoDB,或者能够有效存储和查询图数据的Neo4J。
方案
使各微服务的持久化数据私有于该服务,并只能通过该服务的API进行访问。以下示意图展现了这种模式的结构。
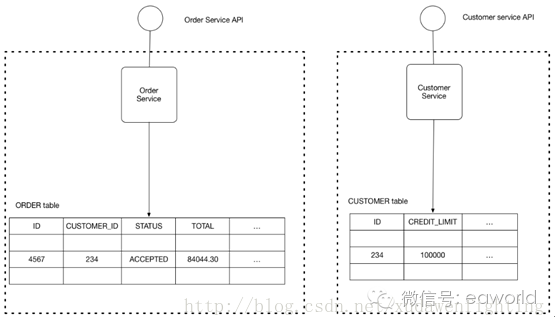
服务的数据库实际上服务实现的一部分。其他服务不能直接访问该服务的数据库。
有几种方法可以使服务的持久化数据私有。不需要为每一服务部署一个数据库。例如,使用关系型数据库,则:
Private-tables-per-service——每一服务拥有一系列只能被该服务访问的表
Schema-per-service——每一服务拥有一个为该服务所私有的数据库Schema
Database-server-per-service——每一服务拥有自己的数据库
Private-tables-per-service 和 schema-per-service都有最低的额外开销。Schema-per-service有清晰的数据所有权,因而更受欢迎。一些高吞吐量的服务可能也需要独立的数据库。
为模块化设置屏障是个不错的办法。例如,为每个服务分配不同的数据库用户,并为其设置数据库访问控制机制,如授权。如果没有这种屏障来进行封装,开发者会绕过服务的API,直接访问数据。
结果
独享数据库拥有以下优势:
确保服务是松耦合的。一个服务的数据库的变化不会影响其他服务。
每一服务都可以使用最能满足其需求的数据库。例如,一个用于文本检索的服务可以使用ElasticSearch。操作社交图谱的服务可以使用Neo4j。
但独享数据库有以下劣势:
跨多个服务的业务事务并不简单。由于CAP定理的限制,最好的选择是避免分布式事务。另外许多现代数据库(NoSQL)也不支持分布式事务。最好的解决方案是使用最终一致性的事件驱动架构。当服务更新数据时,该服务就会发布事件。其它服务会订阅事件,并通过更新数据做出响应。
通过Join来自多个数据库的数据实现查询是很有挑战性的。有以下几种解决方案:
应用端Join---在应用端而非数据库端进行Join。例如,一个服务(或者API网关)要检索客户信息和订单,首先要从客户服务检索客户信息,然后再通过查询订单服务返回客户最新的订单信息。
命令查询职责分离(CQRS)——维护一个或多个包含多个服务数据的物化视图。视图会被保存在订阅了事件的服务中,每个服务在更新数据时会发布出这些事件。例如,网店可以通过维护一个客户信息和订单信息的Join视图来查询特定区域客户和他们的近期订单。该视图由订阅了客户信息事件和订单信息事件的服务进行更新。
管理多种SQL数据库和NoSQL数据库带来的复杂性。
相关模式
微服务模式催生了对该模式的需求
事件驱动架构模式是实现事务最终一致性的有效途径
Command Query Responsibility Segregation (CQRS)模式是执行复杂查询的有效途径
共享数据库反模式描述了微服务中共享数据库带来的难题
博客地址:https://blog.csdn.net/xiang__liu,https://www.cnblogs.com/xiang--liu/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号