


130242014060-郑佳敏-第2次实验
一、实验目的
1.熟悉体系结构的风格的概念
2.理解和应用管道过滤器型的风格。
3、理解解释器的原理
4、理解编译器模型
二、实验环境
硬件:
软件:Python或任何一种自己喜欢的语言
三、实验内容
1、实现“四则运算”的简易翻译器。
结果要求:
1)实现加减乘除四则运算,允许同时又多个操作数,如:2+3*5-6 结果是11
2)被操作数为整数,整数可以有多位
3)处理空格
4)输入错误显示错误提示,并返回命令状态“CALC”
加强练习:
1、有能力的同学,可以尝试实现赋值语句,例如x=2+3*5-6,返回x=11。(注意:要实现解释器的功能,而不是只是显示)
2、尝试实现自增和自减符号,例如x++
2、采用管道-过滤器(Pipes and Filters)风格实现解释器

图2 管道-过滤器风格
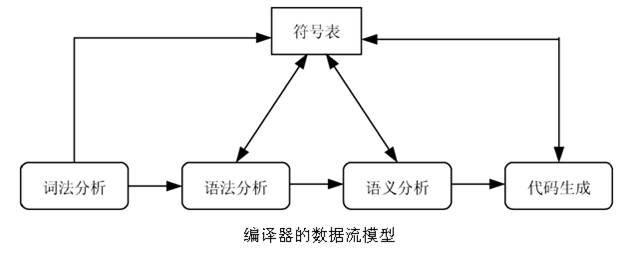
图 3 编译器模型示意图
本实验,实现的是词法分析和语法分析两个部分。
四、实验步骤:
要求写具体实现代码,并根据实际程序,画出程序的总体体系结构图和算法结构图。
总体结构图参照体系结构风格。
算法结构图如下:
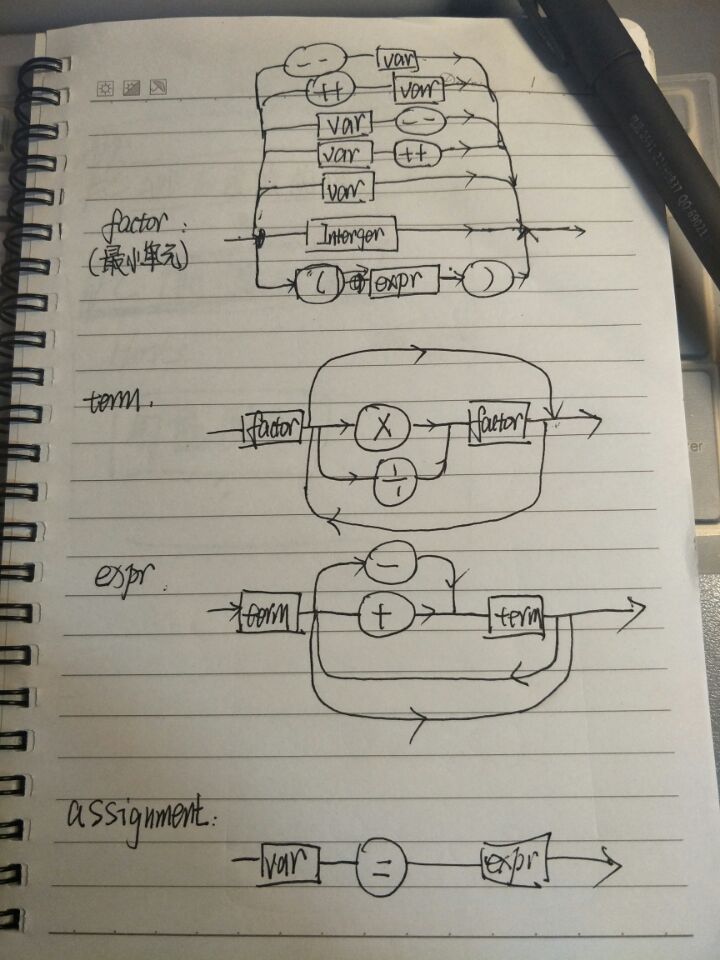
代码:
INTEGER, PLUS, MINUS, MUL, DIV, LPAREN, RPAREN, EOF,VARIABLE,EQUALITY,INCREMENT,REDUCE = (
'INTEGER', 'PLUS', 'MINUS', 'MUL', 'DIV', 'LPAREN', 'RPAREN', 'EOF','VARIABLE','EQUALITY','INCREMENT','REDUCE')
# 定义一个全局的变量数组来保存“变量名”:值的键值对
variables = {}
# Token是标记
class Token(object):
def __init__(self,type,value):
self.type = type
self.value = value
# toString
def __str__(self):
return 'Token({type},{value})'.format(
type=self.type,
value = self.value
)
class Lexer(object):
# 词法分析器
# 给每个词打标记
# text为输入的表达式
def __init__(self, text):
self.text = text
# pos为当前位置
self.pos = 0
# current_char为当前字符
self.current_char = self.text[self.pos]
# 取字符错误时调用的方法
def error(self):
# raise 抛出异常
raise Exception('Invalid Char')
#前进的方法,即取下一个字符
def advance(self):
# 往下走,取值
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None
else:
self.current_char = self.text[self.pos]
def variable(self):
# 变量处理
variable = ''
while self.current_char is not None and self.current_char.isalpha():
variable = variable + self.current_char
# 往下走,取值
self.advance()
# 取值完毕后,将该变量存入字典中
if variable not in variables:
variables[variable] = None
return variable
def integer(self):
# 多位整数处理
result = ''
while self.current_char is not None and self.current_char.isdigit():
result = result + self.current_char
# 往下走,取值
self.advance()
return int(result)
# 处理输入时的非法空格
def deal_space(self):
# 循环遍历,遇到空格则跳过,取下一个字符
while self.current_char is not None and self.current_char.isspace():
self.advance()
def get_next_token(self):
# 打标记:1)pos+1,2)返回Token(类型,数值)
while self.current_char is not None:
# 空格处理
if self.current_char.isspace():
self.deal_space()
# 数字处理(判断是否为多位整数)
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
# 加号处理Plus
if self.current_char == '+':
# # 判断是自增还是加号
# if self.get_next_token() '+':
# self.advance()
# return Token(PLUS, '+')
self.advance()
return Token(PLUS, '+')
# 减号处理Minus
if self.current_char == '-':
self.advance()
return Token(MINUS, '-')
# 左括号
if self.current_char == '(':
self.advance()
return Token(LPAREN,'(')
# 右括号
if self.current_char == ')':
self.advance()
return Token(RPAREN,')')
# 乘号
if self.current_char == '*':
self.advance()
return Token(MUL,'*')
# 除号
if self.current_char == '/':
self.advance()
return Token(DIV,'/')
# 若是判断出字符则进入变量获取的方法
if self.current_char.isalpha():
return Token(VARIABLE,self.variable())
# 等号
if self.current_char == '=':
self.advance()
return Token(EQUALITY,'EQUALITY')
# # 自增
# if self.current_char == '++':
# self.advance()
# return Token(EQUALITY,'EQUALITY')
# 其余均为非法字符
self.error()
# 取到None字符 返回一个空的Token 表示循环结束
return Token(EOF, None)
class Interpreter(object):
# 句法分析
# 语法树
# 语法树中的一个参数为词法分析器Lexer
def __init__(self, lexer):
self.lexer = lexer
self.current_token = self.lexer.get_next_token()
def error(self):
raise Exception('Invalid Syntax')
# 当当前Token取值完毕
# 删除当前的Token,取下一个Token的值
def eat(self, token_type):
# 跳过与当前相同的Token,取下一个Token
if self.current_token.type == token_type:
self.current_token = self.lexer.get_next_token()
else:
# 若在删除的过程中出错,会引起整体的错误,故抛错
self.error()
# 工厂方法
def factor(self):
token = self.current_token
# 判断当前要删除的Token类型
if token.type == INTEGER:
self.eat(INTEGER)
return token.value
# 将类型为Variable的变量返回
if token.type == VARIABLE:
self.eat(VARIABLE)
return variables[token.value]
# 左括号
elif token.type == LPAREN:
self.eat(LPAREN)
result = self.expr()
self.eat(RPAREN)
return result
def term(self):
result = self.factor()
while self.current_token.type in (MUL, DIV):
token = self.current_token
if token.type == MUL:
self.eat(MUL)
result = result * self.factor()
if token.type == DIV:
self.eat(DIV)
result = result / self.factor()
return result
def expr(self):
result = self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
result = result + self.term()
if token.type == MINUS:
self.eat(MINUS)
result = result - self.term()
return result
def assignment(self):
if self.current_token.type == VARIABLE:
var = self.current_token.value
self.eat(VARIABLE)
if self.current_token.type == EQUALITY:
self.eat(EQUALITY)
variables[var] = self.expr()
return var
def printResult(text):
lexer = Lexer(text)
variableKey = Interpreter(lexer).assignment()
print(variableKey,"=",variables[variableKey])
def main():
while True:
try:
text = input('calc_> ')
except EOFError:
break
if not text:
continue
# try:
printResult(text)
# except Exception:
# print('Invalid Syntax')
if __name__ == '__main__':
main()
实验结果:
1.基本功能:

2.额外功能
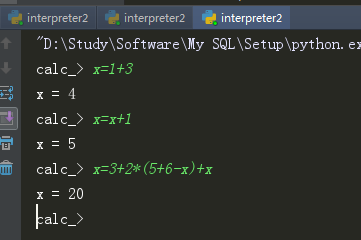
五、实验总结
体系结构是需求分析和概要设计之间的一个过程,是对项目的整体框架的搭建。若是之前的编程方式,看着这个题目不会想到去分析输入的表达式会有哪些情况哪些可能,不会想到一个复杂的表达式要怎样分解。前期我用直接编码的方式实现了简单的加减法,后来想要加上乘除法的时候发现代码的结构非常不易变动增加。后来我尝试了搭建框架的形式先分析了架构,将逻辑分析清楚后再编程,发现编程变得很简单,基本是照着图写的傻瓜式编程,不需要复杂的思考就可以写完代码了。
后来在这个架构的基础上又增加赋值的部分后,又发现实现搭好架构再编码,对代码的可扩展也有很大的帮助。
这个实验让我很深刻的体会到有架构的代码和没架构直接编写代码的差别很大,有一个好的架构可以让编写更简单,也可以让编写出来的程序更易扩展,而不是写完这个程序就结束了,想扩展还得全盘推翻。
