
一个完整的大作业-- European Centre for Medium-Range Weather Forecasts
1.选一个自己感兴趣的主题。
欧洲中期天气预报中心 全称(European Centre for Medium-Range Weather Forecasts 简称 ECMWF)
网页网址为https://www.ecmwf.int/
简介
欧洲中期天气预报中心是一个包括24个欧盟成员国的国际性组织,是当今全球独树一帜的国际性天气预报研究和业务机构。其前身为欧洲的一个科学与技术合作项目。 其前身为欧洲的一个科学与技术合作项目。1973年有关国家召开大会宣布ECMWF正式成立,总部设在英国的雷丁。
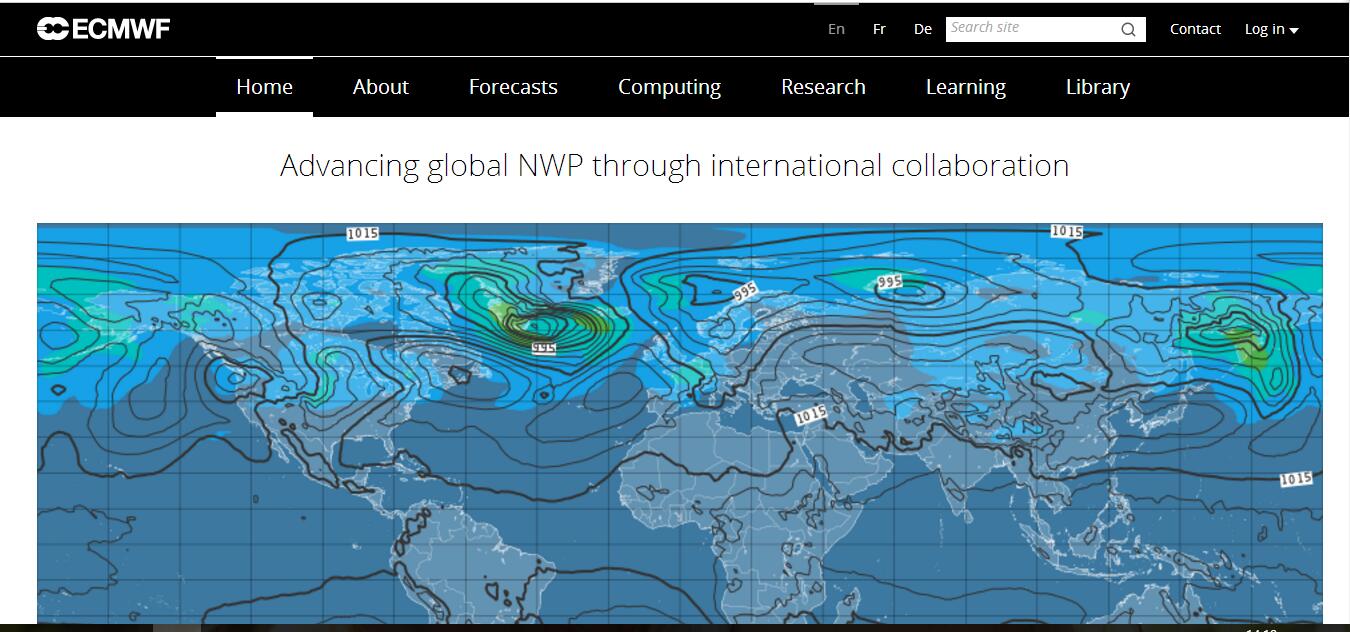
本次所分析的文章是ECMWF对2016年第22号台风海马的预报。
2.网络上爬取相关的数据。
import requests from bs4 import BeautifulSoup from datetime import datetime import re def getTheContent(url1): res = requests.get(url1) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') item = {} item['url'] = url1 # 链接 resd = requests.get(item['url']) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') item['title'] = soupd.select('.content_title')[0].text.strip() # 标题 item['time'] = soupd.select('.content_subtitle')[0].text.strip() # items['dt'] = datetime.strptime(info.lstrip('发布时间:')[6:25], '%Y/%m/%d %H:%M:%S') #时间 #taglist = soupd.find_all('span', attrs={'class': re.compile(".content")}) #con1=soup.find('div',id='content') #item[con2]=con1.span.get_text() item['content'] = soupd.select('.content')[0].text.strip() return (item) #print(getTheContent('https://www.ecmwf.int/en/forecasts/charts')) # 爬取一个列表页面内的所有咨询链接,并将链接返回到getTheContent(url1)中 def getOnePage(pageurl): res = requests.get(pageurl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') lilist = soup.find('div', class_='lilist') # 指定class位置 list = lilist.findAll(name='li') itemls = [] for item in list: if len(item.select('a')[0]['title']) > 0: url= item.select('a')[0]['href'] url1 = re.compile('../../') url2= url1.sub('https://www.ecmwf.int/en/forecasts/charts/', url) itemls.append(getTheContent(url2)) else: print ("错误!") return (itemls) print(getOnePage('https://www.ecmwf.int/en/forecasts/charts/list_2.shtml'))
3.进行文本分析,生成词云。
# 制作词云 def showordcloud(cy): words = jieba.lcut(cy) counts = {} for word in words: # 统计词语出现次数 if len(word) == 1: continue else: counts[word] = counts.get(word, 0) + 1 items = list(counts.items()) items.sort(key=lambda x: x[1], reverse=True) cloudlist = '' for i in range(20): for j in range(items[i][1]): cloudlist += ' ' + items[i][0] cl_split = ''.join(cloudlist) # print(cl_split) mywc = WordCloud(font_path='msyh.ttc').generate(cl_split) plt.imshow(mywc) plt.axis("off") plt.show() #合并所有content文本 def detailwc(totallist): detailall='' for a in range(len(totallist)): detailall += itemtotal[a]['content'] + "\n" detailall=detailall.replace("\n",'') detailall=detailall.replace(" ",'') return(detailall) itemtotal=[] listurl = 'https://www.ecmwf.int/en/forecasts/charts'#首页 itemtotal.extend(getOnePage(listurl)) for i in range(2,10):#第二页至尾页 listurl = 'https://www.ecmwf.int/en/forecasts/charts/list_{}.shtml'.format(i) itemtotal.extend(getOnePage(listurl)) df = pandas.DataFrame(itemtotal) df.to_excel('gzsbk.xlsx') # excel导出 #print(len(itemtotal))#114 showordcloud(detailwc(itemtotal))

4 程序源代码:
import requests from bs4 import BeautifulSoup import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt from datetime import datetime import re import pandas # 爬取单条资讯的信息 def getTheContent(url1): res = requests.get(url1) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') item = {} item['url'] = url1 # 链接 resd = requests.get(item['url']) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') item['title'] = soupd.select('.content_title')[0].text.strip() # 标题 item['time'] = soupd.select('.content_subtitle')[0].text.strip() # items['dt'] = datetime.strptime(info.lstrip('发布时间:')[6:25], '%Y/%m/%d %H:%M:%S') #时间 item['content'] = soupd.select('.content')[0].text.strip() return (item) #print(getTheContent('https://www.ecmwf.int/en/forecasts/charts')) # 爬取一个列表页面内的所有咨询链接,并将链接返回到getTheContent(url1)中 def getOnePage(pageurl): res = requests.get(pageurl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') lilist = soup.find('div', class_='lilist') # 指定class位置 list = lilist.findAll(name='li') itemls = [] for item in list: if len(item.select('a')[0]['title']) > 0: url= item.select('a')[0]['href'] url1 = re.compile('../../') url2= url1.sub('https://www.ecmwf.int/en/forecasts/charts/', url) itemls.append(getTheContent(url2)) else: print ("错误!") return (itemls) #print(getOnePage('https://www.ecmwf.int/en/forecasts/charts')) # 制作词云 def showwordcloud(cy): words = jieba.lcut(cy) counts = {} for word in words: # 统计词语出现次数 if len(word) == 1: continue else: counts[word] = counts.get(word, 0) + 1 items = list(counts.items()) #划分为元组 items.sort(key=lambda x: x[1], reverse=True) cloudlist = '' for i in range(20): for j in range(items[i][1]): cloudlist += ' ' + items[i][0] cl_split = ''.join(cloudlist) # print(cl_split) mywc = WordCloud(font_path='msyh.ttc').generate(cl_split) plt.imshow(mywc) plt.axis("off") plt.show() #合并所有content文本 def dealcontent(totallist): allcontent='' #来个空字符串 for a in range(len(totallist)):#len(itemtotal)=114 allcontent += itemtotal[a]['content'] + "\n" allcontent=allcontent.replace("\n",'') allcontent=allcontent.replace(" ",'') return(allcontent) itemtotal=[] listurl = 'https://www.ecmwf.int/en/forecasts/charts' itemtotal.extend(getOnePage(listurl)) for i in range(2,10):#第二页至尾页 listurl = 'https://www.ecmwf.int/en/forecasts/charts/list_{}.shtml'.format(i) itemtotal.extend(getOnePage(listurl)) df = pandas.DataFrame(itemtotal) df.to_excel('gzsbk.xlsx') # excel导出 #print(len(itemtotal))#114 showwordcloud(dealcontent(itemtotal))
5 根据ECMWF模拟出来的结果以及结合词云进行分析

Typhoon Haima is still to east of Luzon. Forecast tracks have broadly shifted landfall on China coast westwards a little, nearer to Hong Kong. ECMWF - the best computer model for storms - seems to have become settled on landfall over east Hong Kong. Still likely to change, but could be impacts for Hong Kong.
Below are two images, indicating potential landfalls. If well to east of HK; not much to happen here. While if over Sai Kung area, as ECMWF, would be direct hit.
By ECMWF, for 3pm 21 Oct:


可以看出ecmwf认为海马会在正面袭击惠州,给惠州带来严重的风雨影响。

