爬虫实战《抓取案例》之抓取m3u8视频(加密与未加密)(七)
抓取m3u8视频
1、思路分析
视频url:https://www.9meiju.cc/mohuankehuan/shandianxiadibaji/1-1.html
- 打开网址分析当前视频是由多个片段组成还是单独一个视频 如果是一个单独视频,则找到网址,直接下载即可,如果为多个片段的视频,则需要找到片段的文件进行处理,本案例以m3u8为例
- 找到m3u8文件后进行下载,下载后打开文件分析是否需要秘钥,需要秘钥则根据秘钥地址进行秘钥下载,然后下载所有ts文件
- 合并所有视频
2、实现
分析index.m3u8
-
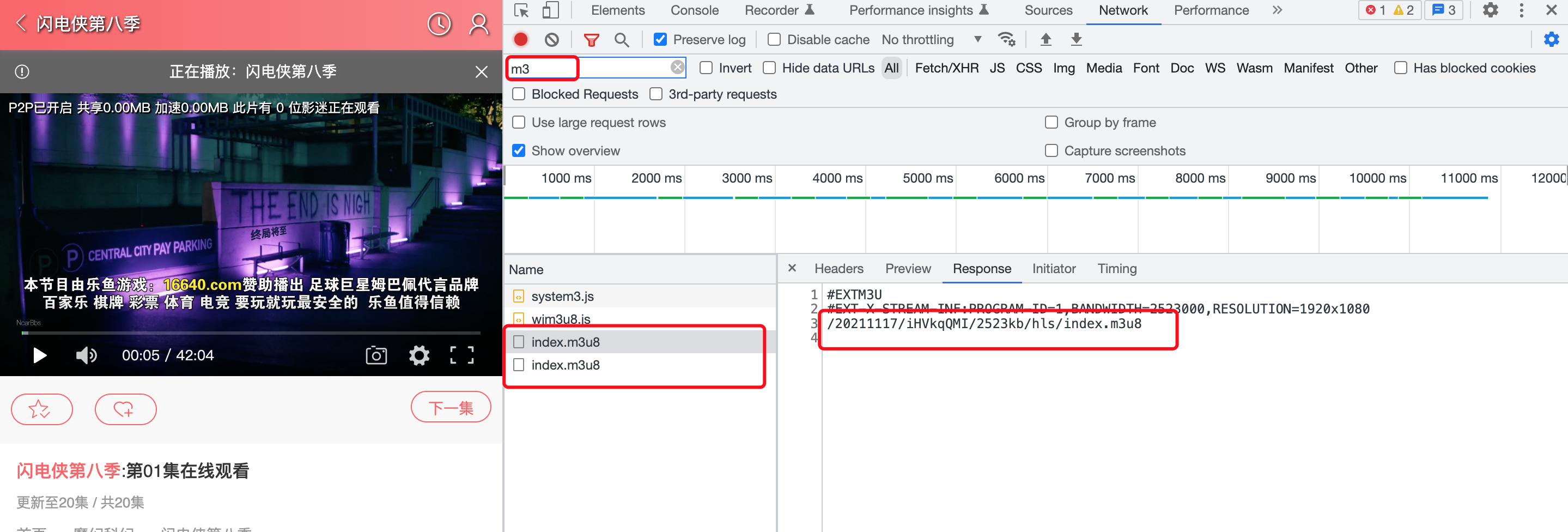
通过网络查找发现有俩个m3u8文件
url分别为
https://new.qqaku.com/20211117/iHVkqQMI/index.m3u8
https://new.qqaku.com/20211117/iHVkqQMI/2523kb/hls/index.m3u8
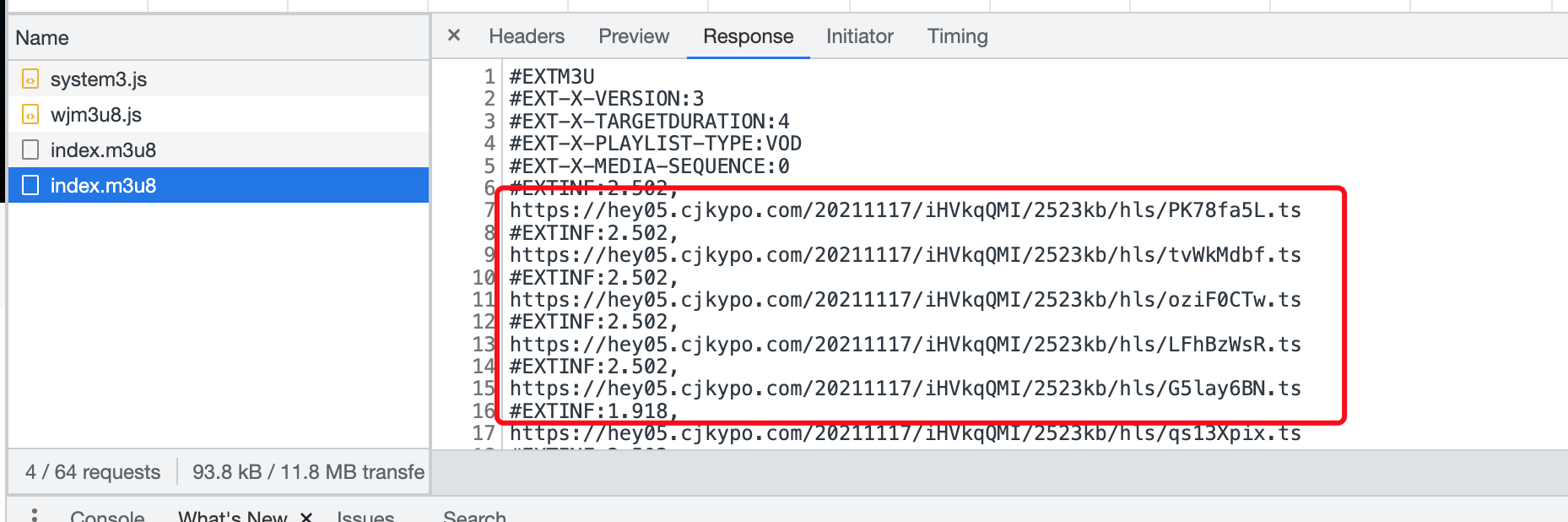
通过分析 第一个index.m3u8请求返回的内容中包含了第二个m3u8请求的url地址
也就是说通过第一个index.m3u8url请求返回包含第二个index.m3u8文件地址,通过拼接请求第二个index.m3u8后 返回了包含当前所有ts文件的地址内容
现在分析出了第二个真正的index.m3u8的地址,但是第一个地址从哪里来的呢,别慌,接下来我们来查找一下第一个url是从哪里来的
-
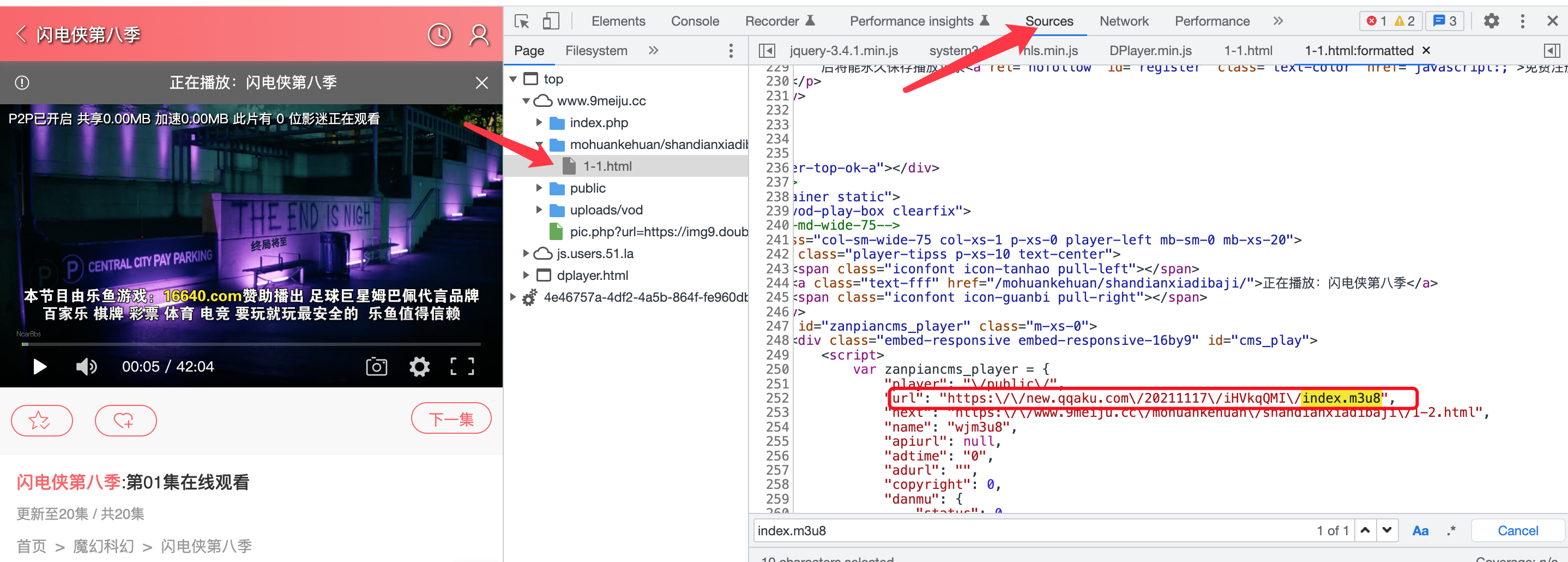
查找第一个index.m3u8的url地址
打开source
发现url存在页面源代码中的js里 知道了位置,在代码中通过正则匹配就可以获取到了
现在我们缕一下思路,通过页面源代码可以找到第一个index.m3u8的url,通过请求返回包含第二个index.m3u8文件的url内容,进行拼接,请求第二个m3u8的url,以此返回所有的ts内容
3、代码实现
3.1 获取最后一个m3u8的url地址
import re
from urllib.parse import urljoin
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
session = requests.Session()
session.get('https://www.9meiju.cc/', headers=headers)
url = 'https://www.9meiju.cc/mohuankehuan/shandianxiadibaji/1-2.html'
response = session.get(url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
# print(data)
'''
<script>
var zanpiancms_player = {"player":"\/public\/","url":"https:\/\/new.qqaku.com\/20211124\/nLwncbZW\/index.m3u8","next":"https:\/\/www.9meiju.cc\/mohuankehuan\/shandianxiadibaji\/1-3.html","name":"wjm3u8","apiurl":null,"adtime":"0","adurl":"","copyright":0,"danmu":{"status":0}};
</script>
'''
# 正则抓取上面的源代码中的m3u8的url
m3u8_uri = re.search('"url":"(.+?index.m3u8)"', data).group(1).replace('\\', '')
# 写入文件 分析当前的页面源代码
with open('99.html', 'wb') as f:
# 写入response.content bytes二进制类型
f.write(response.content)
# 请求可以获取index.m3u8文件
response = session.get(m3u8_uri, headers=headers)
with open('m3u8_uri.text', 'wb') as f:
# 写入response.content bytes二进制类型
f.write(response.content)
response.encoding = 'UTF-8'
data = response.text
# 拆分返回的内容获取真整的index.m3u8文件的url
url = data.split('/', 3)[-1]
print(data)
print('m3u8_uri', m3u8_uri)
print('url', url)
print(urljoin(m3u8_uri, url))
3.2 多线程下载ts文件与视频合并
import time
import requests
import os
from concurrent.futures import ThreadPoolExecutor, wait
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36"
}
def down_video(url, i):
'''
下载ts文件
:param url:
:param i:
:return:
'''
# print(url)
# 下载ts文件
resp = requests.get(url, headers=headers)
with open(os.path.join(path, str(i)+'.ts'), mode="wb") as f3:
f3.write(resp.content)
# print('{} 下载完成!'.format(url))
def download_all_videos(url, path):
'''
下载m3u8文件以及多线程下载ts文件
:param url:
:param path:
:return:
'''
# 请求m3u8文件进行下载
resp = requests.get(url, headers=headers)
with open("first.m3u8", mode="w", encoding="utf-8") as f:
f.write(resp.text)
if not os.path.exists(path):
os.mkdir(path)
# 开启线程 准备下载
pool = ThreadPoolExecutor(max_workers=50)
# 1. 读取文件
tasks = []
i = 0
with open("first.m3u8", mode="r", encoding="utf-8") as f:
for line in f:
# 如果不是url 则走下次循环
if line.startswith("#"):
continue
print(line, i)
# 开启线程
tasks.append(pool.submit(down_video, line.strip(), i))
i += 1
print(i)
# 统一等待
wait(tasks)
# 处理m3u8文件中的url问题
def do_m3u8_url(path, m3u8_filename="index.m3u8"):
# 这里还没处理key的问题
if not os.path.exists(path):
os.mkdir(path)
# else:
# shutil.rmtree(path)
# os.mkdir(path)
with open(m3u8_filename, mode="r", encoding="utf-8") as f:
data = f.readlines()
fw = open(os.path.join(path, m3u8_filename), 'w', encoding="utf-8")
abs_path = os.getcwd()
i = 0
for line in data:
# 如果不是url 则走下次循环
if line.startswith("#"):
# 判断处理是存在需要秘钥
fw.write(line)
else:
fw.write(f'{abs_path}/{path}/{i}.ts\n')
i += 1
def merge(filePath, filename='output'):
'''
进行ts文件合并 解决视频音频不同步的问题 建议使用这种
:param filePath:
:return:
'''
os.chdir(path)
cmd = f'ffmpeg -i index.m3u8 -c copy {filename}.mp4'
os.system(cmd)
if __name__ == '__main__':
# 抓取99美剧闪电侠
# ts文件存储目录
path = 'ts'
url = 'https://new.qqaku.com/20211124/nLwncbZW/1100kb/hls/index.m3u8'
# 下载m3u8文件以及ts文件
download_all_videos(url, path)
do_m3u8_url(path)
# 文件合并
merge(path, 'ts2')
print('over')
注意:当前视频合并所用的工具为ffmpeg 如需安装 查看我的另外一篇博客ffmpeg的使用
3.3 合并获取上面俩个代码段的代码
import re
from urllib.parse import urljoin
import requests
import os # 执行cmd/控制台上的命令
from concurrent.futures import ThreadPoolExecutor, wait
from retrying import retry
def get_m3u8_url(url):
'''
获取页面中m3u8的url
:param url: 电影页面的url
:return:
'''
session = requests.Session()
# 访问首页获取cookie
session.get('https://www.9meiju.cc/', headers=headers)
# url = 'https://www.9meiju.cc/mohuankehuan/shandianxiadibaji/1-2.html'
response = session.get(url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
# print(data)
m3u8_uri = re.search('"url":"(.+?index.m3u8)"', data).group(1).replace('\\', '')
# 写入文件 分析当前的页面源代码
# with open('99.html', 'w', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
# f.write(response.content.decode('UTF-8'))
# 请求可以获取index.m3u8文件
response = session.get(m3u8_uri, headers=headers)
# with open('m3u8_uri.text', 'w', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
# f.write(response.content.decode('UTF-8'))
response.encoding = 'UTF-8'
data = response.text
# 拆分返回的内容获取真整的index.m3u8文件的url
# 注意 一定要strip
url = data.split('/', 3)[-1].strip()
print(data)
print('m3u8_uri', m3u8_uri)
url = urljoin(m3u8_uri, url)
print('url', url)
return url
@retry(stop_max_attempt_number=3)
def down_video(url, i):
'''
下载ts文件
:param url:
:param i:
:return:
'''
# print(url)
# 下载ts文件
# try:
resp = requests.get(url, headers=headers)
with open(os.path.join(path, str(i)+'.ts'), mode="wb") as f3:
f3.write(resp.content)
assert resp.status_code == 200
def download_all_videos(url, path):
'''
下载m3u8文件以及多线程下载ts文件
:param url:
:param path:
:return:
'''
# 请求m3u8文件进行下载
resp = requests.get(url, headers=headers)
with open("index.m3u8", mode="w", encoding="utf-8") as f:
f.write(resp.content.decode('UTF-8'))
if not os.path.exists(path):
os.mkdir(path)
# 开启线程 准备下载
pool = ThreadPoolExecutor(max_workers=50)
# 1. 读取文件
tasks = []
i = 0
with open("index.m3u8", mode="r", encoding="utf-8") as f:
for line in f:
# 如果不是url 则走下次循环
if line.startswith("#"):
continue
print(line, i)
# 开启线程
tasks.append(pool.submit(down_video, line.strip(), i))
i += 1
print(i)
# 统一等待
wait(tasks)
# 如果阻塞可以给一个超时参数
# wait(tasks, timeout=1800)
def do_m3u8_url(path, m3u8_filename="index.m3u8"):
# 这里还没处理key的问题
if not os.path.exists(path):
os.mkdir(path)
# else:
# shutil.rmtree(path)
# os.mkdir(path)
with open(m3u8_filename, mode="r", encoding="utf-8") as f:
data = f.readlines()
fw = open(os.path.join(path, m3u8_filename), 'w', encoding="utf-8")
abs_path = os.getcwd()
i = 0
for line in data:
# 如果不是url 则走下次循环
if line.startswith("#"):
fw.write(line)
else:
fw.write(f'{abs_path}/{path}/{i}.ts\n')
i += 1
def merge(path, filename='output'):
'''
进行ts文件合并 解决视频音频不同步的问题 建议使用这种
:param filePath:
:return:
'''
os.chdir(path)
cmd = f'ffmpeg -i index.m3u8 -c copy {filename}.mp4'
os.system(cmd)
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 电影的url 返回index.m3u8的url地址
url = get_m3u8_url('https://www.9meiju.cc/mohuankehuan/shandianxiadibaji/1-2.html')
# ts文件存储目录
path = 'ts'
# 下载m3u8文件以及ts文件
download_all_videos(url, path)
do_m3u8_url(path)
# 文件合并
merge(path, '第二集')
print('over')
4、注意事项
4.1 说明
在获取index.m3u8文件的内容时,有的文件内容会显示...jpg/png的情况,并没显示...ts,那么遇到这种情况需要单独处理 内容如下:
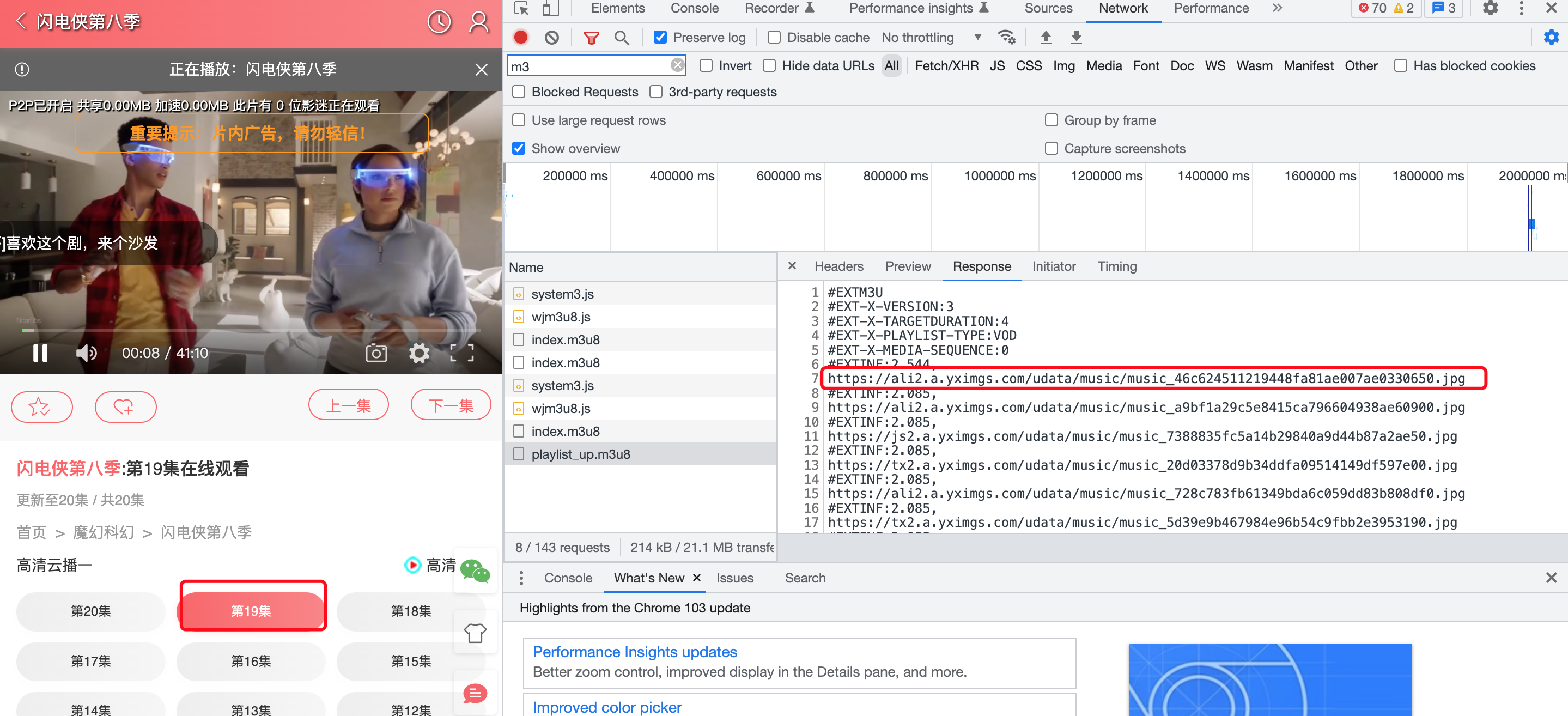
这种情况使用上面的代码就无法进行正常合并,合并后的视频无法播放
但使用ffprobe分析,发现识别为png,进而导致无法正常拼接
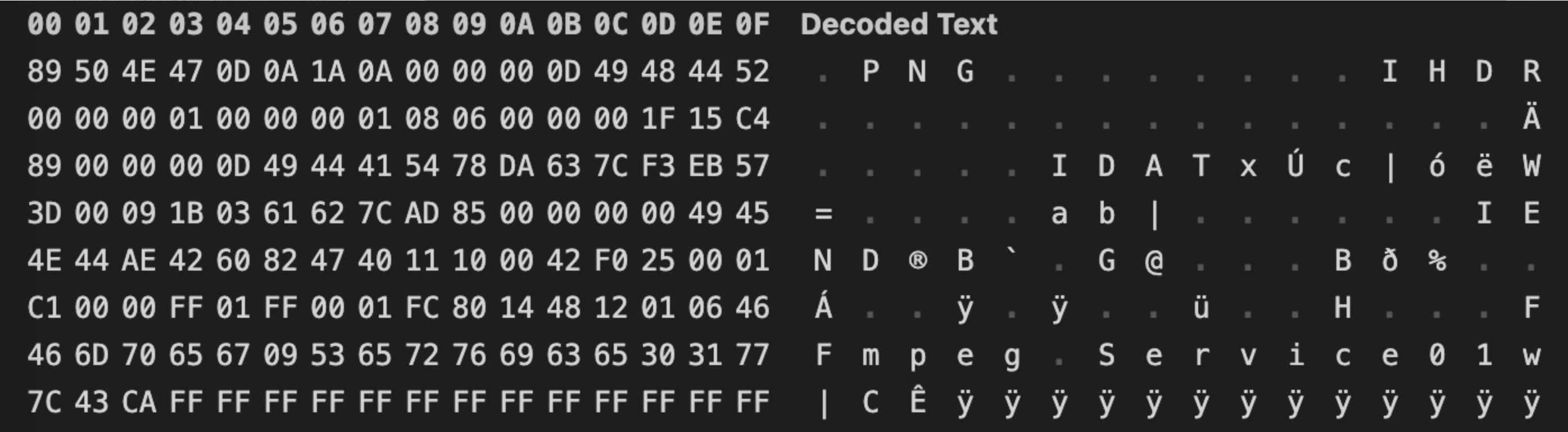
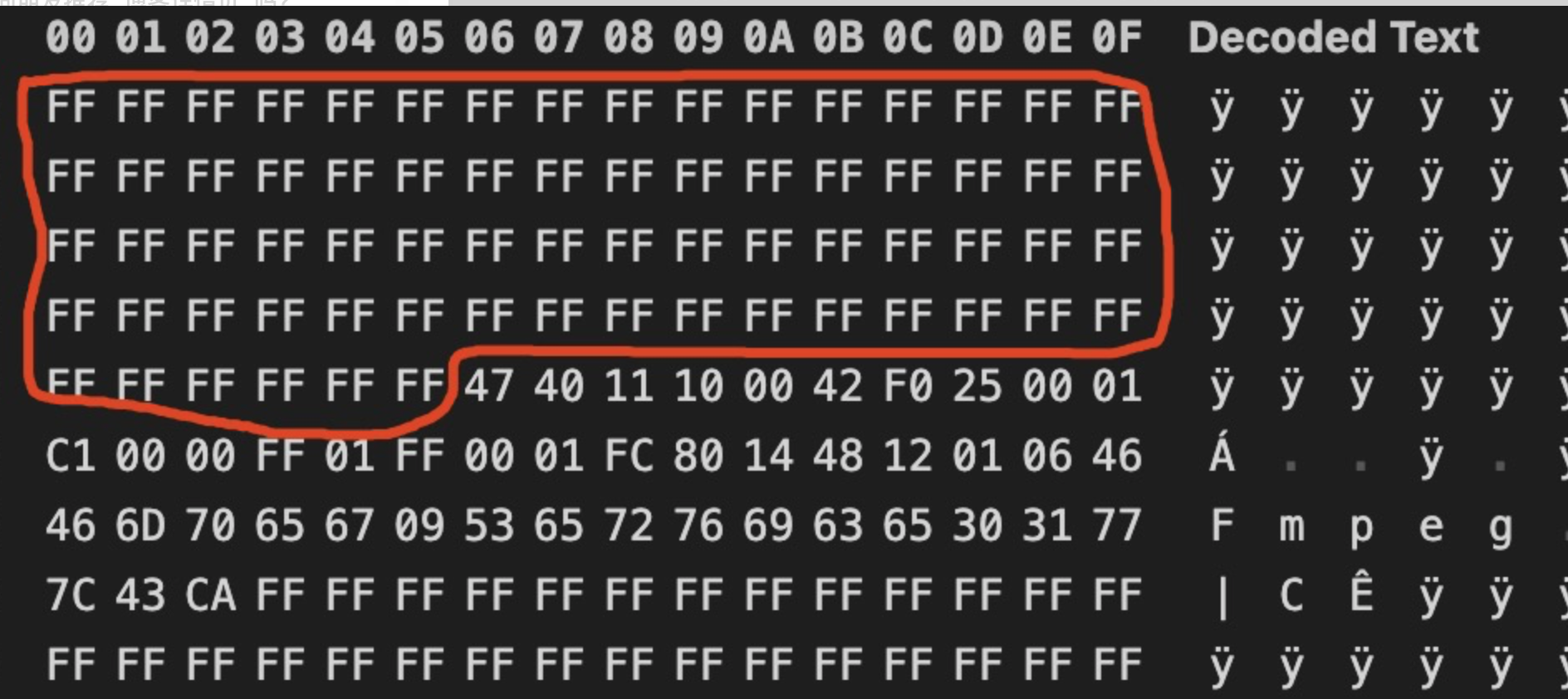
在这种情况下,只需要将其中PNG文件头部分全部使用FF填充,即可处理该问题
填充后的效果如图
4.2 使用代码进行处理
# 解析伪装成png的ts
def resolve_ts(src_path, dst_path):
'''
如果m3u8返回的ts文件地址为
https://p1.eckwai.com/ufile/adsocial/7ead0935-dd4f-4d2f-b17d-dd9902f8cc77.png
则需要下面处理后 才能进行合并
原因在于 使用Hexeditor打开后,发现文件头被描述为了PNG
在这种情况下,只需要将其中PNG文件头部分全部使用FF填充,即可处理该问题
:return:
'''
if not os.path.exists(dst_path):
os.mkdir(dst_path)
file_list = sorted(os.listdir(src_path), key=lambda x: int(x.split('.')[0]))
for i in file_list:
origin_ts = os.path.join(src_path, i)
resolved_ts = os.path.join(dst_path, i)
try:
infile = open(origin_ts, "rb") # 打开文件
outfile = open(resolved_ts, "wb") # 内容输出
data = infile.read()
outfile.write(data)
outfile.seek(0x00)
outfile.write(b'\xff\xff\xff\xff')
outfile.flush()
infile.close() # 文件关闭
outfile.close()
except:
pass
print('resolve ' + origin_ts + ' success')
4.3 完整代码
import shutil
import time
from urllib.parse import urljoin
import requests
import os
import re
from concurrent.futures import ThreadPoolExecutor, wait
def get_m3u8_url(url):
'''
获取页面中m3u8的url
:param url: 电影页面的url
:return:
'''
session = requests.Session()
# 访问首页获取cookie
session.get('https://www.9meiju.cc/', headers=headers)
# url = 'https://www.9meiju.cc/mohuankehuan/shandianxiadibaji/1-2.html'
response = session.get(url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
# print(data)
m3u8_uri = re.search('"url":"(.+?index.m3u8)"', data).group(1).replace('\\', '')
# 请求可以获取index.m3u8文件
response = session.get(m3u8_uri, headers=headers)
response.encoding = 'UTF-8'
data = response.text
# 拆分返回的内容获取真整的index.m3u8文件的url
# 注意 一定要strip
url = data.split('/', 3)[-1].strip()
print(data)
print('m3u8_uri', m3u8_uri)
url = urljoin(m3u8_uri, url)
print('url', url)
return url
def down_video(url, i):
'''
下载ts文件
:param url:
:param i:
:return:
'''
# print(url)
# 下载ts文件
resp = requests.get(url, headers=headers)
with open(os.path.join(path, str(i)+'.ts'), mode="wb") as f3:
f3.write(resp.content)
# print('{} 下载完成!'.format(url))
def download_all_videos(url, path):
'''
下载m3u8文件以及多线程下载ts文件
:param url:
:param path:
:return:
'''
# 请求m3u8文件进行下载
resp = requests.get(url, headers=headers)
with open("index.m3u8", mode="w", encoding="utf-8") as f:
f.write(resp.content.decode('UTF-8'))
if not os.path.exists(path):
os.mkdir(path)
# 开启线程 准备下载
pool = ThreadPoolExecutor(max_workers=50)
# 1. 读取文件
tasks = []
i = 0
with open("index.m3u8", mode="r", encoding="utf-8") as f:
for line in f:
# 如果不是url 则走下次循环
if line.startswith("#"):
continue
print(line, i)
# 开启线程
tasks.append(pool.submit(down_video, line.strip(), i))
i += 1
print(i)
# 统一等待
wait(tasks)
# 解析伪装成png的ts
def resolve_ts(src_path, dst_path):
'''
如果m3u8返回的ts文件地址为
https://p1.eckwai.com/ufile/adsocial/7ead0935-dd4f-4d2f-b17d-dd9902f8cc77.png
则需要下面处理后 才能进行合并
原因在于 使用Hexeditor打开后,发现文件头被描述为了PNG
在这种情况下,只需要将其中PNG文件头部分全部使用FF填充,即可处理该问题
:return:
'''
if not os.path.exists(dst_path):
os.mkdir(dst_path)
file_list = sorted(os.listdir(src_path), key=lambda x: int(x.split('.')[0]))
for i in file_list:
origin_ts = os.path.join(src_path, i)
resolved_ts = os.path.join(dst_path, i)
try:
infile = open(origin_ts, "rb") # 打开文件
outfile = open(resolved_ts, "wb") # 内容输出
data = infile.read()
outfile.write(data)
outfile.seek(0x00)
outfile.write(b'\xff\xff\xff\xff')
outfile.flush()
infile.close() # 文件关闭
outfile.close()
except:
pass
"""
else:
# 删除目录
shutil.rmtree(src_path)
# 将副本重命名为正式文件
os.rename(dst_path, dst_path.rstrip('2'))
"""
print('resolve ' + origin_ts + ' success')
# 处理m3u8文件中的url问题
def do_m3u8_url(path, m3u8_filename="index.m3u8"):
# 这里还没处理key的问题
if not os.path.exists(path):
os.mkdir(path)
with open(m3u8_filename, mode="r", encoding="utf-8") as f:
data = f.readlines()
fw = open(os.path.join(path, m3u8_filename), 'w', encoding="utf-8")
abs_path = os.getcwd()
i = 0
for line in data:
# 如果不是url 则走下次循环
if line.startswith("#"):
fw.write(line)
else:
fw.write(f'{abs_path}/{path}/{i}.ts\n')
i += 1
def merge(path, filename='output'):
'''
进行ts文件合并 解决视频音频不同步的问题 建议使用这种
:param filePath:
:return:
'''
os.chdir(path)
cmd = f'ffmpeg -i index.m3u8 -c copy {filename}.mp4'
os.system(cmd)
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36"
}
url = get_m3u8_url('https://www.9meiju.cc/mohuankehuan/shandianxiadibaji/1-20.html')
# 抓取99美剧闪电侠
# ts文件存储目录
path = 'ts'
# 下载m3u8文件以及ts文件
download_all_videos(url, path)
# 合并png的ts文件
src_path = path
dst_path = path+'2'
resolve_ts(src_path, dst_path)
do_m3u8_url(dst_path)
merge(dst_path, '闪电侠')
print('over')
5、解密处理
-
上面我们讲的是没有经过加密的 ts 文件,这些文件下载后直接可以播放,但经过AES-128加密后的文件下载后会无法播放,所以还需要进行解密。
-
如何判断是否需要加密?观察视频网站是否有m3u8的文件传输,下载下来并打开:
无需解密index.m3u8文件
#EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:4 #EXT-X-PLAYLIST-TYPE:VOD #EXT-X-MEDIA-SEQUENCE:0 #EXTINF:3.086, https://hey05.cjkypo.com/20211215/FMbNtNzz/1100kb/hls/7qs6gJc0.ts #EXTINF:2.085, https://hey05.cjkypo.com/20211215/FMbNtNzz/1100kb/hls/rYpHhq0I.ts #EXTINF:2.085, https://hey05.cjkypo.com/20211215/FMbNtNzz/1100kb/hls/bfays5sw.ts需要解密index.m3u8文件
#EXT-X-VERSION:3 #EXT-X-TARGETDURATION:1 #EXT-X-PLAYLIST-TYPE:VOD #EXT-X-MEDIA-SEQUENCE:0 #EXT-X-KEY:METHOD=AES-128,URI="/20220418/671fJxOB/2000kb/hls/key.key" # 当前路径为解密秘钥的位置 需要使用代码拼凑成完整路径 进行请求 域名+/20220418/671fJxOB/2000kb/hls/key.key #EXTINF:1.235, /20220418/671fJxOB/2000kb/hls/kj6uqHoP.ts # 并且这里ts的url也要拼凑完整 #EXTINF:1.001, /20220418/671fJxOB/2000kb/hls/ZXX8LYPa.ts #EXTINF:1.001, /20220418/671fJxOB/2000kb/hls/sOezpD2H.ts #EXTINF:1.001, ... -
如果你的文件是加密的,那么你还需要一个key文件,Key文件下载的方法和m3u8文件类似,如下所示 key.key 就是我们需要下载的 key 文件,并注意这里 m3u8 有2个,需要使用的是像上面一样存在 ts 文件超链接的 m3u8 文件
-
下载所有 ts 文件,将下载好的所有的 ts 文件、m3u8、key.key 放到一个文件夹中,将 m3u8 文件改名为 index.m3u8,将 key.key 改名为 key.m3u8 。更改 index.m3u8 里的 URL,变为你本地路径的 key 文件,将所有 ts 也改为你本地的路径
文件路径
project/
ts/
0.ts
1.ts
...
index.m3u8
key.m3u8
修改后的index.m3u8内容如下所示:
#EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:1 #EXT-X-PLAYLIST-TYPE:VOD #EXT-X-MEDIA-SEQUENCE:0 #EXT-X-KEY:METHOD=AES-128,URI="/Users/xialigang/PycharmProjects/爬虫/抓取带秘钥的电影/ts/key.m3u8" #EXTINF:1.235, /Users/xialigang/PycharmProjects/爬虫/抓取带秘钥的电影/ts/0.ts #EXTINF:1.001, /Users/xialigang/PycharmProjects/爬虫/抓取带秘钥的电影/ts/1.ts #EXTINF:1.001, /Users/xialigang/PycharmProjects/爬虫/抓取带秘钥的电影/ts/2.ts处理index.m3u8内容的代码如下所示
import time from urllib.parse import urljoin import requests import os from concurrent.futures import ThreadPoolExecutor, wait import re headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36" } def down_video(url, i): ''' 下载ts文件 :param url: :param i: :return: ''' # print(url) # 下载ts文件 resp = requests.get(url, headers=headers) with open(os.path.join(path, str(i) + '.ts'), mode="wb") as f3: f3.write(resp.content) # print('{} 下载完成!'.format(url)) def download_all_videos(path, host): ''' 下载m3u8文件以及多线程下载ts文件 :param url: :param path: :return: ''' if not os.path.exists(path): os.mkdir(path) # 开启线程 准备下载 pool = ThreadPoolExecutor(max_workers=50) # 1. 读取文件 tasks = [] i = 0 with open("index.m3u8", mode="r", encoding="utf-8") as f: for line in f: # 如果不是url 则走下次循环 if line.startswith("#"): continue line = host + line print(line, i) # 开启线程 tasks.append(pool.submit(down_video, line.strip(), i)) i += 1 # 统一等待 wait(tasks) # 处理m3u8文件中的url问题 def do_m3u8_url(url, path, m3u8_filename="index.m3u8"): # 这里还没处理key的问题 if not os.path.exists(path): os.mkdir(path) with open(m3u8_filename, mode="r", encoding="utf-8") as f: data = f.readlines() fw = open(os.path.join(path, m3u8_filename), 'w') abs_path = os.getcwd() i = 0 for line in data: # 如果不是url 则走下次循环 if line.startswith("#"): # 判断处理是存在需要秘钥 if line.find('URI') != -1: line = re.sub('(#EXT-X-KEY:METHOD=AES-128,URI=")(.*?)"', f'\\1{os.path.join(abs_path, path)}/key.m3u8"', line) host = url.rsplit('/', 1)[0] # 爬取key download_m3u8(host + '/key.key', os.path.join(path, 'key.m3u8')) fw.write(line) else: fw.write(f'{abs_path}/{path}/{i}.ts\n') i += 1 def download_m3u8(url, m3u8_filename="index.m3u8", state=0): print('正在下载index.m3u8文件') resp = requests.get(url, headers=headers) with open(m3u8_filename, mode="w", encoding="utf-8") as f: f.write(resp.text) def merge(filePath, filename='output'): ''' 进行ts文件合并 解决视频音频不同步的问题 建议使用这种 :param filePath: :return: ''' os.chdir(path) cmd = f'ffmpeg -i index.m3u8 -c copy {filename}.mp4' os.system(cmd) def get_m3u8_data(first_m3u8_url): session = requests.Session() # 请求第一次m3u8de url resp = session.get(first_m3u8_url, headers=headers) resp.encoding = 'UTF-8' data = resp.text # 第二次请求m3u8文件地址 返回最终包含所有ts文件的m3u8 second_m3u8_url = urljoin(first_m3u8_url, data.split('/', 3)[-1].strip()) resp = session.get(second_m3u8_url, headers=headers) with open('index.m3u8', 'wb') as f: f.write(resp.content) return second_m3u8_url if __name__ == '__main__': # ts文件存储目录 path = 'ts' # 带加密的ts文件的 index.m3u8 url url = 'https://s7.fsvod1.com/20220622/5LnZiDXn/index.m3u8' meu8_url = get_m3u8_data(url) # 下载m3u8文件以及ts文件 host = 'https://s7.fsvod1.com' # 主机地址 用于拼凑完整的ts路径和秘钥路径 download_all_videos(path, host) do_m3u8_url(meu8_url, path) # 文件合并 merge(path, '奇异博士') print('over') -
然后用ffmpeg进行合并:
ffmpeg -i index.m3u8 -c copy out.mp4
代码合并
os.chdir("./ts") os.system('ffmpeg -i index.m3u8 -c copy out.mp4') -
这样就大功告成了!我们成功解密并使用 ffmpeg 合并了这些 ts 视频片段,实际应用场景可能和这不一样,具体网站具体分析

