关于2020年新型冠状病毒肺炎的数据分析
一、选题背景
理由
在2020年2月11日,世界卫生组织总干事谭德塞在瑞士日内瓦宣布,将新型冠状病毒感染的肺炎命名为“COVID-19”22日,国家卫生健康委发布通知,“新型冠状病毒肺炎”英文名称修订为“COVID-19” 。3月11日,世卫组织认为当前新冠肺炎疫情可被称为全球大流行 。4月4日,中国举行全国性哀悼活动,COVID-19对环境、社会和治理等方面的影响在一段时间内将持续存在。1、了解COVID-19有利于个人对COVID-19的预防,及时就医,及时做好自测,2、数据的分析在生活里更容易遇到,提高相关处理能力有利于日常数据处理,3、机器学习是基于大数据的发展,选择大数据的课题,有利于理解机器学习的原理,4、较好的分析数据的能力有利于理解事物的发展规律,有利于顺应事物的发展处理问题
数据分析的预期目标
1,了解COVID-19的相关情况,感染人群特点
2,创建一个简易的预测模型,帮助预测易感染人群,做好防治,及时就医
数据来源等方面进行描述
数据来源爱数科,本文数据地址http://idatascience.cn/dataset-detail?table_id=120
二、大数据分析设计方案
1.本数据集的数据内容与数据特征分析
数据内容
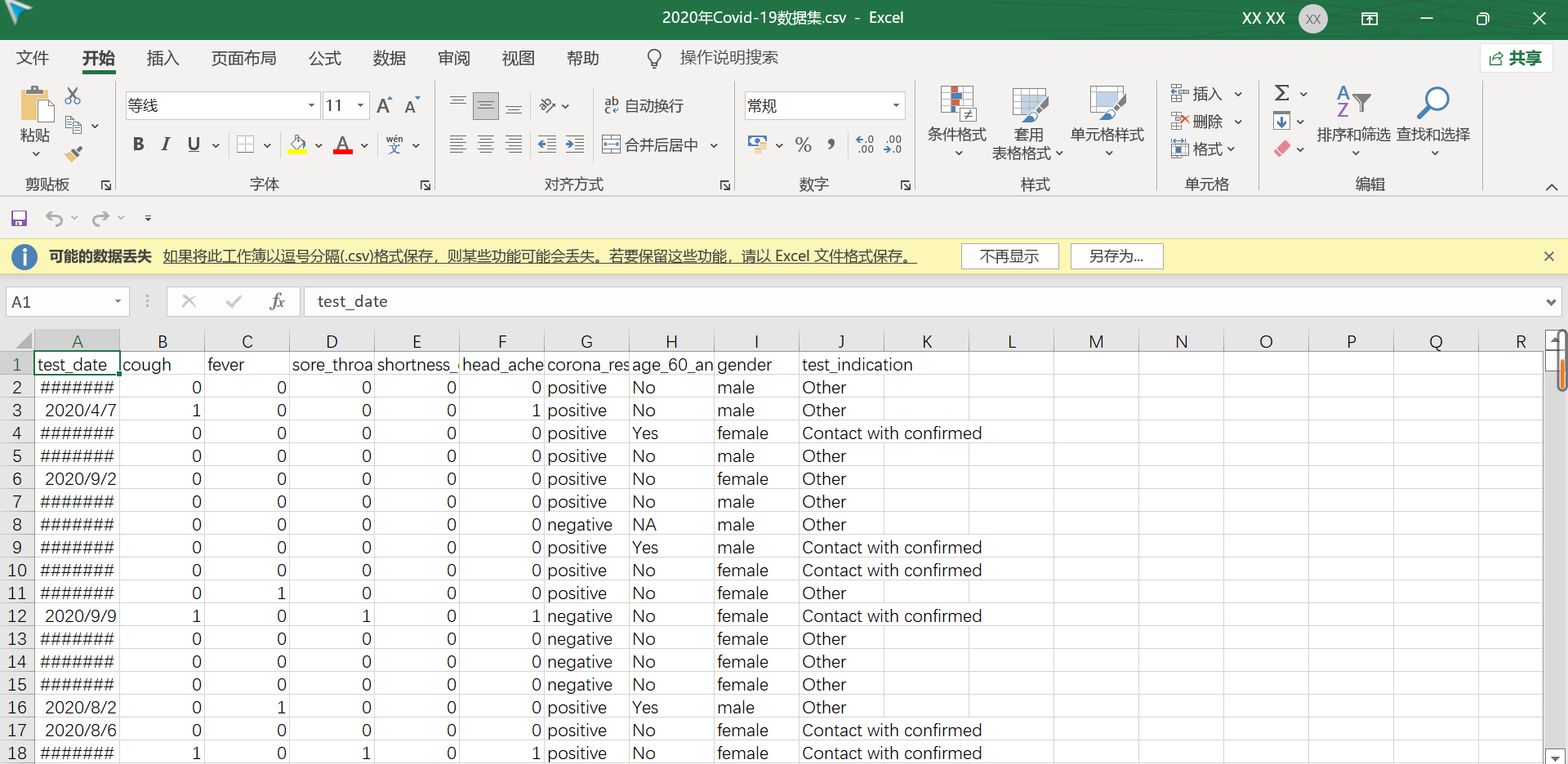
数据共有10个属性的说明
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| test_date | 字符型 | 测试日期。 |
| cough | 整型 | 咳嗽。 |
| fever | 整型 | 发热。 |
| sore_throat | 整型 | 咽喉痛。 |
| shortness_of_breath | 整型 | 气促。 |
| head_ache | 整型 | 头痛。 |
| corona_result | 字符型 | 测试结果。 |
| age_60_and_above | 字符型 | 是否为60岁以上。 |
| gender | 字符型 | 性别。 |
| test_indication | 字符型 | 测试适应症。 |
2.数据分析的课程设计方案概述(包括实现思路与技术难点)
1,数据40万数据本身较大,占用存储极大,利用第三方库pandas和 numpy处理问题
2,数据展示可以利用matplotlib和 seaborn
3,实现预测数据sklearn,最大难点就是提高正确率
三、数据分析步骤
展示数据
1 #数据提取
2 import pandas as pd
3 csv_file="F://2020年Covid-19数据集.csv"
4 csv_data=pd.read_csv(csv_file)
5 # print(csv_data)
6 print(len(csv_data))
7 print(type(csv_data))
8 csv_data_1=csv_data
#数据初步展示
9 csv_data.head() 调整格式
调整格式
1 csv_data_1=csv_data.rename(columns={ 2 'test_date':'测试日期', 3 'cough':'咳嗽', 4 'fever':'发热', 5 'sore_throat':'咽喉痛', 6 'shortness_of_breath':'气促', 7 'head_ache':'头痛', 8 'corona_result':'测试结果', 9 'age_60_and_above':'高60岁?', 10 'gender':'性别', 11 'test_indication':'测试适应症'}) 12 csv_data_1.head()
1 # 查看缺少值 2 print(csv_data_1.info()) 3 print("---------------------------------具体情况-----------------------------") 4 print(csv_data_1.isnull().sum()) 5 print('"性别" 缺失的百分比 %.2f%%' %((csv_data_1['性别'].isnull().sum()/csv_data.shape[0])*100)) 6 print('"高60岁?" 缺失的百分比 %.2f%%' %((csv_data_1['高60岁?'].isnull().sum()/csv_data.shape[0])*100))

1 # 对数据有一个明晰的情况了解,特别重要 2 #数据展示 3 for i in csv_data_1.columns: 4 print(csv_data_1[i].value_counts())
2020-09-24 7277
2020-09-23 7169
2020-09-22 7058
2020-09-29 6970
2020-09-30 6914
...
2020-03-14 88
2020-03-11 76
2020-05-09 68
2020-05-16 42
2020-05-23 35
Name: 测试日期, Length: 247, dtype: int64
0 352571
1 47429
Name: 咳嗽, dtype: int64
0 346254
1 53746
Name: 发热, dtype: int64
0 378864
1 21136
Name: 咽喉痛, dtype: int64
0 392284
1 7716
Name: 气促, dtype: int64
0 357162
1 42838
Name: 头痛, dtype: int64
positive 220975
negative 179025
Name: 测试结果, dtype: int64
No 305847
Yes 44241
Name: 高60岁?, dtype: int64
male 196421
female 195827
Name: 性别, dtype: int64
Other 293180
Contact with confirmed 103218
Abroad 3602
Name: 测试适应症, dtype: int64
1 # 数据归一化处理 2 #检测的值 positive,Yes,male,Contact with confirmed标记为1 3 #检测的值 negative,No,female,Other标记为0 4 # Abroad标记为2 5 csv_data_1=csv_data_1.replace("positive",'1').replace("negative",'0') 6 csv_data_1=csv_data_1.replace("male",'1').replace("female",'0').replace("No",'0').replace("Yes",'1') 7 csv_data_1=csv_data_1.replace("Contact with confirmed",'1').replace("Other",'0').replace("Abroad",'2') 8 print(csv_data_1)

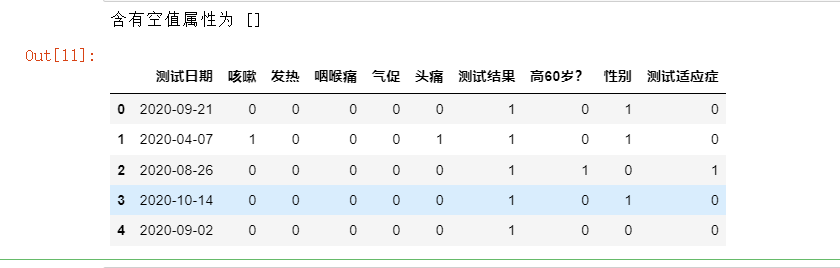
1 #统计有空值的所有属性 2 #空值本身会影响数据 3 #把相关属性放到一个列表里 4 def null_count(csv_data_1): 5 lis_nul=[] 6 for i in csv_data_1.columns: 7 if csv_data_1[i].isnull().value_counts()[False]!=len(csv_data_1): 8 print('属性是:',i,"相关空值是:") 9 print(csv_data_1[i].isnull().value_counts()) 10 lis_nul.append(i) 11 print() 12 print('含有空值属性为',lis_nul) 13 null_count(csv_data_1)

1 # 空值填充为5 2 csv_data_1=csv_data_1.fillna('5') 3 null_count(csv_data_1) 4 csv_data_1.head()
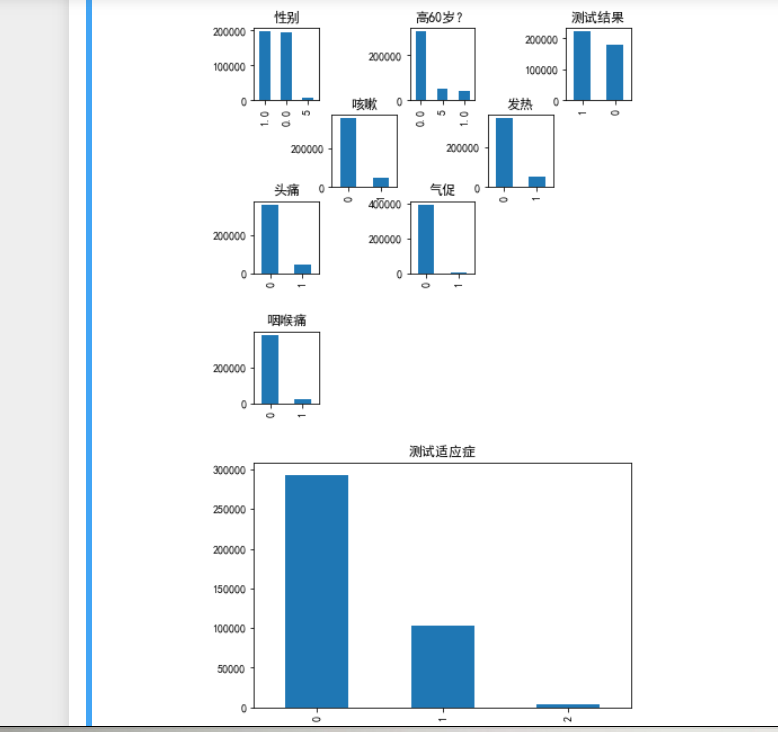
1 # 样本各属性的数据分布情况直观展示 2 import matplotlib.pyplot as plt 3 import matplotlib as mpl 4 #中文设置 5 mpl.rcParams["font.sans-serif"] = ["SimHei"] 6 mpl.rcParams["axes.unicode_minus"] = False 7 #数据取值 8 axesl=plt.subplot(3,5,1) 9 csv_data_1['性别'].value_counts().plot(kind='bar',title='性别') 10 axes2=plt.subplot(3,5,3) 11 csv_data_1['高60岁?'].value_counts().plot(kind='bar',title='高60岁?') 12 axes3=plt.subplot(3,5,5) 13 csv_data_1['测试结果'].value_counts().plot(kind='bar',title='测试结果') 14 axes4=plt.subplot(3,5,7) 15 csv_data_1['咳嗽'].value_counts().plot(kind='bar',title='咳嗽') 16 axes4=plt.subplot(3,5,9) 17 csv_data_1['发热'].value_counts().plot(kind='bar',title='发热') 18 axes4=plt.subplot(3,5,11) 19 csv_data_1['头痛'].value_counts().plot(kind='bar',title='头痛') 20 axes4=plt.subplot(3,5,13) 21 csv_data_1['气促'].value_counts().plot(kind='bar',title='气促') 22 plt.show() 23 axes4=plt.subplot(3,5,15) 24 csv_data_1['咽喉痛'].value_counts().plot(kind='bar',title='咽喉痛') 25 plt.show() 26 csv_data_1['测试适应症'].value_counts().plot(kind='bar',title='测试适应症') 27 plt.show() 28 #可以初步可视化了解数据情况 29 # 样本里性别比列较为均衡 30 # 新冠测试结果相差不大 31 # 数据集合较为可信
1 #绘制组合柱状图(提取取值数据)上 2 # 更直观展现数据情况 3 4 #删掉无效行时间行 5 csv_data_11=csv_data_1.drop('测试日期',axis=1) 6 7 x_label=(list(csv_data_11)) 8 #建构字典处理数据 9 lis=[] 10 a=[] 11 for i in csv_data_11: 12 lis.append(dict(zip(list(csv_data_1[i].value_counts().index),csv_data_1[i].value_counts().values))) 13 print("数据值保存为字典的列表") 14 print(lis) 15 #转字典 16 result_dict=dict(zip(x_label,lis)) 17 print(result_dict)

1 #绘制组合柱状图(绘出图片)下 2 import matplotlib.pyplot as plt 3 import matplotlib as mpl 4 import numpy as np 5 #中文设置 6 mpl.rcParams["font.sans-serif"] = ["SimHei"] 7 mpl.rcParams["axes.unicode_minus"] = False 8 #数据取值 9 x = np.arange(len(list(result_dict)))*2000 10 y = [result_dict[i][0] for i in result_dict ] 11 y1 = [result_dict[i][1] for i in result_dict ] 12 y3=[] 13 for i in result_dict: 14 if '5'in result_dict[i] : 15 y3.append(result_dict[i]['5']) 16 else: 17 y3.append(0) 18 #属性设定 19 bar_width = 0.35*1300 20 tick_label = list(result_dict) 21 plt.bar(x, y, bar_width, align="center", color="c", label="0", alpha=0.7) 22 plt.bar(x+bar_width, y1, bar_width, color="b", align="center", label="1", alpha=0.7) 23 plt.bar(x+bar_width*2, y3, bar_width, color="y", align="center", label="空值", alpha=0.7) 24 25 plt.title('样本数据整体分布情况') 26 plt.xlabel("检测属性") 27 plt.ylabel("数值大小") 28 plt.xticks(x+bar_width/2, tick_label) 29 # 展现图 30 plt.legend() 31 plt.show() 32 print('在粗略的统计下') 33 print("依据本图,在即便是很少的人有不适症状,依然感染新型冠状病毒的概率很大") 34 # 参考链接https://www.cnblogs.com/czz0508/p/10458425.html 35 #参数参考 https://blog.csdn.net/weixin_40343504/article/details/111935995 36 # plt.bar(x, height, width=0.8, bottom=None, *, align='center', data=None, **kwargs) 37 # x 为一个标量序列,确定x轴刻度数目 38 # height 确定y轴的刻度 39 # width 决定了柱子的宽度,仅代表形状宽度 40 # bottom 决定了柱子距离x轴的高度,默认为None,即表示与x轴距离为0 41 # align x轴上的坐标与柱体对齐的位置 42 # color 柱体的填充颜色,“r","b","g","#123465",默认“b" 43 # alpha 柱体填充颜色的透明度 44 # tick_label=labels, 每个柱体的标签名称 45 # edgecolor 柱体的边框颜色 46 # linewidth 柱体边框线的宽度

1 # 构建线性回归模型勘察相关性(上) 2 from sklearn.linear_model import LinearRegression 3 #数据分离去掉结果数据 生成变量csv_data_110 4 csv_data_110=csv_data_11.drop('测试结果',axis=1,inplace=False) 5 # 观察变量数据情况 6 print(csv_data_11.head()) 7 print(csv_data_110.head()) 8 #建模操作 9 predict_model=LinearRegression() 10 predict_model.fit(csv_data_110,csv_data_11["测试结果"]) 11 print('线性回归系数为:',predict_model.coef_) 12 print('线性回归截距',predict_model.intercept_)

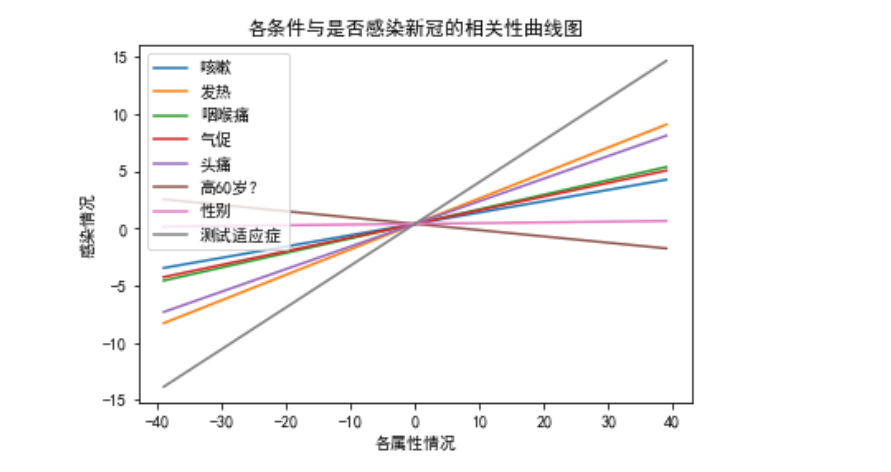
1 import matplotlib.pyplot as plt 2 import numpy as np 3 k=0 4 for i in predict_model.coef_: 5 x=[] 6 for j in range(-39,40): 7 x.append(j) 8 plt.plot(np.array(x),np.array(x)*i+predict_model.intercept_,label=csv_data_110.columns[k]) 9 k+=1 10 plt.title("各条件与是否感染新冠的相关性曲线图") 11 plt.xlabel("各属性情况") 12 plt.ylabel('感染情况') 13 plt.legend() 14 plt.show() 15 # 可以看出年龄是否60岁对是否感染新型冠状病毒几乎没有影响,而且有些反向相关 16 # (,年轻人比较容易外出走动,加大了感染风险,) 17 # 可以看出测试适应症和发热和头疼对是否感染新型冠状病毒占了比较大的比例的相关性 18 #可以思考测试适应症、发热、头痛、咳嗽、气促、咽喉痛之间的影响
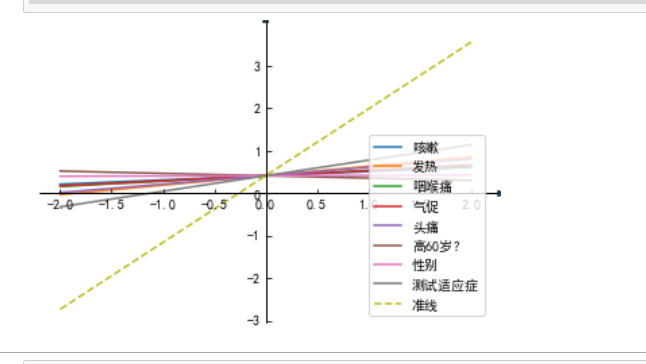
1 from mpl_toolkits.axisartist.axislines import SubplotZero 2 import matplotlib.pyplot as plt 3 import numpy as np 4 import math 5 mpl.rcParams["font.sans-serif"] = ["SimHei"] 6 mpl.rcParams["axes.unicode_minus"] = False 7 if 1: 8 fig = plt.figure(1) 9 ax = SubplotZero(fig, 111) 10 fig.add_subplot(ax) 11 for direction in ["xzero", "yzero"]: 12 # 轴末端加箭头 13 ax.axis[direction].set_axisline_style("-|>") 14 # 从原点添加x和y轴 15 ax.axis[direction].set_visible(True) 16 for direction in ["left", "right", "bottom", "top"]: 17 # #隐藏外框 18 ax.axis[direction].set_visible(False) 19 x = np.linspace(-2, 2., 100) 20 k=0 21 for i in predict_model.coef_: 22 ax.plot(x,x*i+predict_model.intercept_,label=csv_data_110.columns[k]) 23 k+=1 24 ax.plot(x,x*(math.pi/2)+predict_model.intercept_,'--',label=("准线")) 25 ax.plot() 26 plt.legend(loc='lower right') 27 plt.show() 28 #表明斜率越大越接近于真值 29 # 推荐中文官网http://www.matplotlib.org.cn/ 30 # -------------------------------------------- 31 # 结合以上两图,可以得出如下思考 32 #通过比列可以试着思考,通过各属性的占比计算权值,或许加权的思想考虑预测方式 33 #------------------------------------------------------------------------
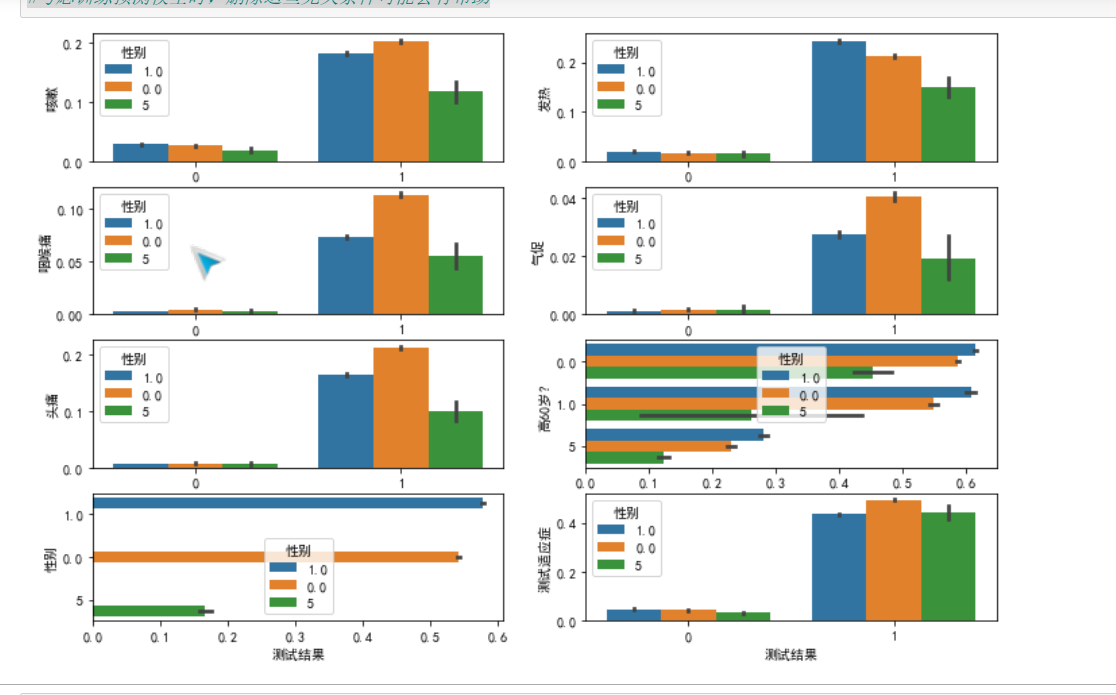
1 # "各条件属性与感染新型冠状病毒的特征柱形图" 2 # 展示样本数据相关情况 3 csv_data_1 4 import matplotlib.pyplot as plt 5 import matplotlib as mpl 6 import seaborn as sns 7 h=4 8 l=2 9 figsize = 12,8 10 # h行l列 11 fig, axes = plt.subplots(h,l,figsize=figsize) # 此处是一个2*2的图 12 mpl.rcParams["font.sans-serif"] = ["SimHei"] 13 mpl.rcParams["axes.unicode_minus"] = False 14 def likuai(n): 15 # 分块器 n=(a,b) 16 t=[] 17 for i in range(n[0]): 18 for j in range(n[1]): 19 t.append([i,j]) 20 return t 21 a=0 22 lk=likuai((h,l)) 23 for i in csv_data_11.columns.drop('测试结果')[0:h*l]: 24 sns.barplot(ax=axes[lk[a][0],lk[a][1]],y=i,x= '测试结果',data=csv_data_11,hue='性别') 25 a+=1 26 27 plt.show() 28 # 通过(0,1)的数据值的集合,可以分析各个条件下的平均值,同样也很具有参考意义 29 # ----------数据分析-------- 30 # 直观可见是否感染新冠后大概率会咳嗽,发热,咽喉痛,头疼气促 31 # 感染新冠后女性较为容易引发其他病症 32 # 男性比女性较为容易感染新冠,但几乎是同样易感染新冠的 33 # 缺失属性在【性别】和【是否60岁上】 34 # 对于年龄而言几乎与 是否60岁?无关的容易感染新冠(可能存在误差,由于缺失值的填充) 35 #有确认接触过患者感染几率是最大的 36 # ----------------------------------- 37 #考虑训练预测模型时,删除这些无关条件可能会有帮助
1 # 所有数据相对与是否感染新冠存在一定关系 2 # 所以理论上是可以构建预测模型来预测数据的 3 # 但是模型还会与输入样本训练的数据大小有一定的关联 4 # 所以选择构建了数据分隔点,寻找良好的样本大小以及最大的成功率 5 from sklearn.linear_model import LogisticRegression 6 import pandas as pd 7 n=[i for i in range(2,34,1)] 8 9 acc0=[] 10 # 获取当不同的分隔值下模型的成功率 11 mod=[] 12 # 方便提取最优模型 13 for i in n: 14 a= i *10**4#分隔参数 15 train_data=np.array(csv_data_110[0:a])#设置为数组参数 16 train_label=np.array(csv_data_11['测试结果'][0:a]) 17 test_data=np.array(csv_data_110[a:]) 18 test_label=np.array(csv_data_11['测试结果'][a:]) 19 from sklearn.ensemble import RandomForestClassifier 20 from xgboost import XGBClassifier 21 import numpy as np 22 #导入相关模型 23 model=LogisticRegression() 24 # model = RandomForestClassifier() 25 # model=XGBClassifier() 26 #训练模型 27 model.fit(train_data,train_label) 28 acc0.append(pd.Series(model.predict(test_data)-test_label).value_counts()[0]/len(model.predict(test_data)-test_label)) 29 mod.append(model) 30 #测试模型 31 print('相关测试标签',model.predict(test_data)) 32 print("真实标签数据",test_label) 33 print("-----------值的概率--------") 34 # 通过实打实的先预测再统计的方法得出的成功率 35 print(model.predict_proba(test_data)) 36 acc=pd.Series(model.predict(test_data)-test_label).value_counts()[0]/len(model.predict(test_data)-test_label) 37 print('成功概率:',acc) 38 #搭建模型参考 https://blog.csdn.net/weixin_42299494/article/details/113652085 39 # 评估模型参考https://blog.csdn.net/weixin_39774682/article/details/111204928
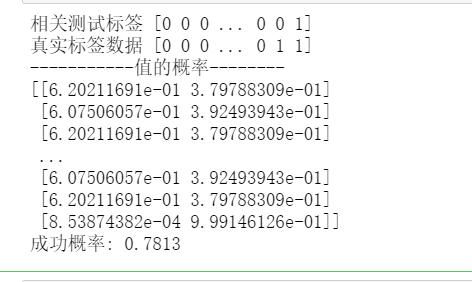
1 # 绘制相关折线图,展现数据变化情况 2 from matplotlib import pyplot as plt 3 #简易的极大值提取器 返回(极大值list,索引list) 4 def mx(data): 5 a=[] 6 ii=[] 7 for i in range(1,len(data)-1): 8 if data[i]>data[i-1] and data[i]>data[i+1]: 9 a.append(data[i]) 10 ii.append(i) 11 return (a,ii) 12 mpl.rcParams["font.sans-serif"] = ["SimHei"] 13 mpl.rcParams["axes.unicode_minus"] = False 14 plt.title("取值分隔线与成功率的关系") 15 plt.xlabel("分隔位置(单位/1e4)") 16 plt.ylabel('预测的成功率') 17 plt.plot(n,acc0) 18 plt.plot([ n[i] for i in mx(acc0)[1]],mx(acc0)[0],"o",c='red') 19 plt.show() 20 #坐标字典 21 x_dic=dict(zip(mx(acc0)[0],mx(acc0)[1])) 22 print(f'极大值的坐标({max(x_dic)},{x_dic[max(x_dic)]})') 23 print(f"最优模型:{ mod[x_dic[max(x_dic)]]}") 24 #该模型还是有一定的可信度,应该还有提升的空间 25 #model1最高可信成功率可达0.7829882352941177 26 #可以思考改变模型 或者修剪数据 提高成功率

1 # 简易的预测器 2 # 提取最优模型 3 model= mod[x_dic[max(x_dic)]] 4 # 构建有趣模型函数 5 def yuche(data,model): 6 print("注意输入的值代表着如下对应属性是否有症状") 7 print(" 咳嗽 发热 咽喉痛 气促 头痛 高60岁? 性别 测试适应症") 8 if model.predict([data])[0] ==1: 9 print('预测结果为 感染') 10 else: 11 print('预测结果为 没感染') 12 print(f'预测的感染概率是{max(model.predict_proba([data])[0]):0.2f}') 13 yuche([0,0,0,0,0,1,1,0],model) 14 yuche([0,1,0,0,0,0,0,0],model) 15 yuche([0,1,0,0,1,0,1,0],model) 16 # 视乎预测模型这效果感觉还可以

# ------------------------------------------------
# 唯一的缺点就是模型准确率不是很高
# 思考如何提高模型的准确率
# 尝试不同的分类模型处理 看是否会有影响
# --------------------------------------
1 # 模型绘图较为经常使用,在 以讨论不同分类函数对模型正确率是否有影响 2 # 固 做出如下优化-------------优化-(上)---------- 3 # 注意 该数据集默认先前样本数据的方式分配 4 from sklearn.linear_model import LogisticRegression 5 import pandas as pd 6 def jianmo (model): 7 from sklearn.ensemble import RandomForestClassifier 8 from xgboost import XGBClassifier 9 import numpy as np 10 from sklearn.model_selection import cross_val_score 11 import numpy as np 12 # ------!!!!!1------经过多次的 建模调参 血泪教训得知-!!!!!!!!!!!!------------------- 13 # 自定义函数里放自定义函数一定一定要注意全局变量和局部变量的问题 14 # --------这里变为全局变量非常非常重要------------------------------ 15 # 不设置为全局变量 直接会导致调用该函数时一直跑第一次的模型 16 global n 17 global acc0 18 global mod 19 global kacc 20 # --------------------------- 21 kacc=[] 22 n=[i for i in range(2,34,1)] 23 # n=[3,4,5,7,9] 24 acc0=[] 25 # 获取当不同的分隔值下模型的成功率 26 mod=[] 27 # 方便提取最优模型 28 # 观察变容量的影响 29 if len(csv_data_110) !=400000: 30 print('数据总样本已改变为',len(csv_data_110)) 31 for i in n: 32 a= i *10**4#分隔参数 33 # drop_5(csv_data_110) 34 # drop_5(csv_data_11) 35 train_data=np.array(csv_data_110[0:a])#设置为数组参数 36 train_label=np.array(csv_data_11['测试结果'][0:a]) 37 test_data=np.array(csv_data_110[a:]) 38 test_label=np.array(csv_data_11['测试结果'][a:]) 39 40 #导入相关模型 41 # model = RandomForestClassifier() 42 # model=XGBClassifier() 43 #训练模型 44 model.fit(train_data,train_label) 45 46 scores = cross_val_score(model,test_data,test_label, cv=5, scoring='accuracy') 47 kacc.append(np.mean(scores) ) 48 print( f"第{i-1}次断点,k折交叉验证accuracy为" ,np.mean(scores)) 49 acc0.append(pd.Series(model.predict(test_data)-test_label).value_counts()[0]/len(model.predict(test_data)-test_label)) 50 mod.append(model)
1 # 固 做出如下优化-------------优化-(下)---------- 2 # 绘制相关折线图,展现数据变化情况 3 def huitu(LogisticRegression): 4 jianmo(model=LogisticRegression) 5 from matplotlib import pyplot as plt 6 #简易的极大值提取器 返回(极大值list,索引list) 7 global n 8 global acc0 9 global mod 10 global kacc 11 def mx(data): 12 a=[] 13 ii=[] 14 for i in range(1,len(data)-1): 15 if data[i]>data[i-1] and data[i]>data[i+1]: 16 a.append(data[i]) 17 ii.append(i) 18 return (a,ii) 19 mpl.rcParams["font.sans-serif"] = ["SimHei"] 20 mpl.rcParams["axes.unicode_minus"] = False 21 plt.title("取值分隔线与成功率的关系") 22 plt.xlabel("分隔位置(单位/1e4)") 23 plt.ylabel('预测的成功率') 24 plt.plot(n,acc0,'--',label='k折acc') 25 plt.plot(n,kacc,label='实测acc')#绘制k折acc曲线 26 plt.plot([ n[i] for i in mx(acc0)[1]],mx(acc0)[0],"o",c='red') 27 plt.legend(loc='upper left') 28 plt.show() 29 #坐标字典 30 x_dic=dict(zip(mx(acc0)[0],mx(acc0)[1])) 31 # print(acc0) 32 print("k折交叉验证,最大成功率",max(kacc)) 33 if mx(acc0)!=([], []): 34 print(f'极大值的坐标({max(x_dic)},{x_dic[max(x_dic)]})') 35 print(f"最优模型:{ mod[x_dic[max(x_dic)]]}") 36 else: 37 print('真实测得最大成功率',max(acc0)) 38 print('无极值序列,请自行调节') 39 kacc=[] 40 n=[] 41 acc0=[] 42 # 获取当不同的分隔值下模型的成功率 43 mod=[]
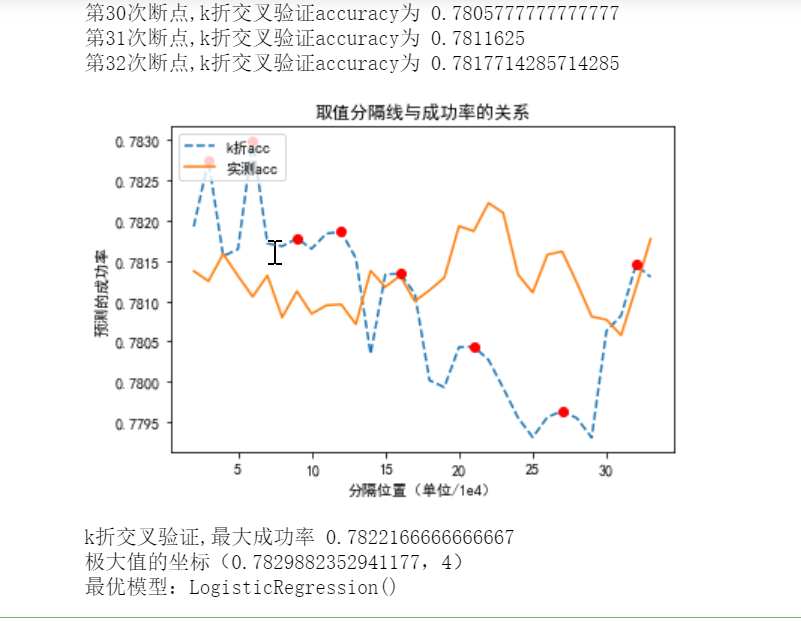
1 # 利用新模型处理数据 2 import seaborn as sns 3 import numpy as np 4 from sklearn import linear_model 5 from sklearn.linear_model import LogisticRegression 6 # from sklearn.model_selection import crosscross_val_score 7 from sklearn.model_selection import cross_val_score 8 #构建逻辑回归模型 9 feature=["咳嗽","发热",'气促',"头痛","高60岁?","性别"] 10 model_log=linear_model.LogisticRegression() 11 # model_log.fit(train_data,train_label)由于可以直接绘图所以注释l该处 12 LogisticRegression(C=1.0, class_weight='balanced', dual=False, fit_intercept=True, 13 intercept_scaling=1, max_iter=10, multi_class='ovr', n_jobs=1, 14 penalty='l2', random_state=None, solver='liblinear', tol=0.0001, 15 verbose=1, warm_start=False) 16 huitu(model_log) 17 #solver优化算法可选newton-cg,lbfgs,liblinear,sag,saga。 18 # 参数参考链接https://blog.csdn.net/jark_/article/details/78342644
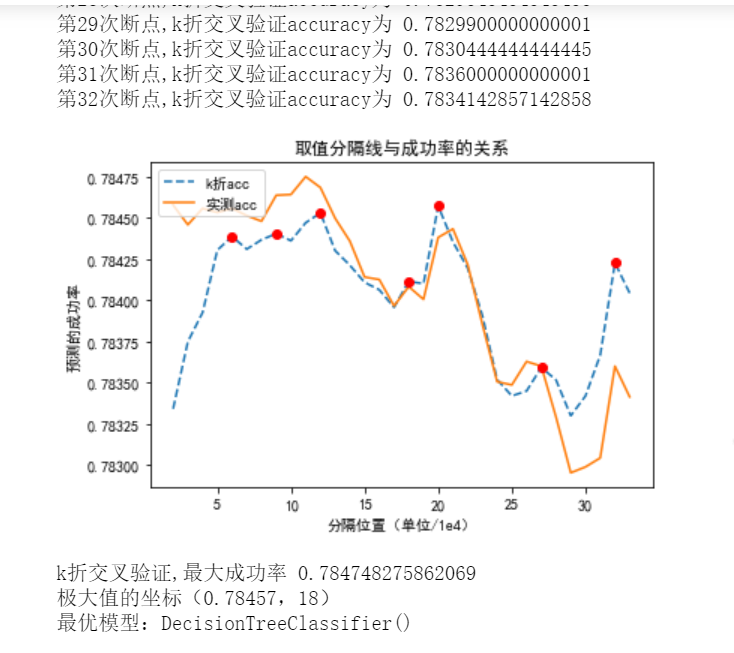
1 # 决策树分类 2 from sklearn.model_selection import cross_val_score 3 from sklearn import tree 4 dt = tree.DecisionTreeClassifier() 5 # dt.fit(train_data,train_label) 6 huitu(dt) 7 # scores = cross_val_score(dt, test_data, test_label, cv=5, scoring='accuracy') 8 # print(np.mean(scores))
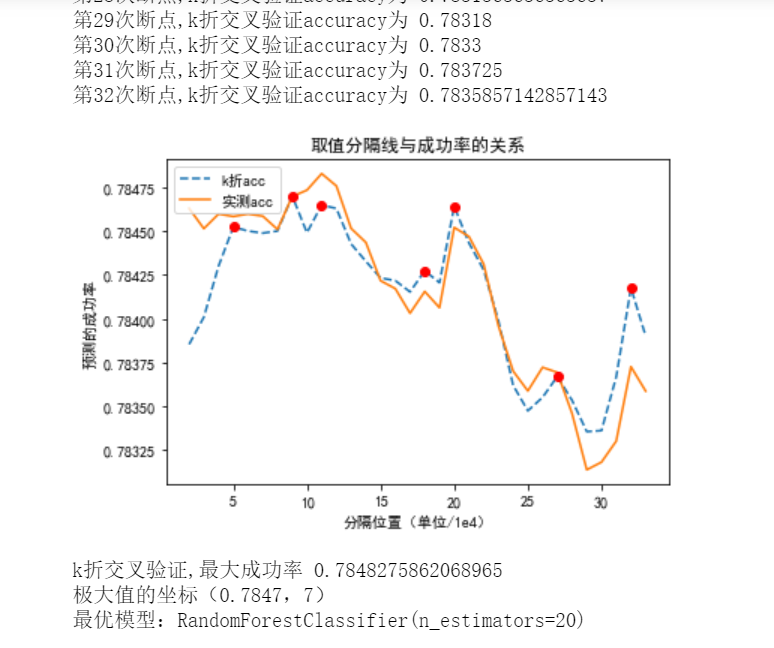
1 # 随机森林分类 2 from sklearn import ensemble 3 rf = ensemble.RandomForestClassifier(20) 4 # rf.fit(train_data,train_label) 5 huitu(rf)
1 #数据集合理论上,空值应该是与是否感染无关的 2 # 尝试删掉无效行来处理是否可以提高效果 3 # 因为这样可以提高样本特征,感觉上会有帮助,所以尝试一下 4 5 # 删掉 高60岁?为'5'的行 6 def drop_5(csv_data_110): 7 csv_data_110=((csv_data_110.drop(index=(csv_data_110.loc[(csv_data_110['高60岁?']=='5')].index)))) 8 print(csv_data_110[csv_data_110["高60岁?"]=='5']) 9 print(len(csv_data_110)) 10 csv_data_110=((csv_data_110.drop(index=(csv_data_110.loc[(csv_data_110['性别']=='5')].index)))) 11 print(csv_data_110[csv_data_110["性别"]=='5']) 12 print(len(csv_data_110)) 13 return csv_data_110 14 csv_data_110=drop_5(csv_data_110) 15 csv_data_11=drop_5(csv_data_11) 16 print(len(csv_data_110))
展示在删掉空值情况下的成功率的变化
1 # 随机森林分类 2 from sklearn import ensemble 3 rf = ensemble.RandomForestClassifier(20) 4 # rf.fit(train_data,train_label) 5 huitu(rf) 6 # 事实证明提供的数据越多,对模型效果较好,一味删掉一些参数会影响准确性
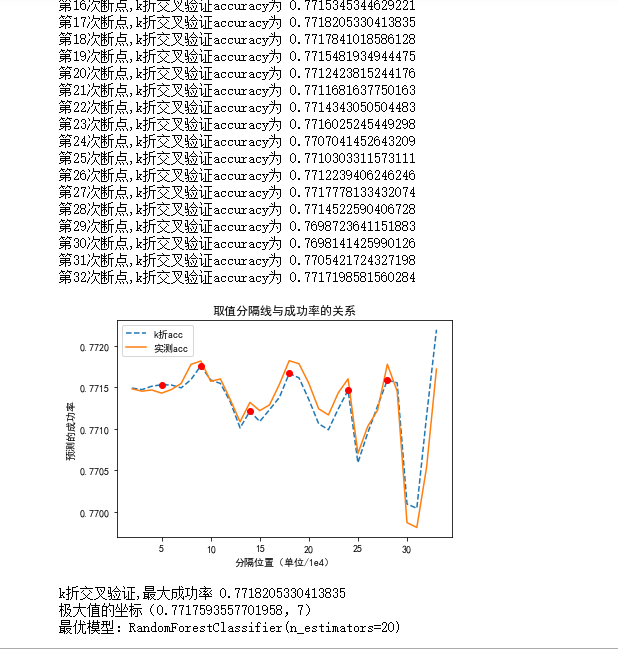
结果显示随机森林和决策树的效果较好一些,可以达到 78%。
附上全部完整代码
1 #数据提取 2 import pandas as pd 3 csv_file="F://2020年Covid-19数据集.csv" 4 csv_data=pd.read_csv(csv_file) 5 # print(csv_data) 6 print(len(csv_data)) 7 print(type(csv_data)) 8 csv_data_1=csv_data 9 #数据初步展示 10 csv_data.head() 11 # --------- 12 csv_data_1=csv_data.rename(columns={ 13 'test_date':'测试日期', 14 'cough':'咳嗽', 15 'fever':'发热', 16 'sore_throat':'咽喉痛', 17 'shortness_of_breath':'气促', 18 'head_ache':'头痛', 19 'corona_result':'测试结果', 20 'age_60_and_above':'高60岁?', 21 'gender':'性别', 22 'test_indication':'测试适应症'}) 23 csv_data_1.head() 24 # --------- 25 print(csv_data_1.info()) 26 print("---------------------------------具体情况-----------------------------") 27 print(csv_data_1.isnull().sum()) 28 print('"性别" 缺失的百分比 %.2f%%' %((csv_data_1['性别'].isnull().sum()/csv_data.shape[0])*100)) 29 print('"高60岁?" 缺失的百分比 %.2f%%' %((csv_data_1['高60岁?'].isnull().sum()/csv_data.shape[0])*100)) 30 # ------- 31 # 对数据有一个明晰的情况了解,特别重要 32 #数据展示 33 for i in csv_data_1.columns: 34 print(csv_data_1[i].value_counts()) 35 # ------ 36 1 # 数据归一化处理 37 2 #检测的值 positive,Yes,male,Contact with confirmed标记为1 38 3 #检测的值 negative,No,female,Other标记为0 39 4 # Abroad标记为2 40 csv_data_1=csv_data_1.replace("positive",'1').replace("negative",'0') 41 csv_data_1=csv_data_1.replace("male",'1').replace("female",'0').replace("No",'0').replace("Yes",'1') 42 csv_data_1=csv_data_1.replace("Contact with confirmed",'1').replace("Other",'0').replace("Abroad",'2') 43 print(csv_data_1) 44 # -------- 45 def null_count(csv_data_1): 46 lis_nul=[] 47 for i in csv_data_1.columns: 48 if csv_data_1[i].isnull().value_counts()[False]!=len(csv_data_1): 49 print('属性是:',i,"相关空值是:") 50 print(csv_data_1[i].isnull().value_counts()) 51 lis_nul.append(i) 52 print() 53 print('含有空值属性为',lis_nul) 54 null_count(csv_data_1) 55 # ----- 56 # 空值填充为5 57 csv_data_1=csv_data_1.fillna('5') 58 null_count(csv_data_1) 59 csv_data_1.head() 60 # ------- 61 # 样本各属性的数据分布情况直观展示 62 import matplotlib.pyplot as plt 63 import matplotlib as mpl 64 #中文设置 65 mpl.rcParams["font.sans-serif"] = ["SimHei"] 66 mpl.rcParams["axes.unicode_minus"] = False 67 #数据取值 68 axesl=plt.subplot(3,5,1) 69 csv_data_1['性别'].value_counts().plot(kind='bar',title='性别') 70 axes2=plt.subplot(3,5,3) 71 csv_data_1['高60岁?'].value_counts().plot(kind='bar',title='高60岁?') 72 axes3=plt.subplot(3,5,5) 73 csv_data_1['测试结果'].value_counts().plot(kind='bar',title='测试结果') 74 axes4=plt.subplot(3,5,7) 75 csv_data_1['咳嗽'].value_counts().plot(kind='bar',title='咳嗽') 76 axes4=plt.subplot(3,5,9) 77 csv_data_1['发热'].value_counts().plot(kind='bar',title='发热') 78 axes4=plt.subplot(3,5,11) 79 csv_data_1['头痛'].value_counts().plot(kind='bar',title='头痛') 80 axes4=plt.subplot(3,5,13) 81 csv_data_1['气促'].value_counts().plot(kind='bar',title='气促') 82 plt.show() 83 axes4=plt.subplot(3,5,15) 84 csv_data_1['咽喉痛'].value_counts().plot(kind='bar',title='咽喉痛') 85 plt.show() 86 csv_data_1['测试适应症'].value_counts().plot(kind='bar',title='测试适应症') 87 plt.show() 88 # ------- 89 csv_data_11=csv_data_1.drop('测试日期',axis=1) 90 x_label=(list(csv_data_11)) 91 #建构字典处理数据 92 lis=[] 93 a=[] 94 for i in csv_data_11: 95 if 0 not in list(csv_data_1[i].value_counts().index): 96 # # 97 lis.append(dict(zip(list(csv_data_1[i].value_counts().index),csv_data_1[i].value_counts().values))) 98 print("数据值保存为字典的列表") 99 print(lis) 100 #转字典 101 result_dict=dict(zip(x_label,lis)) 102 print(result_dict) 103 # ------ 104 #绘制组合柱状图(绘出图片)下 105 import matplotlib.pyplot as plt 106 import matplotlib as mpl 107 import numpy as np 108 #中文设置 109 mpl.rcParams["font.sans-serif"] = ["SimHei"] 110 mpl.rcParams["axes.unicode_minus"] = False 111 #数据取值 112 x = np.arange(len(list(result_dict)))*2000 113 # 有时候字典的key是int 有的时候是str类型 需要灵活更改 114 y = [result_dict[i]['0'] for i in result_dict ] 115 y1 = [result_dict[i]['1'] for i in result_dict ] 116 y3=[] 117 for i in result_dict: 118 if '5'in result_dict[i] : 119 y3.append(result_dict[i]['5']) 120 else: 121 y3.append(0) 122 #属性设定 123 bar_width = 0.35*1300 124 tick_label = list(result_dict) 125 plt.bar(x, y, bar_width, align="center", color="c", label="0", alpha=0.7) 126 plt.bar(x+bar_width, y1, bar_width, color="b", align="center", label="1", alpha=0.7) 127 plt.bar(x+bar_width*2, y3, bar_width, color="y", align="center", label="空值", alpha=0.7) 128 129 plt.title('样本数据整体分布情况') 130 plt.xlabel("检测属性") 131 plt.ylabel("数值大小") 132 plt.xticks(x+bar_width/2, tick_label) 133 # 展现图 134 plt.legend() 135 plt.show() 136 print('在粗略的统计下') 137 print("依据本图,在即便是很少的人有不适症状,依然感染新型冠状病毒的概率很大") 138 # ------- 139 # 构建线性回归模型勘察相关性(上) 140 from sklearn.linear_model import LinearRegression 141 #数据分离去掉结果数据 生成变量csv_data_110 142 csv_data_110=csv_data_11.drop('测试结果',axis=1,inplace=False) 143 # 观察变量数据情况 144 print(csv_data_11.head()) 145 print(csv_data_110.head()) 146 #建模操作 147 predict_model=LinearRegression() 148 predict_model.fit(csv_data_110,csv_data_11["测试结果"]) 149 print('线性回归系数为:',predict_model.coef_) 150 print('线性回归截距',predict_model.intercept_) 151 # -------- 152 # 构建线性回归模型勘察相关性(中) 153 from sklearn.linear_model import LinearRegression 154 import matplotlib.pyplot as plt 155 import numpy as np 156 k=0 157 for i in predict_model.coef_: 158 x=[] 159 for j in range(-39,40): 160 x.append(j) 161 plt.plot(np.array(x),np.array(x)*i+predict_model.intercept_,label=csv_data_110.columns[k]) 162 k+=1 163 plt.title("各条件与是否感染新冠的相关性曲线图") 164 plt.xlabel("各属性情况") 165 plt.ylabel('感染情况') 166 plt.legend() 167 plt.show() 168 # -----带准线的斜率图------- 169 from mpl_toolkits.axisartist.axislines import SubplotZero 170 import matplotlib.pyplot as plt 171 import numpy as np 172 import math 173 mpl.rcParams["font.sans-serif"] = ["SimHei"] 174 mpl.rcParams["axes.unicode_minus"] = False 175 if 1: 176 fig = plt.figure(1) 177 ax = SubplotZero(fig, 111) 178 fig.add_subplot(ax) 179 for direction in ["xzero", "yzero"]: 180 # 轴末端加箭头 181 ax.axis[direction].set_axisline_style("-|>") 182 # 从原点添加x和y轴 183 ax.axis[direction].set_visible(True) 184 for direction in ["left", "right", "bottom", "top"]: 185 # #隐藏外框 186 ax.axis[direction].set_visible(False) 187 x = np.linspace(-2, 2., 100) 188 k=0 189 for i in predict_model.coef_: 190 ax.plot(x,x*i+predict_model.intercept_,label=csv_data_110.columns[k]) 191 k+=1 192 ax.plot(x,x*(math.pi/2)+predict_model.intercept_,'--',label=("准线")) 193 ax.plot() 194 plt.legend(loc='lower right') 195 plt.show() 196 #------------------------------------------------------------------------ 197 # "各条件属性与感染新型冠状病毒的特征柱形图" 198 # 展示样本数据相关情况 199 csv_data_1 200 import matplotlib.pyplot as plt 201 import matplotlib as mpl 202 import seaborn as sns 203 h=4 204 l=2 205 figsize = 12,8 206 # h行l列 207 fig, axes = plt.subplots(h,l,figsize=figsize) # 此处是一个2*2的图 208 mpl.rcParams["font.sans-serif"] = ["SimHei"] 209 mpl.rcParams["axes.unicode_minus"] = False 210 def likuai(n): 211 # 分块器 n=(a,b) 212 t=[] 213 for i in range(n[0]): 214 for j in range(n[1]): 215 t.append([i,j]) 216 return t 217 a=0 218 lk=likuai((h,l)) 219 for i in csv_data_11.columns.drop('测试结果')[0:h*l]: 220 sns.barplot(ax=axes[lk[a][0],lk[a][1]],y=i,x= '测试结果',data=csv_data_11,hue='性别') 221 a+=1 222 223 plt.show() 224 # ----------构建预测模型-------- 225 # 所有数据相对与是否感染新冠存在一定关系-------------------------断点绘图(上)------------------------ 226 # 所以理论上是可以构建预测模型来预测数据的 227 from sklearn.linear_model import LogisticRegression 228 import pandas as pd 229 n=[i for i in range(2,34,1)] 230 acc0=[] 231 # 获取当不同的分隔值下模型的成功率 232 mod=[] 233 # 方便提取最优模型 234 for i in n: 235 a= i *10**4#分隔参数 236 train_data=np.array(csv_data_110[0:a])#设置为数组参数 237 train_label=np.array(csv_data_11['测试结果'][0:a]) 238 test_data=np.array(csv_data_110[a:]) 239 test_label=np.array(csv_data_11['测试结果'][a:]) 240 from sklearn.ensemble import RandomForestClassifier 241 from xgboost import XGBClassifier 242 import numpy as np 243 #导入相关模型 244 model=LogisticRegression() 245 # model = RandomForestClassifier() 246 # model=XGBClassifier() 247 #训练模型 248 model.fit(train_data,train_label) 249 acc0.append(pd.Series(model.predict(test_data)-test_label).value_counts()[0]/len(model.predict(test_data)-test_label)) 250 mod.append(model) 251 #测试模型 252 print('相关测试标签',model.predict(test_data)) 253 print("真实标签数据",test_label) 254 print("-----------值的概率--------") 255 # 通过实打实的先预测再统计的方法得出的成功率 256 print(model.predict_proba(test_data)) 257 acc=pd.Series(model.predict(test_data)-test_label).value_counts()[0]/len(model.predict(test_data)-test_label) 258 print('成功概率:',acc) 259 # --------- 260 # 绘制相关折线图,展现数据变化情况-------------断点绘图(下)------------------------------ 261 from matplotlib import pyplot as plt 262 #简易的极大值提取器 返回(极大值list,索引list) 263 def mx(data): 264 a=[] 265 ii=[] 266 for i in range(1,len(data)-1): 267 if data[i]>data[i-1] and data[i]>data[i+1]: 268 a.append(data[i]) 269 ii.append(i) 270 return (a,ii) 271 mpl.rcParams["font.sans-serif"] = ["SimHei"] 272 mpl.rcParams["axes.unicode_minus"] = False 273 plt.title("取值分隔线与成功率的关系") 274 plt.xlabel("分隔位置(单位/1e4)") 275 plt.ylabel('预测的成功率') 276 plt.plot(n,acc0) 277 plt.plot([ n[i] for i in mx(acc0)[1]],mx(acc0)[0],"o",c='red') 278 plt.show() 279 #坐标字典 280 x_dic=dict(zip(mx(acc0)[0],mx(acc0)[1])) 281 print(f'极大值的坐标({max(x_dic)},{x_dic[max(x_dic)]})') 282 print(f"最优模型:{ mod[x_dic[max(x_dic)]]}") 283 # -------------- 284 # 简易的预测器 285 # 提取最优模型 286 model= mod[x_dic[max(x_dic)]] 287 # 构建有趣模型函数 288 def yuche(data,model): 289 print("注意输入的值代表着如下对应属性是否有症状") 290 print(" 咳嗽 发热 咽喉痛 气促 头痛 高60岁? 性别 测试适应症") 291 if model.predict([data])[0] ==1: 292 print('预测结果为 感染') 293 else: 294 print('预测结果为 没感染') 295 print(f'预测的感染概率是{max(model.predict_proba([data])[0]):0.2f}') 296 yuche([0,0,0,0,0,1,1,0],model) 297 yuche([0,1,0,0,0,0,0,0],model) 298 yuche([0,1,0,0,1,0,1,0],model) 299 # 视乎预测模型这效果感觉还可以 300 # -------- 301 # 固 做出如下优化-------------优化-(上)---------- 302 # 注意 该数据集默认先前样本数据的方式分配 303 from sklearn.linear_model import LogisticRegression 304 import pandas as pd 305 def jianmo(model): 306 from sklearn.ensemble import RandomForestClassifier 307 from xgboost import XGBClassifier 308 import numpy as np 309 from sklearn.model_selection import cross_val_score 310 import numpy as np 311 # ------!!!!!1------经过多次的 建模调参 血泪教训得知-!!!!!!!!!!!!------------------- 312 # 自定义函数里放自定义函数一定一定要注意全局变量和局部变量的问题 313 # --------这里变为全局变量非常非常重要------------------------------ 314 # 不设置为全局变量 直接会导致调用该函数时一直跑第一次的模型 315 global n 316 global acc0 317 global mod 318 global kacc 319 # --------------------------- 320 kacc = [] 321 n = [i for i in range(2, 34, 1)] 322 # n=[3,4,5,7,9] 323 acc0 = [] 324 # 获取当不同的分隔值下模型的成功率 325 mod = [] 326 # 方便提取最优模型 327 # 观察变容量的影响 328 if len(csv_data_110) != 400000: 329 print('数据总样本已改变为', len(csv_data_110)) 330 for i in n: 331 a = i * 10 ** 4 # 分隔参数 332 # drop_5(csv_data_110) 333 # drop_5(csv_data_11) 334 train_data = np.array(csv_data_110[0:a]) # 设置为数组参数 335 train_label = np.array(csv_data_11['测试结果'][0:a]) 336 test_data = np.array(csv_data_110[a:]) 337 test_label = np.array(csv_data_11['测试结果'][a:]) 338 339 # 导入相关模型 340 # model = RandomForestClassifier() 341 # model=XGBClassifier() 342 # 训练模型 343 model.fit(train_data, train_label) 344 345 scores = cross_val_score(model, test_data, test_label, cv=5, scoring='accuracy') 346 kacc.append(np.mean(scores)) 347 print(f"第{i - 1}次断点,k折交叉验证accuracy为", np.mean(scores)) 348 acc0.append(pd.Series(model.predict(test_data) - test_label).value_counts()[0] / len( 349 model.predict(test_data) - test_label)) 350 mod.append(model) 351 # ------- 352 # 固 做出如下优化-------------优化-(下)---------- 353 # 绘制相关折线图,展现数据变化情况 354 def huitu(LogisticRegression): 355 jianmo(model=LogisticRegression) 356 from matplotlib import pyplot as plt 357 #简易的极大值提取器 返回(极大值list,索引list) 358 global n 359 global acc0 360 global mod 361 global kacc 362 def mx(data): 363 a=[] 364 ii=[] 365 for i in range(1,len(data)-1): 366 if data[i]>data[i-1] and data[i]>data[i+1]: 367 a.append(data[i]) 368 ii.append(i) 369 return (a,ii) 370 mpl.rcParams["font.sans-serif"] = ["SimHei"] 371 mpl.rcParams["axes.unicode_minus"] = False 372 plt.title("取值分隔线与成功率的关系") 373 plt.xlabel("分隔位置(单位/1e4)") 374 plt.ylabel('预测的成功率') 375 plt.plot(n,acc0,'--',label='k折acc') 376 plt.plot(n,kacc,label='实测acc')#绘制k折acc曲线 377 plt.plot([ n[i] for i in mx(acc0)[1]],mx(acc0)[0],"o",c='red') 378 plt.legend(loc='upper left') 379 plt.show() 380 #坐标字典 381 x_dic=dict(zip(mx(acc0)[0],mx(acc0)[1])) 382 # print(acc0) 383 print("k折交叉验证,最大成功率",max(kacc)) 384 if mx(acc0)!=([], []): 385 print(f'极大值的坐标({max(x_dic)},{x_dic[max(x_dic)]})') 386 print(f"最优模型:{ mod[x_dic[max(x_dic)]]}") 387 else: 388 print('真实测得最大成功率',max(acc0)) 389 print('无极值序列,请自行调节') 390 kacc=[] 391 n=[] 392 acc0=[] 393 # 获取当不同的分隔值下模型的成功率 394 mod=[] 395 # ------ 396 # 利用新模型处理数据 397 import seaborn as sns 398 import numpy as np 399 from sklearn import linear_model 400 from sklearn.linear_model import LogisticRegression 401 # from sklearn.model_selection import crosscross_val_score 402 from sklearn.model_selection import cross_val_score 403 #构建逻辑回归模型 404 feature=["咳嗽","发热",'气促',"头痛","高60岁?","性别"] 405 model_log=linear_model.LogisticRegression() 406 # model_log.fit(train_data,train_label)由于可以直接绘图所以注释l该处 407 LogisticRegression(C=1.0, class_weight='balanced', dual=False, fit_intercept=True, 408 intercept_scaling=1, max_iter=10, multi_class='ovr', n_jobs=1, 409 penalty='l2', random_state=None, solver='liblinear', tol=0.0001, 410 verbose=1, warm_start=False) 411 huitu(model_log) 412 # ----- 413 # 决策树分类 414 from sklearn.model_selection import cross_val_score 415 from sklearn import tree 416 dt = tree.DecisionTreeClassifier() 417 huitu(dt) 418 # ----- 419 # 随机森林分类 420 from sklearn import ensemble 421 rf = ensemble.RandomForestClassifier(20) 422 # rf.fit(train_data,train_label) 423 huitu(rf) 424 # ------ 425 # 删掉 高60岁?为'5'的行 426 def drop_5(csv_data_110): 427 csv_data_110=((csv_data_110.drop(index=(csv_data_110.loc[(csv_data_110['高60岁?']=='5')].index)))) 428 print(csv_data_110[csv_data_110["高60岁?"]=='5']) 429 print(len(csv_data_110)) 430 csv_data_110=((csv_data_110.drop(index=(csv_data_110.loc[(csv_data_110['性别']=='5')].index)))) 431 print(csv_data_110[csv_data_110["性别"]=='5']) 432 print(len(csv_data_110)) 433 return csv_data_110 434 csv_data_110=drop_5(csv_data_110) 435 csv_data_11=drop_5(csv_data_11) 436 print(len(csv_data_110)) 437 # ------- 438 # 随机森林分类 439 from sklearn import ensemble 440 rf = ensemble.RandomForestClassifier(20) 441 # rf.fit(train_data,train_label) 442 huitu(rf) 443 # 事实证明提供的数据越多,对模型效果较好
四、总结
1.通过对数据分析和挖掘,得到哪些有益的结论?是否达到预期的目标?
新冠病毒极大情况下依赖于接触传播,感染后患咳嗽,发热,咽喉痛,头疼,气促的症状显著升高,病毒不会管你是男是女,年纪大还是年纪小。基本达到预期目标,成功构建了预测模型。稍稍优化了一下。
2.自己在完成此设计过程中,得到哪些收获?以及要改进的建议
对数据的分析很重要,良好的数据分析有利于快速的选择较好的算法模型,同时进一步加深了机器学习的理解,最大的收获就是深刻体验了一下函数套函数,局部变量和全局变量的处理问题。没有很好的处理它们的关系,将引发一系列问题。 模型还有提升的空间,还可以继续思考如何提高模型的正确率,还有提升的空间,继续学习的方向。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号