

1、Nutch命令详解
Nutch采用了一种命令的方式进行工作,其命令可以是对局域网方式的单一命令也可以是对整个Web进行爬取的分步命令。
要看Nutch的命令说明,可执行"Nutch"命令。
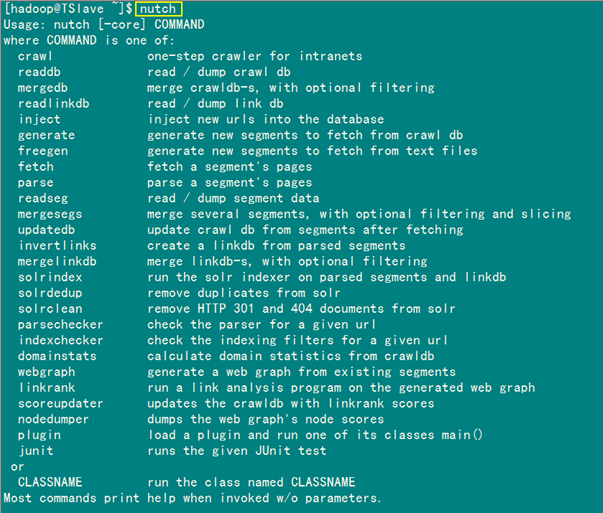
下面是单个命令的说明:
-
crawl
crawl是"org.apache.nutch.crawl.Crawl"的别称,它是一个完整的爬取和索引过程命令。
使用方法:
Shell代码
bin/nutch crawl <urlDir> [-dir d] [-threads n] [-depth i] [-topN]
参数说明:
<urlDir>:包括URL列表的文本文件,它是一个已存在的文件夹。
[-dir <d>]:Nutch保存爬取记录的工作目录,默认情况下值为:./crawl-[date],其中[date]为当前目期。
[-threads <n>]:Fetcher线程数,覆盖默认配置文件中的fetcher.threads.fetch值(默认为10)。
[-depth <i>]:Nutch爬虫迭代的深度,默认值为5。
[-topN <num>]:限制每一次迭代中的前N条记录,默认值为 Integer.MAX_VALUE。
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
crawl-tool.xml
其他文件:
crawl-urlfilter.txt
-
readdb
readdb命令是"org.apache.nutch.crawl.CrawlDbReader"的别称,返回或者导出Crawl数据库(crawldb)中的信息。
使用方法:
Shell代码
bin/nutch readdb <crawldb> (-stats | -dump <out_dir> | -url <url>)
参数说明:
<crawldb>:crawldb目录
[-stats]:在控制台打印所有的统计信息
[-dump <out_dir>]:导出crawldb信息到指定文件夹中的文件
[-url <url>]:打印指定URL的统计信息
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
示例:
Shell代码
$ bin/nutch readdb fullindex/crawldb -stats
CrawlDb statistics start: fullindex/crawldb
Statistics for CrawlDb: fullindex/crawldb
TOTAL urls: 468030
retry 0: 467361
retry 1: 622
retry 2: 32
retry 3: 15
min score: 0.0
avg score: 0.0034686408
max score: 61.401
status 1 (db_unfetched): 312748
status 2 (db_fetched): 80671
status 3 (db_gone): 69927
status 4 (db_redir_temp): 1497
status 5 (db_redir_perm): 3187
CrawlDb statistics: done
备注:
-stats命令是一个快速查看爬取信息的很有用的工作,其输出信息表示了:
db_unfetched:链接到已爬取页面但还没有被爬取的页面数(原因是它们没有通过url过滤器的过滤,或者包括在了TopN之外被Nutch丢弃)。
db_gone:表示发生了404错误或者其他一些臆测的错误,这种状态阻止了对其以后的爬取工作。
db_fetched:表示已爬取和索引的页面,如果其值为0,那肯定出错了。
-
readlinkdb
readlinkdb是"org.apache.nutch.crawl.LinkDbReader"的别称,导出链接库中信息或者返回其中一个URL信息。
使用方法:
Shell代码
Bin/nutch readlinkdb <linkdb> (-dump <out_dir> | -url <url>)
参数说明:
<linkdb>:linkdb工作目录
[-dump <out_dir>]:导出信息到文件夹下
[-url <url>]:打印某个URL的统计信息
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
示例:
Shell代码
$ bin/nutch readlinkdb fullindex/linkdb -url www.hebut.edu.cn - no link information
-
inject
inject是"org.apache.nutch.crawl.Injector"的别称,注入新URL到crawldb中。
使用方法:
Shell代码
bin/nutch injector <crawldb> <urldir>
参数说明:
<crawldb>:crawldb文件夹
<urldir>:保存有URL的文件的文件夹目录
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
以下配置文件参数影响到了注入方式:
db.default.fetch.interval:按天设置爬取间隔,默认值30.0f。
db.score.injected:设置URL的默认打分,默认值1.0f。
urlnormalizer.class:规范化URL的类,默认值为org.apache.nutch.net.BasicUrlNormalizer。
-
generate
generate是"org.apache.nutch.crawl.Generator",从Crawldb中抓取新的Segment。
使用方法:
Shell代码
bin/nutch generator <crawldb> <segments_dir> [-topN <num>] [-numFetchers <fetchers>] [-adddays <days>]
参数说明:
<crawldb>:crawldb目录
<segments_dir>:新建的爬取Segment目录
[-topN <num>]:选取前多少个链接,默认值为Long.MAX_VALUE
[-numFetchers <fetchers>]:抓取分区数量。默认Configuration keyà mapred.map.tasks à1
[-adddays <days>]:添加 <days>到当前时间,配置crawling urls ,以将很快被爬取db.default.fetch.interval默认值为0。爬取结束时间在当前时间以前的。
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
示例:
Shell代码
bin/nutch generate /my/crawldb /my/segments -topN 100 -adddays 20
备注:
generate.max.per.host:设置单个主机最大的URL数量,默认情况下为unlimited。
-
fetch
fetch是"org.apache.nutch.fetcher.Fetcher"的代称,它负责一个segment的爬取。
使用方法:
Shell代码
bin/nutch fetch <segment> [-threads <n>] [-noParsing]
参数说明:
<segment>:segment目录
[-threads <n>]:运行的fetcher线程数默认值 Configuration Key àfetcher.threads.fetch à10
[-noParsing]:禁用自动解析segment数据
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
备注:
Fetcher依赖于多个插件以爬取不同的协议,目前已有的协议及支撑插件如下:
http:
protocol-http
protocol-httpclient
https:
protocol-httpclient
ftp:
protocol-ftp
file:
protocol-file
当爬取网上文档的时候,不应该使用protocol-file,因为它是用于爬取本地文件的。如果你想爬取http、https,应当使用protocol-httpclient。
-
parse
parse是"org.apache.nutch.parse.ParseSegment"的代称,它对一个segment运行ParseSegment。
使用方法:
Shell代码
bin/nutch parse <segment>
参数说明:
<segment>:Segment文件夹
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
备注:
它依赖于多个插件来解析不同格式的内容,支持的格式及插件有:
|
内容格式 |
插件 |
备注 |
|
text/html |
parse-html |
使用NekoHTML 或者TagSoup解析HTML |
|
application/x-javascript |
parse-js |
解析JavaScript 文档(.js) |
|
audio/mpeg |
parse-mp3 |
解析MP3 Audio文档(.mp3) |
|
application/vnd.ms-excel |
parse-msexcel |
解析MSExcel文档(.xls) |
|
application/vnd.ms-powerpoint |
parse-mspowerpoint |
解析MSPower!Point 文档 |
|
application/msword |
parse-msword |
解析MSWord文档 |
|
application/rss+xml |
parse-rss |
解析RSS文档(.rss) |
|
application/rtf |
parse-rtf |
解析RTF文档(.rtf) |
|
application/pdf |
parse-pdf |
解析PDF文档 |
|
application/x-shockwave-flash |
parse-swf |
解析Flash 文档(.swf) |
|
text-plain |
parse-text |
解析Text文档(.txt) |
|
application/zip |
parse-zip |
解析Zip文档(.zip) |
|
other types |
parse-ext |
通过基于content-type或者路径前缀的外部命令来解析文档 |
默认情况下只有txt、HTML、JS格式的插件可用,其他的需要在nutch-site.xml中配置使用。
-
readseg
readseg是"org.apache.nutch.segment.SegmentReader"的代称,它读取并导出Segment数据。
使用方法:
Shell代码
bin/nutch readseg <segment>
参数说明:
<segment>:Segment文件夹
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
备注:
在Nutch0.9前的版本为了segread。
-
updatedb
updatedb是"org.apache.nutch.crawl.CrawlDb"的代称,用fetch过程中获取的信息更新crawldb。
使用方法:
Shell代码
bin/nutch updatedb <crawldb> <segment> [-noadditions]
参数说明:
<crawldb>:crawldb目录
<segment>:已经爬取的segment目录
[-noadditions]:是否添加新的链接到crawldb中
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
-
invertlinks
invertlinks是"org.apache.nutch.crawl.LinkDb"的代称,它用从segment中获取到的信息更新linkdb。
使用方法:
Shell代码
bin/nutch invertlinks <linkdb> (-dir segmentsDir | segment1 segment2 ...)
参数说明:
<linkdb>:linkdb目录
<segment>:segment目录,可以指定至少一个的文件夹
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
-
index
index是"org.apache.nutch.indexer.Indexer"的代称,创建一个segment的索引,利用crawldb和linkdb中的数据对索引中的页面打分。
使用方法:
Shell代码
bin/nutch index <index> <crawldb> <linkdb> <segment> ...
参数说明:
<index>:索引创建后的保存目录
<crawldb>:crawldb目录
<linkdb>:linkdb目录
<segment>:segment目录,可以指定多个
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
-
merge
merge是"org.apache.nutch.indexer.IndexMerger"的代称,它合并多个segment索引。
使用方法:
bin/nutch merge [-workingdir <workingdir>] <outputIndex> <indexesDir> ...
参数说明:
[-workingdir <workingdir>]:提定工作目录
<outputIndex>:合并后的索引存储目录
<indexesDir>:包含待合并的索引目录,可以指定多个
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
-
mergedb
mergedb是"org.apache.nutch.crawl.CrawlDbMerger"的代称,合并多个CrawlDb,URLFilter可选择性地过滤指定内容。
可以合并多个DB到一个中。当你分别运行爬虫并希望最终合并DB时,它会相当有用。可选择地,可以运行当前URLFilter过滤数据库中的URL,以滤去不需要的URL。当只有一个DB时也很有用,它意味着你可以通过这个工作去滤掉那些DB中你不想要的URL。
只用这个工具来过滤也是可能的,在这种情况下,只指定一个crawldb。
如果同一个URL包括在多个CrawlDb中,只有最近版本的才会被保留,即由org.apache.nutch.crawl.CrawlDatum.getFetchTime()值决定的。然而,所有版本的元数据被聚合起来,新的值代替先前的值。
使用方法:
bin/nutch mergedb output_crawldb crawldb1 [crawldb2 crawldb3 ...] [-filter]
参数说明:
output_crawldb:CrawlDb输出文件夹
crawldb1 [crawldb2 crawldb3 ...]:一个或者多个CrawlDb(s)
-filter:采用的URLFilters
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
-
mergelinkdb
mergelinkdb是"org.apache.nutch.crawl.LinkDbMerger"的代称,用于合并多个linkdb,可以选择性的使用URLFilter来过滤指定内容。
当分别从多个segment群中分布式建立LinkDb而又需要合并为一个时很有用。或者,也可以指定单个LinkDb,只是用它来过滤URL。
只用这个工具来过滤也是可能的,在这种情况下,只指定一个LinkDb。
如果一个URL包含在多个LinkDb中,所有的内部链接被聚合,但是最多db.max.inlinks 指定的内链数会添加进来。 如果被激活,URLFilter可以应用到所有的目标URL及其内链中。如果目标链接被禁止,所有的该目标链接的内链将和目标链接一起被移去。如果某些内链被禁止,那么只有他们会被移去,在校验上面提到的最大限制数时他们不会被计算在内。
使用方法:
bin/nutch mergelinkdb output_linkdb linkdb1 [linkdb2 linkdb3 ...] [-filter]
参数说明:
output_linkdb:输出linkdb
linkdb1 [linkdb2 linkdb3 ...]:多于一个的输入LinkDb(s)
-filter:Actual URLFilters to be applied on urls and links in LinkDb(s)
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
-
mergesegs
mergesegs是"org.apache.nutch.segment.SegmentMerger"的代称,用于合并多个segment,可以选择性地输出到一个或者多个固定大小的segment中。
使用方法:
Shell代码
bin/nutch mergesegs output_dir (-dir segments | seg1 seg2 ...) [-filter] [-slice NNNN]
参数说明:
output_dir:结果segment的名称或者segment片的父目录
-dir segments:父目录,包括多个segment
seg1 seg2 ...:segment目录列表
-filter:通过URLFilters过滤
-slice NNNN:创建多个输出segment,每一个中包括了NNNN个URL
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
-
dedup
dedup是"org.apache.nutch.indexer.DeleteDuplicates"的别名,它segment indexes中去掉重复的页面。
使用方法:
Shell代码
bin/nutch dedup <indexes> ...
参数说明:
<indexes>:indexes索引文件
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
-
plugin
plugin是"org.apache.nutch.plugin.PluginRepository"的代称,用于从插件库中加载一个插件并执行其主方法。
使用方法:
Shell代码
bin/nutch plugin <pluginId> <className> [args ...]
参数说明:
<pluginId>:期望执行的插件ID
<className>:包含主方法的类名
[args]:传入插件的参数
配置文件:
hadoop-default.xml
hadoop-site.xml
nutch-default.xml
nutch-site.xml
-
solrindex
solrindex是"org.apache.nutch.indexer.solr.SolrIndexer"的代称,用于对抓取的内容进行索引建立,前提是要有solr环境。
使用方法:
Shell代码
bin/nutch solrindex <solr url> <crawldb> -linkdb <linkdb> (<segment> ... | -dir <segments>)
参数说明:
<solr url>:这是你想索引数据的HTTP的Solr实例
<crawldb>:这个参数指明crawldb目录的路径
-linkdb <linkdb>:这个参数指明linkdb目录的路径,是可以省略的,当缺省时,不影响该solrindex命令的执行
<segment> ...:指一个目录包含的segment
-dir <segments>:指segment的全路径
[-noCommit]:索引segment后,不发送提交
[-deleteGone]:删除网页中的输入段和重定向
2、Nutch简单应用
下面我们将一步一步进行Nutch网络爬行。
-
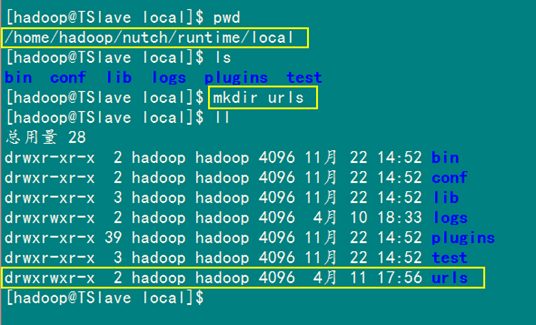
第一步:建立urls目录
在目录"/home/hadoop/nutch /runtime/local"下建立urls目录,见下图:
-
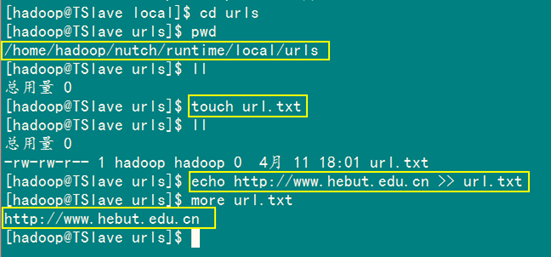
第二步: 建立抓取网站文本
在urls目录下建立url.txt文件,并输入你想爬的网站网址。
http://www.hebut.edu.cn/
-
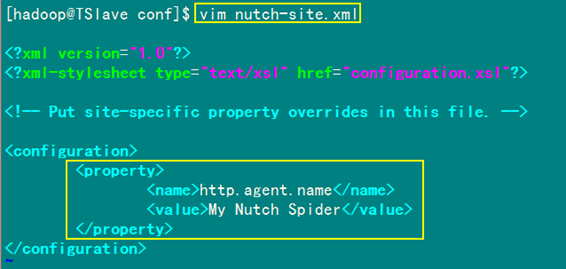
第三步:编辑nutch-site.xml文件
进入到"/home/hadoop/nutch/runtime/local/conf"目录下,修改nutch-site.xml文件,增加以下内容。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>http.agent.name</name>
<value>My Nutch Spider</value>
</property>
<property>
<name>http.agent.description</name>
<value>this is a crawler of xiapi</value>
</property>
</configuration>
备注:参考了众多文献,大部分都只是添加红色标注部分,其余的根据个人情况添加,我们这里也只把红色部分添加到"nutch-site.xml"文件里。
知识点:
Nutch中的所有配置文件都放置在总目录下的conf 子文件夹中,最基本的配置文件是
conf/nutch-default.xml。这个文件中定义了Nutch 的所有必要设置以及一些默认值,它是不
可以被修改的。如果你想进行个性化设置,你需要在conf/nutch-site.xml 进行设置,它会对
默认设置进行屏蔽。
Nutch考虑了其可扩展性,你可以自定义插件plugins 来定制自己的服务,一些plugins
存放于plugins 子文件夹。Nutch的网页解析与索引功能是通过插件形式进行实现的,例如,
对HTML 文件的解析与索引是通过HTML document parsing plugin,parse-html 实现的。所以你完全可以自定义各种解析插件然后对配置文件进行修改,然后你就可以抓取并索引各种类型的文件了。
-
第四步:编辑regex-urlfilter.txt文件
进入到"/home/hadoop/nutch/runtime/local/conf"目录下,修改regex-urlfilter.txt文件,在"# accept anything else"下面输入:"+^http://(\.*)*",然后保存,见下图:
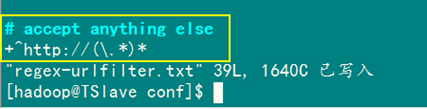
知识点:
-
Nutch 的爬虫有两种方式
-
爬行企业内部网:针对少数网站进行,用crawl 命令。
-
爬行整个互联网:使用低层的inject,generate,fetch 和updatedb 命令,具有更强的可控制性。
-
-
举例
-
+^http://([a-z0-9]*\.)*apache.org/
-
+^http://(\.*)*
-
句点符号匹配所有字符,包括空格、Tab 字符甚至换行符;
-
IP 地址中的句点字符必须进行转义处理(前面加上"\"),因为IP 地址中的句点具有它本来的含义,而不是采用正则表达式语法中的特殊含义。
-
-
-
第六步:开始抓取网页
使用下面命令进行抓取。
nutch crawl urls –dir crawl –depth 3 –topN 5
备注:这里是不带索引的,如果要对抓取的数据建立索引,运行如下命令。
nutch crawl urls -solr http://localhost:8983/solr/ -depth 3 -topN 5
我们这里暂时先采用不带索引的进行网页抓取。
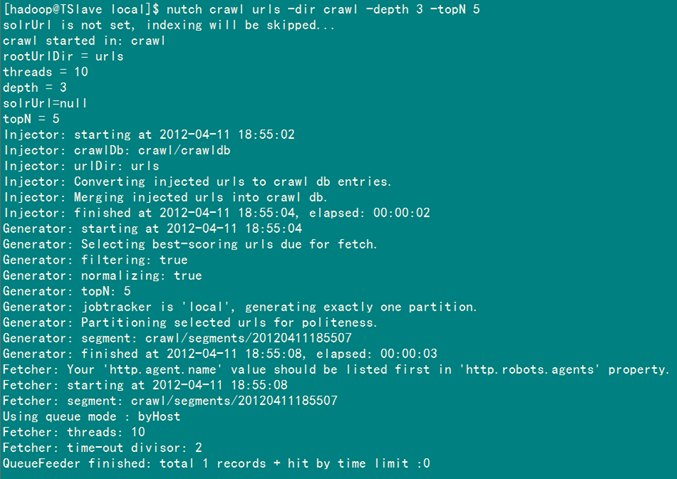
备注:运行这个命令必须在"/home/hadoop/nutch/runtime/local"目录下进行,不然会提示urls这个目录找不到。错误根源是我们写的命令中的urls这个目录的路径是相对路径。
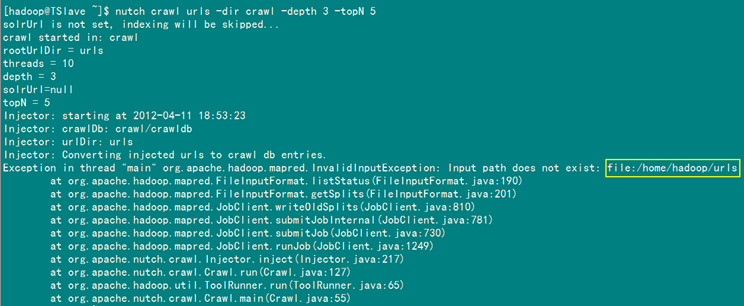
-
第七步:观察生成目录
抓取后,在"/home/hadoop/nutch/runtime/local"目录下生成一个crawl 文件夹。

下表2-1所示的生成的crawl文件夹中所包含的目录。
表2-1 Nutch数据集
|
目录 |
描述 |
|
crawldb |
爬行数据库,用来存储所要爬行的网址 |
|
linkdb |
链接数据库,用来存储每个网址的链接地址,包括源地址和链接地址 |
|
segments |
存放抓取的页面,与上面链接深度depth 相关,抓取的网址被作为一个单元,而一个segment就是一个单元。 一个segment包括以下几个子目录:
|
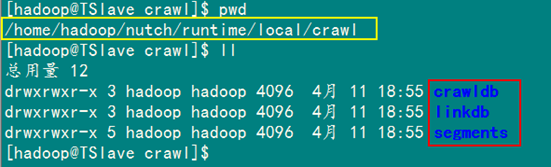
备注:在Nutch-1.3之后,抓取文件后,生成的目录只有crawldb,linkdb,segments,而没有了indexs和index目录。
知识点:
crawldb/ linkdb:web link目录,存放url 及url 的互联关系,作为爬行与重新爬行的依据,页面默认30 天过期(可以在nutch-site.xml 中配置)。
当depth 设为3,则在segments 下生成3个以时间命名的子文件夹。
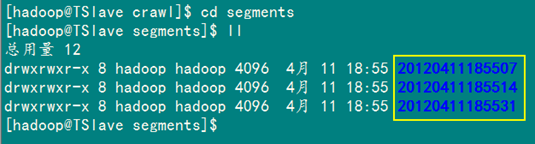
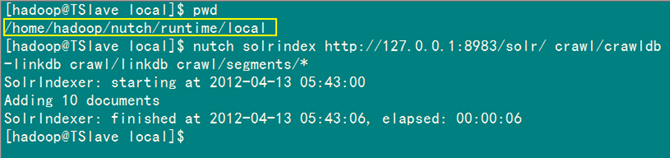
第八步:为刚才的数据建立索引,用Solr搜索。
执行下面语句建立索引。
nutch solrindex http://127.0.0.1:8983/solr/ crawl/crawldb -linkdb crawl/linkdb crawl/segments/*
在执行前,用SecureCRT打开另一个控制台,执行下面命令,不然执行会失败。
java –jar start.jar
上面这个比较麻烦,我们用第二种。
nutch solrindex http://127.0.0.1:8080/solr/ crawl/crawldb -linkdb crawl/linkdb crawl/segments/*

第二种情况就不需要另开一个终端启动Solr了,因为我们这时是用的Tomcat中配置的Solr,此时这个Solr已经在运行了。注意上面的端口号。

点击"Search",然后出现搜索结果如下:

如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【虾皮★csAxp】。
如果,您还想与更多的爱好者进一步交流,不防加入QQ群【虾皮工作室-ABC大数据(232658451)】。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号