
文章标题
One SQL to Rule Them All – an Efficient and Syntactically Idiomatic Approach to Management of Streams and Tables
用SQL统一所有:一种有效的、语法惯用的流和表管理方法
- syntactically 句法上;语法上;句法;句法性地;句法特征
- idiomatic [ˌɪdiəˈmætɪk] 惯用的;合乎语言习惯的;习语的
- approach [əˈproʊtʃ]
v.(在距离或时间上)靠*,接*;接洽;建议;要求;(在数额、水*或质量上)接*
n.(待人接物或思考问题的)方式,方法,态度;(距离和时间上的)靠*,接*;接洽;建议;要求
作者介绍
Apache Calcite:Edmon Begoli、Julian Hyde;
Apache Beam:Tyler Akidau、Kenneth Knowles;
Apache Flink:Fabian Hueske
Kathryn Knight
文章正文
ABSTRACT
Real-time data analysis and management are increasingly critical for today’s businesses. SQL is the de facto lingua franca for these endeavors, yet support for robust streaming analysis and management with SQL remains limited. Many approaches restrict semantics to a reduced subset of features and/or require a suite of non-standard constructs. Additionally, use of event timestamps to provide native support for analyzing events according to when they actually occurred is not pervasive, and often comes with important limitations.
- increasingly [ɪnˈkriːsɪŋli] adv.越来越多地;不断增加地
- critical [ˈkrɪtɪkl] adj. 批评的;批判性的;挑剔的;极重要的;关键的;至关紧要的;严重的;不稳定的;可能有危险的
- de [di] prep.(属于)…的;从;关于;属于
- facto [ˈfæktoʊ] n. 实际上;事实上;根据事实或行为
- lingua franca[ˌlɪŋɡwə ˈfræŋkə] n. (母语不同的人共用的)通用语
- endeavor [ɪnˈdɛvər] n./v. 努力,尽力,企图,试图
- yet [jet] adv. 用于否定句和疑问句,谈论尚未发生但可能发生的事;现在;即刻;马上;从现在起直至某一时间;还 conj. 但是;然而
- robust [roʊˈbʌst] adj. 强健的;强壮的;结实的;耐用的;坚固的;强劲的;富有活力的
- remains [rɪˈmeɪnz] n. 剩余物;残留物;剩饭菜;古代遗物;古迹;遗迹;遗址;遗体;遗骸 v. 仍然是;保持不变;剩余;遗留;继续存在;仍需去做(或说、处理)
- restrict [rɪˈstrɪkt] v. 限制,限定(数量、范围等);束缚;妨碍;阻碍;(以法规)限制
- semantic [sɪˈmæntɪk] adj. 语义的
- pervasive [pərˈveɪsɪv] adj.遍布的;充斥各处的;弥漫的;无处不在
对于当今的企业来说,实时数据分析和管理越来越重要。 SQL是这些努力的事实上的通用语言,但对SQL的强大流分析和管理的支持仍然有限。 许多方法将语义限制为减少的特征子集和/或需要一套非标准构造。 此外,使用事件时间戳来提供本机支持,以便根据事件实际发生的时间来分析事件并不是普遍存在的,并且通常具有重要的局限性。
We present a three-part proposal for integrating robust streaming into the SQL standard, namely: (1) time-varying relations as a foundation for classical tables as well as streaming data, (2) event time semantics, (3) a limited set of optional keyword extensions to control the materialization of time-varying query results. Motivated and illustrated using examples and lessons learned from implementations in Apache Calcite, Apache Flink, and Apache Beam, we show how with these minimal additions it is possible to utilize the complete suite of standard.
- proposal [prəˈpoʊzl] n. 提议;建议;动议;求婚
- integrating [ˈɪntɪɡreɪtɪŋ] v.(使)合并,成为一体;(使)加入,融入群体,整合
- namely [ˈneɪmli] adv. 即;也就是
- foundation [faʊnˈdeɪʃn] n. 地基;房基;基础;基本原理;根据;基金会
- materialization n. 物质化;具体化;实现;物化
- motivated [ˈmoʊtɪveɪtɪd] v. 成为…的动机;是…的原因;推动…甘愿苦干;激励;激发;(就所说的话)给出理由;说明…的原因;启发
- illustrated [ˈɪləstreɪtɪd] v. 加插图于;给(书等)做图表;(用示例、图画等)说明,解释;表明…真实;显示…存在
- implementations [ˌɪmpləmɛnˈteɪʃənz] 实现;实施;实现工具;实作
- utilize [ˈjuːtəlaɪz] v. 使用;利用;运用;应用
我们提出了一个将强健流式集成到SQL标准中的三部分提议,即:(1)时变关系作为经典表格和流数据的基础,(2)事件时间语义,(3)有限集合 可选的关键字扩展,用于控制时变查询结果的具体化。 通过使用Apache Calcite,Apache Flink和Apache Beam中的实现中的示例和经验教训进行激励和说明,我们展示了如何利用这些最小的附加功能来使用完整的标准套件。
1 INTRODUCTION
The thesis of this paper, supported by experience developing large open-source frameworks supporting real-world streaming use cases, is that the SQL language and relational model, as-is and with minor non-intrusive extensions, can be very effective for manipulation of streaming data.
- thesis [ˈθiːsɪs] n. 论文;毕业论文;学位论文;命题;论题
本文的论文在开发支持实际流式使用案例的大型开源框架的经验的支持下,是SQL语言和关系模型,原样并且具有次要的非侵入式扩展,可以非常有效地操作流数据。
Our motivation is two-fold. First, we want to share our observations, innovations, and lessons learned while working on stream processing in widely used open source frameworks. Second, we want to inform the broader database community of the work we are initiating with the international SQL standardization body [26] to standardize streaming SQL features and extensions, and to facilitate a global dialogue on this topic (we discuss proposed extensions in Section 6).
- motivation [ˌmoʊtɪˈveɪʃn] n. 动机;动力;诱因
- observations [ˌɑbzərˈveɪʃənz] n. 观察;观测;监视;(尤指据所见、所闻、所读而作的)评论
- facilitate [fəˈsɪlɪteɪt] v. 促进;促使;使便利
- dialogue [ˈdaɪəlɔːɡ] n. (书、戏剧或电影中的)对话,对白;(尤指集体或国家间为解决问题、结束争端等进行的)对话
我们的动机是双重的。 首先,我们希望在广泛使用的开源框架中处理流处理时分享我们的观察,创新和经验教训。 其次,我们希望向更广泛的数据库社区通报我们正在与国际SQL标准化机构[26]开展的工作,以标准化流SQL特性和扩展,并促进关于该主题的全球对话(我们在第6节讨论建议的扩展))。
1.1 One SQL for Tables and Streams
Combined, tables and streams cover the critical spectrum of business operations ranging from strategic decision making supported by historical data to near- and real-time data used in interactive analysis. SQL has long been a dominant technology for querying and managing tables of data, backed by decades of research and product development.
- spectrum [ˈspektrəm] n. 谱;光谱;声谱;波谱;频谱;范围;各层次;系列;幅度
- strategic [strəˈtiːdʒɪk] adj. 根据全局而安排的;战略性的;战略上的
表格和流程结合起来涵盖了业务运营的关键范围,从历史数据支持的战略决策到交互式分析中使用的*实时数据。 在数十年的研究和产品开发的支持下,SQL长期以来一直是查询和管理数据表的主导技术。
We believe, based on our experience and nearly two decades of research on streaming SQL extensions, that using the same SQL semantics in a consistent manner is a productive and elegant way to unify these two modalities of data: it simplifies learning, streamlines adoption, and supports development of cohesive data management systems. Our approach is therefore to present a unified way to manage both tables and streams of data using the same semantics.
- elegant [ˈelɪɡənt] adj. 优美的;文雅的;漂亮雅致的;陈设讲究的;精美的;简练的;简洁的;简明的
- modalities [məˈdælətiz] n. 形式;样式;方式;形态;情态;感觉模式;感觉形式
- cohesive [koʊˈhiːsɪv] adj. 结成一个整体的;使结合的;使凝结的;使内聚的
我们相信,根据我们的经验和*二十年的流式SQL扩展研究,以一致的方式使用相同的SQL语义是统一这两种数据模式的高效优雅方式:它简化了学习,简化了采用,以及 支持有凝聚力的数据管理系统的开发。 因此,我们的方法是使用相同的语义提供统一管理表和数据流的方法。
1.2 Proposed Contribution
Building upon the insights gained in prior art and through our own work, we propose these contributions in this paper:
在现有技术和我们自己的工作中获得的见解的基础上,我们在本文中提出了这些贡献:
Time-varying relations: First, we propose time-varying relations as a common foundation for SQL, underlying classic point-in-time queries, continuously updated views, and novel streaming queries. A time-varying relation is just what it says: a relation that changes over time, which can also be treated as a function, mapping each point in time to a static relation. Critically, the full suite of existing SQL operators remain valid on time-varying relations (by the natural point-wise application), providing maximal functionality with minimal cognitive overhead. Section 3.1 explores this in detail and Section 6.2 discusses its relationship to standard SQL.
- novel [ˈnɑːvl] n. (长篇)小说 adj. 新颖的;与众不同的;珍奇的
- point-wise [pɔɪnt waɪz] 逐点;点方式
- cognitive [ˈkɑːɡnətɪv] adj. 认知的;感知的;认识的
时变关系:首先,我们提出时变关系作为SQL的基础,基础经典时间点查询,不断更新的视图和新颖的流式查询。 时变关系就是它所说的:随时间变化的关系,也可以被视为函数,将每个时间点映射到静态关系。 至关重要的是,全套现有的SQL运算符在时变关系(通过自然的逐点应用程序)上仍然有效,提供最大的功能和最小的认知开销。 3.1节详细探讨了这一点,6.2节讨论了它与标准SQL的关系。
Event time semantics: Second, we present a concise proposal for enabling robust event time streaming semantics. The extensions we propose preserve all existing SQL semantics and fit in well. By virtue of utilizing time-varying relations as the underlying primitive concept, we can freely combine classical SQL and event time extensions. Section 3.2 describes the necessary foundations and Sections 6.2-6.4 describe our proposed extensions for supporting event time.
- concise [kənˈsaɪs] adj. 简明的;简练的;简洁的;简略的;简缩的
- proposal [prəˈpoʊzl] n. 提议;建议;动议;求婚
事件时间语义:其次,我们提出了一个简明的提议,用于启用强大的事件时间流语义。 我们建议的扩展保留了所有现有的SQL语义并且很好地适应。 通过利用时变关系作为底层原始概念,我们可以自由地组合经典SQL和事件时间扩展。 3.2节描述了必要的基础,第6.2-6.4节描述了我们提议的支持事件时间的扩展。
Materialization control: Third, we propose a modest set of materialization controls to provide the necessary flexibility for handling the breadth of modern streaming use cases.
- materialization n. 物质化;具体化;实现
物化控制:第三,我们提出了一套适度的物化控制,以便为处理现代流媒体用例的广度提供必要的灵活性。
- Stream materialization: To complete the stream-table duality,we propose to allow optionally rendering query output as a stream of changes to the output relation. This stream is, itself, a time-varying relation to which streaming SQL can be applied to express use cases for the stream aspect of systems that differentiate streams and tables. Section 3.3.1 describes stream materialization in general and Section 6.5.1 describes our proposal for adding stream materialization to SQL.
- duality [duːˈæləti] n. 双重性;二元性
- 流实现:为了完成流表二元性,我们建议允许选择性地将查询输出呈现为输出关系的变化流。 该流本身是一个时变关系,流SQL可用于表示区分流和表的系统流方面的用例。 第3.3.1节概述了流实现,第6.5.1节描述了我们向SQL添加流实现的建议。
- Materialization delay: Lastly, we propose a minimal, but flexible, framework for delaying the materialization of incomplete, speculative results from a time-varying relation. Our framework adds expressiveness beyond instantaneously updated view semantics to support push semantics (e.g., notification use cases, which are often poorly served by instantaneous update) as well as high-volume use cases (e.g., controlling the frequency of aggregate coalescence in high throughput streams). Section 3.3.2 discusses materialization control in detail and Section 6.5.2 presents our framework for materialization.
- speculative [ˈspekjələtɪv] adj. 推测的;猜测的;推断的;揣摩的;忖度的;试探的;投机性的;风险性的
- instantaneously adv. 即刻;突如其来地
- instantaneous [ˌɪnstənˈteɪniəs] adj. 立即的;立刻的;瞬间的
- coalescence [ˌkoʊəˈlɛsəns] n. 合并;联合;接合
- 实现延迟:最后,我们提出了一个最小但灵活的框架,用于推迟从时变关系中对不完整的推测结果的具体化。 我们的框架增加了超越即时更新的视图语义的表达性,以支持推送语义(例如,通知用例,通常由瞬时更新服务很差)以及大量用例(例如,控制高吞吐量流中聚合聚合的频率))。 第3.3.2节详细讨论了物化控制,第6.5.2节介绍了物化的框架。
Taken together, we believe these contributions provide a solid foundation for utilizing the full breadth of standard SQL in a streaming context, while providing additional capabilities for robust event time handling in the context of classic point-in-time queries.
总而言之,我们相信这些贡献为在流式上下文中利用标准SQL的全面性提供了坚实的基础,同时在经典时间点查询的上下文中提供了强大的事件时间处理的附加功能。
2 BACKGROUND AND RELATEDWORK
Stream processing and streaming SQL, in their direct forms, as well as under the guise of complex event processing (CEP) [18] and continuous querying [11], have been active areas of database research since the 1990s. There have been significant developments in these fields, and we present here a brief survey, by no means exhaustive, of research, industrial, and open source developments relevant to our approach.
- guise [ɡaɪz] n. 表现形式;外貌;伪装;外表 vi. 使化装伪装
- significant [sɪɡˈnɪfɪkənt] adj. 有重大意义的;显著的;有某种意义的;别有含义的;意味深长的
- exhaustive [ɪɡˈzɔːstɪv] adj. 详尽的;彻底的;全面的
- relevant [ˈreləvənt] adj. 紧密相关的;切题的;有价值的;有意义的
流式处理和流式SQL以其直接形式,以复杂事件处理(CEP)[18]和连续查询[11]为表现形式,自20世纪90年代以来一直是数据库研究的活跃领域。 这些领域已取得重大进展,我们在此提供与我们的方法相关的研究,工业和开源开发的简要调查,但并非详尽无遗。
2.1 A History of Streaming SQL
Work on stream processing goes back to the introduction of the Tapestry [25] system in 1992, intended for content-based filtering of emails and message board documents using a subset of SQL called TQL [37]. Several years later, Liu et al. introduced OpenCQ, an information delivery system driven by user- or application-specified events, the updates of which only occur at specified triggers that don‘t require active monitoring or interference [30]. That same group developed CONQUER, an update/capture system for efficiently monitoring continuous queries over the web using a three-tier architecture designed to share information among variously structured data sources [29]. Shortly thereafter NiagaraCQ emerged, an XML-QL-based query system designed to address scalability issues of continuous queries by grouping similar continuous queries together via dynamic regrouping [21]. OpenCQ, CONQUER, and NiagaraCQ each support arrival and timer-based queries over a large network (i.e. the Internet). However, neither Tapestry nor OpenCQ address multiple query optimization, and NiagaraCQ ignores query execution timings and doesn’t specify time intervals [27].
- intend [ɪnˈtend] v. 打算;计划;想要;意指
- delivery [dɪˈlɪvəri] n. 传送;递送;交付;分娩;演讲方式;表演风格
- thereafter [ˌðerˈæftər] adv. 之后;此后;以后
关于流处理的工作可以追溯到1992年Tapestry [25]系统的引入,该系统用于使用称为TQL的SQL子集对电子邮件和留言板文档进行基于内容的过滤[37]。几年后,刘等人。介绍了OpenCQ,一种由用户或应用程序指定的事件驱动的信息传递系统,其更新仅发生在不需要主动监视或干扰的指定触发器上[30]。同一个小组开发了CONQUER,这是一个更新/捕获系统,用于使用三层架构有效监控Web上的连续查询,该架构旨在在各种结构化数据源之间共享信息[29]。此后不久,NiagaraCQ出现了一个基于XML-QL的查询系统,旨在通过动态重组将类似的连续查询分组在一起来解决连续查询的可扩展性问题[21]。 OpenCQ,CONQUER和NiagaraCQ都支持在大型网络(即因特网)上的到达和基于计时器的查询。但是,Tapestry和OpenCQ都没有解决多个查询优化问题,NiagaraCQ忽略了查询执行时序,也没有指定时间间隔[27]。
In 2003, Arasu, Babu and Widom introduced the Continuous Query Language (CQL), a declarative language similar to SQL and developed by the STREAM project team at Stanford process both streaming and static data, this work was the first to introduce an exact semantics for general-purpose, declarative continuous queries over streams and relations. It formalized a form of streams, updateable relations, and their relationships; moreover, it defined abstract semantics for continuous queries constructed on top of relational query language concepts [8, 9].
- declarative [dɪˈklærətɪv] adj. 陈述的
2003年,Arasu,Babu和Widom推出了连续查询语言(CQL),这是一种类似于SQL的声明性语言,由STREAM项目团队在斯坦福大学开发流程和静态数据开发,这项工作是第一个引入精确语义的工作。 对流和关系的通用,声明性连续查询。 它形成了一种流,可更新的关系及其关系; 此外,它为在关系查询语言概念之上构建的连续查询定义了抽象语义[8,9]。
2.1.1 CQL Operators.
CQL defines three classes of operators: relation-to-relation, stream-to-relation, and relation-to-stream. The core operators, relation-to-relation, use a notation similar to SQL. Stream-to-relation operators extract relations from streams using windowing specifications, such as sliding and tumbling windows. Relation-to-stream operators include the Istream (insert stream), Dstream (delete stream), and Rstream (relation stream) operators [7]. Specifically, these three special operators are defined as follows:
CQL定义了三类运算符:关系到关系,流到关系和关系到流。 核心运算符(relation-to-relation)使用类似于SQL的表示法。 流到关系运算符使用窗口规范从流中提取关系,例如滑动和翻滚窗口。 关系到流的运算符包括Istream(插入流),Dstream(删除流)和Rstream(关系流)运算符[7]。 具体来说,这三个特殊运算符定义如下:
(1) Istream(R) contains all (r ,T ) where r is an element of R at T but not T − 1
(2) Dstream(R) contains all (r ,T ) where r is an element of R at T − 1 but not at T
(3) Rstream(R) contains all (r ,T ) where r is an element of R at time T [39]
The kernel of many ideas lies within these operators. Notably, time is implicit. The STREAM system accommodates out-of-order data by buffering it on intake and presenting it to the query processor in timestamp order, so the CQL language does not address querying of out-of-order data.
- implicit [ɪmˈplɪsɪt] adj. 含蓄的;不直接言明的;成为一部分的;内含的;完全的;无疑问的
- accommodates [əˈkɑːmədeɪts] v. 为(某人)提供住宿(或膳宿、座位等);容纳;为…提供空间;考虑到;顾及
- intake [ˈɪnteɪk] n. (食物、饮料等的)摄取量,吸入量;(一定时期内)纳入的人数;(机器上的液体、空气等的)进口
许多想法的核心在于这些运算符。 值得注意的是,时间是隐含的。 STREAM系统通过在进入时缓冲它并按时间戳顺序将其呈现给查询处理器来适应无序数据,因此CQL语言不会解决对无序数据的查询。
An important limitation of CQL is that time refers to a logical clock that tracks the evolution of relations and streams, not time as expressed in the data being analyzed, which means time is not a first-class entity one can observe and manipulate alongside other data.
- alongside [əˌlɔːŋˈsaɪd] prep. 在…旁边;沿着…的边;与…一起;与…同时
CQL的一个重要限制是时间是指跟踪关系和流的演变的逻辑时钟,而不是在被分析的数据中表达的时间,这意味着时间不是可以与其他数据一起观察和操纵的第一类实体。
2.1.2 Other Developments.
The Aurora system was designed around the same time as STREAM to combine archival, spanning, and real-time monitoring applications into one framework. Like STREAM, queries are structured as DirectedAcyclic Graphs with operator vertices and data flow edges [3]. Aurora was used as the query processing engine for Medusa, a load management system for distributed stream processing systems [13], and Borealis, a stream processing engine developed by Brandeis, Brown and MIT. Borealis uses Medusa’s load management system and introduced a new means to explore fault-tolerance techniques (results revision and query modification) and dynamic load distribution [2]. The optimization processes of these systems still do not take event specification into account. Aurora’s GUI provides custom operators, designed to handle delayed or missing data, with four specific novel functions: timeout capability, out-of-order input handling, user-defined extendibility, and a resampling operator [34]. These operators are partially based on linear algebra / SQL, but also borrow from AQuery and SEQ [12].
- linear algebra [ˈlɪniər ˈældʒɪbrə] 线性代数;线形代数;線性代數;线代;高等代数
Aurora系统与STREAM大致同时设计,将归档,跨越和实时监控应用程序组合到一个框架中。与STREAM一样,查询被构造为具有操作符顶点和数据流边缘的DirectedAcyclic Graphs [3]。 Aurora被用作Medusa的查询处理引擎,Medusa是一个用于分布式流处理系统的负载管理系统[13],Borealis是由Brandeis,Brown和MIT开发的流处理引擎。 Borealis使用Medusa的负载管理系统,并引入了一种新方法来探索容错技术(结果修订和查询修改)和动态负载分配[2]。这些系统的优化过程仍然没有考虑事件规范。 Aurora的GUI提供自定义操作符,旨在处理延迟或丢失的数据,具有四个特定的新功能:超时功能,无序输入处理,用户定义的可扩展性和重采样操作符[34]。这些运算符部分基于线性代数/ SQL,但也借鉴了AQuery和SEQ [12]。
IBM introduced SPADE, also known as System S [24], in 2008; this later evolved into InfoSphere Streams, a stream analysis platform which uses SPL, its own native processing language, which allows for event-time annotation.
IBM于2008年推出了SPADE,也称为System S [24]; 后来演变为InfoSphere Streams,这是一个流分析*台,它使用SPL(它自己的本机处理语言),允许事件时间注释。
2.2 Contemporary Streaming Systems
While streaming SQL has been an area of active research for almost three decades, stream processing itself has enjoyed recent industry attention, and many current streaming systems have adopted some form of SQL functionality.
虽然流式SQL*三十年来一直是一个活跃的研究领域,但流处理本身已经引起了业界的关注,而且许多当前的流式系统都采用了某种形式的SQL功能。
Apache Spark Spark’s Dataset API is a high-level declarative API built on top of Spark SQL’s optimizer and execution engine. Dataset programs can be executed on finite data or on streaming data. The streaming variant of the Dataset API is called Structured Streaming [10]. Structured Streaming queries are incrementally evaluated and by default processed using a micro-batch execution engine, which processes data streams as a series of small batch jobs and features exactly-once fault-tolerance guarantees.
- finite [ˈfaɪnaɪt] adj. 有限的;有限制的;限定的
- incrementally 递增地;逐渐地;增加地;渐进性的;增量模式
- evaluated [ɪˈvæljueɪtɪd] v. 估计;评价;评估
- guarantees [ˌɡærənˈtiːz] n. 保证;担保;保修单;保用证书;起保证作用的事物
Apache Spark Spark的Dataset API是一个基于Spark SQL优化器和执行引擎构建的高级声明式API。 数据集程序可以在有限数据或流数据上执行。 Dataset API的流式变体称为Structured Streaming [10]。 结构化流式查询是逐步评估的,默认情况下使用微批处理执行引擎进行处理,该引擎将数据流作为一系列小批量作业处理,并具有完全的容错保证。
KSQL Confluent’s KSQL [28] is built on top of Kafka Streams, the stream processing framework of the Apache Kafka project. KSQL is a declarative wrapper around Kafka Streams and defines a custom SQL-like syntax to expose the idea of streams and tables [33]. KSQL focuses on eventually consistent, materialized view semantics.
KSQL Confluent的KSQL [28]构建于Kafka Streams之上,Kafka Streams是Apache Kafka项目的流处理框架。 KSQL是Kafka Streams的声明性包装器,它定义了一个类似于SQL的自定义语法来揭示流和表的概念[33]。 KSQL专注于最终一致的物化视图语义。
Apache Flink [23] features two relational APIs, the LINQstyle [31] Table API and SQL, the latter of which has been adopted by enterprises like Alibaba, Huawei, Lyft, Uber, and others. Queries in both APIs are translated into a common logical plan representation and optimized using Apache Calcite [19], then optimized and execute as batch or streaming applications.
Apache Flink [23]提供了两个关系API,LINQstyle [31] Table API和SQL,后者已被阿里巴巴,华为,Lyft,Uber等企业采用。 两个API中的查询都被转换为通用的逻辑计划表示,并使用Apache Calcite [19]进行优化,然后作为批处理或流应用程序进行优化和执行。
Apache Beam [15] has recently added SQL support, developed with a careful eye towards Beam’s unification of bounded and unbounded data processing [5]. Beam currently implements a subset of the semantics proposed by this paper, and many of the proposed extensions have been informed by our experiences with Beam over the years.
Apache Beam [15]最*添加了SQL支持,开发时仔细考虑了Beam对有界和无界数据处理的统一[5]。 Beam目前实现了本文提出的语义的一个子集,并且许多提议的扩展已经通过我们多年来对Beam的经验得到了解。
Apache Calcite [19] is widely used as a streaming SQL parser and planner/optimizer, notably in Flink SQL and Beam SQL. In addition to SQL parsing, planning and optimization, Apache Calcite supports stream processing semantics which have, along with the approaches from Flink and Beam, influenced the work presented in this paper.
Apache Calcite [19]被广泛用作流式SQL解析器和规划器/优化器,特别是在Flink SQL和Beam SQL中。 除了SQL解析,规划和优化之外,Apache Calcite还支持流处理语义,这些语义与Flink和Beam的方法一起影响了本文中的工作。
There are many other such systems that have added some degree of SQL or SQL-like functionality. A key difference in our new proposal in this work is that other systems are either limited to a subset of standard SQL or bound to specialized operators. Additionally, the other prominent implementations do not fully support robust event time semantics, which is foundational to our proposal.
- prominent [ˈprɑːmɪnənt] adj. 重要的;著名的;杰出的;显眼的;显著的;突出的;凸现的
还有许多其他类似的系统增加了一定程度的SQL或类似SQL的功能。 我们在这项工作中的新提案的一个关键区别是,其他系统要么限于标准SQL的子集,要么绑定到专门的运算符。 此外,其他突出的实现并不完全支持强大的事件时间语义,这是我们的提议的基础。
In this paper, we synthesize the lessons learned from work on three of these systems - Flink, Beam, Calcite - into a new proposal for extending the SQL standard with the most essential aspects of streaming relational processing.
- synthesize [ˈsɪnθəsaɪz] v. (通过化学手段或生物过程)合成;(音响)合成;综合
- essential [ɪˈsenʃl] adj. 完全必要的;必不可少的;极其重要的;本质的;基本的;根本的
在本文中,我们将从这三个系统(Flink,Beam,Calcite)的工作中学到的经验综合成一个新的提案,用于扩展SQL标准,其中包括流关系处理的最重要方面。
3 MINIMAL STREAMING SQL FOUNDATIONS
Our proposal for streaming SQL comes in two parts. The first, in this section, is conceptual groundwork, laying out concepts and implementation techniques that support the fundamentals of streaming operations. The second, in Section 6, builds on these foundations, identifies the ways in which standard SQL already supports streaming, and proposes minimal extensions to SQL to provide robust support for the remaining concepts. The intervening sections are dedicated to discussing the foundations through examples and lessons learned from our open source frameworks.
- concept [ˈkɑːnsept] n. 概念;观念
- intervening [ˌɪntərˈviːnɪŋ] adj. 发生于其间的;介于中间的
我们的流式SQL提议分为两部分。 本节的第一部分是概念性基础,阐述了支持流操作基础的概念和实现技术。 第二部分在第6节的基础上,构建了这些基础,确定了标准SQL已经支持流式传输的方式,并提出了对SQL的最小扩展,以便为其余概念提供强大的支持。 介入部分致力于通过我们的开源框架中的示例和经验教训来讨论基础。
3.1 Time-Varying Relations
In the context of streaming, the key additional dimension to consider is that of time. When dealing with classic relations, one deals with relations at a single point in time. When dealing with streaming relations, one must deal with relations as they evolve over time. We propose making it explicit that SQL operates over time-varying relations, or TVRs.
- explicit [ɪkˈsplɪsɪt] adj. 清楚明白的;易于理解的;(说话)清晰的,明确的;直言的;坦率的;直截了当的;不隐晦的;不含糊的
在流媒体环境中,要考虑的关键附加维度是时间。 在处理经典关系时,人们会在一个时间点处理关系。 在处理流媒体关系时,必须处理随着时间的推移而发展的关系。 我们建议明确表示SQL在时变关系或TVR上运行。
A time-varying relation is exactly what the name implies: a relation whose contents may vary over time. The idea is compatible with the mutable database tables with which we are already familiar; to a consumer of such a table, it is already a time-varying relation.But such a consumer is explicitly denied the ability to observe or compute based on how the relation changes over time. A traditional SQL query or view can express a derived time-varying relation that evolves in lock step with its inputs: at every point in time, it is equivalent to querying its inputs at exactly that point in time. But there exist TVRs that cannot be expressed in this way, where time itself is a critical input.
- derived [dɪˈraɪvd] v. 获得;取得;得到;(使)起源;(使)产生;派生
TVRs are not a new idea; they are explored in [8, 9, 33]. An important aspect of TVRs is that they may be encoded or materialized in many ways, notably as a sequence of classic relations (instantaneous relations, in the CQL parlance), or as a sequence of INSERT and DELETE operations. These two encodings are duals of one another, and correspond to the tables and streams well described by Sax et al. [33]. There are other useful encodings based on relation column properties. For example, when an aggregation is invertible, a TVR’s encoding may use aggregation differences rather than entire deletes and additions.
- parlance [ˈpɑːrləns] n. 说法;术语;用语
- correspond [ˌkɔːrəˈspɑːnd] v. 相一致;符合;类似于;相当于;通信
- invertible adj. 相反的;可逆的;被翻过来的;被颠倒的
TVR不是一个新主意; 他们在[8,9,33]中进行了探索。 TVR的一个重要方面是它们可以以多种方式编码或实现,特别是作为一系列经典关系(瞬时关系,在CQL用语中),或作为一系列INSERT和DELETE操作。 这两种编码是彼此的双重编码,并且对应于Sax等人描述的表和流。[33]。 还有其他基于关系列属性的有用编码。 例如,当聚合是可逆的时,TVR的编码可以使用聚合差异而不是整个删除和添加。
Our main contribution regarding TVRs is to suggest that neither the CQL nor the Streams and Tables approaches go far enough: rather than defining the duality of streams and tables and then proceeding to treat the two as largely different, we should use that duality to our advantage. The key insight, stated but under-utilized in prior work, is that streams and tables are two representations for one semantic object. This is not to say that the representation itself is not interesting - there are use cases for materializing and operating on the stream of changes itself - but this is again a TVR and can be treated uniformly.
- neither nor [ˈnaɪðər nɔːr] 既不……也不;两者都不;均不
- go far [ɡoʊ fɑːr] 成功;经用;够用
我们对TVR的主要贡献是建议CQL和Streams and Tables方法都不够用:不是定义流和表的二元性,而是继续将两者视为大不相同,我们应该利用这种二元性来发挥我们的优势。 在先前的工作中陈述但未充分利用的关键见解是流和表是一个语义对象的两种表示。 这并不是说表示本身并不有趣 - 有用于实现变更流本身的用例 - 但这也是TVR并且可以统一对待。
What’s important here is that the core semantic object for relations over time is always the TVR, which by definition supports the entire suite of relational operators, even in scenarios involving streaming data. This is critical, because it means anyone who understands enough SQL to solve a problem in a non-streaming context still has the knowledge required to solve the problem in a streaming context as well.
这里重要的是,随着时间的推移,关系的核心语义对象始终是TVR,根据定义,TVR支持整套关系运算符,即使在涉及流数据的场景中也是如此。 这很关键,因为这意味着任何理解足够的SQL来解决非流式上下文中的问题的人仍然具有在流式上下文中解决问题所需的知识。
3.2 Event Time Semantics
Our second contribution deals with event time semantics. Many approaches fall short of dealing with the inherent independence of event time and processing time. The simplest failure is to assume data is ordered according to event time. In the presence of mobile applications, distributed systems, or even just sharded archival data, this is not the case. Even if data is in order according to event time, the progression of a logical clock or processing clock is unrelated to the scale of time as the events actually happened – one hour of processing time has no relation to one hour of event time. Event time must be explicitly accounted for to achieve correct results.
- inherent [ɪnˈhɪrənt] adj. 固有的;内在的
我们的第二个贡献涉及事件时间语义。 许多方法都无法处理事件时间和处理时间的固有独立性。 最简单的失败是假设数据是根据事件时间排序的。 在存在移动应用程序,分布式系统或甚至只是分片存档数据的情况下,情况并非如此。 即使根据事件时间数据是有序的,逻辑时钟或处理时钟的进展与事件实际发生的时间尺度无关 - 一小时的处理时间与一小时的事件时间无关。 必须明确说明事件时间才能获得正确的结果。
The STREAM system includes heartbeats as an optional feature to buffer out-of-order data and feed it in-order to the query processor. This introduces latency to allow timestamp skew. Millwheel [4] based its processing instead on watermarks, directly computing on the out-of-order data along with metadata about how complete the input was believed to be. This approach was further extended in Google’s Cloud Dataflow [5], which pioneered the out-of-order processing model adopted in both Beam and Flink.
- skew [skjuː] v. 歪曲;曲解;使不公允;影响…的准确性;偏离;歪斜
- pioneer [ˌpaɪəˈnɪr] n. 先锋;先驱;带头人;开发者;拓荒者
STREAM系统包括心跳作为可选功能,用于缓冲无序数据并将其按顺序提供给查询处理器。 这引入了延迟以允许时间戳偏斜。 Millwheel [4]的处理基于水印,直接计算无序数据以及有关输入被认为是完整的元数据。 这种方法在Google的Cloud Dataflow [5]中进一步扩展,它开创了Beam和Flink采用的无序处理模型。
The approach taken in KSQL [33] is also to process the data in arrival order. Its windowing syntax is bound to specific types of event-time windowing implementations provided by the system (rather than allowing arbitrary, declarative construction via SQL). Due to its lack of support for watermarks, it is unsuitable for use cases like notifications where some notion of completeness is required, instead favoring an eventual consistency with a polling approach. We believe a more general approach is necessary to serve the full breadth of streaming use cases.
- arbitrary [ˈɑːrbɪtreri] adj. 任意的;武断的;随心所欲的;专横的;专制的
- notion [ˈnoʊʃn] n. 观念;信念;理解
- favoring [ˈfeɪvərɪŋ] v. 喜爱,偏爱;赞同;有利于,便于
KSQL [33]采用的方法也是按到达顺序处理数据。 它的窗口语法绑定到系统提供的特定类型的事件时间窗口实现(而不是允许通过SQL进行任意的声明性构造)。 由于缺乏对水印的支持,它不适用于需要完整性概念的通知等用例,而是倾向于最终与轮询方法保持一致。 我们认为有必要采用更通用的方法来提供全面的流媒体用例。
We propose to support event time semantics via two concepts: explicit event timestamps and watermarks. Together, these allow correct event time calculation, such as grouping into intervals (or windows) of event time, to be effectively expressed and carried out without consuming unbounded resources.
我们建议通过两个概念来支持事件时间语义:显式事件时间戳和水印。 这些允许正确的事件时间计算,例如分组到事件时间的间隔(或窗口),以有效地表达和执行,而不消耗无限制的资源。
3.2.1 Event Timestamps.
To perform robust stream processing over a time-varying relation, the rows of the relation should be timestamped in event time and processed accordingly, not in arrival order or processing time.
为了在时变关系上执行鲁棒的流处理,关系的行应该在事件时间中加时间戳并相应地处理,而不是在到达顺序或处理时间。
3.2.2 Watermarks.
A watermark is a mechanism in stream processing for deterministically or heuristically defining a temporal margin of completeness for a timestamped event stream. Such margins are used to reason about the completeness of input data being fed into temporal aggregations, allowing the outputs of such aggregates to be materialized and resources to be released only when the input data for the aggregation are sufficiently complete. For example, a watermark might be compared against the end time of an auction to determine when all valid bids for said auction have arrived, even in a system where events can arrive highly out of order. Some systems provide configuration to allow sufficient slack time for events to arrive.
- mechanism [ˈmekənɪzəm] n. 机械装置;机件;方法;机制;(生物体内的)机制,构造
- deterministically adv. 确切地
- heuristically adv. 启发式地;试探性地
- temporal [ˈtempərəl] adj. 世间的;世俗的;现世的;时间的;太阳穴的;颞的
- sufficiently [sə'fɪʃ(ə)ntli] adv. 足以;十分;充分地;最大限度地
- auction [ˈɔːkʃn] n. 拍卖 v. 拍卖
- determine [dɪˈtɜːrmɪn] v. 查明;测定;准确算出;决定;形成;支配;影响;确定;裁决;安排
- slack [slæk] adj. 不紧的;松弛的;萧条的;冷清的;清淡的;懈怠的;不用心的;敷衍了事的;吊儿郎当的
水印是流处理中用于确定性地或启发式地定义时间戳事件流的完整性的时间余量的机制。 这些余量用于推断输入数据的完整性被馈送到时间聚合中,允许这些聚合的输出物化,并且仅当聚合的输入数据足够完整时才释放资源。 例如,可以将水印与拍卖的结束时间进行比较,以确定何时所有有效的所述拍卖的出价都已到达,即使在事件可能高度无序到达的系统中也是如此。 一些系统提供配置以允许事件到达的足够松弛时间。
More formally, a watermark is a monotonic function from processing time to event time. For each moment in processing time, the watermark specifies the event timestamp up to which the input is believed to be complete at that point in processing time. In other words, if a watermark observed at processing time y has value of event time x, it is an assertion that as of processing time y, all future records will have event timestamps greater than x.
- monotonic adj. 单调的;无变化的
更正式地说,水印是从处理时间到事件时间的单调函数。 对于处理时间中的每个时刻,水印指定事件时间戳,在该处理时间内输入被认为完成。 换句话说,如果在处理时间y处观察到的水印具有事件时间x的值,则断言:从处理时间y开始,所有未来记录将具有大于x的事件时间戳。
3.3 Materialization Controls
Our third contribution deals with shaping the way relations are materialized, providing control over how the relation is rendered and when rows themselves are materialized.
我们的第三个贡献涉及塑造关系实现的方式,控制关系的呈现方式以及行本身何时实现。
3.3.1 Stream Materialization.
As described in [33], stream changelogs are a space-efficient way of describing the evolution of a TVR over time. Changelogs capture the element-by-element differences between two versions of a relation, in effect encoding the sequence of INSERT and DELETE statements used to mutate the relation over time. They also expose metadata about the evolution of the rows in the relation over time. For example: which rows are added or retracted, the processing time at which a row was materialized, and the revision index of a row for a given event-time interval.
如[33]中所述,流更改日志是描述TVR随时间演变的节省空间的方式。 更改日志捕获关系的两个版本之间的元素 - 元素差异,实际上编码用于随时间改变关系的INSERT和DELETE语句的序列。 它们还会随着时间的推移公开有关关系中行的演变的元数据。 例如:添加或撤消哪些行,实现行的处理时间以及给定事件时间间隔的行的修订索引。
If dealing exclusively in TVRs, as recommended above, rendering a changelog stream of a TVR is primarily needed when materializing a stream-oriented view of that TVR for storage, transmission, or introspection (in particular, for inspecting metadata about the stream such as whether a change was additive or retractive). Unlike other approaches which treat stream changelogs as wholly different objects from relations (and the primary construct for dealing with relations over time), we propose representing the changelog as simply another time-varying relation. In that way, it can be operated on using the same machinery as a normal relation. Furthermore, it remains possible to declaratively convert the changelog stream view back into the original TVR using standard SQL (no special operators needed), while also supporting the materialization delays described next.
如果按照上面的建议专门处理TVR,则在实现TVR的面向流的视图以进行存储,传输或内省(特别是用于检查关于流的元数据,例如是否)时,主要需要呈现TVR的更改日志流。 变化是加性或回缩的)。 与将流变更日志视为完全不同的关系(以及随时间处理关系的主要结构)的其他方法不同,我们建议将变更日志表示为另一个时变关系。 以这种方式,它可以使用与正常关系相同的机器进行操作。 此外,仍然可以使用标准SQL(不需要特殊操作符)以声明方式将changelog流视图转换回原始TVR,同时还支持下面描述的实现延迟。
3.3.2 Materialization Delay.
By modeling input tables and streams as time-varying relations, and the output of a query as a resulting time-varying relation, it may seem natural to define a query’s output as instantaneously changing to reflect any new input. But as an implementation strategy, this is woefully inefficient, producing an enormous volume of irrelevant updates for consumers that are only interested in final results. Even if a consumer is prepared for speculative non-final results, there is likely a maximum frequency that is useful. For example, for a real-time dashboard viewed by a human operator, updates on the order of second are probably sufficient. For top-level queries that are stored or transmitted for external consumption, how frequently and why output materialization occurs is fundamental business logic.
通过将输入表和流建模为时变关系,并将查询的输出建模为结果时变关系,将查询的输出定义为瞬时更改以反映任何新输入似乎很自然。 但作为一种实施策略,这种效率非常低,为消费者提供了大量无关的更新,这些消息只对最终结果感兴趣。 即使消费者已经为投机性非最终结果做好准备,也可能存在最有用的频率。 例如,对于由操作员查看的实时仪表板,大约二阶的更新可能就足够了。 对于存储或传输以供外部使用的顶级查询,输出实现的频率和原因是基本的业务逻辑。
There are undoubtedly many interesting ways to specify when materialization is desired. In Section 6.5 we make a concrete proposal based on experience with real-world use cases. But what is important is that the user has some way to express their requirements.
毫无疑问,有许多有趣的方法可以指明何时需要实现。 在6.5节中,我们根据对实际用例的经验提出了具体的建议。 但重要的是用户可以通过某种方式表达他们的要求。
4 A MOTIVATING EXAMPLE
To illustrate the concepts in Section 3, this section examines a concrete example query from the streaming SQL literature. We show how the concepts are used in the query and then walk through its semantics on realistic input.
为了说明第3节中的概念,本节将从流式SQL文献中检查具体的示例查询。 我们将展示如何在查询中使用这些概念,然后在实际输入中查看其语义。
The following example is from the NEXMark benchmark[38] which was designed to measure the performance of stream query systems. The NEXMark benchmark extends the XMark benchmark [35] and models an online auction platform where users can start auctions for items and bid on items. The NEXMark data model consists of three streams, Person, Auction, and Bid, and a static Category table that holds details about items.
以下示例来自NEXMark基准[38],该基准旨在测量流查询系统的性能。 NEXMark基准扩展了XMark基准[35],并建立了一个在线拍卖*台,用户可以开始拍卖物品并对物品进行投标。 NEXMark数据模型由三个流组成:Person,Auction和Bid,以及一个包含项目详细信息的静态Category表。
From the NEXMark benchmark we chose Query 7, defined as: "Query 7 monitors the highest price items currently on auction. Every ten minutes, this query returns the highest bid (and associated itemid) in the most recent ten minutes." [38]. This is a continuously evaluated query which consumes a stream of bids as input and produces as output a stream of aggregates computed from finite windows of the input.
在NEXMark基准测试中,我们选择了查询7,定义为:“查询7监控当前拍卖的最高价格项目。每隔十分钟,此查询将返回最*十分钟内的最高出价(以及相关的itemid)。”[38]。 这是一个连续评估的查询,它使用一个出价流作为输入,并产生一个从输入的有限窗口计算出的聚合流作为输出。
Before we show a solution based on plain SQL, we present a variant [17] built with CQL [8] to define the semantics of Query 7:
在我们展示基于纯SQL的解决方案之前,我们提出了一个用CQL [8]构建的变体[17]来定义Query 7的语义:

Every ten minutes, the query processes the bids of the previous ten minutes. It computes the highest price of the last ten minutes (subquery) and uses the value to select the highest bid of the last ten minutes. The result is appended to a stream. We won’t delve into the details of CQL’s dialect, but to note some aspects which we will not reproduce in our proposal:
每隔十分钟,查询将处理前十分钟的出价。 它计算最后十分钟(子查询)的最高价格,并使用该值选择过去十分钟的最高出价。 结果将附加到流中。 我们不会深入研究CQL方言的细节,但要注意我们在提案中不会重现的一些方面:
CQL makes explicit the concept of streams and relations, providing operators to convert a stream into a relation (RANGE in our example) and operators to convert a relation into a stream (Rstream in our example). Our approach is based on the single concept of a time-varying relation and does not strictly require conversion operators.
CQL明确了流和关系的概念,提供运算符将流转换为关系(在我们的示例中为RANGE)和运算符以将关系转换为流(在我们的示例中为Rstream)。 我们的方法基于时变关系的单一概念,并不严格要求转换运算符。
Time is implicit; the grouping into ten minute windows depends on timestamps that are attached to rows by the underlying stream as metadata. As discussed in Section 3.2, STREAM supports out-of-order timestamps by buffering and feeding to CQL in order so intervals of event time always correspond to contiguous sections of the stream. Our approach is to process out-of-order data directly by making event timestamps explicit and leveraging watermarks to reason about input completeness.
时间是隐含的; 分组为十分钟窗口取决于底层流作为元数据附加到行的时间戳。 如3.2节所述,STREAM通过缓冲和馈送到CQL来支持无序时间戳,因此事件时间间隔始终对应于流的连续部分。 我们的方法是通过明确事件时间戳并利用水印来推断输入完整性来直接处理无序数据。
Time moves in lock step for the whole query. There is no explicit condition that the window in the subquery corresponds to the window in the main query. We make this relationship explicit via a join condition.
时间在整个查询的锁定步骤中移动。 没有明确的条件,子查询中的窗口对应于主查询中的窗口。 我们通过连接条件使这种关系显式化。
In contrast, here is Query 7 specified with our proposed extensions to standard SQL.
相反,这里是我们建议的标准SQL扩展指定的查询7。
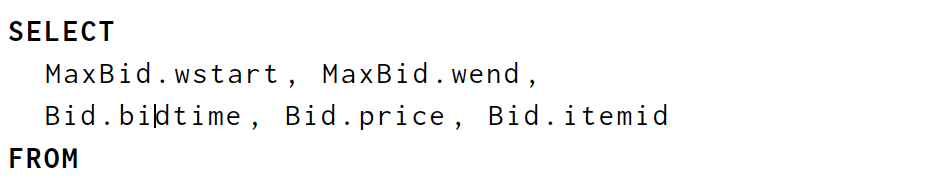

This query computes the same result, but does so using our proposed extensions to standard SQL (as well as SQL standard features from 2016). Noteworthy points:
此查询计算相同的结果,但使用我们建议的标准SQL扩展(以及2016年的SQL标准功能)。 值得注意的要点:
The column bidtime holds the time at which a bid occurred. In contrast to the prior query, timestamps are explicit data. Rows in the Bid stream do not arrive in order of bidtime.
列出价时间保留出价的时间。 与先前的查询相反,时间戳是显式数据。 出价流中的行未按出价时间顺序到达。
The Bid stream is presumed to have a watermark, as described in Section 3.2, estimating completeness of BidTime as a lower bound on future timestamps in the bidtime column. Note that the requirement does not affect the basic semantics of the query. The same query can be evaluated without watermarks over a table that was recorded from the bid stream, yielding the same result.
如第3.2节所述,Bid流被假定为具有水印,将BidTime的完整性估计为bidtime列中未来时间戳的下限。 请注意,该要求不会影响查询的基本语义。 可以在从出价流中记录的表上没有水印的情况下评估相同的查询,从而产生相同的结果。
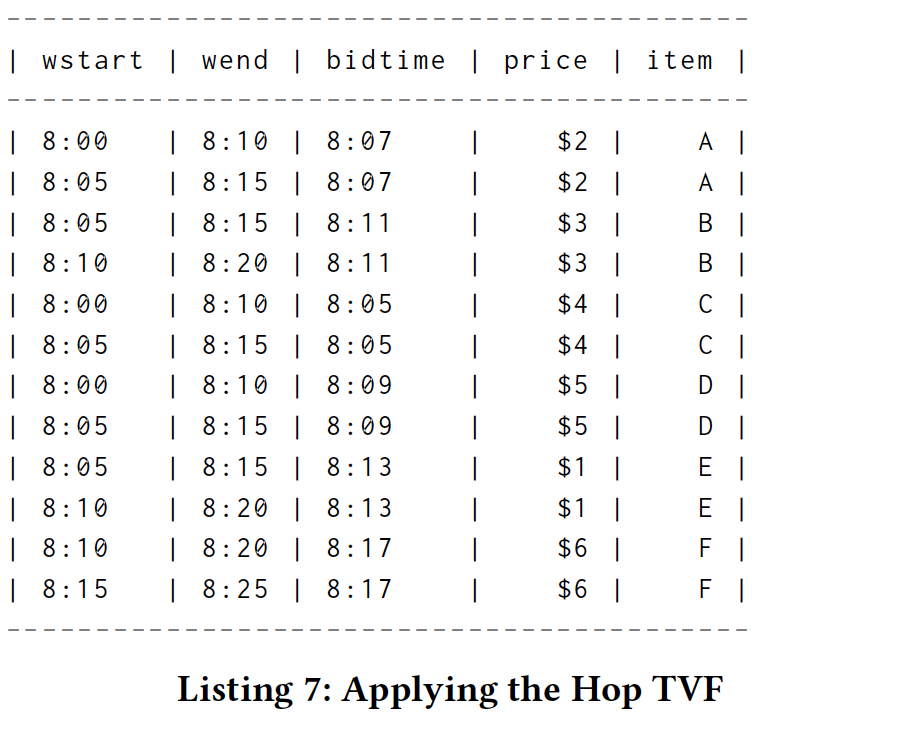
Tumble is a table-valued function [1] which assigns each row in the bid stream to the 10-minute interval containing bidtime. The output table TumbleBid has all the same columns as Bid plus two additional columns wstart and wend, which repesent the start and end of the tumbling window interval, respectively. The wend column contains timestamps and has an associated watermark that estimates completeness of TumbleBid relative to wend.
Tumble是一个表值函数[1],它将出价流中的每一行分配给包含出价时间的10分钟间隔。 输出表TumbleBid具有与Bid相同的列以及两个附加列wstart和wend,它们分别重复翻滚窗口间隔的开始和结束。 wend列包含时间戳,并且具有相关的水印,用于估计TumbleBid相对于wend的完整性。
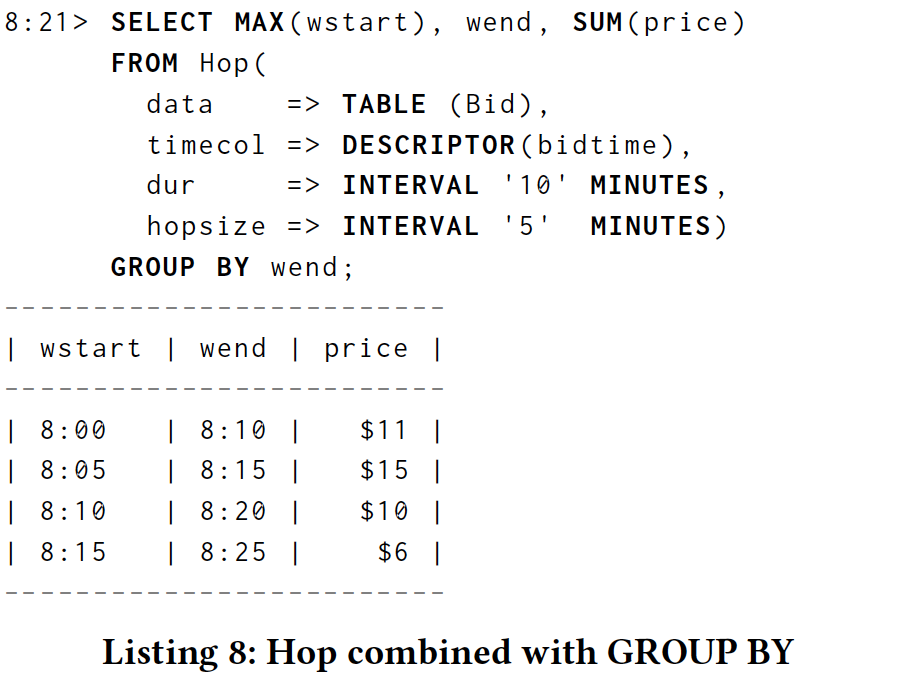
The GROUP BY TumbleBid.wend clause is where the watermark is used. Because the watermark provides a lower bound on not-yet-seen values for wend, it allows an implementation to reason about when a particular grouping of inputs is complete. This fact can be used to delay materialization of results until aggregates are known complete, or to provide metadata indicating as much.
GROUP BY TumbleBid.wend子句是使用水印的地方。 因为水印为wend的尚未看到的值提供了下限,所以它允许实现来推断特定的输入分组何时完成。 此事实可用于延迟结果的实现,直到已知完成聚合,或提供指示尽可能多的元数据。
As the Bid relation evolves over time, with newevents being added, the relation defined by this query also evolves. This is identical to instantaneous view semantics. We have not used the advanced feature of managing the materialization of this query.
随着Bid关系随着时间的推移而发展,添加了newevents,此查询定义的关系也会发展。 这与瞬时视图语义相同。 我们还没有使用管理此查询的具体化的高级功能。
Now let us apply this query to a concrete dataset to illustrate how it might be executed. As we’re interested in streaming data, we care not only about the data involved, but also when the system becomes aware of them (processing time), as well as where in event time they occurred, and the system’s own understanding of input completeness in the event-time domain (i.e., the watermark) over time. The example data set we will use is the following:
现在让我们将此查询应用于具体数据集,以说明如何执行该查询。 由于我们对流数据感兴趣,我们不仅关心所涉及的数据,还关注系统何时意识到它们(处理时间),以及事件发生的时间,以及系统自身对输入完整性的理解 随着时间的推移在事件时间域(即水印)中。 我们将使用的示例数据集如下:
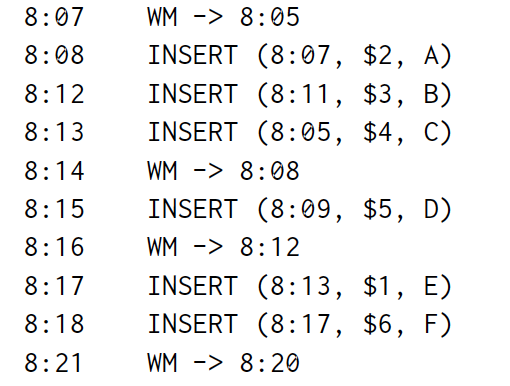
Here, the left column of times includes the processing times at which events occur within the system. The right column describes the events themselves, which are either the watermark advancing to a point in event time or a (bidtime, price, item) tuple being inserted into the stream.
- advancing [ədˈvænsɪŋ] adj. 年事渐高 v. (为了进攻、威胁等)前进,行进;(知识、技术等)发展,进步;促进;推动
这里,左列时间包括系统内发生事件的处理时间。 右栏描述事件本身,它们是前进到事件时间点的水印或插入到流中的(bidtime,price,item)元组。
The example SQL query in Listing 2 would yield the following results when executed on this dataset at time 8:21 (eliding most of the query body for brevity):
清单2中的示例SQL查询在8:21时在此数据集上执行时会产生以下结果(为了简洁,省略了大部分查询主体):
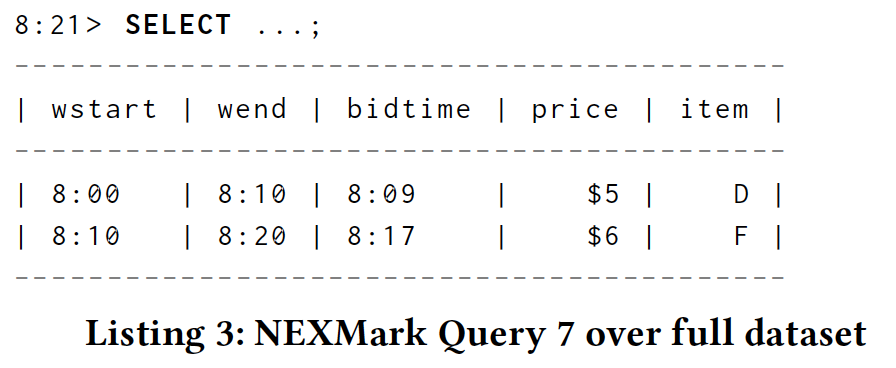
This is effectively the same output that would have been provided by the original CQL query, with the addition of explicit window start, window end, and event occurrence timestamps.
这实际上是原始CQL查询提供的相同输出,添加了显式窗口开始,窗口结束和事件发生时间戳。
However, this is a table view of the data set capturing a point-in-time view of the entire relation at query time, not a stream view. If we were to have executed this query earlier in processing time, say at 8:13, it would have looked very different due to the fact that only half of the input data had arrived by that time:
但是,这是捕获查询时整个关系的时间点视图的数据集的表视图,而不是流视图。 如果我们在处理时间早些时候执行了这个查询,比如在8:13,那么由于到那时只有一半的输入数据到达,它看起来会有很大不同:

In Section 6, we’ll describe how to write a query that creates a stream of output matching that from the original CQL query, and also why our approach is more flexible overall.
在第6节中,我们将描述如何编写一个查询,该查询创建与原始CQL查询匹配的输出流,以及为什么我们的方法总体上更灵活。
5 LESSONS LEARNED IN PRACTICE
Our proposed SQL extensions are informed by prior art and related work, and derived from experience in working on Apache Calcite, Flink, and Beam – open source frameworks with wide adoption across the industry and by other open source frameworks.
我们提出的SQL扩展由现有技术和相关工作提供信息,并源自Apache Calcite,Flink和Beam的工作经验 - 开源框架在整个行业和其他开源框架中得到广泛采用。
In Appendix B, we describe the general architectural properties of these three frameworks, the breadth of their adoption, and streaming implementations that exist today. Though the implementations thus far fall short of the full proposal we make in Section 6, they are a step in the right direction and have yielded useful lessons which have informed its evolution. Here we summarize those lessons:
在附录B中,我们描述了这三个框架的一般架构属性,它们的采用范围以及当前存在的流实现。 虽然到目前为止的实施还没有达到我们在第6节中提出的完整提案,但它们是朝着正确方向迈出的一步,并且已经产生了有用的经验教训,这些经验告诉了它的发展。 在这里,我们总结了这些经验:
Some operations only work (efficiently) on watermarked event time attributes. Whether performing an aggregation on behalf of the user or executing overtly stateful business logic, an implementer must have a way to maintain finite state over infinite input. Event time semantics, particularly watermarks, are critical. State for an ongoing aggregation or stateful operator can be freed when the watermark is sufficiently advanced that the state won’t be accessed again.
某些操作仅对水印事件时间属性有效(高效)。 无论是代表用户执行聚合还是执行公开的有状态业务逻辑,实现者都必须有办法在无限输入上维持有限状态。 事件时间语义,特别是水印,是至关重要的。 当水印足够先进以至于不再访问状态时,可以释放正在进行的聚合或有状态运算符的状态。
Operators may erase watermark alignment of event time attributes. Event time processing requires that event timestamps are aligned with watermarks. Since event timestamps are exposed as regular attributes, they can be referenced in arbitrary expressions. Depending on the expression, the result may or may not remain aligned with the watermarks; these cases need to be taken into account during query planning. In some cases it is possible to preserve watermark alignment by adjusting the watermarks, and in others an event time attribute loses its special property.
操作符可以擦除事件时间属性的水印对齐。 事件时间处理要求事件时间戳与水印对齐。 由于事件时间戳作为常规属性公开,因此可以在任意表达式中引用它们。 根据表达式,结果可能会或可能不会与水印保持一致; 在查询计划期间需要考虑这些情况。 在某些情况下,可以通过调整水印来保持水印对齐,而在其他情况下,事件时间属性会失去其特殊属性。
Time-varying relations might have more than one event time attribute. Most stream processing systems that feature event time processing only support a single event time attribute with watermarks. When joining two TVRs it can happen that the event time attributes of both input TVRs are preserved in the resulting TVR. One approach to address this situation is to "hold-back" the watermark such that all event time attributes remain aligned.
时变关系可能具有多个事件时间属性。 大多数具有事件时间处理功能的流处理系统仅支持带有水印的单个事件时间属性。 当连接两个TVR时,可能发生两个输入TVR的事件时间属性被保留在得到的TVR中。 解决这种情况的一种方法是“保持”水印,使得所有事件时间属性保持对齐。
Reasoning about what can be done with an event time attribute can be difficult for users. In order to define a query that can be efficiently executed using event time semantics and reasoning, event time attributes need to be used at specific positions in certain clauses, for instance as an ORDER BY attribute in an OVER clause. These positions are not always easy to spot and failing to use event time attributes correctly easily leads to very expensive execution plans with undesirable semantics.
关于用事件时间属性可以做什么的推理对于用户来说可能是困难的。 为了定义可以使用事件时间语义和推理有效执行的查询,需要在某些子句中的特定位置使用事件时间属性,例如作为OVER子句中的ORDER BY属性。 这些位置并不总是容易发现,并且未能正确使用事件时间属性容易导致具有不期望语义的非常昂贵的执行计划。
Reasoning about the size of query state is sometimes a necessary evil. Ideally, users should not need to worry about internals when using SQL. However, when consuming unbounded input user intervention is useful or sometimes necessary. So we need to consider what metadata the user needs to provide (active interval for attribute inserts or updates, e.g. sessionId) and also how to give the user feedback about the state being consumed, relating the physical computation back to their query.
关于查询状态的大小的推理有时是必要的恶。 理想情况下,用户在使用SQL时不必担心内部问题。 但是,当消费无限制输入时,用户干预是有用的或有时是必要的。 因此,我们需要考虑用户需要提供哪些元数据(属性插入或更新的活动间隔,例如sessionId),以及如何向用户提供有关正在消耗的状态的反馈,将物理计算与其查询相关联。
It is useful for users to distinguish between streaming and materializing operators. In Flink and Beam, users need to reason explicitly about which operators may produce updating results, which operators can consume updating results, and the effect of operators on event time attributes. These low-level considerations are inappropriate for SQL and have no natural place in relational semantics; we need materialization control extensions that work well with SQL.
用户区分流式传输和物化操作符非常有用。 在Flink和Beam中,用户需要明确地说明哪些操作符可能产生更新结果,哪些操作符可以使用更新结果,以及操作符对事件时间属性的影响。 这些低级别的考虑因素不适合SQL,并且在关系语义中没有自然的位置; 我们需要适用于SQL的物化控制扩展。
Torrents of updates: For a high-throughput stream, it is very expensive to issue updates continually for all derived values. Through materialization controls in Flink and Beam, this can be limited to fewer and more relevant updates.
更新的浪潮:对于高吞吐量流,为所有派生值不断发布更新是非常昂贵的。 通过Flink和Beam中的物化控制,这可以限于更少和更相关的更新。
6 EXTENDING THE SQL STANDARD
Work presented here is part of an initial effort to standardize streaming SQL and define our emerging position on its features. In this section, we will first briefly discuss some ways in which SQL already supports streaming, after which we will present our proposed streaming extensions.
这里介绍的工作是标准化流SQL的初步工作的一部分,并定义了我们在其功能上的新兴位置。 在本节中,我们将首先简要讨论SQL已经支持流式传输的一些方法,之后我们将介绍我们提出的流式传输扩展。
6.1 Existing Support for Streaming in SQL
SQL as it exists today already includes support for a number of streaming related approaches. Though not sufficient to cover all relevant streaming use cases, they provide a good foundation upon which to build, notably:
如今存在的SQL已经包括对许多流相关方法的支持。 虽然不足以涵盖所有相关的流媒体用例,但它们为构建提供了良好的基础,特别是:
Queries are on table snapshots: As a classical SQL table evolves, queries can execute on their current contents. In this way, SQL already plays nicely with relations over time, albeit only in the context of static snapshots.
查询在表快照上:随着经典SQL表的发展,查询可以对其当前内容执行。 通过这种方式,SQL已经可以很好地处理关系,尽管只是在静态快照的上下文中。
Materialized Views: Views (semantically) and materialized views (physically) map a query pointwise over a TVR. At any moment, the view is the result of a query applied to its inputs at that moment. This is an extremely useful initial step in stream processing.
物化视图:视图(语义上)和物化视图(物理上)在TVR上逐点映射查询。 在任何时候,视图都是在那一刻应用于其输入的查询的结果。 这是流处理中非常有用的初始步骤。
Temporal tables: Temporal tables embody the idea of a time-varying relation, and provide the ability to query snapshots of the table from arbitrary points of time in the past via AS OF SYSTEM TIME operators.
时态表:时态表体现了时变关系的概念,并提供了通过AS OF SYSTEM TIME运算符从过去的任意时间点查询表的快照的能力。
MATCH RECOGNIZE: The MATCH_RECOGNIZE clause was added with SQL:2016 [1]. When combined with event time semantics, this extension is highly relevant to streaming SQL as it enables a new class of stream processing use case, namely complex event processing and pattern matching [18].
MATCH RECOGNIZE:MATCH_RECOGNIZE子句添加了SQL:2016 [1]。 当与事件时间语义结合使用时,此扩展与流式SQL高度相关,因为它启用了一类新的流处理用例,即复杂事件处理和模式匹配[18]。
6.2 Time-Varying Relations, Event Time Columns, and Watermarks
There are no extensions necessary to support time-varying relations. Relational operators as they exist today already map one time-varying relation to another naturally. 1 To enable event time semantics in SQL, a relation may include in its schema columns that contain event timestamps. Query execution requires knowledge of which column(s) correspond to event timestamps to associate them with watermarks, described below. The metadata that a column contains event timestamps is to be stored as part of or alongside the schema. The timestamps themselves are used in a query like any other data, in contrast to CQL where timestamps themselves are metadata and KSQL which implicitly references event time attributes that are declared with the schema.
没有必要扩展来支持时变关系。 如今存在的关系运算符已经自然地将一个时变关系映射到另一个。 1要在SQL中启用事件时间语义,关系可以在其架构中包含包含事件时间戳的列。 查询执行需要知道哪些列对应于事件时间戳以将它们与水印相关联,如下所述。 列包含事件时间戳的元数据将作为模式的一部分存储或与模式一起存储。 时间戳本身在任何其他数据的查询中使用,与时间戳本身是元数据的CQL和隐式引用用模式声明的事件时间属性的KSQL相反。
To support unbounded use cases, watermarks are also available as semantic inputs to standard SQL operators. This expands the universe of relational operators to include operators that are not pointwise with respect to time, as in Section 6.5.2. For example, rows may be added to an output relation based only on the advancement of the watermark, even when no rows have changed in the input relation(s).
为了支持无限用例,水印也可用作标准SQL运算符的语义输入。 这扩展了关系运算符的范围,以包括与时间无关的运算符,如第6.5.2节所述。 例如,即使在输入关系中没有行改变时,也可以仅基于水印的推进将行添加到输出关系。
Extension 1 (Watermarked event time column). An event time column in a relation is a distinguished column of type TIMESTAMP with an associated watermark. The watermark associated with an event time column is maintained by the system as time-varying metadata for the relation as a whole and provides a lower bound on event timestamps that may be added to the column.
扩展1(水印事件时间列)。 关系中的事件时间列是具有相关水印的TIMESTAMP类型的区分列。 与事件时间列相关联的水印由系统维护为整个关系的时变元数据,并提供可添加到列的事件时间戳的下限。
6.3 Grouping on Event Timestamps
When processing over an unbounded stream, an aggregate projected in a query of the form SELECT ... GROUP BY ... is complete when it is known that no more rows will contribute to the aggregate. Without extensions, it is never known whether there may be more inputs that contribute to a grouping. Under event time semantics, the watermark gives a measure of completeness and can determine when a grouping is complete based on event time columns. This corresponds to the now-widespread notion of event-time windowing. We can adapt this to SQL by leveraging event time columns and watermarks.
当处理无界流时,当已知不再有行将对聚合有贡献时,在SELECT ... GROUP BY ...形式的查询中投影的聚合完成。 如果没有扩展,就不可能知道是否有更多的输入有助于分组。 在事件时间语义下,水印给出了完整性的度量,并且可以基于事件时间列确定分组何时完成。 这对应于现在普遍存在的事件时间窗口的概念。 我们可以通过利用事件时间列和水印来使其适应SQL。
Extension 2 (Grouping on event timestamps). When a GROUP BY clause contains a grouping key that is an event time column, any grouping where the key is less than the watermark for that column is declared complete, and further inputs that would contribute to that group are dropped (in practice, a configurable amount of allowed lateness is often needed, but such a mechanism is beyond the scope of this paper; for more details see Chapter 2 of [6]) Every GROUP BY clause with an unbounded input is required to include at least one event-time column as a grouping key.
扩展2(对事件时间戳进行分组)。 当GROUP BY子句包含作为事件时间列的分组键时,任何键小于该列水印的分组都将被声明为完成,并且将删除对该组有贡献的其他输入(实际上,可配置) 通常需要延迟允许的数量,但是这种机制超出了本文的范围;更多细节见[6]的第2章)每个具有无界输入的GROUP BY子句都必须包含至少一个事件时间列 作为分组键。
6.4 Event-Time Windowing Functions
It is rare to group by an event time column that contains original event timestamps unless you are trying to find simultaneous events. Instead, event timestamps are usually mapped to a distinguished end time after which the grouping is completed. In the example from Section 4, bid timestamps are mapped to the end of the ten minute interval that contains them.We propose adding built-in table-valued functions that augment a relation with additional event timestamp columns for these common use cases (while leaving the door open for additional built-in or custom TVFs in the future).
除非您尝试查找同时发生的事件,否则很少按包含原始事件时间戳的事件时间列进行分组。 相反,事件时间戳通常映射到分组完成之后的标识结束时间。 在第4节的示例中,出价时间戳被映射到包含它们的十分钟间隔的末尾。我们建议添加内置表值函数,以增加与这些常见用例的附加事件时间戳列的关系(离开时) 为未来的其他内置或定制TVF敞开大门。
Extension 3 (Event-time windowing functions). Add (as a starting point) built-in table-valued functions Tumble and Hop which take a relation and event time column descriptor as input and return a relation with additional event-time interval columns as output, and establish a convention for the eventtime interval column names.
扩展3(事件时间窗口函数)。 添加(作为起点)内置表值函数Tumble和Hop,它将关系和事件时间列描述符作为输入并返回与附加事件 - 时间间隔列的关系作为输出,并为事件时间间隔建立约定 列名。
The invocation and semantics of Tumble and Hop are below. There are other useful event time windowing functions used in streaming applications which the SQL standard may consider adding, but these two are extremely common and illustrative. For brevity, we show abbreviated function signatures and describe the parameters in prose, then illustrate with example invocations.
Tumble和Hop的调用和语义如下。 在SQL应用程序可能会考虑添加的流应用程序中还有其他有用的事件时间窗口函数,但这两个函数非常常见且具有说明性。 为简洁起见,我们显示缩写的函数签名并描述散文中的参数,然后通过示例调用进行说明。
6.4.1 Tumble.
Tumbling (or "fixed") windows partition event time into equally spaced disjoint covering intervals. Tumble takes three required parameters and one optional parameter:
翻滚(或“固定”)窗口将事件时间划分为等间隔的不相交覆盖间隔。 Tumble需要三个必需参数和一个可选参数:
Tumble (data , timecol , dur , [ offset ])
- data is a table parameter that can be any relation with an event time column.
- timecol is a column descriptor indicating which event time column of data should be mapped to tumbling windows.
- dur is a duration specifying the width of the tumbling windows.
- offset (optional) specifies that the tumbling should begin from an instant other than the standard beginning of the epoch.
The return value of Tumble is a relation that includes all columns of data as well as additional event time columns wstart and wend. Here is an example invocation on the Bid table from the example in Section 4:
Tumble的返回值是一个包含所有数据列以及附加事件时间列wstart和wend的关系。 以下是第4节中示例的Bid表上的示例调用:
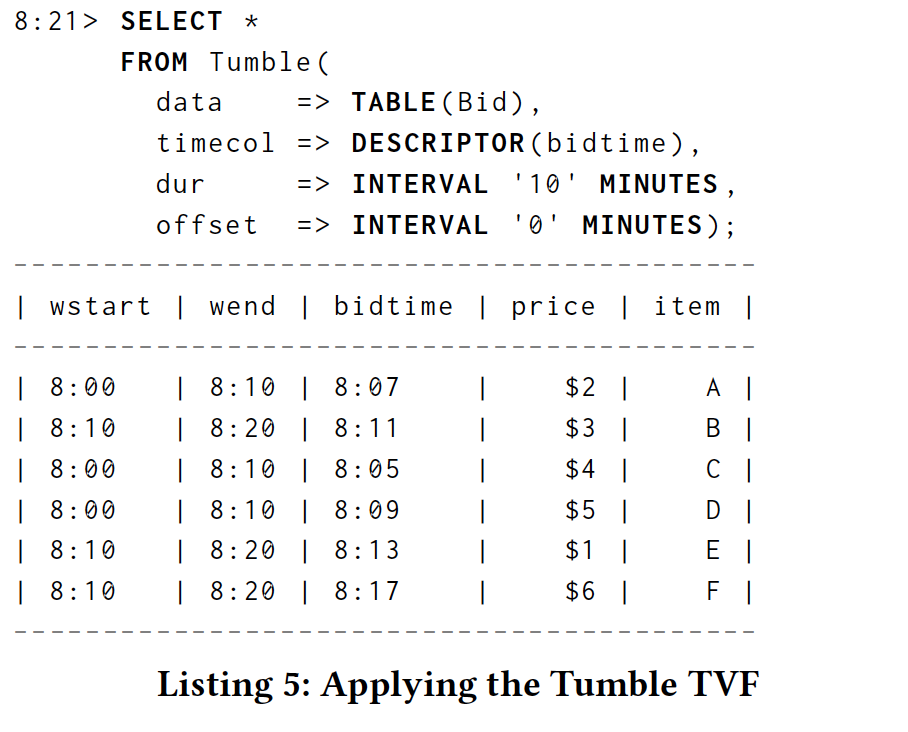
Users can group by wstart or wend; both result in the same groupings and, assuming ideal watermark propagation, the groupings reach completeness at the same time. For example, grouping by wend:
用户可以通过wstart或wend进行分组; 两者都产生相同的分组,并且假设理想的水印传播,分组同时达到完整性。 例如,按wend分组:

6.4.2 Hop.
Hopping (or "sliding") event time windows place intervals of a fixed size evenly spaced across event time. Hop takes four required parameters and one optional parameter. All parameters are analogous to those for Tumble except for hopsize, which specifies the duration between the starting points (and endpoints) of the hopping windows, allowing for overlapping windows (hopsize < dur , common) or gaps in the data (hopsize > dur , rarely useful).
跳跃(或“滑动”)事件时间窗口在事件时间内均匀地间隔固定大小的间隔。 Hop需要四个必需参数和一个可选参数。 除了hopsize之外,所有参数都类似于Tumble的参数,hopsize指定跳跃窗口的起点(和端点)之间的持续时间,允许重叠窗口(hopsize <dur,common)或数据中的间隙(hopsize> dur, 很少有用)。
The return value of Hop is a relation that includes all columns of data as well as additional event time columns wstart and wend. Here is an example invocation on the Bid table from the example in Section 4:
Hop的返回值是包含所有数据列以及附加事件时间列wstart和wend的关系。 以下是第4节中示例的Bid表上的示例调用:

Users can group by wstart or wend with the same effect, as with tumbling windows. For example:
用户可以按开头或结尾进行分组,效果与翻滚窗口相同。 例如:
Using table-valued functions improves on the current state of implementations in the following ways:
使用表值函数可以通过以下方式改进当前的实现状态:
GROUP BY is truly a grouping of rows according to a column’s value. In Calcite, Beam, and Flink, GROUP BY HOP(...) violates relational semantics by causing multiple input rows.
GROUP BY根据列的值真正是一组行。 在Calcite,Beam和Flink中,GROUP BY HOP(...)通过引起多个输入行来违反关系语义。
A more uniform notation for all window functions. The near-trivial Tumble has the same general form as the input-expanding Hop, and using a table-valued functions allows adding a wide variety of more complex functionality (such as calendar windows or sessionization) with a similar look-and-feel.
所有窗口函数的统一表示法。 *乎*凡的Tumble具有与输入扩展Hop相同的一般形式,并且使用表值函数允许添加具有类似外观的各种更复杂的功能(例如日历窗口或会话化)。
Engines have flexibility in howthey implement these table-valued functions. Rows in the output may appear and disappear as appropriate according to downstream materialization requirements.
引擎在如何实现这些表值函数方面具有灵活性。 根据下游物化要求,输出中的行可能会出现和消失。
6.5 Materialization Controls
The last piece of our proposal centers around materialization controls, allowing users flexibility in shaping how and when the rows in their TVRs are materialized over time.
我们的最后一条建议围绕物化控制,允许用户灵活地塑造TVR中的行如何以及何时实现。
6.5.1 Stream Materialization.
The how aspect of materialization centers around the choice of materializing a TVR as a table or stream. The long-standing default for relations has been to materialize them as tables. And since this approach is completely compatible with the idea of swapping pointin-time relations with time-varying relations, no changes around materializing a table are necessary. However, in certain situations, materializing a stream-oriented changelog view of the TVR is desirable.
物化的方面主要围绕将TVR实现为表格或流的选择。 关系的长期默认一直是将它们作为表格实现。 并且由于这种方法与使用时变关系交换点时间关系的想法完全兼容,因此不需要实现表的实现。 然而,在某些情况下,实现TVR的面向流的更改日志视图是可取的。
In these cases, we require some way to signal to the system that the changelog of the relation should be materialized.We propose the use of a new EMIT STREAM modifier on a query to do this. Recall our original motivating query results from Listing 3, which rendered a table view of our example query. By adding EMIT STREAM at the top-level, we materialize the stream changelog for the TVR instead of a point-in-time snapshot of the relation itself:
在这些情况下,我们需要某种方式向系统发出关于应该实现关系的更改日志的信号。我们建议在查询中使用新的EMIT STREAM修饰符来执行此操作。 回想一下清单3中的原始激励查询结果,它们呈现了我们的示例查询的表格视图。 通过在顶层添加EMIT STREAM,我们实现了TVR的流更改日志,而不是关系本身的时间点快照:
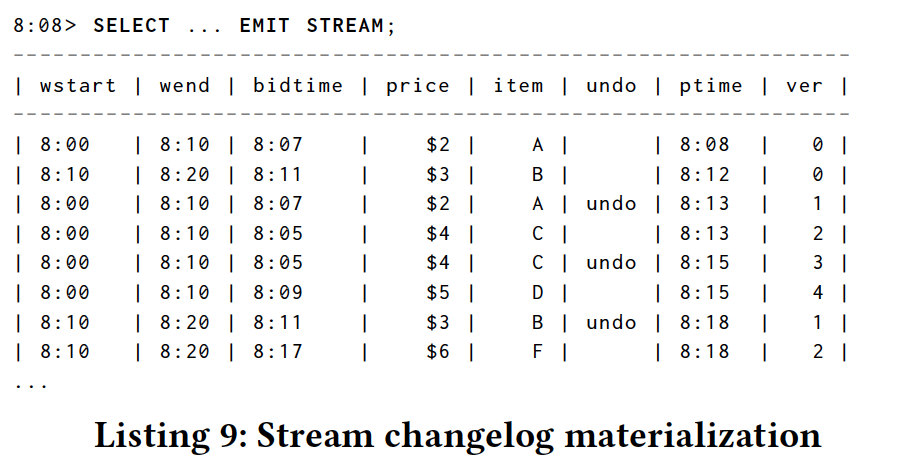
Note that there are a number of additional columns included in the STREAM version:
请注意,STREAM版本中包含许多其他列:
- undo: whether the row is a retraction of a previous row or not.
- undo:该行是否是前一行的缩进。
- ptime: the processing time offset of the row in the changelog.
- ptime:更改日志中行的处理时间偏移量。
- ver: a sequence number that versions this row with respect to other rows corresponding to different revisions of the same event-time window.
- ver:一个序列号,它针对与同一事件时间窗口的不同修订版对应的其他行对该行进行版本控制。
A changelog only has multiple revisions to a row when there is a aggregation present in the query resulting in changes to the row over time.
当查询中存在聚合时,更改日志仅对行进行多次修订,从而导致行随时间发生更改。
Extension 4 (Stream Materialization). EMIT STREAM results in a time-varying relation representing changes to the classical result of the query. In addition to the schema of the classical result, the change stream includes columns indicating: whether or not the row is a retraction of a previous row, the changelog processing time offset of the row, a sequence number relative to other changes to the same event time grouping.
扩展4(流实现)。 EMIT STREAM导致时变关系,表示查询的经典结果的变化。 除了经典结果的模式之外,更改流还包括指示:行是否是前一行的缩回,行的更改日志处理时间偏移,相对于同一事件的其他更改的序列号的列时间分组。
One could imagine other options, such as allowing materialization of deltas rather than aggregates, or even entire relations a la CQL’s Rstream. These could be specified with additional modifiers, but are beyond the scope of this paper.
人们可以想象其他选择,例如允许实现增量而不是聚合,甚至整个关系都是CQL的Rstream。 这些可以使用其他修饰符指定,但超出了本文的范围。
As far as equaling the output of the original CQL query, the STREAM keyword is a step in the right direction, but it’s clearly more verbose, capturing the full evolution of the highest bidders for the given 10-minute event time windows as data arrive, whereas the CQL version provided only a single answer per 10-minute window once the input data for that window was complete. To tune the stream output to match the behavior of CQL (but accommodating out-of-order input data), we need to support materialization delay.
至于等同于原始CQL查询的输出,STREAM关键字是朝着正确方向迈出的一步,但它显然更加冗长,随着数据到达,捕获给定10分钟事件时间窗口的最高出价者的完全演变, 而一旦该窗口的输入数据完成,CQL版本每10分钟窗口只提供一个答案。 要调整流输出以匹配CQL的行为(但是容纳无序输入数据),我们需要支持实现延迟。
6.5.2 Materialization Delay.
The when aspect of materialization centers around the way relations evolve over time. The standard approach is on a record-by-record basis: as DML operations such as INSERT and DELETE are applied to a relation, those changes are immediately reflected. However, when dealing with aggregate changes in relations, it’s often beneficial to delay the materialization of an aggregate in some way. Over the years, we’ve observed two main categories of delayed materialization in common use: completeness delays and periodic delays.
物化的时间方面围绕着关系随时间演变的方式。 标准方法是逐个记录的:当INSERT和DELETE等DML操作应用于关系时,这些更改会立即反映出来。 但是,在处理关系中的聚合变化时,以某种方式延迟聚合的实现通常是有益的。 多年来,我们观察到两种主要的常见延迟物化类型:完整性延迟和周期性延迟。
Completeness delays: Event time windowing provides a means for slicing an unbounded relation into finite temporal chunks, and for use cases where eventual consistency of windowed aggregates is sufficient, no further extensions are required. However, some use cases dictate that aggregates only be materialized when their inputs are complete, such as queries for which partial results are too unstable to be of any use, such a query which determines if a numeric sum is even or odd. These still benefit from watermark-driven materialization even when consumed as a table.
完整性延迟:事件时间窗口提供了将无界关系切片为有限时间块的方法,对于窗口聚合的最终一致性足够的用例,不需要进一步扩展。 但是,一些用例规定聚合只有在输入完成时才能实现,例如部分结果太不稳定而无法使用的查询,这种查询确定数字和是偶数还是奇数。 即使作为表格消费,这些仍然受益于水印驱动的物化。
Recall again our query from Listing 4 where we queried the table version of our relation at 8:13. That query presented a partial result for each window, capturing the highest priced items for each tumbling window at that point in processing time. For use cases where presenting such partial results is undesirable, we propose the syntax EMIT AFTER WATERMARK to ensure the table view would only materialize rows whose input data were complete. In that way, our query at 8:13 would return an empty table:
再回想一下清单4中的查询,我们在8:13查询了关系的表格版本。 该查询为每个窗口显示了部分结果,捕获了处理时间中该点的每个翻滚窗口的最高价格项目。 对于不希望出现这种部分结果的用例,我们提出语法EMIT AFTER WATERMARK以确保表视图仅实现输入数据完整的行。 这样,我们在8:13的查询将返回一个空表:

If we were to query again at 8:16, once the watermark had passed the end of the first window, we’d see the final result for the first window, but still none for the second:
如果我们在8:16再次查询,一旦水印通过了第一个窗口的末尾,我们将看到第一个窗口的最终结果,但第二个窗口仍然没有:

And then if we queried again at 8:21, after the watermark had passed the end of the second window, we would finally have the final answers for both windows:
然后,如果我们在8:21再次查询,在水印通过第二个窗口结束后,我们最终会得到两个窗口的最终答案:
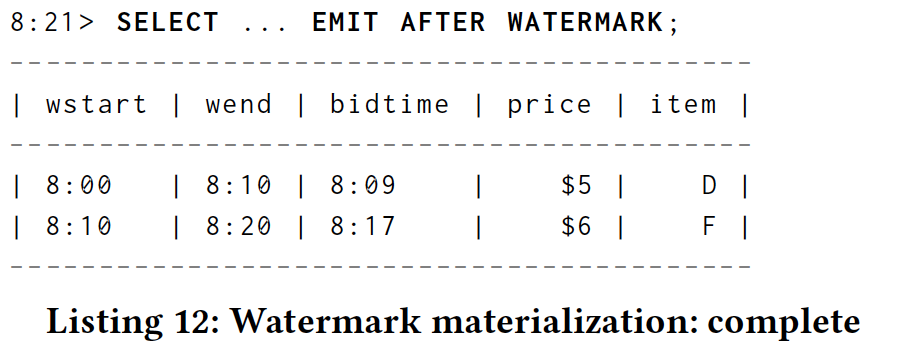
We also can use STREAM materialization to concisely observe the evolution of the result, which is analogous to what the original CQL query would produce:
我们还可以使用STREAM实现来简明地观察结果的演变,这类似于原始CQL查询将产生的:

Comparing this to the evolution of the streamed changelog in Section 6.5.1 illustrates the difference with AFTER WATERMARK:
将其与6.5.1节中流式更改日志的演变进行比较,说明了与AFTER WATERMARK的区别:
- There is exactly one row per window, each containing the final result.
- 每个窗口只有一行,每行包含最终结果。
- The ptime values no longer correspond to the arrival time of the max bid records, but instead the processing time at which the watermark advanced beyond the end of the given window.
- ptime值不再对应于最大出价记录的到达时间,而是对应于水印超出给定窗口结束的处理时间。
The most common example of delayed stream materialization is notification use cases, where polling the contents of an eventually consistent relation is infeasible. In this case, it’s more useful to consume the relation as a stream which contains only aggregates whose input data is known to be complete. This is the type of use case targeted by the original CQL top bids query.
延迟流实现的最常见示例是通知用例,其中轮询最终一致关系的内容是不可行的。 在这种情况下,将关系用作仅包含已知输入数据已完成的聚合的流更有用。 这是原始CQL最高出价查询所针对的用例类型。
Extension 5 (Materialization Delay: Completeness). When a query has an EMIT AFTER WATERMARK modifier, only complete rows from the results are materialized.
扩展5(具体化延迟:完整性)。 当查询具有EMIT AFTER WATERMARK修改器时,仅实现结果中的完整行。
Periodic delays: The second delayed materialization use case we care about revolves around managing the verbosity of an eventually consistent STREAM changelog. The default STREAM rendering, as we saw above, provides updates every time any row in the relation changes. For high volume streams, such a changelog can be quite verbose. In those cases, it is often desirable to limit how frequently aggregates in the relation are updated. To do so, we propose the addition of an AFTER DELAY modifier to the EMIT clause, which dictates a delay imposed on materialization after a change to a given aggregate occurs, for example:
定期延迟:我们关心的第二个延迟实现用例围绕管理最终一致的STREAM更改日志的详细程度。 如上所述,默认的STREAM呈现每次关系中的任何行发生更改时都会提供更新。 对于高容量流,这样的更改日志可能非常冗长。 在这些情况下,通常希望限制关系中聚合的更新频率。 为此,我们建议在EMIT子句中添加一个AFTER DELAY修饰符,该修饰符指示在更改给定聚合后发生的实现延迟,例如:

In this example, multiple updates for each of the windows are compressed together, each within a six-minute delay from the first change to the row.
在此示例中,每个窗口的多个更新被压缩在一起,每个更新在从第一次更改到行的六分钟延迟内。
Extension 6 (Periodic Materialization). When a query has EMIT AFTER DELAY d, rows are materialized with period d (instead of continuously).
扩展6(定期实现)。 当查询具有EMIT AFTER DELAY d时,将使用句点d(而不是连续)实现行。
It’s also possible to combine AFTER DELAY modifiers with AFTER WATERMARK modifiers to provide the early/on-time/late pattern [6] of repeated periodic updates for partial result rows, followed by a single on-time row, followed by repeated periodic updates for any late rows.
也可以将AFTER DELAY修改器与AFTER WATERMARK修改器结合使用,为部分结果行提供重复定期更新的早期/准时/后期模式[6],然后是单个准时行,然后重复定期更新 任何晚行。
Extension 7 (CombinedMaterialization Delay). When a query has EMIT AFTER DELAYd AND AFTER WATERMARK, rows are materialized with period d as well as when complete.
扩展7(CombinedMaterialization Delay)。 当查询具有EMIT AFTER DELAYd AND AFTER WATERMARK后,行具有句点d以及完成时的具体化。
7 SUMMARY
Streaming SQL is an exercise in manipulating relations over time. The large body of streaming SQL literature combined with recent efforts in the modern streaming community form a strong foundation for basic streaming semantics, but room for improvement remains in the dimensions of usability, flexibility, and robust event-time processing.We believe that the three contributions proposed in this paper, (1) pervasive use of time-varying relations, (2) robust event-time semantics support, and (3) materialization control can substantially improve the ease-of-use of streaming SQL. Moreover, they will broaden the menu of available operators to not only include the full suite of point-in-time relational operators available in standard SQL today, but also extend the capabilities of the language to operators that function over time to shape when and how relations evolve.
流式SQL是一种随着时间的推移操纵关系的练习。 大量的流式SQL文档与最*在现代流媒体社区中的努力相结合,形成了基本流式语义的坚实基础,但改进的空间仍然在于可用性,灵活性和强大的事件时间处理等方面。我们相信三者 本文提出的贡献,(1)普遍使用时变关系,(2)强大的事件时间语义支持,以及(3)物化控制可以大大提高流SQL的易用性。 此外,它们将扩展可用运算符的菜单,不仅包括当今标准SQL中提供的全套时间点关系运算符,还将语言的功能扩展到随时间变化的运算符,以便何时以及如何运行 关系发展。
8 FUTUREWORK
Expanded/custom event-time windowing: Although the windowing TVFs proposed in Section 6.4 are common, Beam and Flink both provide many more, e.g., transitive closure sessions (periods of contiguous activity), keyed sessions (periods with a common session identifier, with timeout), and calendar-based windows. Experience has also shown that prebuilt solutions are never sufficient for all use cases (Chapter 4 of [6]); ultimately, users should be able to utilize the power of SQL to describe their own custom-windowing TVFs.
扩展/自定义事件时间窗口:尽管第6.4节中提出的窗口TVF是常见的,但是Beam和Flink都提供了更多,例如,传递闭包会话(连续活动的时段),键控会话(具有公共会话标识符的时段,具有 超时)和基于日历的窗口。 经验还表明,预建解决方案永远不足以满足所有用例([6]的第4章); 最终,用户应该能够利用SQL的力量来描述他们自己的自定义窗口TVF。
Time-progressing expressions: Computing a view over the tail of a stream is common, for example counting the bids of the last hour. Conceptually, this can be done with a predicate like (bidtime > CURRENT_TIME - INTERVAL ’1’ HOUR). However, the SQL standard defines that expressions like CURRENT_TIME are fixed at query execution time. Hence, we need expressions that progress over time.
时间进度表达式:计算流尾部的视图很常见,例如计算最后一小时的出价。 从概念上讲,这可以通过谓词来完成(bidtime> CURRENT_TIME - INTERVAL'1'HOUR)。 但是,SQL标准定义了像CURRENT_TIME这样的表达式在查询执行时是固定的。 因此,我们需要随时间推移的表达式。
Correlated access to temporal tables A common use case in streaming SQL is to enrich a table with attributes from a temporal table at a specific point in time, such as enriching an order with the currency exchange rate at the time when the order was placed. Currently, only a temporal version specified by a fixed literal AS OF SYSTEM TIME can be accessed. To enable temporal tables for joins, the table version needs to be accessible via a correlated join attribute.
对时态表的相关访问流式SQL中的一个常见用例是在特定时间点使用来自时态表的属性来丰富表,例如使用下订单时的货币汇率来丰富订单。 目前,只能访问固定文字AS OF SYSTEM TIME指定的时间版本。 要为连接启用时态表,需要通过相关的连接属性访问表版本。
Streaming changelog options: As alluded to in Section 6.5.1, more options for stream materialization exist, and EMIT should probably be extended to support them. In particular, rendering a stream changelog as a sequence of deltas.
流更改日志选项:如第6.5.1节中所提到的,存在更多用于流实现的选项,并且可能应该扩展EMIT以支持它们。 特别是,将流更改日志呈现为一系列增量。
Nested EMIT: Though we propose limiting the application of EMIT to the top level of a query, an argument can be made for the utility of allowing EMIT at any level of nested query. It is worthwhile to explore the tension between additional power and additional complexity this change would impose.
嵌套EMIT:虽然我们建议将EMIT的应用程序限制在查询的顶层,但可以在任何嵌套查询级别允许EMIT的实用程序参数。 值得探讨这种变化所带来的额外功率与额外复杂性之间的紧张关系。
Graceful evolution: Streaming queries by definition exist over an extended period of time, but software is never done nor perfect: bugs are uncovered, requirements evolve, and over time, long-running queries must change. The stateful nature of these queries imposes new challenges regarding the evolution of intermediate state. This remains an unsolved problem for the streaming community in general, but its relevance in the more abstract realm of SQL is all the greater.
优雅的演变:按定义存在流式查询在很长一段时间内存在,但软件从未完成也不完美:错误被发现,需求不断发展,并且随着时间的推移,长时间运行的查询必须改变。 这些查询的有状态性质对中间状态的演变提出了新的挑战。 对于流社区而言,这仍然是一个未解决的问题,但它在更抽象的SQL领域中的相关性更大。
More rigorous formal definitions of semantics: Although we’ve tried to provide semi-formal analyses of concepts presented in this paper where applicable, we as a streaming community still lack a true formal analysis of what streaming means, particularly when applied to some of the more subtle aspects of event-time processing such as watermarks and materialization controls. A more rigorous survey of modern streaming concepts would be a welcome and beneficial addition to the literature.
更严格的语义正式定义:虽然我们试图在适用的情况下提供本文中提出的概念的半正式分析,但我们作为流媒体社区仍然缺乏对流式传输方式的真实形式分析,特别是当应用于某些流式传输时 事件时间处理的更微妙的方面,如水印和物化控制。 对现代流媒体概念进行更严格的调查将是文献中受欢迎且有益的补充。
参考文献
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【虾皮★csAxp】。
如果,您还想与更多的爱好者进一步交流,不防加入QQ群【虾皮工作室-ABC大数据(232658451)】。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号