canal学习笔记
1.官方文档
https://github.com/alibaba/canal/wiki
项目:https://github.com/alibaba/canal
2.使用场景
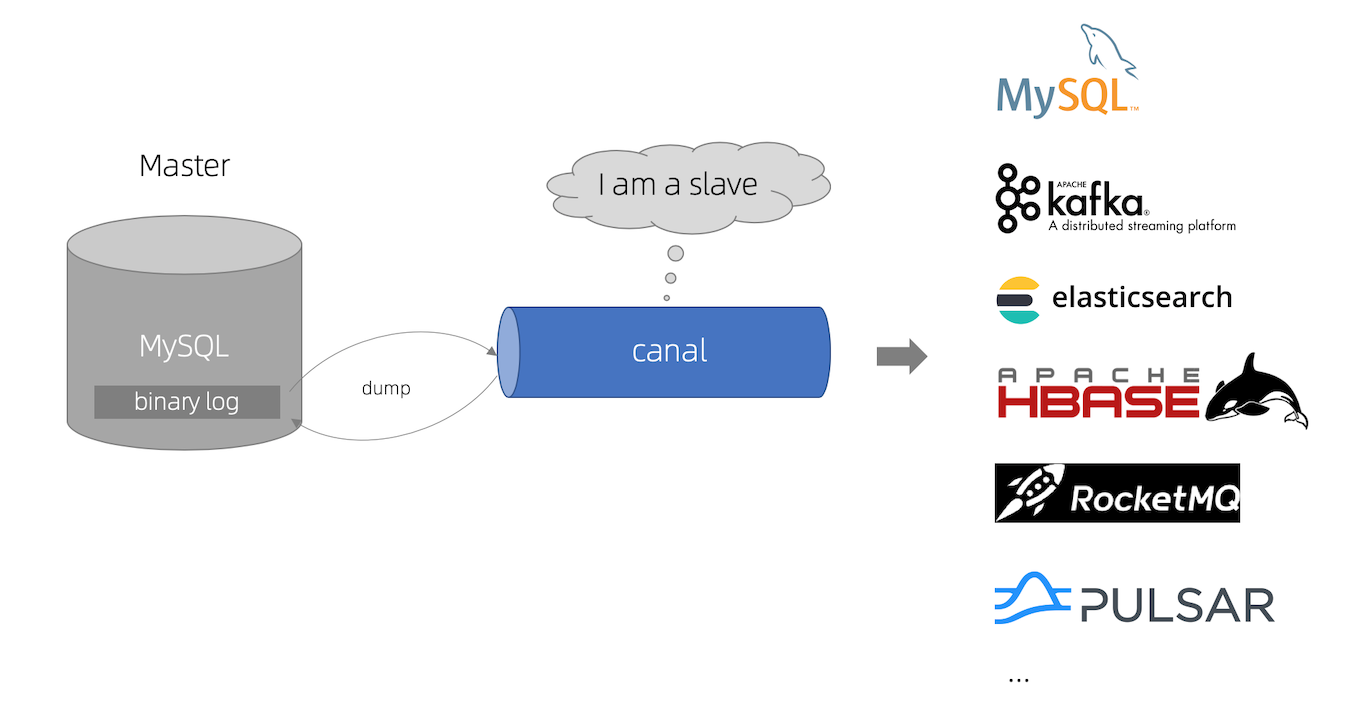
canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
(1)阿里otter(阿里用于进行异地数据库之间的同步框架基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务,从此开启了一段新纪元)这是canal需求的原始场景。

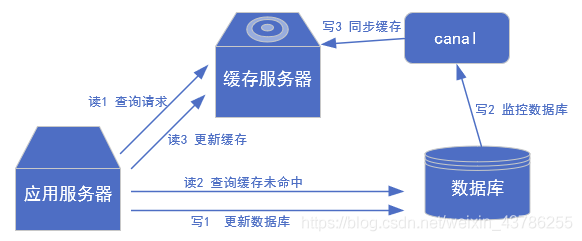
(2)更新缓存,比如电商场景下商品价格、库存发生变更需实时同步到redis:如果有大量的请求发送到mysql的话,mysql查询速度慢,QPS上不去,光查mysql可能会瘫痪,那就可以在前面加个缓存,这个缓存有2个主要的问题。一是缓存没有怎么办,二是数据不一致怎么办。对于第一个问题查缓存没有就查mysql,mysql再往缓存中写一份。对于第二个问题可以用canal中间件来解决,如果数据库修改了,那就采用异步的方式进行修改缓存,启动一个canal服务,监控mysql,只要一有变化就同步缓存,这样mysql和缓存就能达到最终的一致性。
(3)抓取业务数据新增变化记录表,用于制作拉链表或实时统计或业务实时消息:做拉链表是需要有增加时间和修改时间的,需要数据今天新增和变化的数据,如果时间不全就没办法知道哪些是修改的。可以通过canal把数据库变化的抽到记录表里,拉链数据就从这个表出。
(4)search build,根据数据库的变更实时更新到搜索引擎,比如电商场景下商品信息发生变更,实时同步到商品搜索引擎Elasticsearch、solr等。
(5)将数据库变更整理成自己的数据格式发送到kafka等消息队列,供消息队列的消费者进行消费业务。
3.canal工作原理
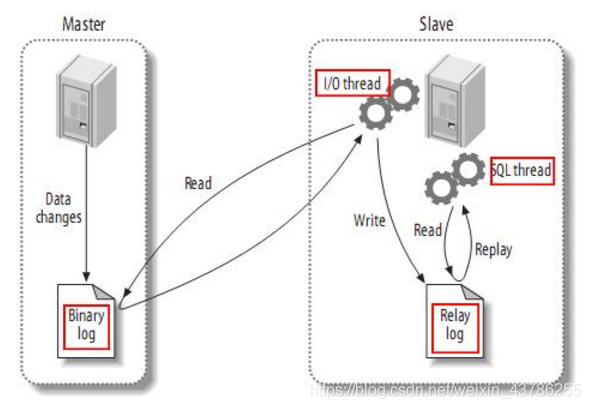
首先了解一下mysql主备复制原理:
(1)master主库将改变记录,发送到二进制文件(binary log)中
(2)slave从库向mysql Master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log)
(3)slave从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库
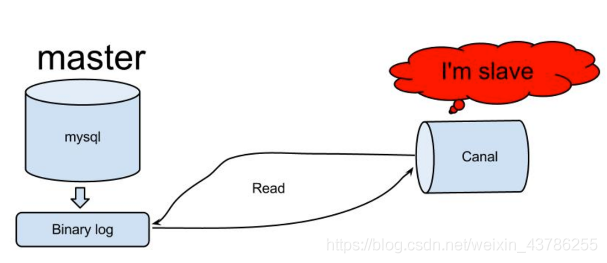
canal的工作原理:把自己伪装成slave,从master复制数据。读取binlog是需要master授权的,因为binlog是加密的。master授权后不知道读他的binlog的是从机还是canal,canal的所有传输协议都符合从机的标准,所以master一直以为是从机读的。
4.mysql的准备工作(开启binlog和用户创建和授权并且安装jdk11,在使用canal-admin时server一直显示关闭jdk从8换11解决了)
4.1 二进制日志介绍
mysql的二进制日志记录了所有的DDL和DML(除了数据查询语句),以事件的形式进行记录,包含语句执行消耗的时间,mysql的二进制日志是事务安全型的。
开启二进制日志大概会有1%的性能损坏。二进制日志有2个主要的使用场景:①mysql的主备复制②数据恢复,通过使用mysqlbinlog工具来恢复数据(用这个做恢复是备选方案,主方案还是定期快照,定期执行脚本导数据,其实就是把当前所有数据导成insert和update,这个量少)
二进制日志包括2类文件:①二进制日志索引文件(后缀为.index)用于记录所有的二进制文件②二进制日志文件(后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)。
4.2 开启binlog
修改mysql的配置文件my.cnf。
# vim /etc/my.cnf
在[mysqld] 区块添加
log-bin=mysql-bin
mysql-bin表示binlog日志的前缀,以后生成的的日志文件就是 mysql-bin.000001 的文件后面的数字按顺序生成。 当mysql重启或到达单个文件大小的阈值时,新生一个文件,按顺序编号。
4.3 binlog分类
binlog的格式有三种:STATEMENT,MIXED,ROW对比如下
| 格式 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| STATEMENT | 语句级别,记录每一次执行写操作的语句,相对于ROW模式节省了空间,但是可能产生数据不一致如update tt set create_date=now(),由于执行时间不同产生使得数据就不同 | 节省空间 | 可能造成数据不一致 |
| ROW | 行级,记录每次操作后每行记录的变化。假如一个update的sql执行结果是1万行statement格式只存一条sql语句,如果是row的话会把这个10000行的结果存着。 | 数据的绝对一致性。因为不管sql是什么,引用了什么函数,他只记录执行后的结果数据 | 占用较大空间 |
| MIXED | 是对statement的升级,如当函数中包含 UUID() 时,包含 AUTO_INCREMENT 字段的表被更新时,执行 (INSERT DELAYED) 语句时,用 UDF(Userdefined function)用户自定义函数 时,会按照 ROW的方式进行处理 | 节省空间,同时兼顾了一定的一致性 | 还有些极个别情况依旧会造成不一致,另外statement和mixed对于需要对binlog的监控的情况都不方便 |
4.4 binlog格式选择
如果只考虑主从复制的话可以用mixed,一般情况下使用statement,遇到几种特殊情况使用row,同步的话有SQL就行,因为手里有数据,前提是有数据才能执行这个SQL。在大数据场景下我们抽取数据是用于统计分析,分析的数据,如果用statement抽了SQL手里也没数据,不知道执行修改哪些,因为没有数据,所以没办法分析,所以适合用row,清清楚楚的表明了每一行是什么样。
4.5 修改配置文件
修改my.cnf文件,在[mysqld]模块下添加如下内容
server-id= 1
log-bin=mysql-bin
binlog_format=row (无任何修改的语句并不会进消息队列)
binlog-do-db=bigdata
binlog-do-db用于指定库,缩小监控的范围,server-id不能和mysql集群的其他节点重复
4.6 重启mysql
service mysqld restart 或者
Redirecting to /bin/systemctl restart mysqld.service
到数据目录下查询是否生成binlog文件,这里我把数据目录自定义为了/data/mysql/
# cd /data/mysql/
# ll
total 188500
-rw-r----- 1 mysql mysql 56 Jul 1 2020 auto.cnf
-rw------- 1 mysql mysql 1676 Jul 1 2020 ca-key.pem
-rw-r--r-- 1 mysql mysql 1112 Jul 1 2020 ca.pem
-rw-r--r-- 1 mysql mysql 1112 Jul 1 2020 client-cert.pem
-rw------- 1 mysql mysql 1676 Jul 1 2020 client-key.pem
drwxr-x--- 2 mysql mysql 4096 Jul 1 2020 dataxweb
-rw-r----- 1 mysql mysql 526 Jan 14 11:03 ib_buffer_pool
-rw-r----- 1 mysql mysql 79691776 Jan 14 11:04 ibdata1
-rw-r----- 1 mysql mysql 50331648 Jan 14 11:04 ib_logfile0
-rw-r----- 1 mysql mysql 50331648 Aug 5 06:20 ib_logfile1
-rw-r----- 1 mysql mysql 12582912 Jan 14 11:04 ibtmp1
drwxr-x--- 2 mysql mysql 116 Jul 1 2020 iot
drwxr-x--- 2 mysql mysql 4096 Jul 1 2020 mysql
-rw-r----- 1 mysql mysql 154 Jan 14 11:03 mysql-bin.000001
-rw-r----- 1 mysql mysql 19 Jan 14 11:03 mysql-bin.index
srwxrwxrwx 1 mysql mysql 0 Jan 14 11:03 mysql.sock
-rw------- 1 mysql mysql 6 Jan 14 11:03 mysql.sock.lock
drwxr-x--- 2 mysql mysql 8192 Jul 1 2020 performance_schema
-rw------- 1 mysql mysql 1680 Jul 1 2020 private_key.pem
-rw-r--r-- 1 mysql mysql 452 Jul 1 2020 public_key.pem
-rw-r--r-- 1 mysql mysql 1112 Jul 1 2020 server-cert.pem
-rw------- 1 mysql mysql 1676 Jul 1 2020 server-key.pem
drwxr-x--- 2 mysql mysql 8192 Jul 1 2020 sys
可以发现,这二进制日志索引文件和日志文件生成了。只要重启mysql,mysql-bin后面的序号就会往上涨,他的切分规则就是重启或者到一个大小的阈值,就会切一个
mysql-bin.000001
mysql-bin.index
4.7 mysql为canal配置权限
在mysql中给canal单独建一个用户,给全库全表的读,拷贝,复制的权限
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal' ;
报错:ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
原因是因为密码canal设置的过于简单会报错,MySQL有密码设置的规范,具体是与validate_password_policy的值有关,下图表明该值规则

查看MySQL完整的初始密码规则,登陆后执行以下命令
mysql> SHOW VARIABLES LIKE 'validate_password%';
+--------------------------------------+--------+
| Variable_name | Value |
+--------------------------------------+--------+
| validate_password_check_user_name | OFF |
| validate_password_dictionary_file | |
| validate_password_length | 8 |
| validate_password_mixed_case_count | 1 |
| validate_password_number_count | 1 |
| validate_password_policy | MEDIUM |
| validate_password_special_char_count | 1 |
+--------------------------------------+--------+
密码的长度是由validate_password_length决定的,但是可以通过以下命令修改
set global validate_password_length=4;
validate_password_policy决定密码的验证策略,默认等级为MEDIUM(中等),可通过以下命令修改为LOW或者0(低)
set global validate_password_policy=0;
重新执行或者密码更改为其他复杂的
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal' ;
5.安装canal
5.1 下载地址
https://github.com/alibaba/canal/releases
5.2 解压及配置
mkdir canal
tar -zxvf canal.deployer-1.1.6.tar.gz
配置说明:canal server的conf下有几个配置文件
conf/
├── canal_local.properties
├── canal.properties
├── example
│ ├── h2.mv.db
│ ├── instance.properties
│ └── meta.dat
├── logback.xml
├── metrics
│ └── Canal_instances_tmpl.json
└── spring
├── base-instance.xml
├── default-instance.xml
├── file-instance.xml
├── group-instance.xml
├── memory-instance.xml
└── tsdb
├── h2-tsdb.xml
├── mysql-tsdb.xml
├── sql
│ └── create_table.sql
└── sql-map
├── sqlmap-config.xml
├── sqlmap_history.xml
└── sqlmap_snapshot.xml
canal.properties的common属性前四个配置项:
canal.ip= # ip这里不指定,默认为本机
canal.port= 11111 # 端口号,是给tcp模式(netty)时候用的,如果用了kafka或者rocketmq,就不会去起这个端口了
canal.zkServers= # zk用于canal cluster
canal.serverMode = tcp # 用于指定什么模式拉取数据
destinations相关的配置:
#################################################
######### destinations #############
#################################################
canal.destinations = example
canal.conf.dir = ../conf
canal.auto.scan = true
canal.auto.scan.interval = 5
canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
canal.destinations = example可以设置多个,比如example1,example2,则需要创建对应的两个文件夹,并且每个文件夹下都有一个instance.properties文件。
如canal.instance.destination等于example,就会加载example/instance.properties配置文件
修改instance 配置文件
vi conf/example/instance.properties
# 按需修改成自己的数据库信息
#################################################
canal.instance.master.address=数据库ip:端口
# username/password,数据库的用户名和密码
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
# table regex .*\\..*表示监听所有表 也可以写具体的表名,用,隔开
canal.instance.filter.regex=.*\\..*
# mysql 数据解析表的黑名单,多个表用,隔开
canal.instance.filter.black.regex=
#################################################
mysql链接时的起始位置
canal.instance.master.journal.name + canal.instance.master.position : 精确指定一个binlog位点,进行启动
canal.instance.master.timestamp : 指定一个时间戳,canal会自动遍历mysql binlog,找到对应时间戳的binlog位点后,进行启动
不指定任何信息:默认从当前数据库的位点,进行启动。(show master status)
6.canal的instance与消费方式
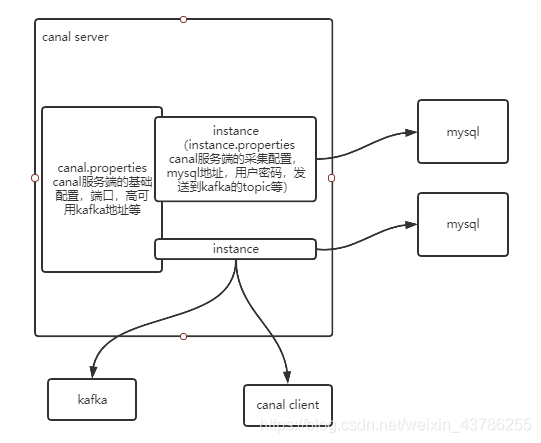
canal.properties这个配置文件负责的是canal服务的基础配置,每个canal可以起n多个实例instance,一个instance代表一个线程,每个instance都有一个独立的配置文件instance.properties,不同的instance可以采集不同的mysql数据库,也就是一个canal可以对应多个mysql数据库。
在instance里面有一个小队列,可以理解为是jvm级的队列,instance抓取来的数据先放入到队列中,队列可以有很多出口:①一个是canal server自己主动把数据推送到kafka,这个比较简单,一行代码不用写,只需要配个kafka的地址,每个instance对应kafka的一个topic,数据是json串。这种方式虽然简单,但是他的缺点主要体现在2个方面,一个instance对应一个topic,所有表都在这一个topic,所以实时的时候要进行分流,可以建2个相同instance,用不同的表过滤原则。另一方面,因为数据是json,并且携带了很多冗余信息,但是数据量大的时候传输效率比较低。②第二种方式是启动canal客户端主动去拉取数据,可以定义多长周期消费多少数据。他的缺点在于抓取出来的是序列化压缩的数据,所以需要反序列化,解压,比较麻烦。他的优点在于我们可以进行压缩,过滤掉没用的冗余信息,只保留我们需要的信息,提交传输效率。
一个example的目录就是一个instance,canal要配置多个实例采集多个数据源mysql的话如下配置,然后把conf目录下example复制多份,分别重命名。如下
#################################################
######### destinations #############
#################################################
canal.destinations = example1,example2,example3
7.Filter模块简介
filter模块用于对binlog进行过滤。在实际开发中,一个mysql实例中可能会有多个库,每个库里面又会有多个表,可能我们只是想订阅某个库中的部分表,这个时候就需要进行过滤。也就是说,parser模块解析出来binlog之后,会进行一次过滤之后,才会存储到store模块中。
过滤规则的配置既可以在canal服务端进行,也可以在客户端进行。
7.1 服务端配置
我们在配置一个canal instance时,在instance.properties中有以下两个配置项:

canal.instance.filter.regex用于配置白名单,也就是我们希望订阅哪些库,哪些表,默认值为.\..,也就是订阅所有库,所有表。
canal.instance.filter.black.regex用于配置黑名单,也就是我们不希望订阅哪些库,哪些表。没有默认值,也就是默认黑名单为空。
需要注意的是,在过滤的时候,会先根据白名单进行过滤,再根据黑名单过滤。意味着,如果一张表在白名单和黑名单中都出现了,那么这张表最终不会被订阅到,因为白名单通过后,黑名单又将这张表给过滤掉了。
另外一点值得注意的是,过滤规则使用的是perl正则表达式,而不是jdk自带的正则表达式。意味着filter模块引入了其他依赖,来进行匹配。
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\)。
注意:此过滤条件只针对row模式的数据库有效(mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)
8.canal-admin的部署与使用,及相关监控(https://blog.csdn.net/weixin_46097842/article/details/125019459)
改完之后,启动canal-server,启动的时候,记得带参数,指定local配置
sh bin/startup.sh local
canal集群搭建
https://blog.csdn.net/blueo666/article/details/127654542
9.canal-admin与canal-server的相关监控
这个监控主要用到prometheus
prometheus官网:https://prometheus.io/
中文文档:https://prometheus.fuckcloudnative.io/
10.canal-php
canal-php 是阿里巴巴开源项目 Canal是阿里巴巴mysql数据库binlog的增量订阅&消费组件 的 php 客户端。为 php 开发者提供一个更友好的使用 Canal 的方式。
canal-php 是 Canal 的 php 客户端,它与 Canal 是采用的Socket来进行通信的,传输协议是TCP,交互协议采用的是 Google Protocol Buffer 3.0。
文档与项目:https://github.com/xingwenge/canal-php
https://blog.csdn.net/qq_29744347/article/details/123402874
11.canal Adapter
为了便于大家的使用,官方做了一个独立的组件Adapter,Adapter是可以将canal server端获取的数据转换成几个常用的中间件数据源,现在支持kafka、rocketmq、hbase、elasticsearch,针对这几个中间件的支持,直接配置即可,无需开发。上文中,如果需要将mysql的数据同步到elasticsearch,直接运行 canal Adapter,修改相关的配置即可。
11.1 无法接收到数据,程序也没有报错?
一定要确保mysql的binlog模式为row模式,canal原理是解析Binlog文件,并且直接中文件中获取数据的。
11.2 Adapter 使用无法同步数据?
按照官方文档,检查配置项,如sql的大小写,字段的大小写可能都会有影响,如果还无法搞定,可以自己获取代码调试下,Adapter的代码还是比较容易看懂的。
12.canal配合rabbitmq
12.1 Canal服务端配置更改
# tcp, kafka, rocketMQ, rabbitMQ 一共四种模式 使用了什么插件就配置什么
canal.serverMode = rabbitMQ
##################################################
######### RabbitMQ #############
##################################################
# mq的ip地址 不可带端口号 加了端口号会报ipv6的错
rabbitmq.host = 127.0.0.1
# 就填个/就行
rabbitmq.virtual.host = /
# 填写mq队列相对应的交换机名称
rabbitmq.exchange = asyncdbcharge
# mq用户名
rabbitmq.username = admin
# mq密码
rabbitmq.password = !Abc@123
# 2 表示Durable
rabbitmq.deliveryMode = 2
12.2 Canal的Instance配置更改
# mq config 此处配置mq中队列所配置的Key
canal.mq.topic = AsyncDB_Exchanges_Key
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#################################################
同一个库不同表拆分成多个队列
https://www.cnblogs.com/brady-wang/p/13507270.html
12.3 Kafka并法消费 https://blog.csdn.net/qq_38550836/article/details/107945210
缓解Canal服务器压力以及不再手动拉取日志的问题,但是这样的方式依然是在一条一条的消费消息,性能并未得到提升。
如何多线程并发消费,如果我们单纯地用多线程并发消费的话并不能保证消息的有序性,这种binlog日志同步是需要严格有序性的,否则会导致数据错乱。那有没有办法能够保证顺序的情况下并发消费呢?答案是有的,即将指定数据发送到指定分区当中,然后起多个消费者消费不同分区的数据即可,并且Canal提供写入指定分区的配置。
更改instance配置
# canal.mq.partition=0
# hash partition config
canal.mq.partitionsNum=3
canal.mq.partitionHash=demo\\.pricing_house_info:house_code
这里面主要配置了canal.mq.partitionsNum和canal.mq.partitionHash两个参数,他们的意思如下:
canal.mq.partitionsNum:指定当前topic的分区数
canal.mq.partitionHash:指定到分区的分区规则,可以细化到字段
这里我们指定topic有3个分区,并且使用pricing_house_info表中的house_code字段来进行划分,即让相同house_code的数据全部到一个分区当中
13.canal常见问题
https://blog.csdn.net/qq_36971119/article/details/122856561
遇到一个问题:canal.instance.filter.regex要过滤{m,n}等m-n个字符的逗号,在这个配置是分隔多个表的作用,不知道如何改,现在改成+但没有{m,n}更精确。
ubuntu下无法停止程序
https://www.jianshu.com/p/ff7a19a11bff
Ubuntu 遇到 bin/stop.sh: 52: kill: No such process和bin/stop.sh: 58: [: unexpected operator的问题
https://blog.csdn.net/wm9028/article/details/122965577
Canal报错:Could not find first log file name in binary log index file
https://blog.csdn.net/sxc1414749109/article/details/121080447
可以通过在主库上通过"flush logs"命令重新生成信息binlog,然后使用"show master status"查询信息位点,重新使用“CHANGE MASTER TO MASTER_LOG_FILE='log-bin.00000xx',MASTER_LOG_POS=xxx;”重新同步binlog。
canal实战问题汇总分析
https://blog.csdn.net/nandao158/article/details/128447014
https://www.linuxe.cn/post-585.html
canal是无法避免脚本操作产生的批量数据进队列,后续需要自我脚本控制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号