mysql面试题
mysql中int(10)与int(11)有什么区别吗?
https://www.cnblogs.com/jewave/p/6214517.html
Mysql innodb引擎不开始事务时,更改数据会写redolog么?
对于InnoDB,你不能关闭事务Transaction,你只能不提交commit。对于AUTOCOMMIT = 1,如果没有显式explicit(即你自己写出begin transaction语句),任何一个语句,都是独立的一个事务,每个语句前面隐式(implicit)加了begin transaction,然后随后自动commit如果你设置AUTOCOMMIT = 0,如果你没有写commit语句,那么你所有的语句都在一个事务里,等着你最后写一个commit去提交不管commit语句出现没有,都会有Redo Log和Undo Log(commit语句的标志会记录在Redo Log里)。从MySQL 8.0.21开始,允许你用INNODB_REDO_LOG_ENABLE,这个参数去关闭Redo Log,这时,就真的没有Redo Log了。
为什么有binlog还要redo log
https://blog.csdn.net/ab1024249403/article/details/110099571
Mysql 核心日志(redolog、undolog、binlog)
https://zhuanlan.zhihu.com/p/213770128
面试官:谈谈你对Mysql的MVCC的理解?
https://baijiahao.baidu.com/s?id=1629409989970483292&wfr=spider&for=pc
MySQL面试经典100题(收藏版,附答案)
https://www.cnblogs.com/setalone/p/14851000.html 可以白嫖的为什么要自己写的咸鱼
后端程序员必备:书写高质量SQL的30条建议
https://juejin.cn/post/6844904098999828488
Inner join 、left join、right join,优先使用Inner join,如果是left join,左边表结果尽量小
exist & in的合理利用
为了提高group by 语句的效率,可以在执行到该语句前,把不需要的记录过滤掉。先where的再groupby having
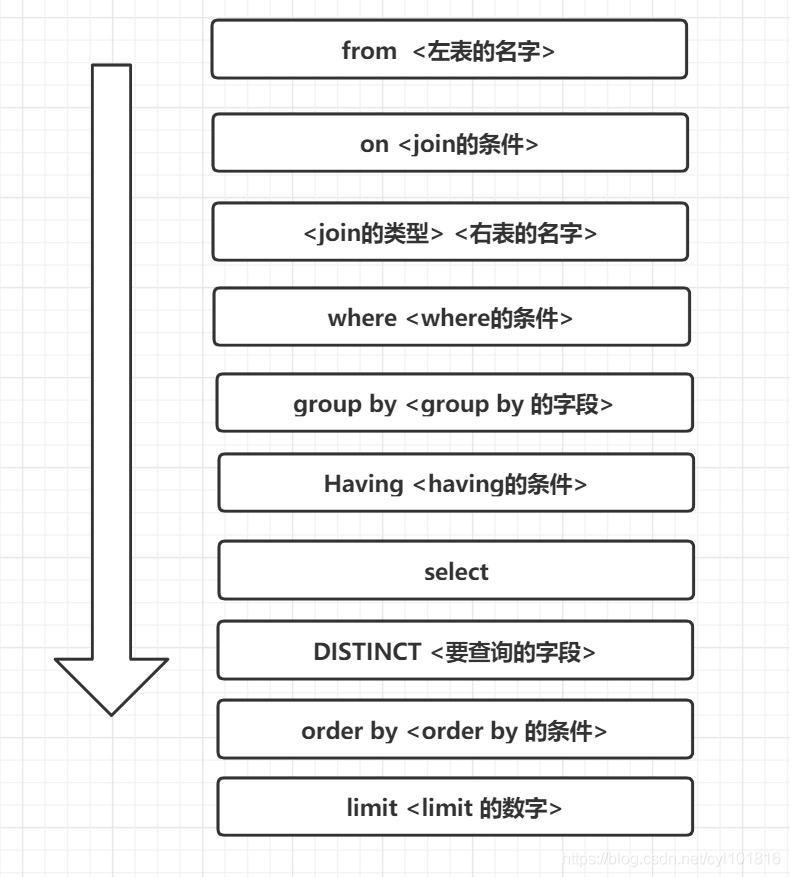
讲一讲,数据库ACID的特性。
原子性(atomicity)是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(consistent)指事务前后数据的完整必须保持一致。
隔离性(isolation)指多个用户并发访问数据库时,一个用户的事务不能被其他用户的事务所干扰,多个并发事务之间数据要相互隔离。
持久性(durablity)是指一个事务一旦提交,它对数据库中数据的改变就是永久性的,即便数据库发生故障也不应该对其有任何影响。
请你介绍一下,数据库乐观锁和悲观锁
悲观锁(Pessimistic Lock),顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。
Java synchronized 就属于悲观锁的一种实现,每次线程要修改数据时都先获得锁,保证同一时刻只有一个线程能操作数据,其他线程则会被block。
乐观锁(Optimistic Lock),顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在提交更新的时候会判断一下在此期间别人有没有去更新这个数据。乐观锁适用于读多写少的应用场景,这样可以提高吞吐量。
乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。
乐观锁一般来说有以下2种方式:
使用数据版本(Version)记录机制实现,这是乐观锁最常用的一种实现方式。何谓数据版本?即为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据。
使用时间戳(timestamp)。乐观锁定的第二种实现方式和第一种差不多,同样是在需要乐观锁控制的table中增加一个字段,名称无所谓,字段类型使用时间戳(timestamp), 和上面的version类似,也是在更新提交的时候检查当前数据库中数据的时间戳和自己更新前取到的时间戳进行对比,如果一致则OK,否则就是版本冲突。
数据库索引底层是怎样实现的,哪些情况下索引会失效
B+树实现的。
-
没有遵循最左匹配原则。
-
一些关键字会导致索引失效,例如 or, != , not in,is null ,is not unll
-
like查询是以%开头
-
隐式转换会导致索引失效。
-
对索引应用内部函数,索引字段进行了运算。
请你简单介绍一下,数据库水平切分与垂直切分
垂直拆分就是要把表按模块划分到不同数据库表中(当然原则还是不破坏第三范式),这种拆分在大型网站的演变过程中是很常见的。当一个网站还在很小的时候,只有小量的人来开发和维护,各模块和表都在一起,当网站不断丰富和壮大的时候,也会变成多个子系统来支撑,这时就有按模块和功能把表划分出来的需求。其实,相对于垂直切分更进一步的是服务化改造,说得简单就是要把原来强耦合的系统拆分成多个弱耦合的服务,通过服务间的调用来满足业务需求看,因此表拆出来后要通过服务的形式暴露出去,而不是直接调用不同模块的表,淘宝在架构不断演变过程,最重要的一环就是服务化改造,把用户、交易、店铺、宝贝这些核心的概念抽取成独立的服务,也非常有利于进行局部的优化和治理,保障核心模块的稳定性。
垂直拆分:单表大数据量依然存在性能瓶颈
水平拆分,上面谈到垂直切分只是把表按模块划分到不同数据库,但没有解决单表大数据量的问题,而水平切分就是要把一个表按照某种规则把数据划分到不同表或数据库里。例如像计费系统,通过按时间来划分表就比较合适,因为系统都是处理某一时间段的数据。而像SaaS(Software as a Service)应用,通过按用户维度来划分数据比较合适,因为用户与用户之间的隔离的,一般不存在处理多个用户数据的情况,简单的按user_id范围来水平切分。
通俗理解:水平拆分行,行数据拆分到不同表中, 垂直拆分列,表数据拆分到不同表中。
JDBC中如何进行事务处理?
Connection提供了事务处理的方法,通过调用setAutoCommit(false)可以设置手动提交事务;当事务完成后用commit()显式提交事务;如果在事务处理过程中发生异常则通过rollback()进行事务回滚。除此之外,从JDBC 3.0中还引入了Savepoint(保存点)的概念,允许通过代码设置保存点并让事务回滚到指定的保存点。
请你讲讲 Statement 和 PreparedStatement 的区别?哪个性能更好?
与Statement相比,①PreparedStatement接口代表预编译的语句,它主要的优势在于可以减少SQL的编译错误并增加SQL的安全性(减少SQL注射攻击的可能性);②PreparedStatement中的SQL语句是可以带参数的,避免了用字符串连接拼接SQL语句的麻烦和不安全;③当批量处理SQL或频繁执行相同的查询时,PreparedStatement有明显的性能上的优势,由于数据库可以将编译优化后的SQL语句缓存起来,下次执行相同结构的语句时就会很快(不用再次编译和生成执行计划)。
请你谈谈JDBC的反射,以及它的作用?
通过反射com.mysql.jdbc.Driver类,实例化该类的时候会执行该类内部的静态代码块,该代码块会在Java实现的DriverManager类中注册自己,DriverManager管理所有已经注册的驱动类,当调用DriverManager.geConnection方法时会遍历这些驱动类,并尝试去连接数据库,只要有一个能连接成功,就返回Connection对象,否则则报异常。
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号