php rabbitmq的开发体验(一)
一、前言
为了公司的推送任务,监听用户后台的操作在不影响用户的操作速度,尽快的在用户的网站上更新用户的更改,需要保证消息的稳定性和可恢复性。所以我用了消息队列,具有
-
解耦
-
冗余
-
扩展性
-
灵活性 & 峰值处理能力
-
可恢复性
-
顺序保证
-
-
异步通信
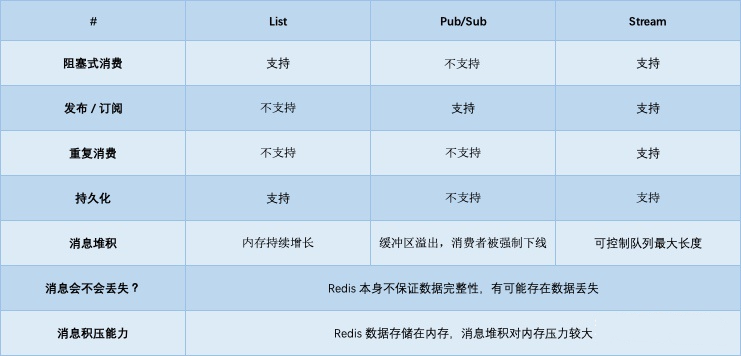
很满足我的需求,然后研究了线上很火的消息队列,消息队列(MQ)概述这篇文章对消息队列介绍的很全面,我采用了rabbitmq更考虑消息的可靠性,并且感觉并发量不大,还不至于到Kafka的高吞吐地步,rabbitmq也可以集群化来为以后的高流量问题解决。但许多公司同事用redis做队列,那这里讲下redis和我们正式的消息队列之间的区别,首先我要肯定redis的十万QPS,单进程单线程执行。下面我介绍2种基本的redis队列存在的问题,可以做准确性要求不高的队列。
一.基于List的 LPUSH+BRPOP 的实现
使用rpush和lpush操作入队列,lpop和rpop操作出队列。
List支持多个生产者和消费者并发进出消息,每个消费者拿到都是不同的列表元素。
但是当队列为空时,lpop和rpop会一直空轮训,消耗资源;所以引入阻塞读blpop和brpop,阻塞读在队列没有数据的时候进入休眠状态,超时时间设置为0时,即可无限等待,还能实现优先级队列。
一旦数据到来则立刻醒过来,消息延迟几乎为零。甚至返回一个消息(pop时队列的当前消息删除)的同时还将这个消息添加到另一个备份redis列表当中,一个客户端完成某个消息的处理之后,可以用LREM命令将这个消息从备份列表删除,通过备份列表来做ack消息消费确认(即消息已经被正常消费完成),并添加一个定时任务专门用于监视备份列表,它自动地将超过一定处理时限的备份消息RPOPLPUSH重新放入队列中去,来重新处理这些处理异常的消息重新消费。
redis性能可靠但万一突然服务崩溃的情况可能遇到的问题:
1.消息已经处理完毕但删除备份异常,这条消息存在重复消费的情况,因此消费操作要实现幂等性,即保证重复消费结果一致。(一般由消费代码本身具有幂等性,消息不管未完成或完成都有重试性的可能性)
2.消息根本没有处理好,中间异常。则主动回滚,并把定时任务从备份队列中移除,重新push进队列。
缺点:
1.做消费者确认ACK麻烦,不能保证消费者消费消息后是否成功处理的问题(宕机或处理异常等),通常需要维护一个后备(Pending待确认)列表,保证消息处理确认。
2.不能做广播模式,如pub/sub,消息发布/订阅模型(List模式下的消费者之间是竞争关系)
3.不能重复消费,一旦消费就会被删除
4.不支持分组消费
二.PUB/SUB,订阅/发布模式
SUBSCRIBE,用于订阅信道
PUBLISH,向信道发送消息
UNSUBSCRIBE,取消订阅
此模式允许生产者每生产一次消息,由中间件负责将消息复制到多个消息队列,每个消息队列由对应的消费组消费。
优点
典型的广播模式,一个消息可以发布到多个消费者
多信道订阅,消费者可以同时订阅多个信道,从而接收多类消息
消息即时发送,消息不用等待消费者读取,消费者会自动接收到信道发布的消息
缺点
消息一旦发布,不能接收。换句话就是发布时若客户端不在线,则消息丢失,不能寻回
不能保证每个消费者接收的时间是一致的
若消费者客户端出现消息积压,到一定程度,会被强制断开,导致消息意外丢失。通常发生在消息的生产远大于消费速度时
可见,Pub/Sub 模式不适合做消息存储,消息积压类的业务,而是擅长处理广播,即时通讯,即时反馈的业务。
下面从消息队列的主要特征来区分
1.可靠性
redis :没有相应的机制保证消息的可靠消费,如果发布者发布一条消息,而没有对应的订阅者的话,这条消息将丢失,不会存在内存中;没有ack,不能保证消费者消费消息后是否成功处理的问题,即使做了Pending列表,也存在高并发的意外情况。
rabbitmq:具有消息消费确认机制,如果发布一条消息,还没有消费者消费该队列,那么这条消息将一直存放在队列中,直到有消费者消费了该条消息,以此可以保证消息的可靠消费。
2.实时性
redis:实时性高,redis作为高效的缓存服务器,所有数据都存在内存中,所以它具有很高的实时性。
3.消费者负载均衡:
rabbitmq队列可以被多个消费者同时监控消费,可以为竞争也可以是订阅,由于rabbitmq的消费确认机制,因此它能够根据消费者的消费能力而调整它的负载。
redis发布订阅模式,一个队列可以被多个消费者同时订阅,当有消息到达时,会将该消息依次发送给每个订阅者,她是一种消息的广播形式,redis本身不做消费者的负载均衡,因此消费效率存在瓶颈。
4.持久性
redis:redis的持久化是针对于整个redis缓存的内容,它有RDB和AOF两种持久化方式,可以将整个redis实例持久化到磁盘,以此来做数据备份,防止异常情况下导致数据丢失。
rabbitmq:交换器,队列,每条消息都可以选择性持久化,持久化粒度更小,更灵活。
5.队列监控
rabbitmq实现了后台监控平台,可以在该平台上看到所有创建的队列的详细情况,良好的后台管理平台可以方面我们更好的使用。
redis没有所谓的队列消费监控平台。
总结
redis: 轻量级,低延迟,高并发,低可靠性;
rabbitmq:重量级,高可靠,异步,不保证实时;
rabbitmq是一个专门的AMQP协议队列,他的优势就在于提供可靠的队列服务,并且可做到异步,而redis主要是用于缓存的,redis的发布订阅模块,可用于实现及时性,且可靠性低的功能。
二、RabbitMq 安装与运行
本人开发环境是Ubuntu 18.04,
apt-get install erlang-nox # 安装erlang erl # 查看relang语言版本,成功执行则说明relang安装成功
wget -O- https://www.rabbitmq.com/rabbitmq-release-signing-key.asc | sudo apt-key add -
apt-get update
apt-get install rabbitmq-server #安装成功自动启动
systemctl status rabbitmq-server #Active: active (running) 说明处于运行状态
# service rabbitmq-server status 用service指令也可以查看,同systemctl指令
service rabbitmq-server start # 启动 service rabbitmq-server stop # 停止 service rabbitmq-server restart # 重启
rabbitmq-plugins enable rabbitmq_management # 启用插件
service rabbitmq-server restart # 重启
rabbitmqctl list_users
rabbitmqctl add_user admin yourpassword # 增加普通用户
rabbitmqctl set_user_tags admin administrator # 给普通用户分配管理员角色
ok,你可以在你的浏览器上输入:http://服务器Ip:15672/ 来访问你的rabbitmq监控页面。使用刚刚添加的新用户登录。我们可以通过代码也可以通过界面操作rabbitmq,页面操作相当于linux的图形画界面更显性和直接。具体的界面功能介绍可以通过https://www.cnblogs.com/BNTang/articles/13777477.html这个博客主的介绍页面。本文不作更具体的介绍。大家可以先对第三块有概念上的了解后再看界面功能理解更快。
apt-cache search rabbitmq apt-get install php5.6-amqp #我本地php环境5.6可能有点老了 大家需要根据自己的php版本安装对应扩展
/etc/init.d/apache2 restart 重启php 我本地apache2重启带动关联的php
三、AMQP协议
提到RabbitMQ,就不得不提AMQP协议。AMQP协议是具有现代特征的二进制协议。是一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
先了解一下AMQP协议中间的几个重要概念:很重要,至少脑海里有这些概念和逻辑图,面试可以谈,毕竟面试又不上机。
- Server:接收客户端的连接,实现AMQP实体服务。
- Connection:连接,应用程序与Server的网络连接,TCP连接。
- Channel:信道,消息读写等操作在信道中进行。客户端可以建立多个信道,每个信道代表一个会话任务。
- Message:消息,应用程序和服务器之间传送的数据,消息可以非常简单,也可以很复杂。有Properties和Body组成。Properties为外包装,可以对消息进行修饰,比如消息的优先级、延迟等高级特性;Body就是消息体内容。
- Virtual Host:虚拟主机,用于逻辑隔离。一个虚拟主机里面可以有若干个Exchange和Queue,同一个虚拟主机里面不能有相同名称的Exchange或Queue。
- Exchange:交换器,接收消息,按照路由规则将消息路由到一个或者多个队列。如果路由不到,或者返回给生产者,或者直接丢弃。RabbitMQ常用的交换器常用类型有direct、topic、fanout、headers四种,后面详细介绍。
- Binding:绑定,交换器和消息队列之间的虚拟连接,绑定中可以包含一个或者多个RoutingKey。
- RoutingKey:路由键,生产者将消息发送给交换器的时候,会发送一个RoutingKey,用来指定路由规则,这样交换器就知道把消息发送到哪个队列。路由键通常为一个“.”分割的字符串,例如“com.rabbitmq”。
- Queue:消息队列,用来保存消息,供消费者消费。
我们完全可以直接使用 Connection 就能完成信道的工作,为什么还要引入信道呢?
试想这样一个场景, 一个应用程序中有很多个线程需要从 RabbitMQ 中消费消息,或者生产消息,那么必然需要建立很多个 Connection,也就是许多个 TCP 连接。然而对于操作系统而言,建立和销毁 TCP 连接是非常昂贵的开销,如果遇到使用高峰,性能瓶颈也随之显现。 RabbitMQ 采用 TCP 连接复用的方式,不仅可以减少性能开销,同时也便于管理 。
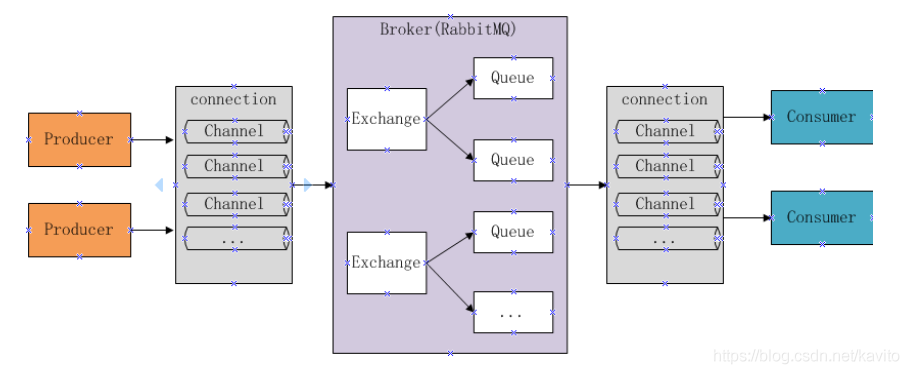
下图是AMQP的协议模型:

正如图中所看到的,AMQP协议模型有三部分组成:生产者、消费者和服务端。
生产者是投递消息的一方,首先连接到Server,建立一个连接,开启一个信道;然后生产者声明交换器和队列,设置相关属性,并通过路由键将交换器和队列进行绑定。同理,消费者也需要进行建立连接,开启信道等操作,便于接收消息。
接着生产者就可以发送消息,发送到服务端中的虚拟主机,虚拟主机中的交换器根据路由键选择路由规则,然后发送到不同的消息队列中,这样订阅了消息队列的消费者就可以获取到消息,进行消费。
最后还要关闭信道和连接。
RabbitMQ是基于AMQP协议实现的,其结构如下图所示,和AMQP协议简直就是一模一样

 浙公网安备 33010602011771号
浙公网安备 33010602011771号