kvm的cpu,mem 的超分(over-commit)
kvm 支持CPU和mem的超分,适当的超分可以提升物力资源的利用效率
一.什么是mem超分:
实际上mem 超分是指kvm能够分配给客户机内存的总大于实际可用的物理内存总数。由于客户机操作系统里的内存不可能一直100%的利用,所以内存过载是可行的。
但是最好不好超分太大,所有客户机的内存总和不要超过host物理内存加swap的总和,不然当所有客户机都处在内存使用较高的情况下,就会出现有客户机因为内存不足而被关闭的情况。
二.mem超分的实现方式:
1.内存交换(swapping):用交换空间来弥补内存不足,也就是说在给客户机分配内存的时候,将物理机swap空间当作物理内存分配给客户机使用,广泛使用,但性能要相对于其它两种要低一些。
2.气球(ballooning):通过virio_balloon驱动来实现宿主机Hypervisor和客户机之间的协作。ballooning可以简单理解为,host内存不足了,找guest要内存来使用,通常情况下guest需要关机,调整内存配置再开机,而ballooning技术可以不需要客户机关闭,客户机释放空闲内存到气球中,气球中的内存可以供host访问(但不能被geust访问使用),如果客户机空闲内存不足,可能会将部分内存交换到客户机的swap中,从而使气球膨胀,host再回收气球中的内存供其它进程或者客户机来使用。相反,当客户机内存不足时候,可以让客户机内存气球压缩,释放出内存气球中的部分内存供客户机使用。

ballooning是一种让内存过载变得非常有效的机制,例如在一个为8GB的host上,有6个内存为2GB的guest(A、B、C、D、E、F),当在一段时间内A,B,C的负载很轻,就通过ballooning将其内存降到512M,这样512M*3+2G*3<8G,看起来8G内存,每个客户机分不到2G内存,实际上每个客户机可以使用到2G内存。
3.页共享(page sharing):通过KSM(Kernel SamePage Merging)合并多个客户机进程使用的相同内存页,KSM允许内核在多个进程(包括虚拟机之间)共享完全相同的页。KSM让内核扫描正在运行的程序并比较他们的内存,如果发现内存页是完全相同的,就将它们合并成一个内存页,并标识‘写时复制’,这样可以节省内存的使用量,如果有进程尝试去修改标识为 ‘写时复制’的合并内存页,就为该进程复制出一个新的内存页供其使用。事实上,客户机运行相同的操作系统或者应用程序时,KSM的作用就更加明显,KSM合并那些相同的页,并不影响客户机的运行,这样实际客户机的内存总和也可以大于物理机的内存总和。
3.overcommit 与OOM killer:
要实现mem的过度分配,必须要修改overcommit_memory的值,否则客户机在申请内存时候会遭到拒绝,修改的方式是有三种
1)sysctl -w vm.overcommit=[0|1|2],临时设置
2)echo $n > /proc/sys/vm/overcommit_memory;n的值为0或1或2,临时设置
3)echo "vm.overcommmit_memroy=$n" > /etc/sysctl.conf,同样n的值为0或1或2,永久有效
0(默认):不允许超分,内核将检查是否有足够的可用内存供进程使用,如果有则允许申请,如果没有则返回错误
1:允许超分,不管当前内存状态如何,允许所有的内存分配申请
2:当内存分配申请小于CommitLimit的时候允许,否则返回错误
当vm.overcommit=2的时候,CommitLimit=【物理内存*vm.overcommit_ratio/100)+swap】,vm.overcommit的值默认是50,可以修改,仅当vm.overcommit_memory=2时才有效。

linux内核有个机制叫OOM killer(Out-of-Memory killer),当系统检测到内存不足的时候,有两种方式处理,依赖/proc/sys/vm/panic_on_oom里的值
a)当vm.panic_on_oom=1时,直接panic
b)默认值,当vm.panic_on_oom=0时,杀掉部分使用内存大的进程

当vm.panic_on_oom=0时,kernel会根据/proc/$pid/oom_score的分数来决定是否杀掉该进程,分数越大越容易被杀掉,除了kernel通过运行时间等因素调整这个分数,用户也可以去调整这个分数,比如我们想要某个进程远离oom killer,我们可以设置该进程的oom_score为最小。那么怎么来设定这个score呢

可以看到,oom_score是只读的,oom_adj 和oom_score_adj这两个是可写的。那么这个分数调整的范围是多少呢,这个得看kernel的oom.h里定义多少,在/usr/src/kernels*/include/uapi/linux/oom.h里定义
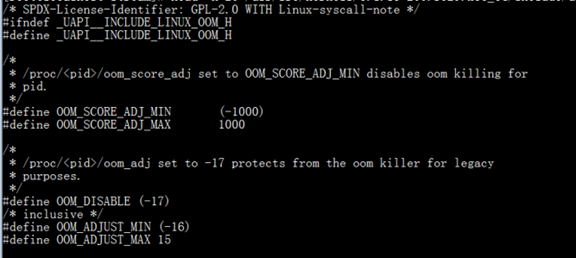
可以看到oom_score_adj的范围时-1000到1000,当值为-1000时意味着disable oom
oom_adj的范围时-16到15,当值为-17时意味着disable oom
来看几个实验:
1.修改oom_adj的值为-17,看看oom_socre,oom_score_adj的值变化
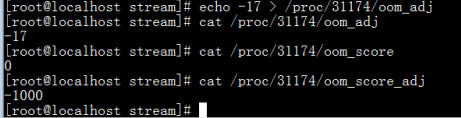
2.修改oom_adj的值为15,看看oom_score,oom_score_adj的值变化

3.修改oom_score_adj的值为-1000,看看oom_adj,oom_score的值变化

4.修改oom_score_adj的值为1000,看看oom_adj,oom_score的值变化

5.写入范围外的值
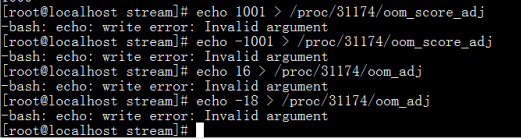
总结:
1.超过设定范围的值时不允许被写入到oom_adj,oom_score_adj里
2.无论修改oom_adj和oom_score_adj的效果是一样的
3.oom_score的分数范围是0-1000
*注意:子进程会继承父进程的oom_adj
上面提到当vm.overcommit=2的时候,CommitLimit=【物理内存*vm.overcommit_ratio/100)+swap】,那么问题又来了,kernel何时开始使用SWAP空间,可以参考/proc/sys/vm/swappness
vm.swappness的值越高,越容易交换
vm.swappness=0时
当剩余空闲内存小于/proc/sys/vm/min_free_kbytes里的值,就开始使用SWAP区
vm.swappness=1时
进行少量交换
vm.swappness=100时
内核将积极使用交换空间
三.CPU超分
CPU过载使用,是让一个或者多个客户机的vCPU总数超过host物理CPU的总数。
因为物理机中的客户机不可能都处于高负荷的状态,所以适当的超分有助于资源的充分利用。KVM允许CPU 过载使用,但是实际生产环境中(特别是负载较重的环境)一定要谨慎。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号