

Java并发编程之共享变量
可见性
如果一个线程对共享变量值的修改,能够及时的被其他线程看到,叫做共享变量的可见性。
Java 虚拟机规范试图定义一种 Java 内存模型(JMM),来屏蔽掉各种硬件和操作系统的内存访问差异,让 Java 程序在各种平台上都能达到一致的内存访问效果。简单来说,由于 CPU 执行指令的速度是很快的,但是内存访问的速度就慢了很多,相差的不是一个数量级,所以搞处理器的那群大佬们又在 CPU 里加了好几层高速缓存。
在 Java 内存模型里,对上述的优化又进行了一波抽象。JMM 规定所有变量都是存在主存中的,类似于上面提到的普通内存,每个线程又包含自己的工作内存,方便理解就可以看成 CPU 上的寄存器或者高速缓存。所以线程的操作都是以工作内存为主,它们只能访问自己的工作内存,且工作前后都要把值在同步回主内存。简单点说就是:多线程中读取或修改共享变量时,首先会读取这个变量到自己的工作内存中成为一个副本,对这个副本进行改动后再更新回主内存中。
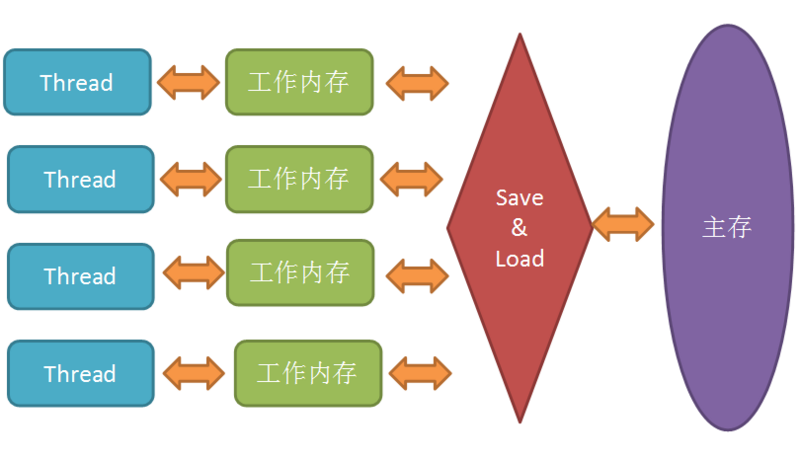
使用工作内存和主存虽然加快了速度,但是也带来了一些问题,比如:
i = i + 1;
假设 i 初值为0,当只有一个线程执行它时,结果肯定得到1,当两个线程执行时,会得到结果2吗?这就不一定了,可能会存在这种情况:
线程1:load i from 主存 // i = 0
i + 1 // i = 1
线程2:load i from 主存 // 因为线程1还没将i的值写回内存,所以i还是0
i + 1 // i = 1
线程1:save i to 主存
线程2:save i to 主存
如果两个线程按照上面的执行流程,那么 i 最后的值居然是1了,如果最后的写回生效的慢,你再读取 i 的值,都可能是0,这就是缓存不一致问题。
这种情况一般称为失效数据,因为线程1还没将 i 的值写回主内存,所以 i 还是0,在线程2中读到的就是 i 的失效值(旧值)。也可以理解成,在操作完成之后将工作内存中的副本回写到主内存,并且在其它线程从主内存将变量同步回自己的工作内存之前,共享变量的改变对其是不可见的。
有序性
即程序执行的顺序按照代码的先后顺序执行。例如:
int i = 0; boolean flag = false; i = 1; // 语句1 flag = true; // 语句2
上面代码定义了一个 int 型变量,定义了一个 boolean 类型变量,然后分别对两个变量进行赋值操作。
从代码顺序上看,语句1 是在语句2 前面的,那么 JVM 在真正执行这段代码的时候会保证语句1 一定会在语句2 前面执行吗? 不一定,为什么呢? 这里可能会发生指令重排序。
重排序
指令重排是指 JVM 在编译 Java 代码的时候,或者 CPU 在执行 JVM 字节码的时候,对现有的指令顺序进行重新排序。它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的(指的是不改变单线程下的程序执行结果)。
虽然处理器会对指令进行重排序,但是它会保证程序最终结果会和代码顺序执行结果相同,那么它靠什么保证的呢? 再看下面一个例子:
int a = 10; // 语句1 int r = 2; // 语句2 a = a + 3; // 语句3 r = a * a; // 语句4
这段代码有4个语句,那么可能的一个执行顺序是:

那么可不可能是这个执行顺序呢?
语句2 -> 语句1 -> 语句4 -> 语句3
不可能,因为处理器在进行重排序时是会考虑指令之间的数据依赖性,如果一个指令 Instruction 2 必须用到 Instruction 1 的结果,那么处理器会保证 Instruction 1 会在 Instruction 2 之前执行。
虽然重排序不会影响单个线程内程序执行的结果,但是多线程呢?下面看一个例子:
// 线程1
context = loadContext(); // 语句1
inited = true; // 语句2
// 线程2
while( !inited ){
sleep();
}
doSomethingwithconfig(context);
上面代码中,由于语句1 和语句2 没有数据依赖性,因此可能会被重排序。
假如发生了重排序,在线程1 执行过程中先执行语句2,而此时线程2 会以为初始化工作已经完成,那么就会跳出 while 循环,去执行 doSomethingwithconfig(context) 方法,而此时 context 并没有被初始化,就会导致程序出错。
从上面可以看出,指令重排序不会影响单个线程的执行,但是会影响到线程并发执行的正确性。
原子性
Java 中,对基本数据类型的读取和赋值操作是原子性操作, 所谓原子性操作就是指这些操作是不可中断的,要做一定做完,要么就没有执行。
JMM 只实现了基本的原子性,像 i++ 的操作,必须借助于 synchronized 和 Lock 来保证整块代码的原子性了。线程在释放锁之前,必然会把 i 的值刷回到主存的。
要想并发程序正确地执行,必须要保证原子性、可见性以及有序性。只要有一个没有被保证,就有可能会导致程序运行不正确。
volatile 关键字
volatile 关键字的两层语义
一旦一个共享变量(类的成员变量、类的静态成员变量)被 volatile 修饰之后,那么就具备了两层语义:
- 禁止进行指令重排序。
- 读写一个变量时,都是直接操作主内存。
在一个变量被 volatile 修饰后,JVM 会为我们做两件事:
- 在每个 volatile 写操作前插入 StoreStore 屏障,在写操作后插入 StoreLoad 屏障。
- 在每个 volatile 读操作前插入 LoadLoad 屏障,在读操作后插入 LoadStore 屏障。
或许这样说有些抽象,我们看一看刚才线程A代码的例子:
boolean contextReady = false; // 在线程A中执行: context = loadContext(); contextReady = true;
我们给 contextReady 增加 volatile 修饰符,会带来什么效果呢?

由于加入了 StoreStore 屏障,屏障上方的普通写入语句 context = loadContext() 和屏障下方的 volatile 写入语句 contextReady = true 无法交换顺序,从而成功阻止了指令重排序。

也就是说,当程序执行到 volatile 变量的读或写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见。
volatile特性之一:
保证变量在线程之间的可见性。可见性的保证是基于 CPU 的内存屏障指令,被 JSR-133 抽象为 happens-before 原则。
volatile特性之二:
阻止编译时和运行时的指令重排。编译时 JVM 编译器遵循内存屏障的约束,运行时依靠 CPU 屏障指令来阻止重排。
volatile 除了保证可见性和有序性,还解决了 long 类型和 double 类型数据的 8 字节赋值问题。虚拟机规范中允许对 64 位数据类型,分为 2 次 32 位的操作来处理,当读取一个非 volatile 类型的 long 变量时,如果对该变量的读操作和写操作不在同一个线程中执行,那么很有可能会读取到某个值得高 32 位和另一个值得低 32 位。

