

python 机器学习记录
dataset = sns.load_dataset("iris") gaierror Traceback (most recent call last)
https://blog.csdn.net/AcStudio/article/details/106772665
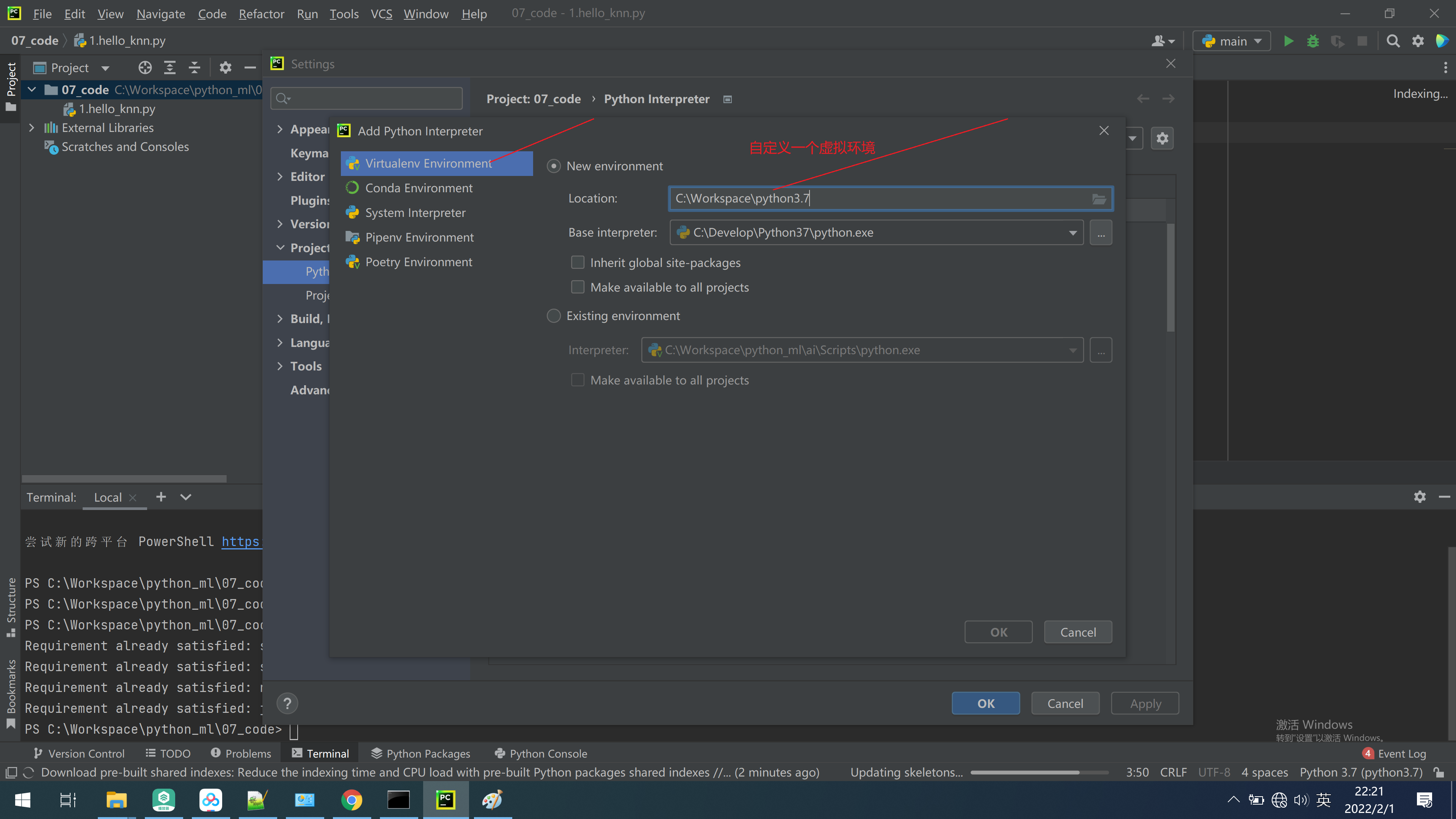
pycharm 自定义创建一个虚拟环境
https://qa.1r1g.com/sf/ask/2287251711/
pip install scikit-learn==0.21.3 安装失败,
Running setup.py install for scikit-learn error
【
pip install cython
pip install scikit-learn==0.21.3
】
切比雪夫距离

K值选择问题,李航博士的一书「统计学习方法」上所说
1) 选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
2) 选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
3) K=N(N为训练样本个数),则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单,忽略了训练实例中大量有用信息。
在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是把训练数据在分成两组:训练集和验证集)来选择最优的K值。
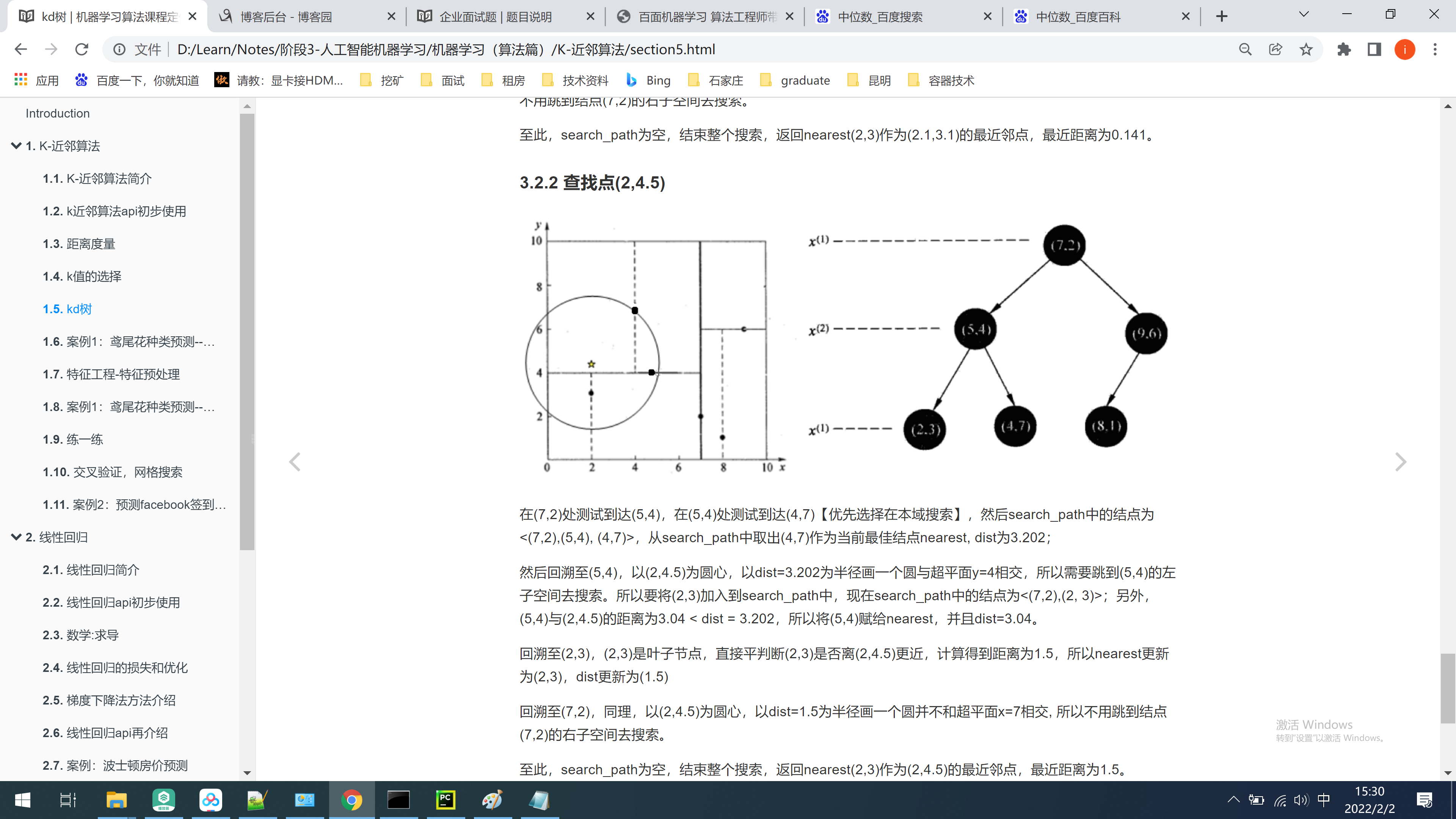
KD树 Kd-树是K-dimension tree
matplotlib中文乱码
#解决中文显示问题
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题



部分机器学习数据源
数据来源:https://www.kaggle.com/starbucks/store-locations/data
国外的kaggle,国内的天池
estimator = GridSearchCV(estimator=estimator,param_grid=param_grid, cv=3, n_jobs=-1)
n_jobs=-1表示多少个cpu跑,-1表示有多少用多少


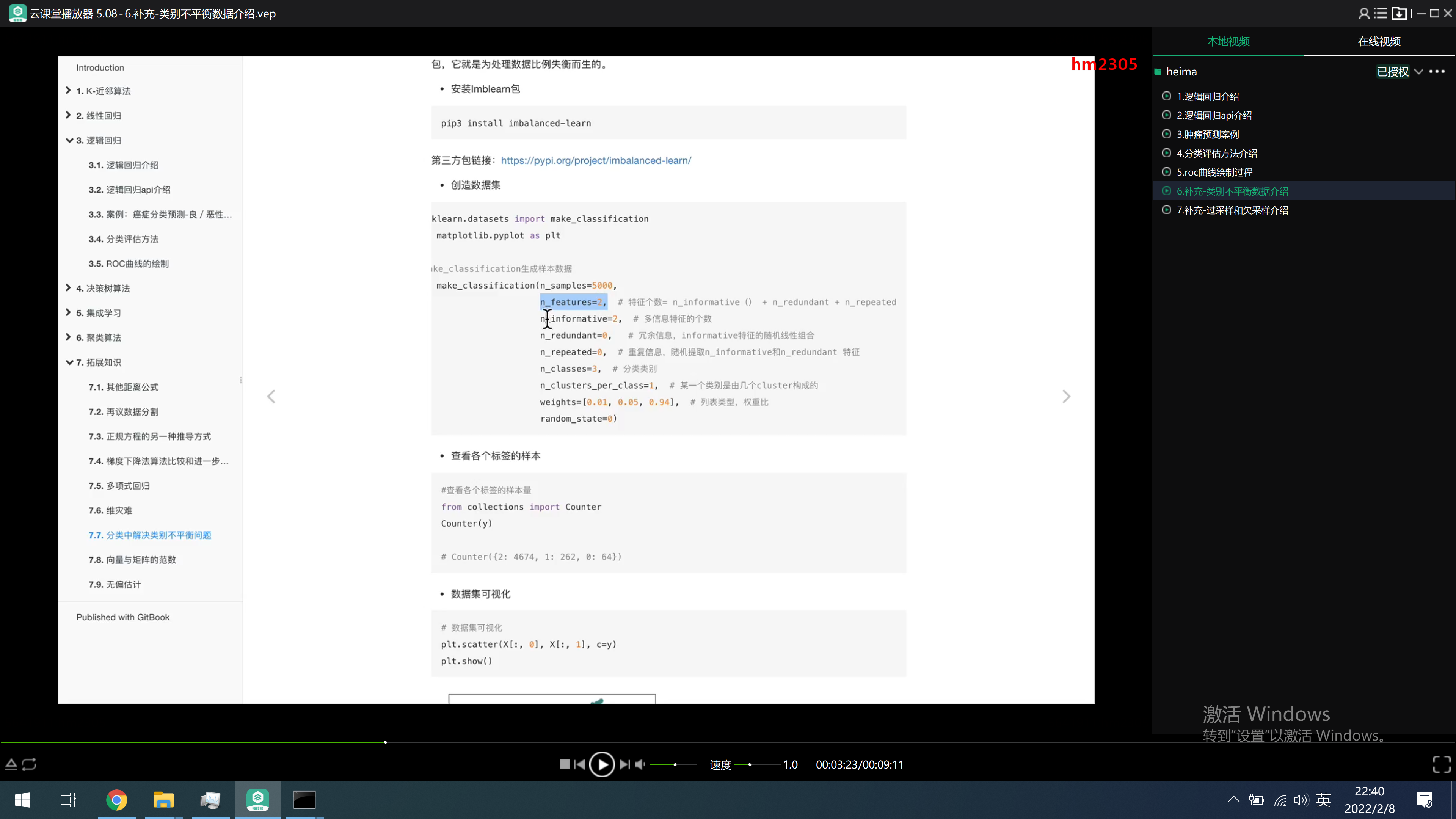
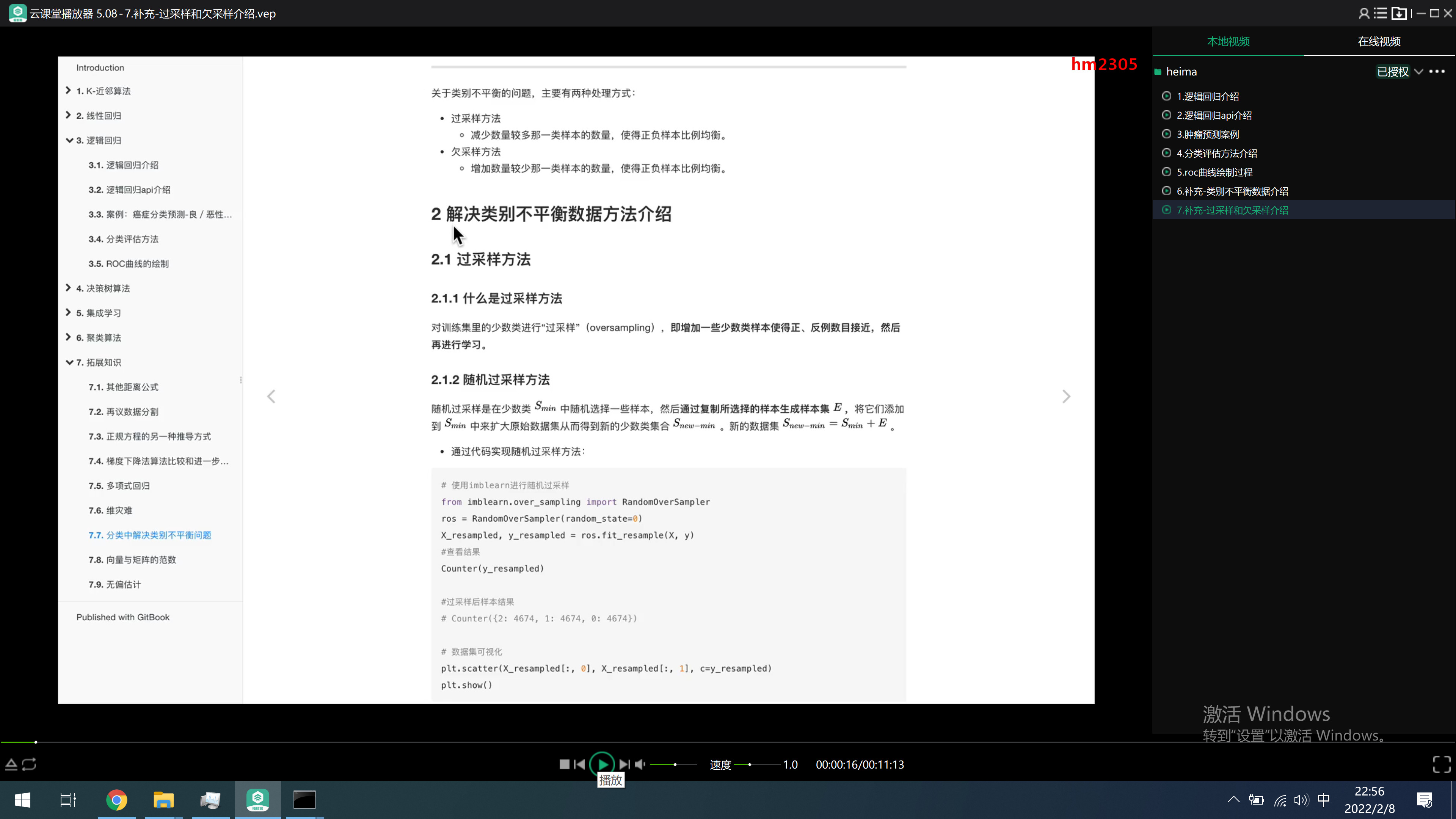




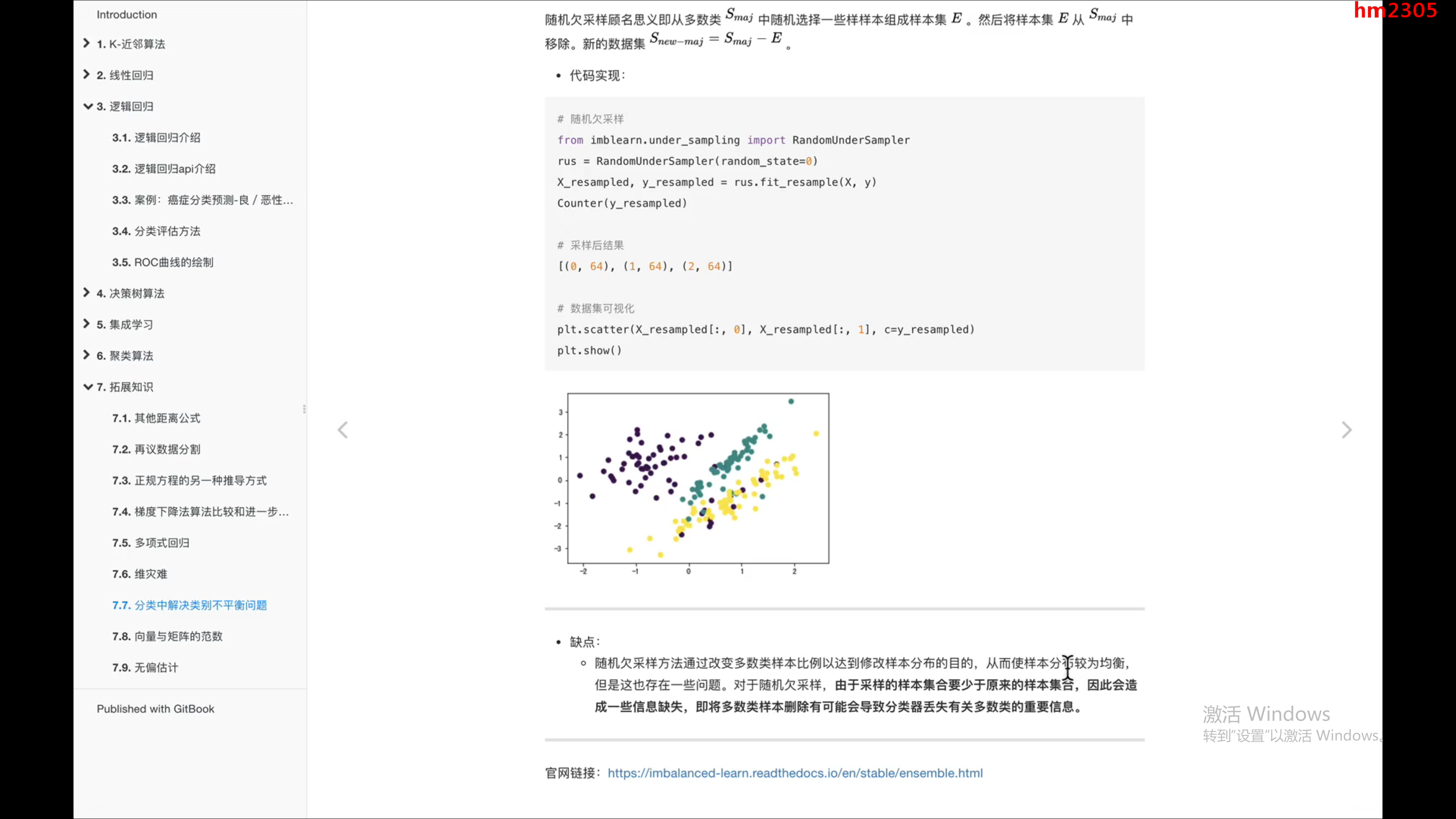
https://imbalanced-learn.org/stable/auto_examples/index.html
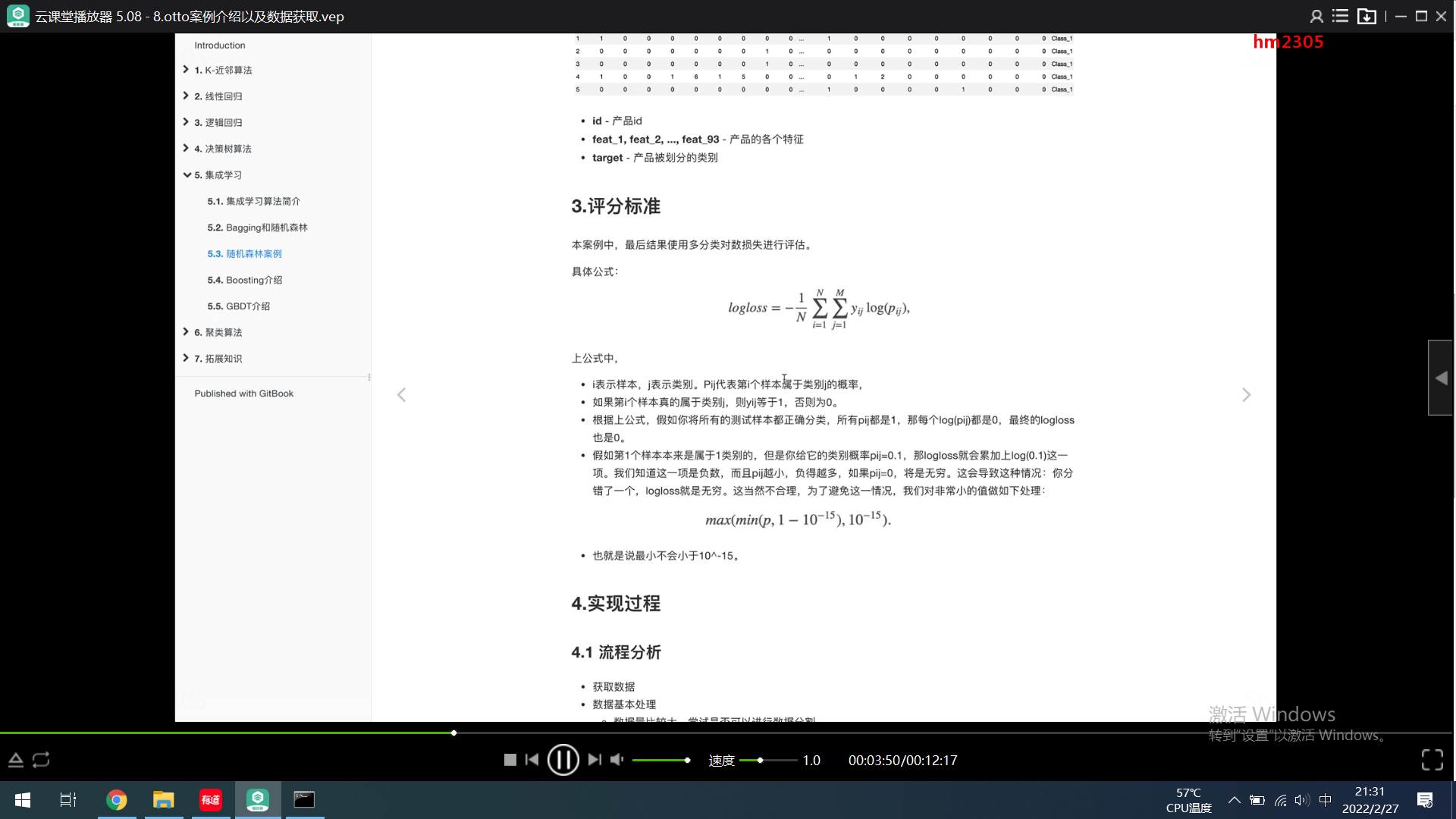
https://www.kaggle.com/c/otto-group-product-classification-challenge
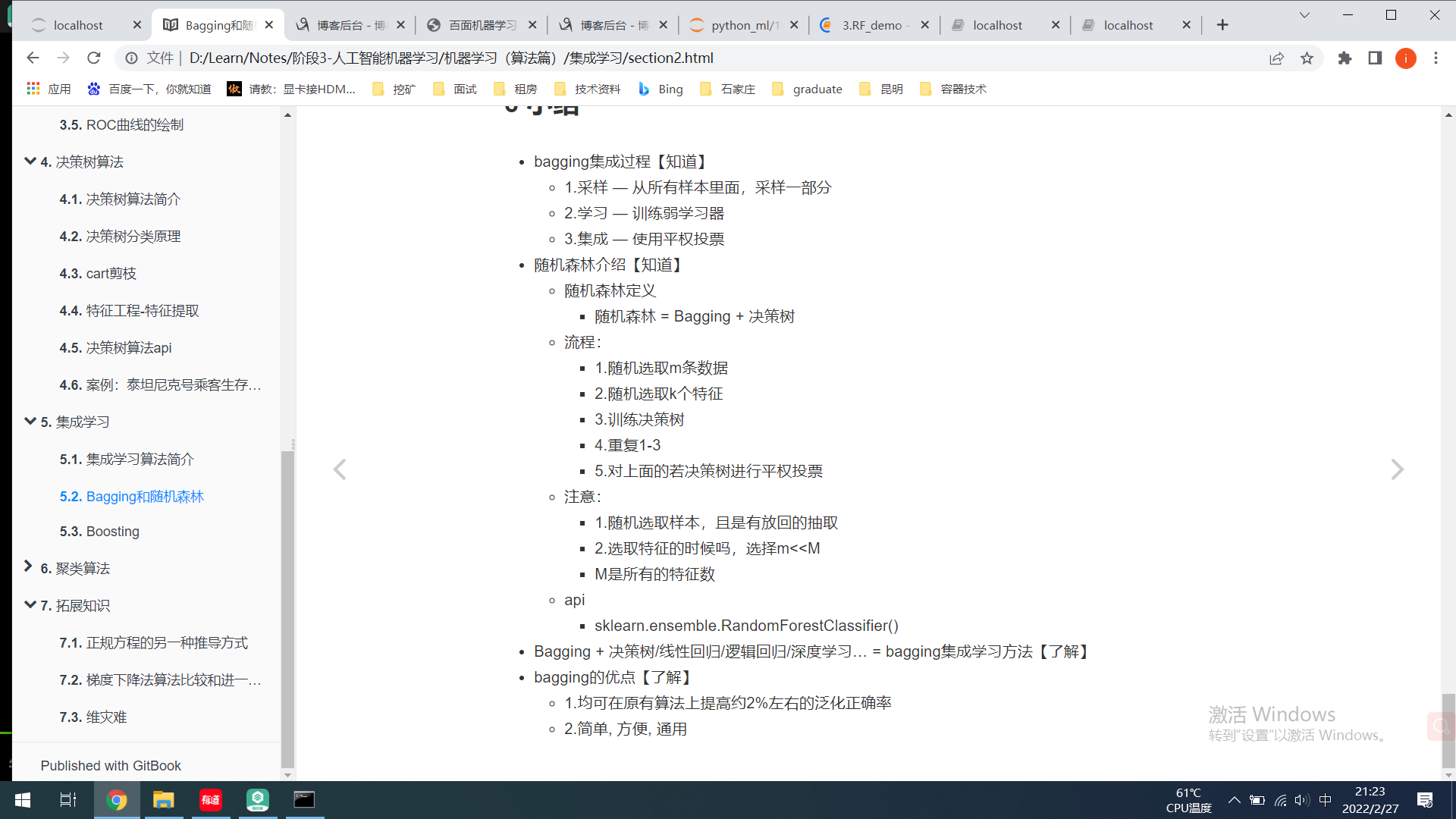
袋外估计
https://blog.csdn.net/zehui6202/article/details/79625639
提交物



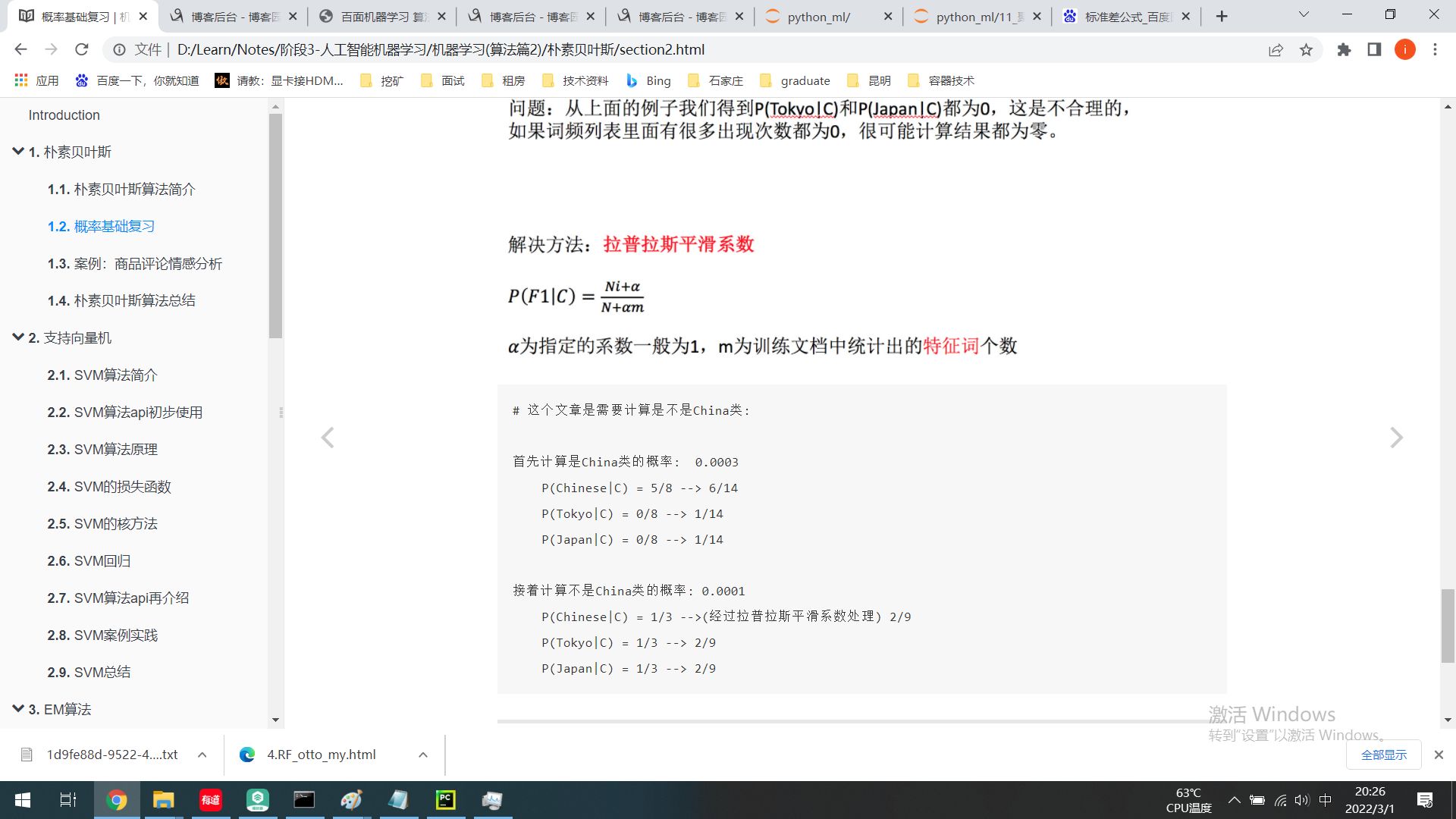
而朴素贝叶斯可以帮助我们解决这个问题。
-
朴素贝叶斯,简单理解,就是假定了特征与特征之间相互独立的贝叶斯公式。
-
也就是说,朴素贝叶斯,之所以朴素,就在于假定了特征与特征相互独立。

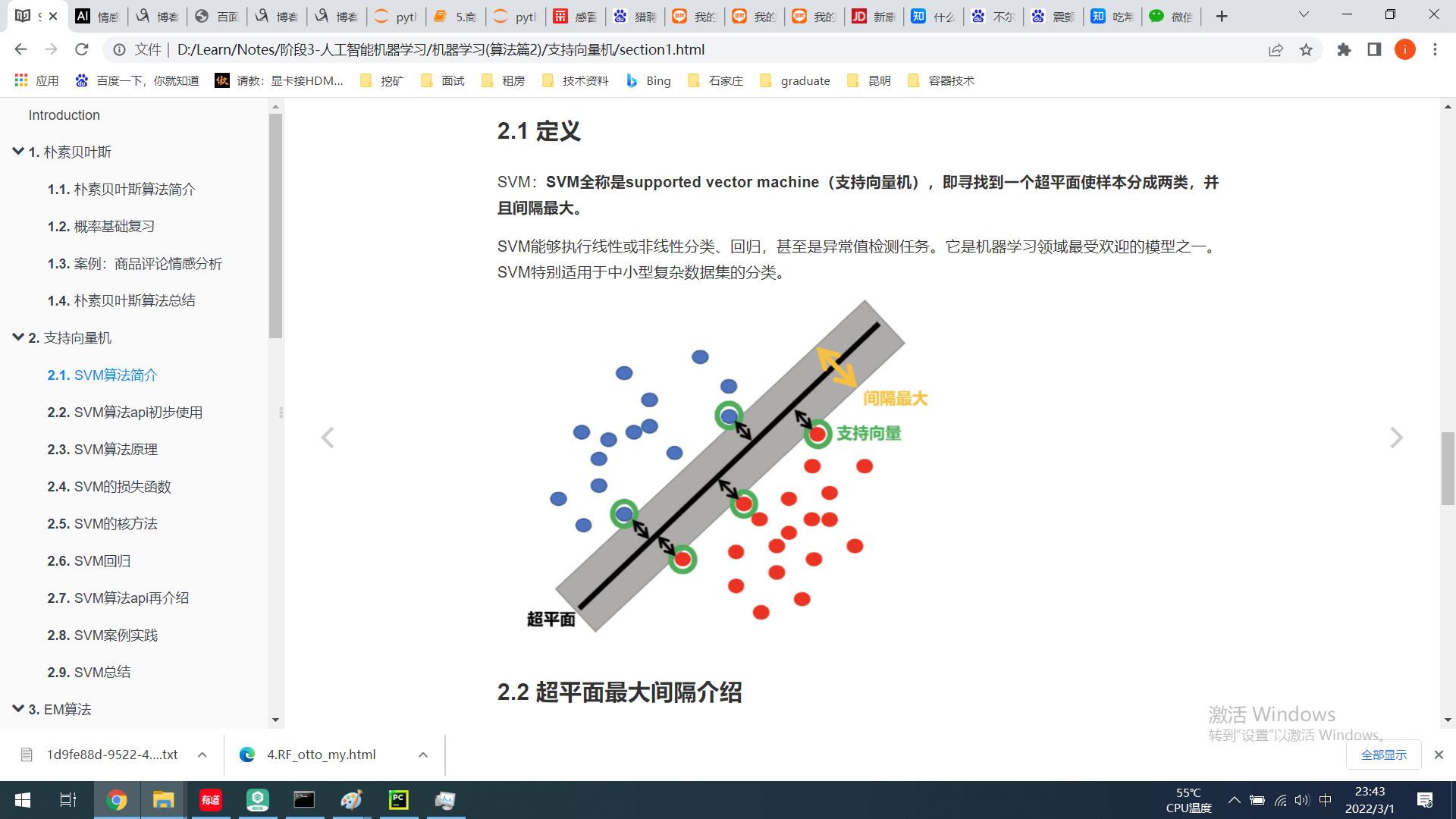

百度情感类分析api:
https://ai.baidu.com/tech/nlp_apply/sentiment_classify
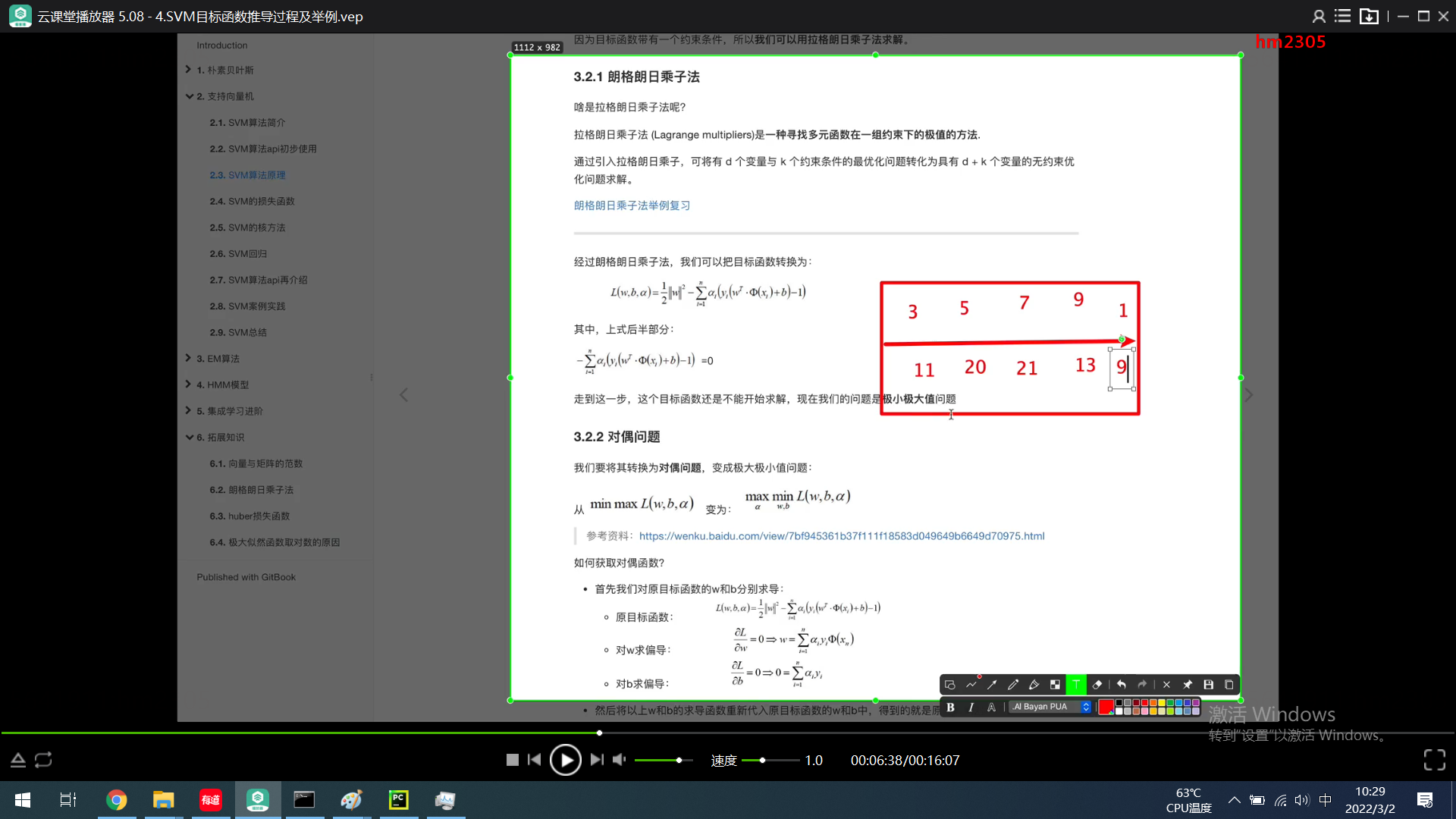
SVM 推导
https://www.zhihu.com/question/30434540/answer/486366689







 浙公网安备 33010602011771号
浙公网安备 33010602011771号