

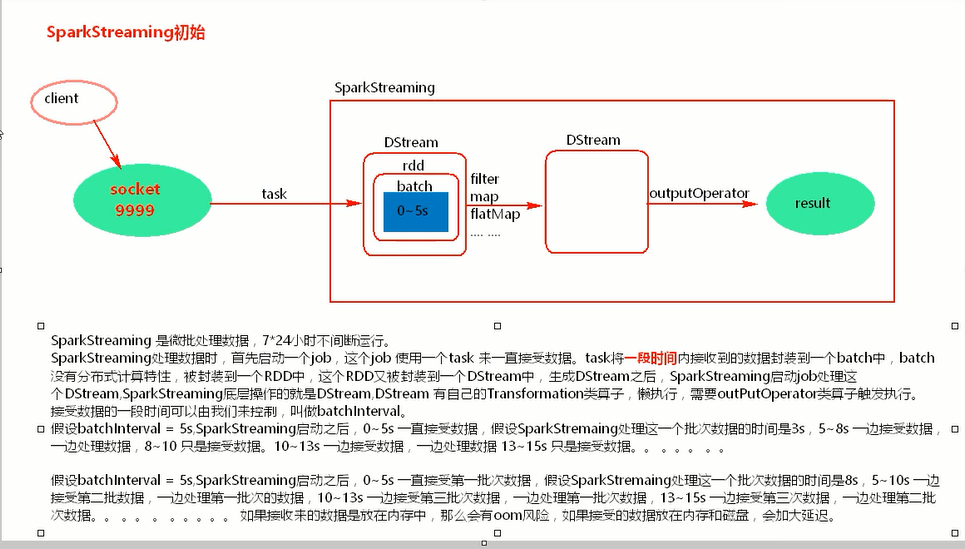
spark streaming

discretized 离散化的 http://spark.apache.org/docs/1.6.0/streaming-programming-guide.html#overview
[root@node5 ~]# yum install nc
[root@node5 ~]# nc -lk 9999
package com.bjsxt.spark;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
public class SparkStreamingTest {
public static void main(String[] args) {
// local[1] 时只有一个task,被占用为接收数据,打印输出没有任务线程执行
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparkStreamingTest");
final JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("WARN");
JavaStreamingContext jsc = new JavaStreamingContext(sc,Durations.seconds(5));
JavaReceiverInputDStream<String> socketTextStream = jsc.socketTextStream("node5",9999);
JavaDStream<String> words = socketTextStream.flatMap(new FlatMapFunction<String,String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String lines) throws Exception {
return Arrays.asList(lines.split(" "));
}
});
JavaPairDStream<String,Integer> pairWords = words.mapToPair(new PairFunction<String, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word,1);
}
});
JavaPairDStream<String, Integer> reduceByKey = pairWords.reduceByKey(new Function2<Integer, Integer, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
System.out.println("rdd reduceByKey************************");
return v1 + v2;
}
});
// reduceByKey.print(1000);
/**
* foreachRDD 可以拿到DStream中的RDD,对拿到的RDD可以使用RDD的transformation类算子转换,要对拿到的RDD使用action算子触发执行,否则,foreachRDD也不会执行。
* foreachRDD中call方法内,拿到的RDD的算子外,代码是在Driver端执行;可以使用这个算子动态改变广播变量(使用配置文件的方式)
*/
reduceByKey.foreachRDD(new VoidFunction<JavaPairRDD<String,Integer>>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public void call(JavaPairRDD<String, Integer> rdd)
throws Exception {
// Driver中获取SparkContext的正确方式; 中获取广播变量的正确方式。
SparkContext context = rdd.context();
JavaSparkContext sc = new JavaSparkContext(context);
Broadcast<String> broadcast = sc.broadcast("hello");
String value = broadcast.value();
System.out.println("Driver.........");
JavaPairRDD<String, Integer> mapToPair = rdd.mapToPair(new PairFunction<Tuple2<String,Integer>, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(
Tuple2<String, Integer> tuple) throws Exception {
System.out.println("Executor.........");
return new Tuple2<String,Integer>(tuple._1,tuple._2);
}
});
mapToPair.foreach(new VoidFunction<Tuple2<String,Integer>>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Integer> arg0)
throws Exception {
System.out.println(arg0);
}
});
}
});
jsc.start();
jsc.awaitTermination();
jsc.stop();
}
}
[root@node5 ~]# nc -lk 9999 ## linux 发送socket数据。
hello sxt
hello bj
hello
hello
zhongguo
zhngguo
zhongguo
* foreachRDD能够动态获取广播变量, * 能顾获取到JavaSparkContext,说明是在Driver端执行
checkpoint 在内存中也存在一份,磁盘中保存一份。
package com.bjsxt.sparkstreaming;
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import com.google.common.base.Optional;
import scala.Tuple2;
/**
* UpdateStateByKey的主要功能:
* 1、为Spark Streaming中每一个Key维护一份state状态,state类型可以是任意类型的, 可以是一个自定义的对象,那么更新函数也可以是自定义的。
* 2、通过更新函数对该key的状态不断更新,对于每个新的batch而言,Spark Streaming会在使用updateStateByKey的时候为已经存在的key进行state的状态更新
*
* hello,3
* bjsxt,2
*
* 如果要不断的更新每个key的state,就一定涉及到了状态的保存和容错,这个时候就需要开启checkpoint机制和功能
*
* 全面的广告点击分析
* @author root
*
* 有何用? 统计广告点击流量,统计这一天的车流量,统计点击量
*/
public class UpdateStateByKeyOperator {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("UpdateStateByKeyDemo");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
/**
* 设置checkpoint目录
*
* 多久会将内存中的数据(每一个key所对应的状态)写入到磁盘上一份呢?
* 如果你的batchInterval小于10s 那么10s会将内存中的数据写入到磁盘一份
* 如果bacthInterval 大于10s,那么就以bacthInterval为准
*
* 这样做是为了防止频繁的写HDFS
*/
// JavaSparkContext sc = jsc.sparkContext();
// sc.setCheckpointDir("./checkpoint");
// jsc.checkpoint("hdfs://node1:9000/spark/checkpoint");
jsc.checkpoint("./checkpoint");
JavaReceiverInputDStream<String> lines = jsc.socketTextStream("node5", 9999);
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String s) {
return Arrays.asList(s.split(" "));
}
});
JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairDStream<String, Integer> counts =
ones.updateStateByKey(new Function2<List<Integer>, Optional<Integer>, Optional<Integer>>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Optional<Integer> call(List<Integer> values, Optional<Integer> state) throws Exception {
/**
* values:经过分组最后 这个key所对应的value [1,1,1,1,1]
* state:这个key在本次之前之前的状态
*/
Integer updateValue = 0 ;
if(state.isPresent()){
updateValue = state.get();
}
for(Integer value : values) {
updateValue += value;
}
return Optional.of(updateValue);
}
});
//output operator
counts.print();
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
// 窗口长度和滑动间隔必须是批次的整数倍
package com.bjsxt.sparkstreaming;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
/**
* 基于滑动窗口的热点搜索词实时统计
* @author root
*
*/
public class WindowOperator {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setMaster("local[2]")
.setAppName("WindowHotWord");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
/**
* 设置日志级别为WARN
*
*/
jssc.sparkContext().setLogLevel("WARN");
/**
* 注意:
* 没有优化的窗口函数可以不设置checkpoint目录
* 优化的窗口函数必须设置checkpoint目录
*/
// jssc.checkpoint("hdfs://node1:9000/spark/checkpoint");
jssc.checkpoint("./checkpoint");
JavaReceiverInputDStream<String> searchLogsDStream = jssc.socketTextStream("node5", 9999);
// JavaDStream<String> window = searchLogsDStream.window(Durations.seconds(15), Durations.seconds(5));
//word 1
JavaDStream<String> searchWordsDStream = searchLogsDStream.flatMap(new FlatMapFunction<String, String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String t) throws Exception {
return Arrays.asList(t.split(" "));
}
});
// 将搜索词映射为(searchWord, 1)的tuple格式
JavaPairDStream<String, Integer> searchWordPairDStream = searchWordsDStream.mapToPair(
new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String searchWord)
throws Exception {
return new Tuple2<String, Integer>(searchWord, 1);
}
});
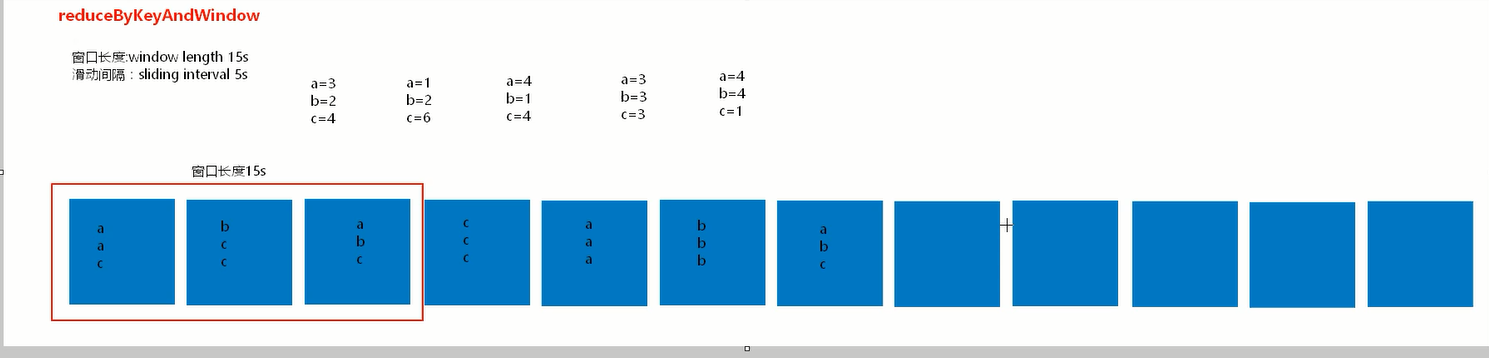
/**
* 每隔10秒,计算最近60秒内的数据,那么这个窗口大小就是60秒,里面有12个rdd,在没有计算之前,这些rdd是不会进行计算的。
* 那么在计算的时候会将这12个rdd聚合起来,然后一起执行reduceByKeyAndWindow操作 ,
* reduceByKeyAndWindow是针对窗口操作的而不是针对DStream操作的。
*/
// JavaPairDStream<String, Integer> searchWordCountsDStream =
//
// searchWordPairDStream.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() {
//
// private static final long serialVersionUID = 1L;
//
// @Override
// public Integer call(Integer v1, Integer v2) throws Exception {
// return v1 + v2;
// }
// }, Durations.seconds(15), Durations.seconds(5));
/**
* window窗口操作优化:
*/
JavaPairDStream<String, Integer> searchWordCountsDStream =
searchWordPairDStream.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
},new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 - v2;
}
}, Durations.seconds(15), Durations.seconds(5));
searchWordCountsDStream.print();
jssc.start();
jssc.awaitTermination();
jssc.close();
}
}
// 设置本地运维模式启动两个线程运行程序
SparkConf conf = new SparkConf()
.setMaster("local[2]")
.setAppName("WindowHotWord");
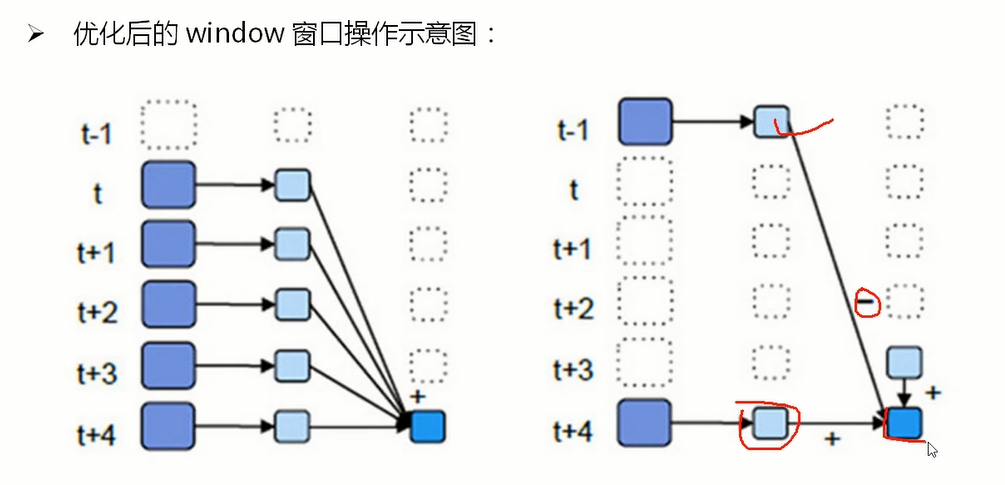
普通机制不需要设置checkpoint; 窗口滑动的优化机制,必须设置checkpoint; 相当于减去出去的批次,增加新进入的批次。
package com.bjsxt.sparkstreaming;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
/**
* 过滤黑名单
* transform操作
* DStream可以通过transform做RDD到RDD的任意操作。
* @author root
*
*/
public class TransformOperator {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local[2]").setAppName("transform");
JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(5));
//黑名单
List<String> list = Arrays.asList("zhangsan");
final Broadcast<List<String>> bcBlackList = jsc.sparkContext().broadcast(list);
//接受socket数据源
JavaReceiverInputDStream<String> nameList = jsc.socketTextStream("node5", 9999);
JavaPairDStream<String, String> pairNameList =
nameList.mapToPair(new PairFunction<String, String, String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(String s) throws Exception {
return new Tuple2<String, String>(s.split(" ")[1], s);
}
});
/**
* transform 可以拿到DStream中的RDD,做RDD到RDD之间的转换,不需要Action算子触发,需要返回RDD类型。
* 注意:transform call方法内,拿到RDD 算子外的代码 在Driver端执行,也可以做到动态改变广播变量。
*/
JavaDStream<String> transFormResult =
pairNameList.transform(new Function<JavaPairRDD<String,String>, JavaRDD<String>>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public JavaRDD<String> call(JavaPairRDD<String, String> nameRDD)
throws Exception {
JavaPairRDD<String, String> filter = nameRDD.filter(new Function<Tuple2<String,String>, Boolean>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<String, String> tuple) throws Exception {
return !bcBlackList.value().contains(tuple._1);
}
});
JavaRDD<String> map = filter.map(new Function<Tuple2<String,String>, String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public String call(Tuple2<String, String> tuple) throws Exception {
return tuple._2;
}
});
//返回过滤好的结果
return map;
}
});
transFormResult.print();
jsc.start();
jsc.awaitTermination();
jsc.stop();
}
}
监控socket需要2个task,因为spark streaming 底层监控socket需要有一个task一致receive.另外一个负责运行程序。setMaster("local[2]")
监控文件夹则可以不需要两个task,一个task也可。setMaster("local")
spark streaming 监控文件夹。
package streamingOperate.transformations;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
/**
* 通过func函数过滤返回为true的记录,返回一个新的Dstream
* @author root
*
*/
public class Operate_filter {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("Operate_filter");
JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(5));
JavaDStream<String> textFileStream = jsc.textFileStream("data");
/**
* 下面的例子是每次读入一行数据,通过观察文件,看到第一行为“crosses the repetition to duplicate daily,”开头
* 所以下面将过滤只显示以“crosses the repetition to duplicate daily,”开头的行
*/
textFileStream.filter(new Function<String,Boolean>(){
/**
*
*/
private static final long serialVersionUID = 1L;
public Boolean call(String line) throws Exception {
return line.startsWith("a 100");
}
}).print(1000);
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
// 不能监控手动修改的文件,需要保证文件操作的原子性。
package streamingOperate.util;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.UUID;
/**
* 此复制文件的程序是模拟在data目录下动态生成相同格式的txt文件,用于给sparkstreaming 中 textFileStream提供输入流。
* @author root
*
*/
public class CopyFile_data1 {
public static void main(String[] args) throws IOException, InterruptedException {
while(true){
Thread.sleep(5000);
String uuid = UUID.randomUUID().toString();
System.out.println(uuid);
copyFile(new File("data1.txt"),new File(".\\data\\"+uuid+"----data1.txt"));
}
}
public static void copyFile(File fromFile, File toFile) throws IOException {
FileInputStream ins = new FileInputStream(fromFile);
FileOutputStream out = new FileOutputStream(toFile);
byte[] b = new byte[1024];
@SuppressWarnings("unused")
int n = 0;
while ((n = ins.read(b)) != -1) {
out.write(b, 0, b.length);
}
ins.close();
out.close();
}
}
package streamingOperate.output;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.dstream.DStream;
/**
* saveAsTextFiles(prefix, [suffix]):
* 将此DStream的内容另存为文本文件。每批次数据产生的文件名称格式基于:prefix和suffix: "prefix-TIME_IN_MS[.suffix]".
*
* 注意:
* saveAsTextFile是调用saveAsHadoopFile实现的
* spark中普通rdd可以直接只用saveAsTextFile(path)的方式,保存到本地,但是此时DStream的只有saveAsTextFiles()方法,没有传入路径的方法,
* 其参数只有prefix, suffix
* 其实:DStream中的saveAsTextFiles方法中又调用了rdd中的saveAsTextFile方法,我们需要将path包含在prefix中
*
*/
public class Operate_saveAsTextFiles {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("Operate_saveAsTextFiles");
JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(5));
JavaDStream<String> textFileStream = jsc.textFileStream("./data");
JavaDStream<String> flatMap = textFileStream.flatMap(new FlatMapFunction<String, String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
public Iterable<String> call(String t) throws Exception {
return Arrays.asList(t.split(" "));
}
});
//保存在当前路径中savedata路径下,以prefix开头,以suffix结尾的文件。
DStream<String> dstream = flatMap.dstream();
// dstream.saveAsTextFiles(".\\savedata\\prefix", "suffix");
dstream.saveAsTextFiles(".\\savedata\\spark\\mydate", "aaaa");
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号