


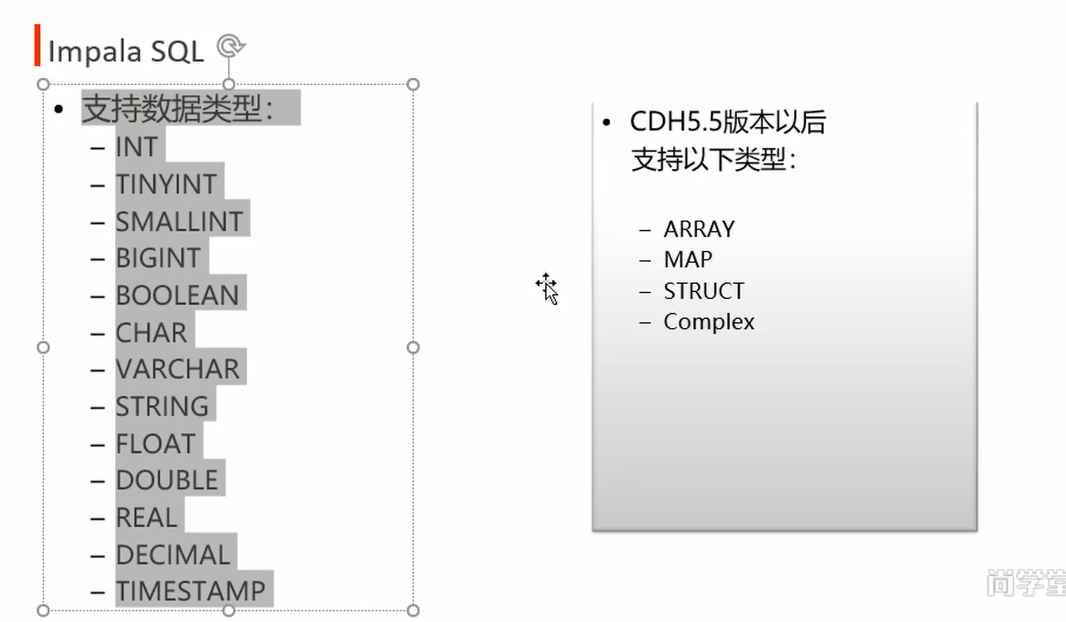
cdh hue impala
hue 英 [hjuː] n. 色彩;色度;色调;叫声
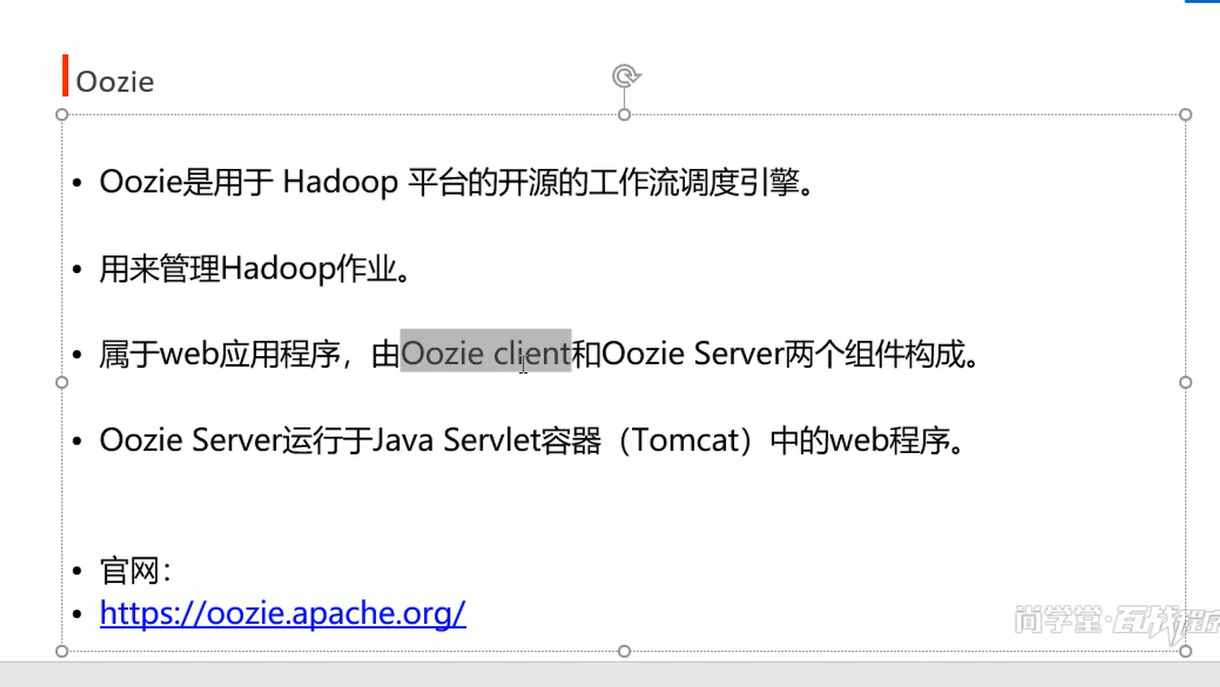
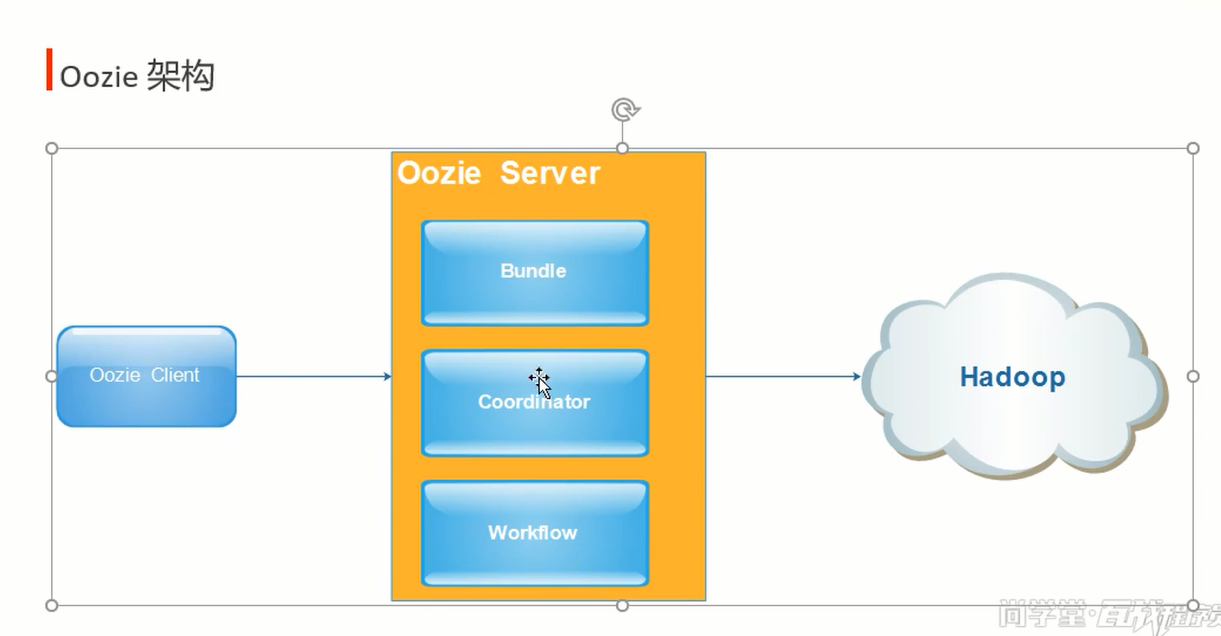
oozie ['uːzɪ] (缅甸的)驯象人,驭象者
Hue是一个开源的Apache Hadoop UI系统。 通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据。 例如操作HDFS上的数据、运行Hive脚本、管理Oozie任务等等。 是基于Python Web框架Django实现的。 支持任何版本Hadoop 基于文件浏览器(File Browser)访问HDFS 基于web编辑器来开发和运行Hive查询 支持基于Solr进行搜索的应用,并提供可视化的数据视图,报表生成 通过web调试和开发impala交互式查询 spark调试和开发 Pig开发和调试 oozie任务的开发,监控,和工作流协调调度 Hbase数据查询和修改,数据展示 Hive的元数据(metastore)查询 MapReduce任务进度查看,日志追踪 创建和提交MapReduce,Streaming,Java job任务 Sqoop2的开发和调试 Zookeeper的浏览和编辑 数据库(MySQL,PostGres,SQlite,Oracle)的查询和展示
调度系统: 作业输入输出有依赖;A执行完成再给信号给B
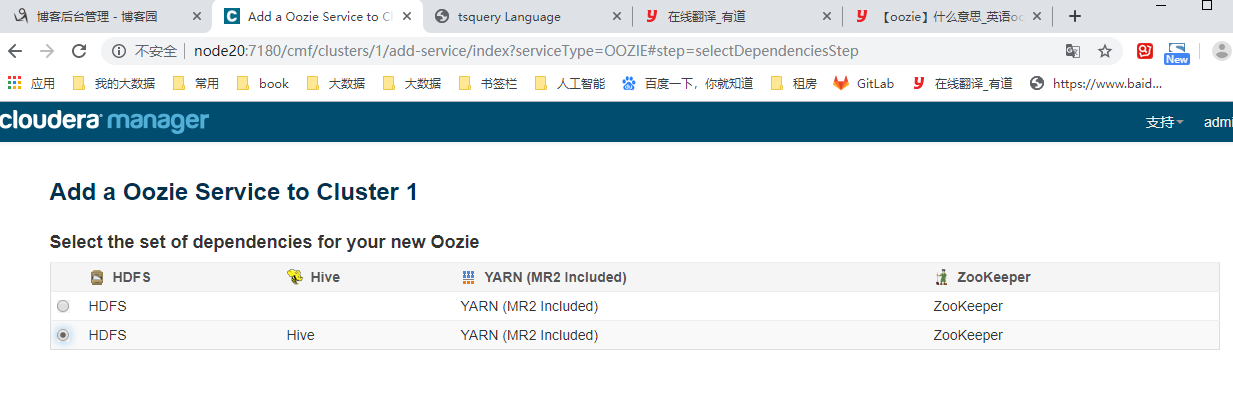
添加hue服务。先添加依赖的服务oozie. mysql> create database oozie DEFAULT CHARACTER SET utf8; mysql> grant all on oozie.* TO 'oozie'@'%' IDENTIFIED BY 'oozie';
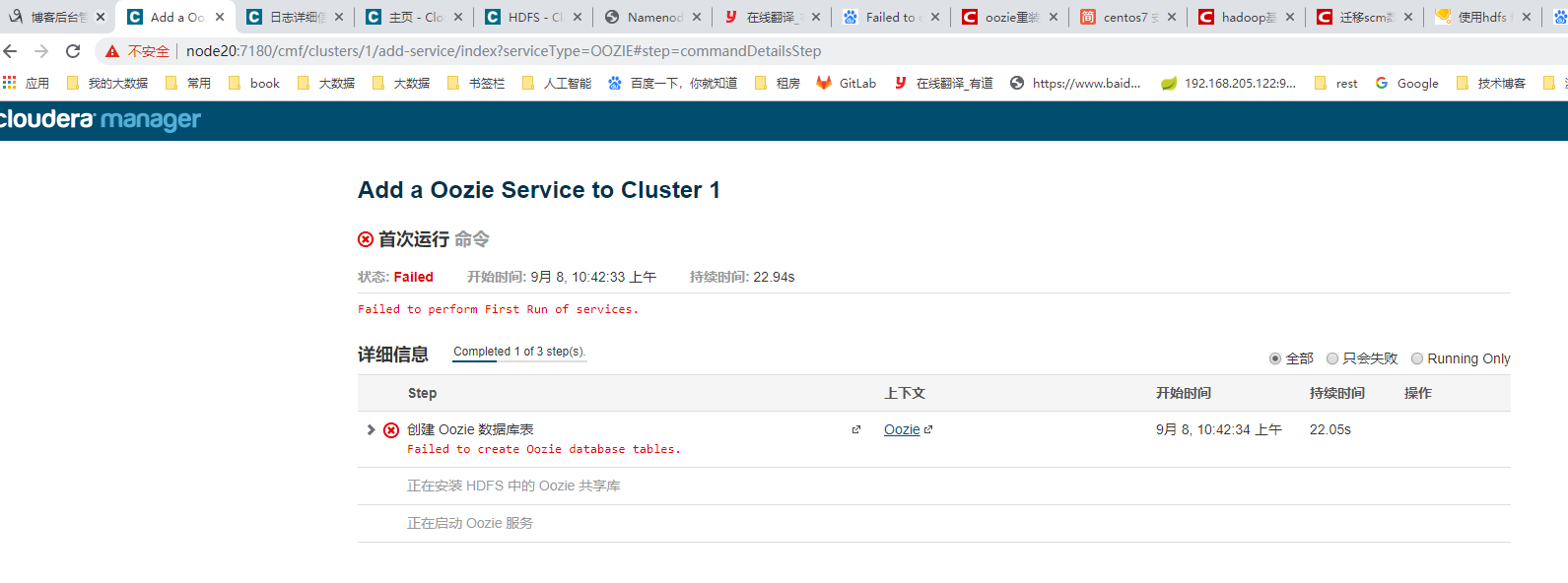
Failed to create Oozie database tables. 直接返回主页启动zoozie即可。 https://blog.csdn.net/qiang0066/article/details/79214441
继续添加hue服务
进入hue服务页点击webUI
创建用户
点击右侧下拉创建用户

点击文件浏览器创建和保存文件
拖拽设计作业链
hue hive 创建表
load上传文件到hive表
impala 英 [ɪm'pɑːlə; -'pælə] 美 n. 黑斑羚(产于非洲中南部) n. (Impala)人名;(意)因帕拉
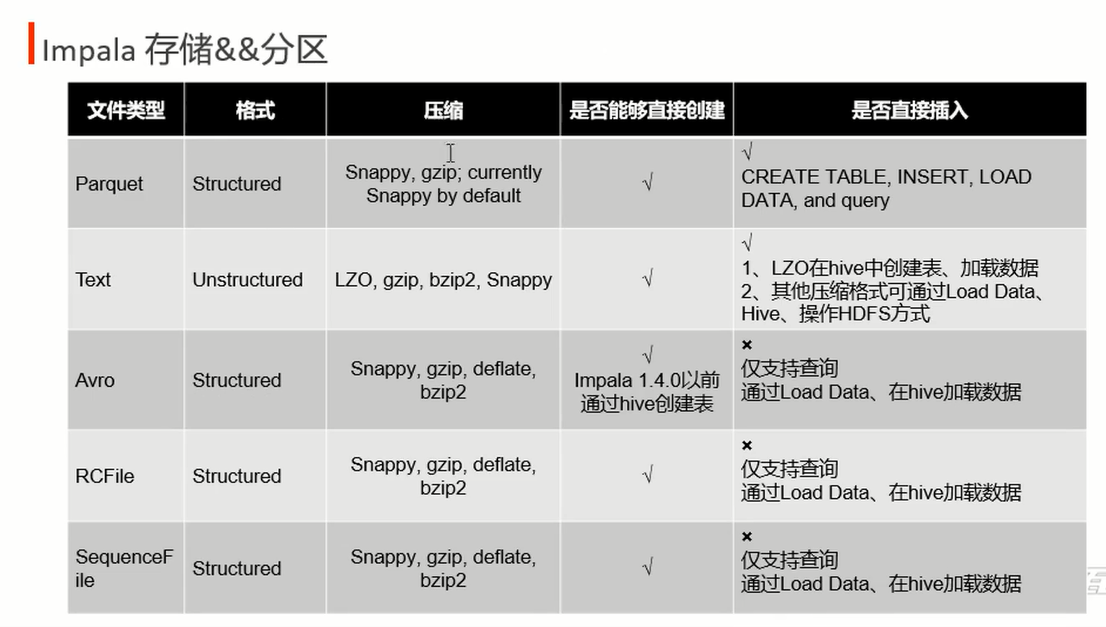
impala 对应hive : 是基于hdfs的sql执行引擎

cloudara推荐impala的服务器的内存为128G;cloudara manager server的内存是64G.
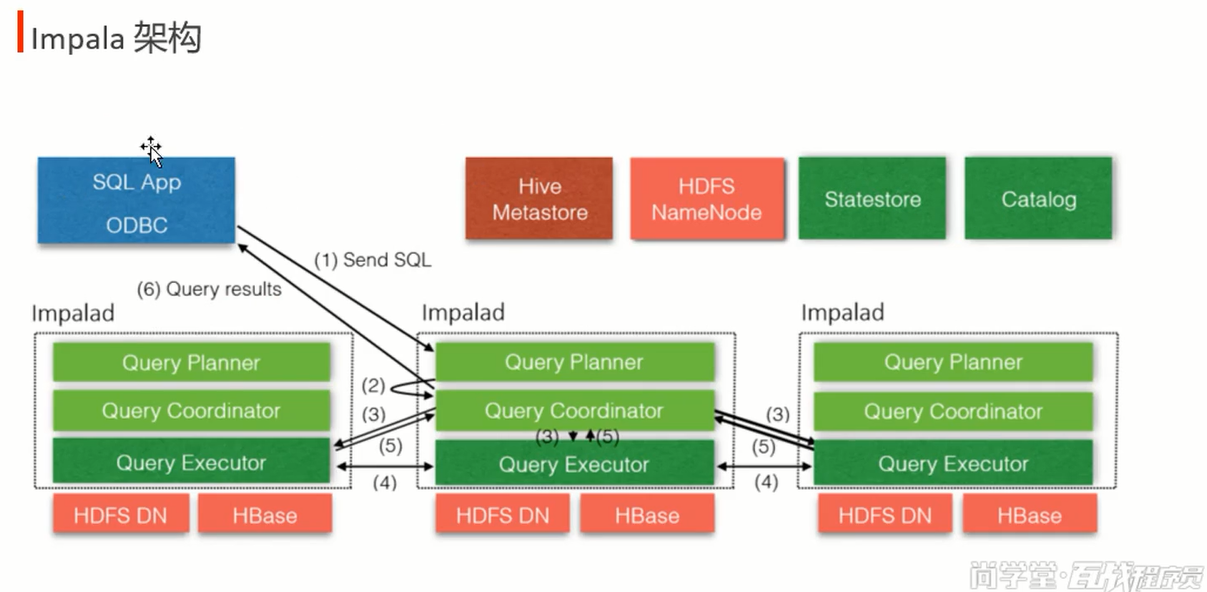
hive <--> Catalog 数据同步,

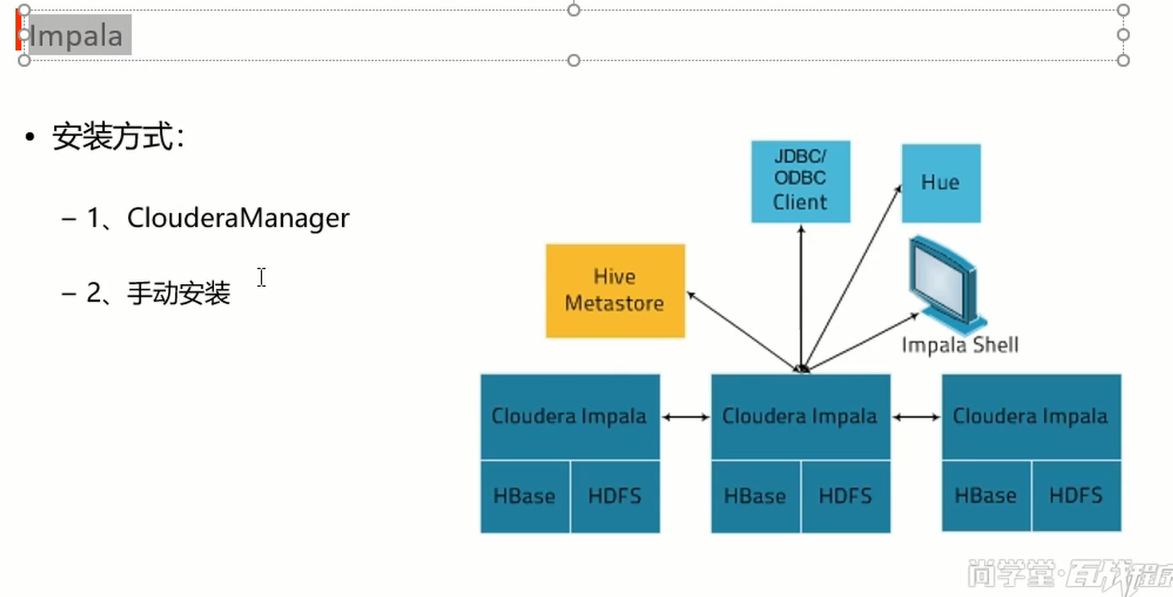
添加impala服务
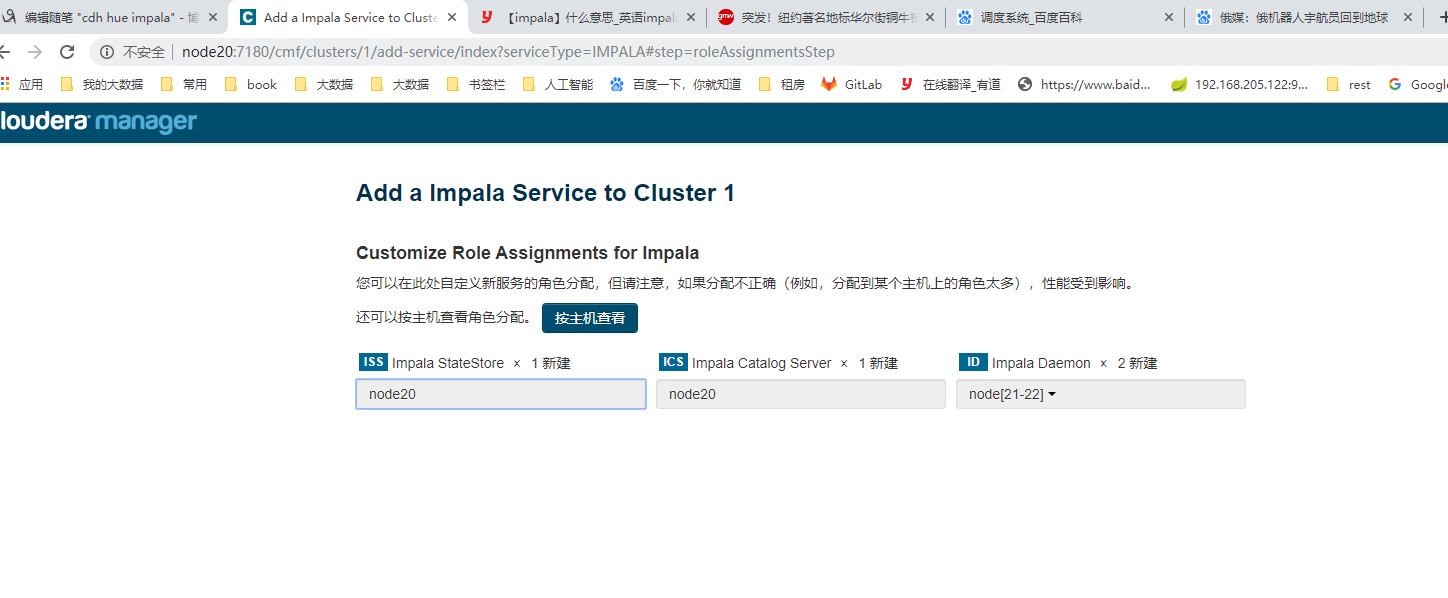
启动impala
[root@node21 ~]# impala-shell Starting Impala Shell without Kerberos authentication Connected to node21:21000 Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build 0c891d79aa38f297d244855a32f1e17280e2129b) *********************************************************************************** Welcome to the Impala shell. Copyright (c) 2015 Cloudera, Inc. All rights reserved. (Impala Shell v2.3.0-cdh5.5.0 (0c891d7) built on Mon Nov 9 12:18:12 PST 2015) The HISTORY command lists all shell commands in chronological order. **********[node21:21000] > show tables; Query: show tables +------+ | name | +------+ | ooxx | +------+ ************************************************************************* [node21:21000] > [root@node22 ~]# hive hive> show tables; ## 已创建的hive表在impala中能够看到。 OK ooxx hive> create table oxox(name string); [node21:21000] > create table xoxo(name string); Query: create table xoxo(name string) ##在hive中创建的表不能在impala中及时看到,在impala中创建的表能够在hive中看到 [node21:21000] > select count(*) name from ooxx; Query: select count(*) name from ooxx +------+ | name | +------+ | 7 | +------+ Fetched 1 row(s) in 10.72s hive> select count(*) name from ooxx; Query ID = root_20190908133636_9a96e840-6a8a-4227-959f-1bb01a14a4d1 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1567832148877_0002, Tracking URL = http://node20:8088/proxy/application_1567832148877_0002/ Kill Command = /opt/cloudera/parcels/CDH-5.5.0-1.cdh5.5.0.p0.8/lib/hadoop/bin/hadoop job -kill job_1567832148877_0002 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2019-09-08 13:37:11,874 Stage-1 map = 0%, reduce = 0% 2019-09-08 13:38:17,502 Stage-1 map = 0%, reduce = 0%, Cumulative CPU 27.07 sec 2019-09-08 13:38:27,805 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 33.58 sec 2019-09-08 13:38:43,354 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 36.66 sec MapReduce Total cumulative CPU time: 36 seconds 660 msec Ended Job = job_1567832148877_0002 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 36.66 sec HDFS Read: 6317 HDFS Write: 2 SUCCESS Total MapReduce CPU Time Spent: 36 seconds 660 msec OK 7 Time taken: 162.49 seconds, Fetched: 1 row(s) ##hive比较慢


默认是 -V 如: [root@node21 ~]# implat-shell -V
[root@node21 ~]# implala-shell -p ## 显示详细执行计划
[root@node21 ~]# impala-shell -q "select * from ooxx" Starting Impala Shell without Kerberos authentication Connected to node21:21000 Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build 0c891d79aa38f297d244855a32f1e17280e2129b) Query: select * from ooxx +----------+ | name | +----------+ | zhangsan | | lisi | | lisi | | zhangsan | | wangwu | | wangsan | | wangsan | +----------+ Fetched 7 row(s) in 0.95s [root@node21 ~]# impala-shell -B -q "select * from ooxx" Starting Impala Shell without Kerberos authentication Connected to node21:21000 Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build 0c891d79aa38f297d244855a32f1e17280e2129b) Query: select * from ooxx zhangsan lisi lisi zhangsan wangwu wangsan wangsan Fetched 7 row(s) in 0.62s [root@node21 ~]# impala-shell -B -q "select * from ooxx" Starting Impala Shell without Kerberos authentication Connected to node21:21000 Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build 0c891d79aa38f297d244855a32f1e17280e2129b) Query: select * from ooxx zhangsan lisi lisi zhangsan wangwu wangsan wangsan Fetched 7 row(s) in 0.62s [root@node21 ~]# impala-shell -B -q "select * from ooxx" >> ooxx Starting Impala Shell without Kerberos authentication Connected to node21:21000 Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build 0c891d79aa38f297d244855a32f1e17280e2129b) Query: select * from ooxx Fetched 7 row(s) in 7.77s [root@node21 ~]# cat ooxx zhangsan lisi lisi zhangsan wangwu wangsan wangsan [root@node21 ~]# cat sql select * from ooxx; select * from xxoo; select * from ooxx; [root@node21 ~]# impala-shell -f sql ## 第二句错误了,第三句不在执行。 [root@node21 ~]# impala-shell -c -f sql ## 第二句错误了,第三句仍然执行。
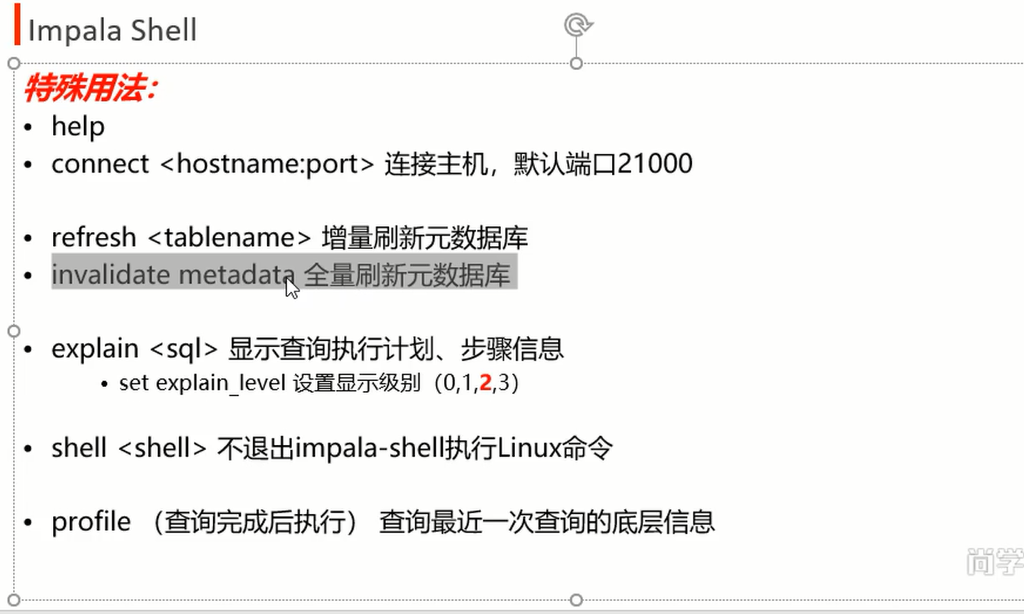
[node21:21000] > show tables; Query: show tables +------+ | name | +------+ | ooxx | | xoxo | +------+ Fetched 2 row(s) in 0.29s [node21:21000] > invalidate metadata; Query: invalidate metadata Fetched 0 row(s) in 5.23s [node21:21000] > show tables; Query: show tables +------+ | name | +------+ | ooxx | | oxox | | xoxo | +------+ [node21:21000] > set explain_level=0; EXPLAIN_LEVEL set to 0 [node21:21000] > explain select count(*) from ooxx; [node21:21000] > set explain_level=4; EXPLAIN_LEVEL set to 4 [node21:21000] > explain select count(*) from ooxx; [node21:21000] > select count(*) name from ooxx; Query: select count(*) name from ooxx +------+ | name | +------+ | 7 | +------+ Fetched 1 row(s) in 30.80s [node21:21000] > profile;








oozie



cd /opt/cloudera-manager/cm-5.5.0/etc/init.d
./cloudera-scm-server start
./cloudera-scm-agent start ## 三台都启动
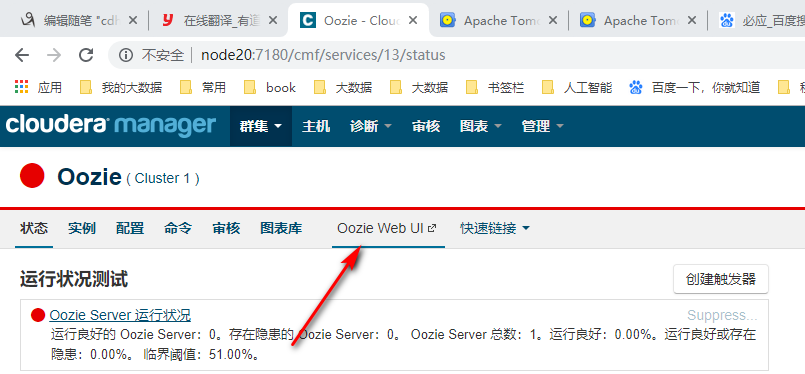
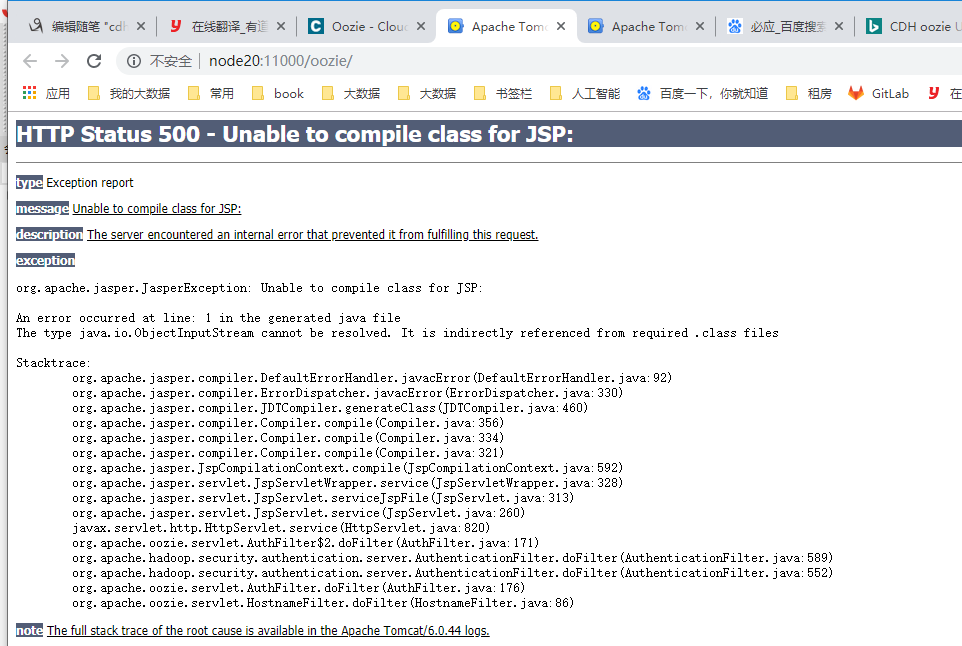
上图是我的页面cdh5.5.0 centos7版本。报错。 下图是老师的oozie报错。他安装Ext.js Ext.2.2.zip 到 /var/lib/oozie/下。
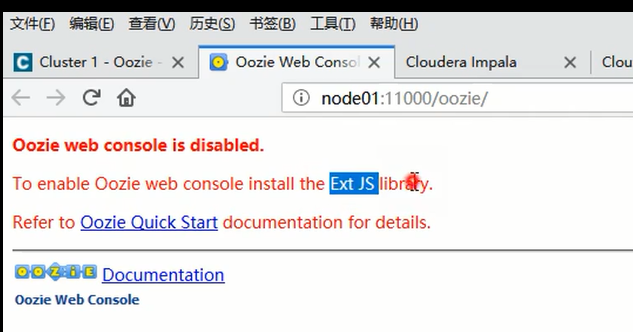
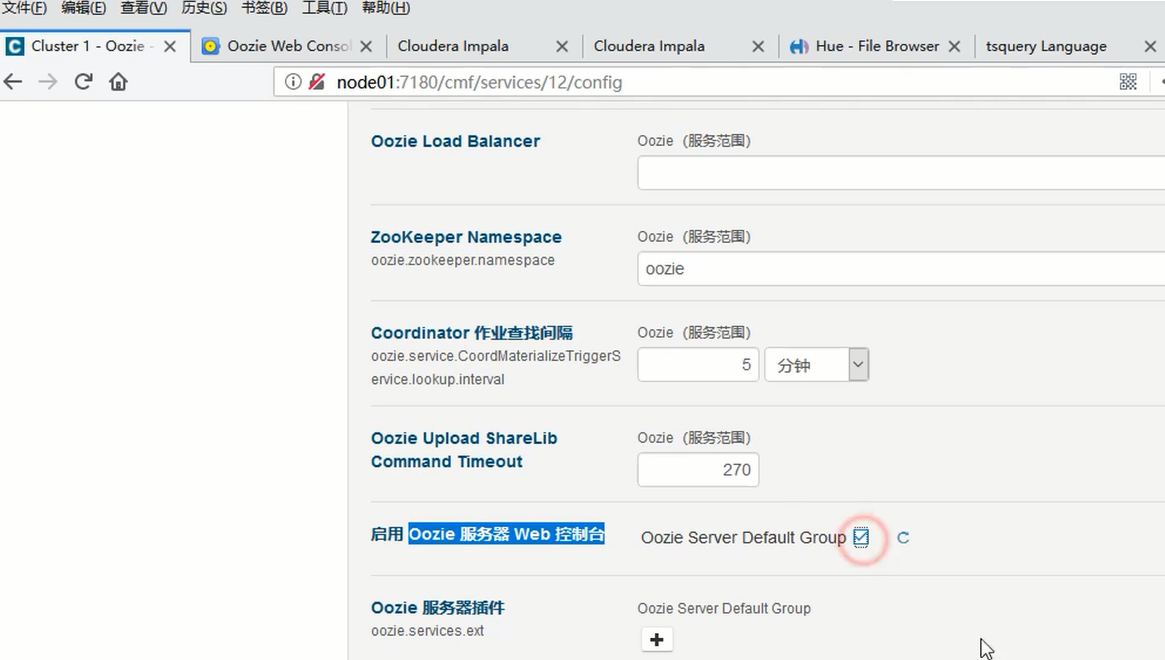
并且修改了如下配置,再保存更改,重启。(老师操作,)可以看到如下页面。

例子演示:oozie提交job ,用上文创建的root用户登录
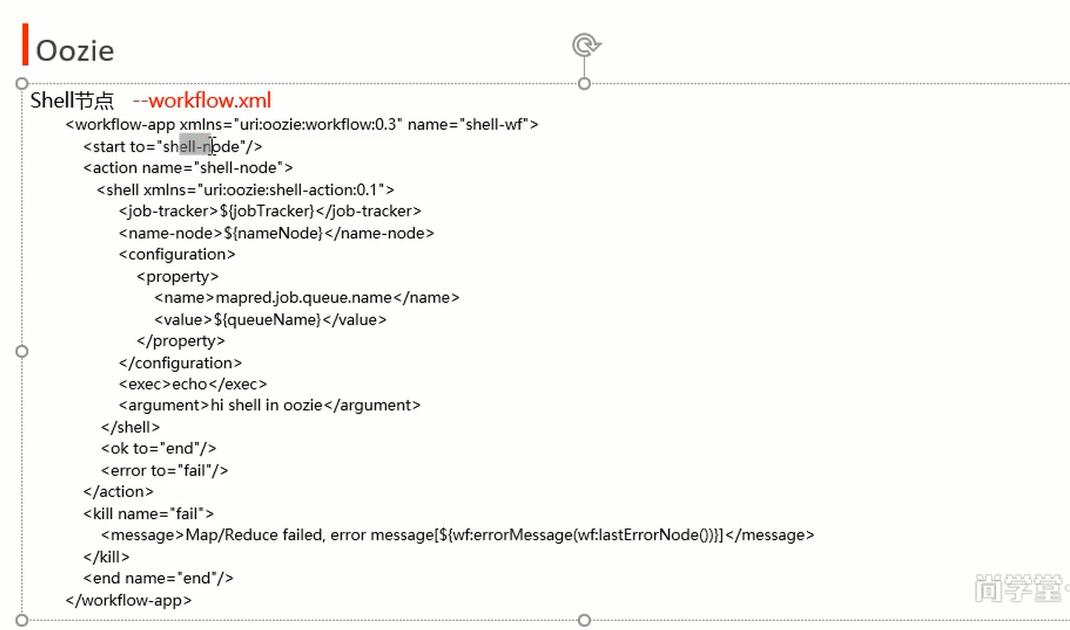
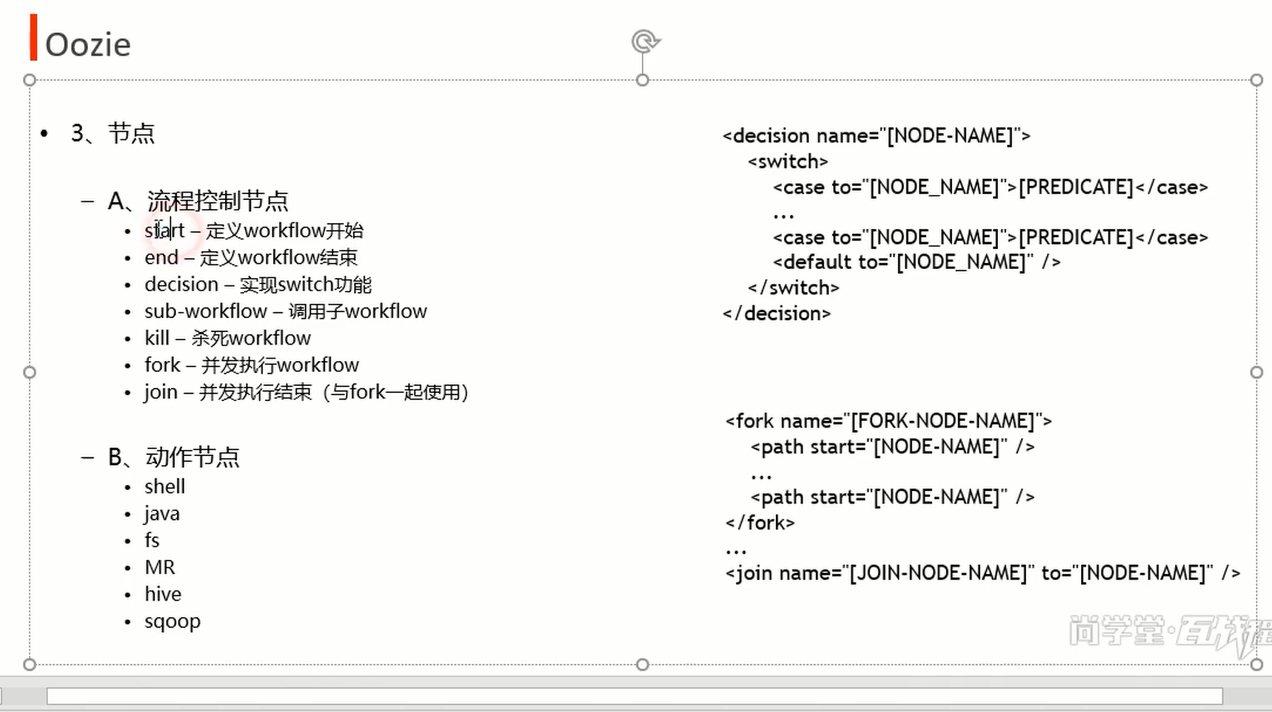
<workflow-app xmlns="uri:oozie:workflow:0.3" name="shell-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>echo</exec>
<argument>hi shell in oozie</argument>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
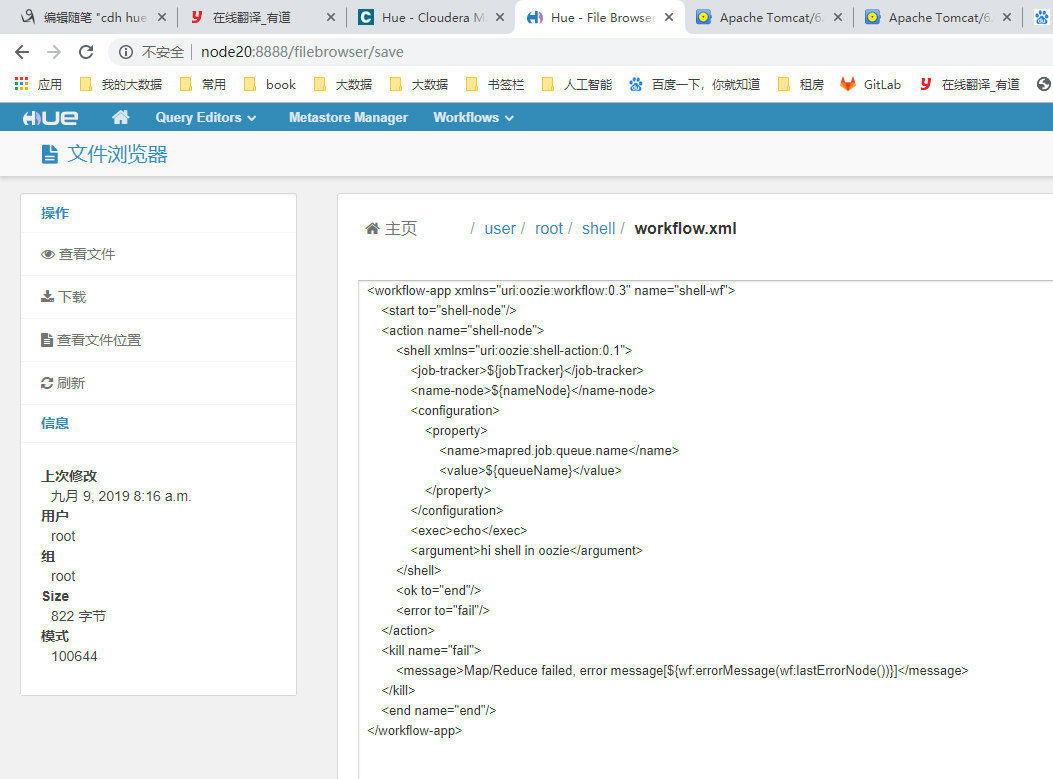
[root@node20 shell]# pwd
/root/shell
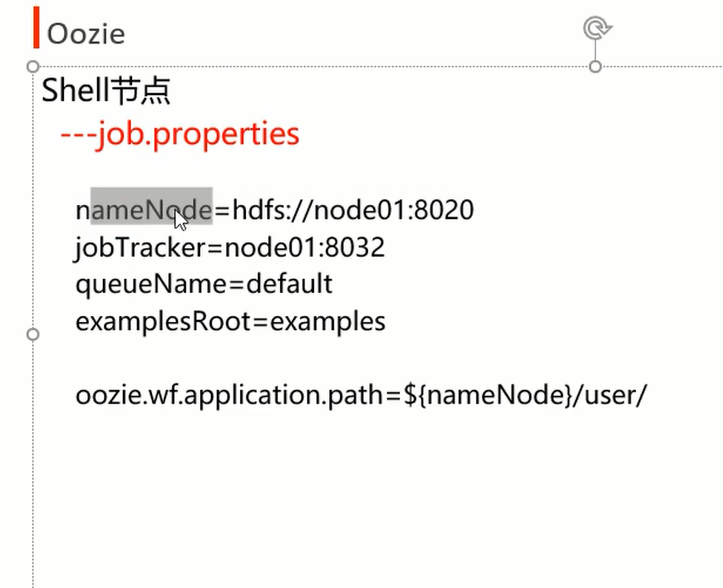
[root@node20 shell]# cat job.properties
nameNode=hdfs://node20:8020
jobTracker=node20:8032
queueName=default
examplesRoot=examples
oozie.wf.application.path=${nameNode}/user/root/shell
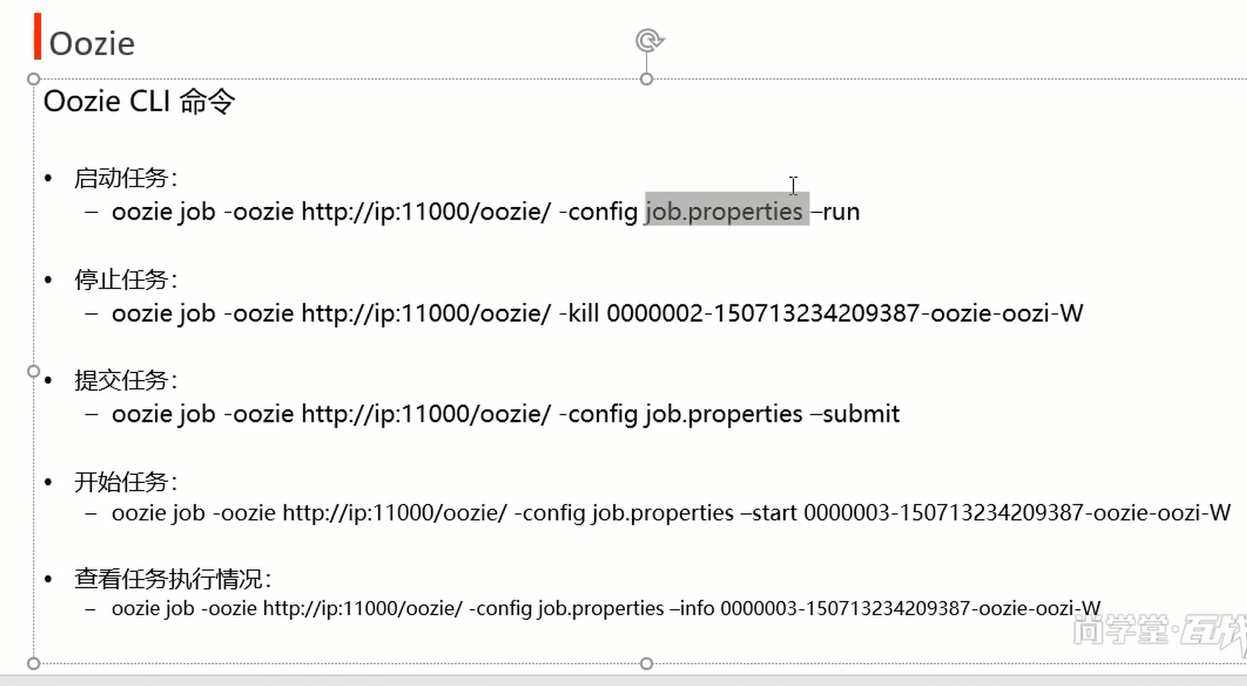
[root@node20 shell]# oozie job --oozie http://node20:11000/oozie/ -config job.properties -run
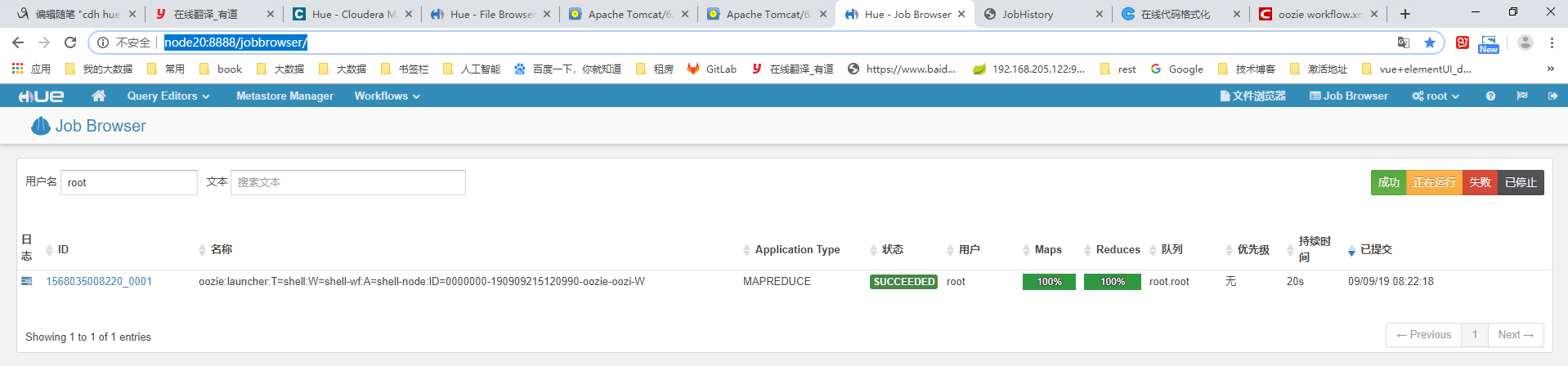
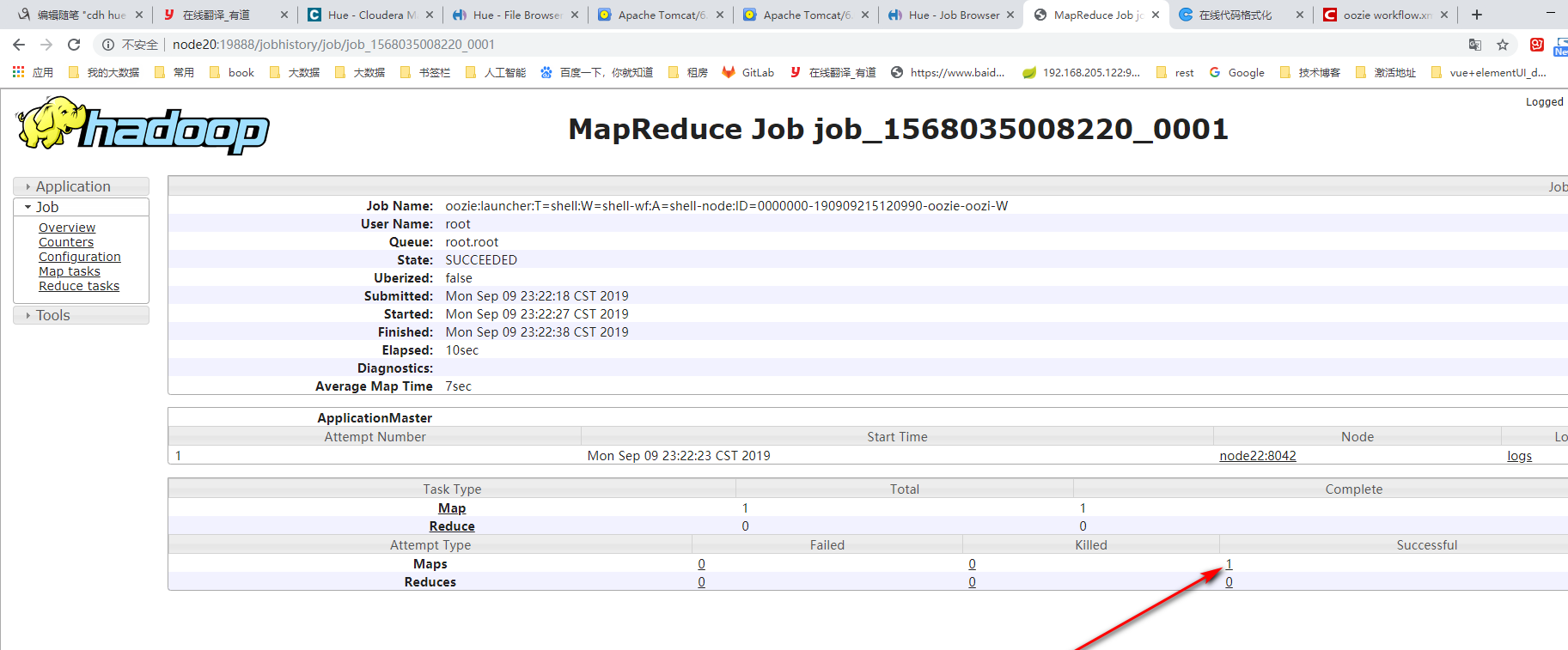
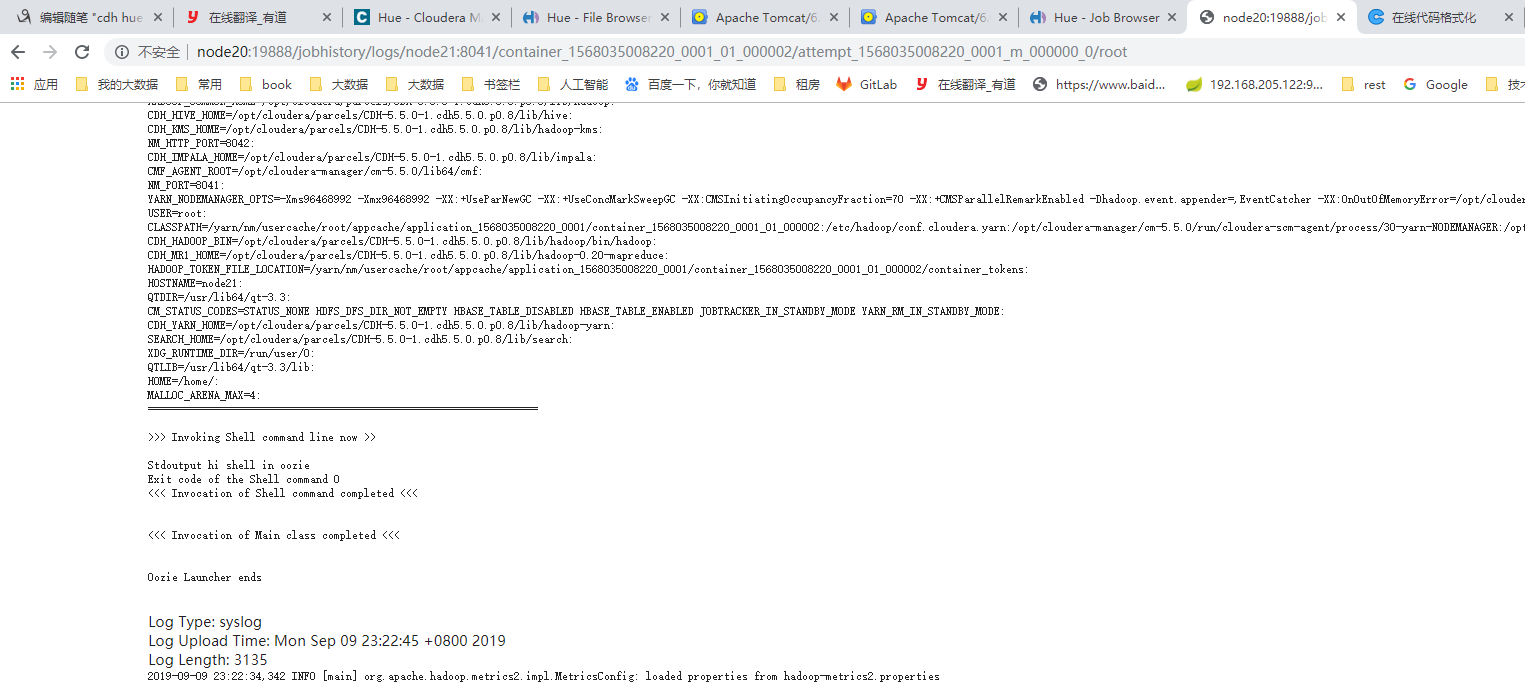
看到上图的输出结果。
如下图,比较oozie workflow.xml 与hue配置workflow图操作的方便性
DAG :有向无环图
