(转)Java并发编程:核心理论
原文链接:https://www.cnblogs.com/paddix/p/5374810.html
Java并发编程系列:
并发编程时Java程序员最重要的技能之一,也是最难掌握的一种技能。他要求编程者对计算机最底层的运作原理有深刻的理解,同时要求编程者逻辑清晰、思维缜密,这样才能写出高效、安全、可靠的多线程并发程序。本系列会从线程间协调的方式(wait、notify、notifyAll)、Synchronized及volatile的本质入手,详细解释JDK为我们提供的每种并发工具和底层实现机制。在此基础上,我们会进一步分析java.util.concurrent包的工具类,包括其使用方式、实现源码及其背后的原理。本文是该系列的第一遍文章,是这系列中最核心的理论部分,之后的文档都会以此为基础来分析和解释
一、共享性
数据共享性是线程安全的主要原因之一。如果所有的数据只是在线程内有效,那就不存在线程安全问题,这也是我们在编程的时候经常不需要考虑线程安全的主要原因之一。但是,在多线程编程中,数据共享是不可避免的。最典型的场景是数据库中的数据,为了保证数据的一致性,我们通常需要共享同一个数据库中的数据,即使是在主从的情况下,访问的也是同一份数据,主从只是为了访问的效率和数据安全,而对同一份数据做的副本。我们现在,通过一个简单的示例来演示多线程下共享数据导致的问题:
代码段一:
package com.paddx.test.concurrent;
public class ShareData {
public static int count = 0;
public static void main(String[] args) {
final ShareData data = new ShareData();
for (int i = 0; i < 10; i++) {
new Thread(new Runnable() {
@Override
public void run() {
try {
//进入的时候暂停1毫秒,增加并发问题出现的几率
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int j = 0; j < 100; j++) {
data.addCount();
}
System.out.print(count + " ");
}
}).start();
}
try {
//主程序暂停3秒,以保证上面的程序执行完成
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("count=" + count);
}
public void addCount() {
count++;
}
}
上述代码的目的是对count进行加一的操作,执行1000次,由10个线程来实现,每个线程执行100次,我们想要的应该输出1000。但是,上面程序的结果不是这样的。下面是某次的执行结果(每次运行的结果不一定相同,有时候也可能获取到正确的结果):

可以看出,对共享变量的操作,在多线程环境下很容易出现各种意想不到的结果。
二、互斥性
资源互斥是只同时只允许一个访问者对其访问,具有唯一性和排他性。我们通常允许多个线程对数据进行读操作,但同时只允许一个线程对数据进行写操作。所以我们通常将锁分为共享锁和排它锁,也叫做读锁和写锁。如果资源不具有互斥性,即使是共享资源,我们也不需要担心线程安全。例如,对于不可变的数据共享,所有线程都只能对其进行读操作,所以不用考虑线程安全问题。但是对共享数据的写操作,一般就需要保证互斥性,上述例子中就是因为没有保证互斥性才导致数据的修改产生问题。Java中提供多种机制来保证互斥性,最简单的方式是使用synchronized,现在我们在上面程序中加上synchronized再执行:
代码段二:
package com.paddx.test.concurrent;
public class ShareData {
public static int count = 0;
public static void main(String[] args) {
final ShareData data = new ShareData();
for (int i = 0; i < 10; i++) {
new Thread(new Runnable() {
@Override
public void run() {
try {
//进入的时候暂停1毫秒,增加并发问题出现的几率
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int j = 0; j < 100; j++) {
data.addCount();
}
System.out.print(count + " ");
}
}).start();
}
try {
//主程序暂停3秒,以保证上面的程序执行完成
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("count=" + count);
}
/**
* 增加 synchronized 关键字
*/
public synchronized void addCount() {
count++;
}
}
现在再执行上述代码,会发现无论执行多少次,返回的最终结果都是1000.
三、原子性
原子性就是指对数据的操作是一个独立的,不可分割的整体。换句话说,就是一次操作,是一个连续不可中断的过程,数据不会执行到一半的时候被其他线程所修改。保证原子性的最简单方式就是操作系统指令,就是说如果一次操作对应一条操作系统指令,这样肯定可以保证原子性。但是很多操作不能通过一条指令就完成。例如:对long类型的运算,很多系统就需要分成多条指令分别对高位和地位进行操作才能完成。还比如,我们经常使用的整数i++的操作,其实需要分成三个步骤:(1)读取整数i的值;(2)对i进行加1的操作;(3)将结果写回内存。这个过程在多线程下就可能出现如下现象:
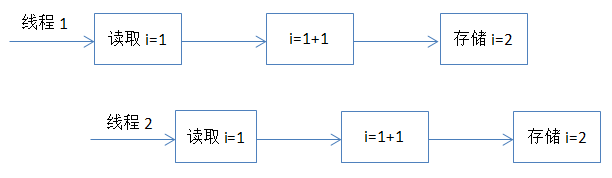
这也是代码段一执行的结果为什么不正确的原因。对于这种组合操作,要保证原子性,最常见的方式是加锁,如Java中的Synchronized或Lock都可以实现,代码段二就是通过synchronized实现的。除了锁以外,还有一种方式就是CAS(Compare And Swap),即修改数据之前先比较与之前读取到的值是否一致,如果一致,则进行修改,如果不一致则重新执行,这也是乐观锁的实现原理。不过CAS在某些场景下不一定有效,比如另一线程先修改了某个值,然后再改回原来的值,这种情况下,CAS是无法判断的
四、可见性
要理解可见性,需要先对JVM的内存模型有一定的了解,JVM的内存模型与操作系统类似,如图所示:
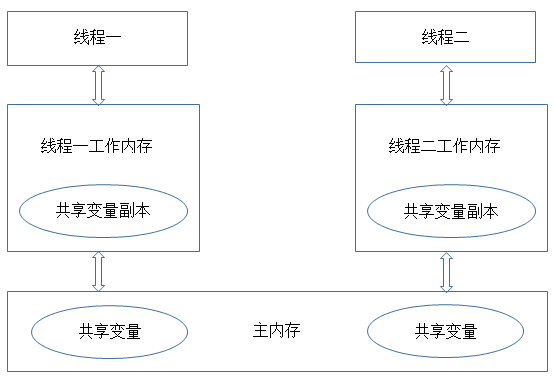
从这个图中我们可以看出,每个线程都有一个自己的工作内存(相当于CPU高级缓冲区,这么做的目的还是在于进一步缩小存储系统与cpu之间速度的差异,提高性能),对于共享变量,线程每次读取到的是工作内存中共享变量的副本,写入的时候也直接修改工作内存中副本的值,然后在某个时间再将工作内存与主内存中的值进行同步。这样导致的问题是,如果线程1对某个变量进行了修改,线程2却有可能看不到线程1对共享变量所做的修改。通过下面这段程序我们可以掩饰一下不可见的问题:
package com.paddx.test.concurrent;
public class VisibilityTest {
private static boolean ready;
private static int number;
private static class ReaderThread extends Thread {
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (!ready) {
System.out.println(ready);
}
System.out.println(number);
}
}
private static class WriterThread extends Thread {
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
number = 100;
ready = true;
}
}
public static void main(String[] args) {
new WriterThread().start();
new ReaderThread().start();
}
}
从直观上理解,这段程序应该只会输出100,ready的值是不会打印出来的。实际上,如果多次执行上面代码的话,可能会出现多种不同的结果,下面是运行出来的某两次的结果:


当然,这个结果也只能说是有可能是可见性造成的,当写线程(WriterThread)设置ready=true后,读线程(ReaderThread)看不到修改后的结果,所以会打印false,对于第二个结果,也就是执行if(!ready)时还没有读取到写线程的结果,但执行System.out.println(ready)时读取到了写线程执行的结果。不过,这个结果也有可能是线程的交替执行所造成的。Java中可通过Synchronized或Volatile来保证可见性,具体细节会在后续文章中分析。
五、有序性
为了提高性能,编译器和处理器可能会对指令进行重排序。重排序可以分为三种:
(1)编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
(2)指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
(3)内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
我们可以直接参考一下JSR 133中对重排序问题的描述:

(1) (2)
先看上图中的(1)源码部分,从源码来看,要么指令1先执行要么指令3先执行。如果指令1先执行,r2不应该能看到指令4中写入的值。如果指令3先执行,r1不应该能看到指令2的值。但是运行结果却可能出现r2==2,r1==1的情况,这就是“重排序”导致的结果。上图(2)即是一种可能出现的合法的编译结果,编译后,指令1和指令2的顺序可能就互换了。因此,才会出现r2==2,r1==1的结果。Java中也可通过Synchronized或volatile来保证顺序性。
六、总结
本文对Java并发编程中的理论基础进行了讲解,有些东西在后续的分析汇总还会做更详细的讨论,如可见性、顺序性等。后续的文章都会以本章内容作为理论基础来讨论。

