

shell脚本三剑客:grep、sed、awk
shell脚本三剑客:grep sed awk
grep语法:
grep [OPTIONS] PATTERN [FILE]
常用选项
-c 统计匹配到的行数
-i 匹配时不区分大小写
-n 显示匹配行所在行号
-o 只显示匹配到的字符串
-v 取反,反方向匹配,不匹配关键字的行
-E 开启扩展的正则表达式
-A n 显示匹配的所在的行及其后n行
-B n 显示匹配的所在的行及其前n行
-C n 显示匹配的所在的行及其前后各n行
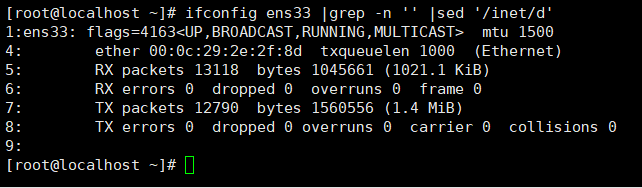
例:查看ifconfig ens33,并选择关键字进行匹配,然后显示匹配到多少行,如果显示2行,说明有2行的内容包括这个关键字。

显示关键字所在的行号:-n

取反,反方向匹配,不匹配关键字的行:-v

显示匹配的所在的行及其后n行:-An
显示ifconfig ens33的结果并以192.168.100.30作为检索关键字提取所在行及后5行,后6行。
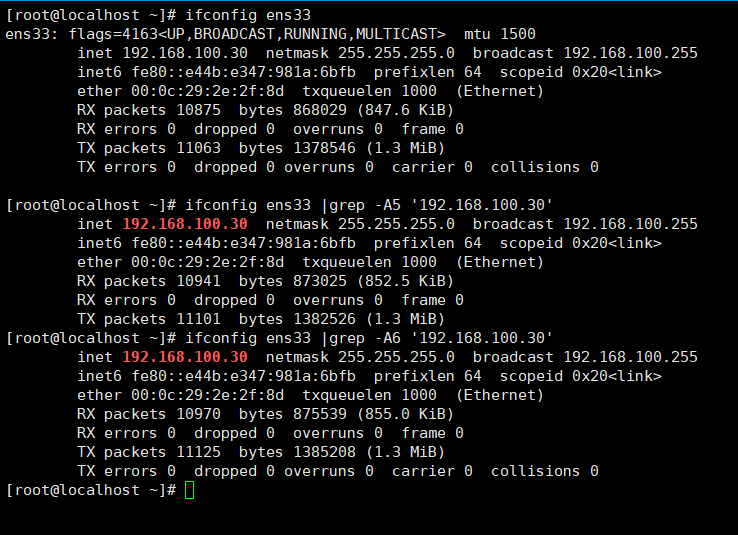
显示匹配的所在的行及其前n行:-Bn
显示ifconfig ens33的结果并以TX errors作为检索关键字提取所在行及前5行,以RX errors作为检索关键字提取所在行及前5行,若匹配行数多于实际行数则显示匹配行及前面所有行。

显示匹配的所在的行及其前后n行:-Cn
以RX packets为关键字,匹配关键字所在行及上下三行。

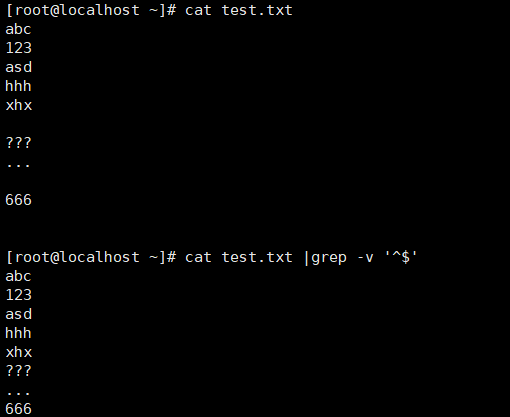
过滤空行:grep -v '^$'
正则表达式:
常用选项
. : 匹配任何单个字符(除NUL)
* : 匹配其前的任何数目或没有的单个字符,例: . 表示任一字符, 则 .* 匹配任一字符的任意长度
^ : 匹配紧接着的正则表达式,BRE中仅在正则表达式的开头有特殊的含义,ERE中在任何位置都有特殊含义
$ : 匹配前面的正则表达式,在字符串或者行结尾处。BRE中仅在正则表达式的结尾处有特殊的含义,ERE中在任何位置都有特殊含义
[] : 匹配方括号内的任一字符,其中可用连字符(-)指的连续字符的范围;^符号苦出现在方括号的第一个位置,则表示匹配不在列表中的任一字符,
字符出现次数:
* 前面的字符出现任意次,包括0次
\? 前面的字符出现0次或1次,\为转义符
\+ 前面的字符至少出现一次
\{m\} 前面的字符出现m次,\为转义符
\{m,\} 前面的字符至少出现m次,\为转义符
\{m,n\} 前面的字符至少出现m次,至多n次,\为转义符
sed语法:
sed [OPTIONS] PATTERN [FILE]
常用选项
-e 允许多项编辑
-i 直接修改
-f 指定sed脚本文件
-n 取消默认的输出
常见命令
p 打印(默认在屏幕上显示出来)建议和 -n 一起使用
c 替换行
i 添加 在指定行的上一行添加内容
a 添加 在指定行的下一行添加内容
d 删除
n N 读取/添加 模式匹配到的行的下一行内容,在对其进行操作
w 保存
s 文本内容替换
g 全部匹配
& 调用前面匹配的内容
例子:打印内容
1.打印指定行内容
打印某一行内容:sed -n 'np'
打印指定的多行内容,第x行到第y行:sed -n 'x,yp'
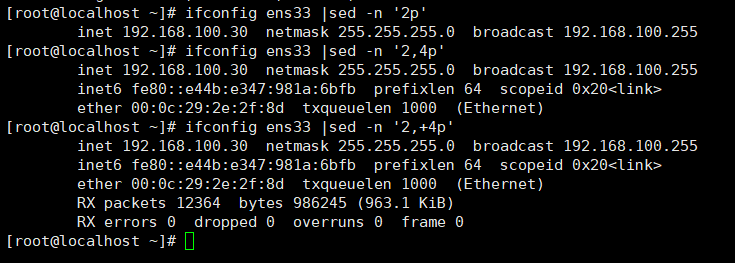
2.打印关键字所在行内容:sed -n '/关键字/ p' 文件

打印以root开头的行

3.打印奇数行及偶数行
1~2p:以第一行为开始行,步数为2进行打印。
2~2p:以第二行为开始行,步数为2进行打印。
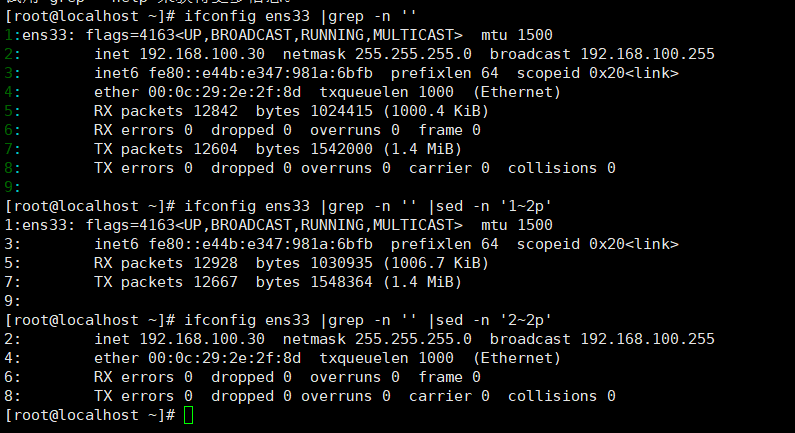
例子:删除内容
1.删除指定行:sed -n 'nd' 文件

2.通过关键字删除所在行
删除包含inet的所在行
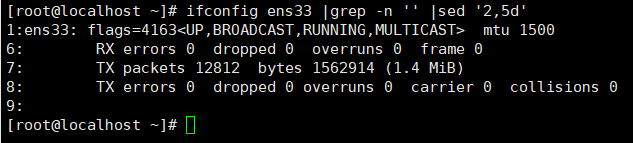
3.删除第几行到第几行
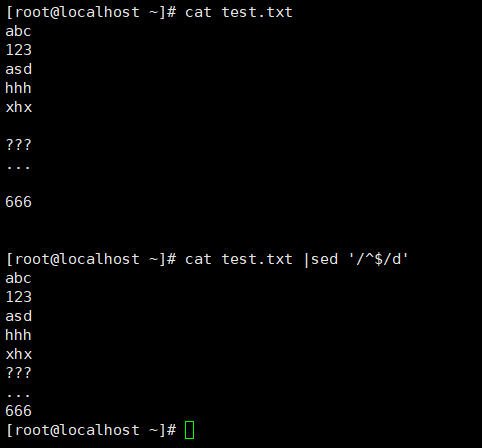
4.删除空行
sed '/^$/d' 文件
5.取反删除
sed '/^$/ !d' 文件

例子:修改内容
sed -i '命令 ' 文件
1.插入内容
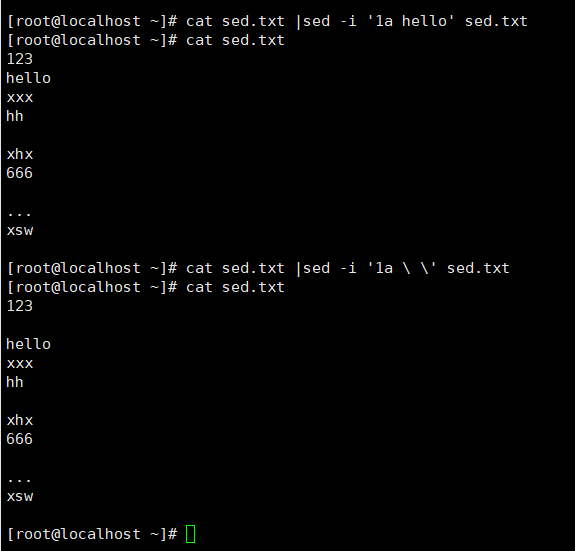
在文本第二行后插入hello
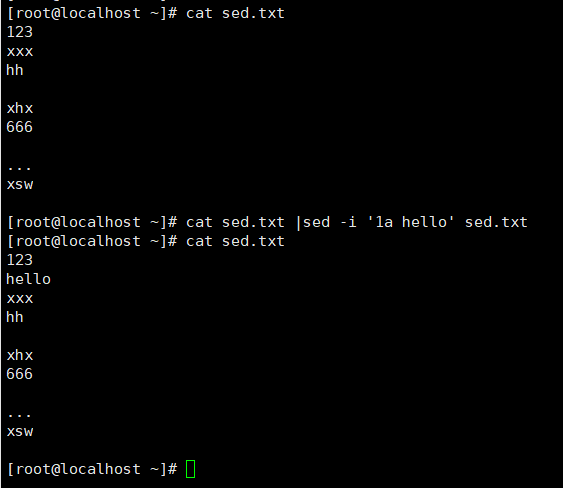
插入空行
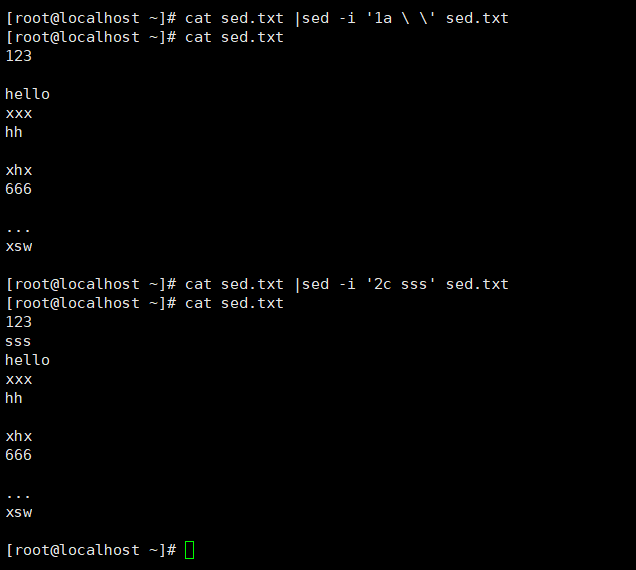
sed -i '1a \ \' 文件
2替换内容
sed -i '原内容所在行c 新内容' 文件
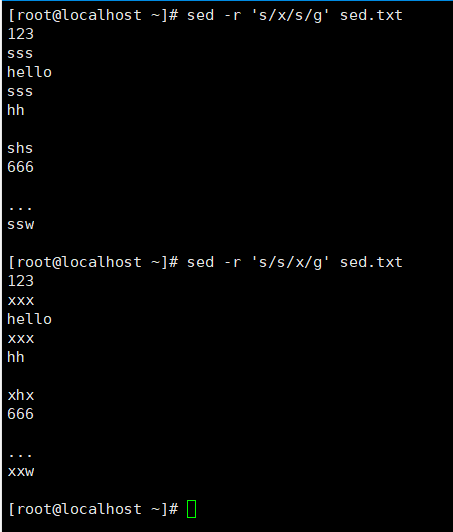
指定字符进行替换
将文本中的s替换成x
awk语法
sed [OPTIONS] ‘模式{操作}’ 文件
内置变量
FS :输入字段分隔符,默认为空白字符
OFS:输出字段分隔符,默认为空白字符
RS :输入记录分隔符,指定输入时的换行符,原换行符仍有效
ORS :输出记录分隔符,输出时用指定符号代替换行符
NF :字段数量,共有多少字段, $NF引用最后一列,$(NF-1)引用倒数第2列
NR :行号,后可跟多个文件,第二个文件行号继续从第一个文件最后行号开始
FNR :各文件分别计数, 行号,后跟一个文件和NR一样,跟多个文件,第二个文件行号从1开始
FILENAME :当前文件名
ARGC :命令行参数的个数
ARGV :数组,保存的是命令行所给定的各参数,查看参数
例子:打印内容
awk '{print $n}'
默认以空格为分隔符,打印第n个字段,效果与awk -F" " '{print $n}'相似。
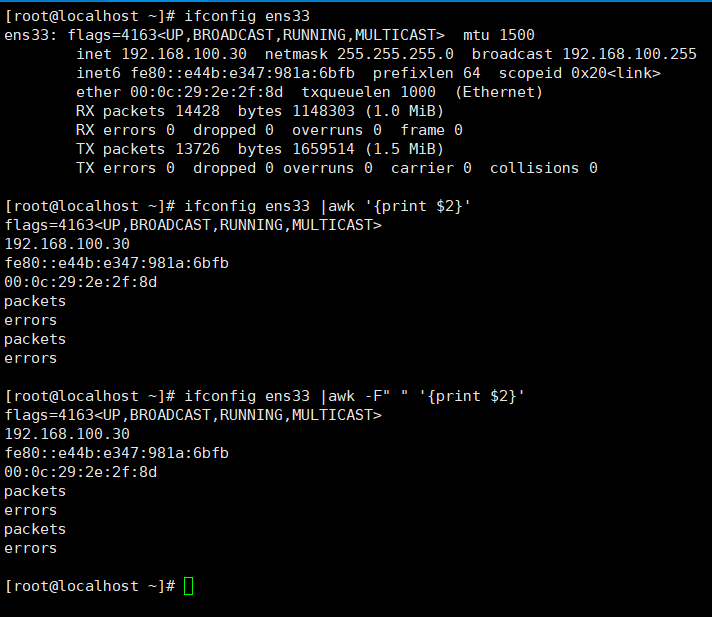
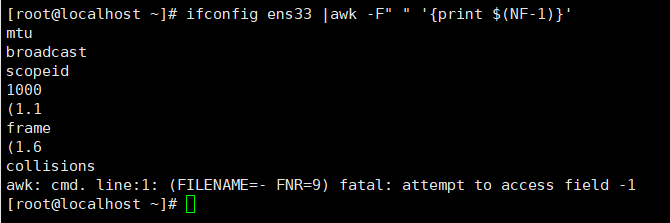
打印倒数第二个字段
awk '{print $(NF-1)}'
打印多列内容
awk -F '{print $n,$m}'

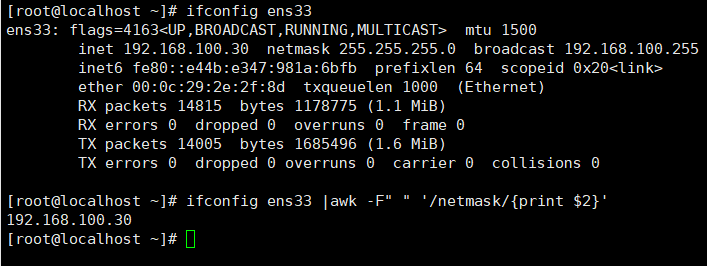
打印多列内容并指定分隔符
awk -F '{print $n “?” $m}'(以?为分隔符)

打印关键字所在行
awk '/关键字/ {print}'

利用关键字提取IP
打印行号
awk '{print $n,NR}'
\t为制表符

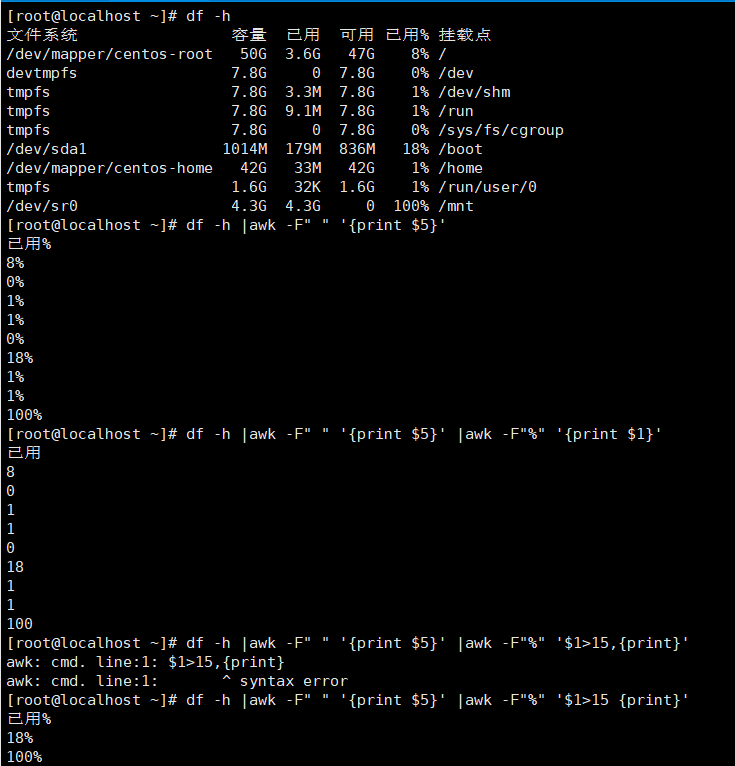
提取符合条件的字段
取已用字段中占用比大于15%的字段
df -h |awk -F" " '{print $5}' |awk -F"%" '$1>15 {print}'
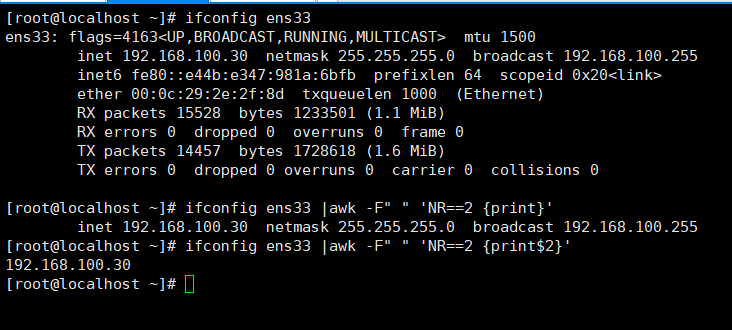
打印某行
awk 'NR==n {print}'

提取IP
以某行某列确定IP的位置
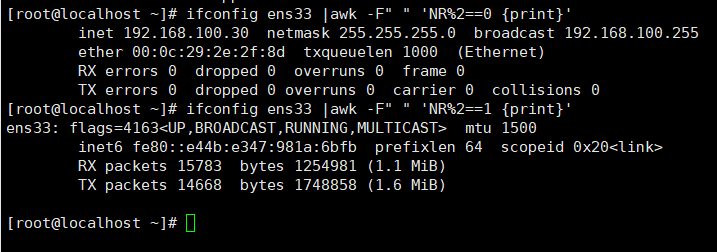
取偶数行
awk -F 'NR%2==0 {print}'
取奇数行
awk -F 'NR%2==1 {print}'


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏