行转列:总结
行转列之一 太简单不说了
例1:
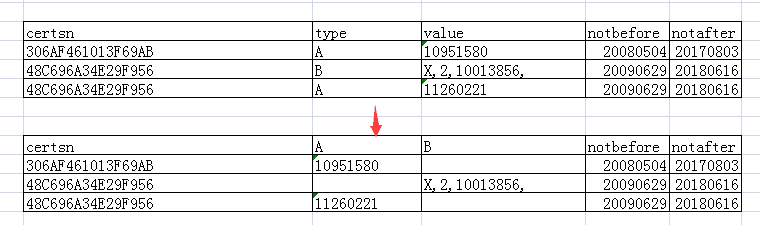
1 with v_data as 2 (select '306A' certsn, 'A' type, '10951580' value, 20080504 notbefore, 20170803 notafter from dual union 3 select '48C6' certsn, 'B' type, 'X,2,10013856' value, 20090629 notbefore, 20180616 notafter from dual union 4 select '48C6' certsn, 'A' type, '11260221' value, 20090629 notbefore, 20180616 notafter from dual) 5 select certsn, 6 case when v_data.type = 'A' then max(value) else ' ' end A, 7 case when v_data.type = 'B' then max(value) else ' ' end B, 8 max(notbefore) notbefore, 9 max(notafter) notafter 10 from v_data 11 group by certsn, type;
结果:
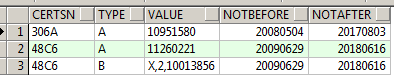
转置成

行转列之二 wm_concat()
例1:
wm_concat()行转列并且用逗号分隔, 需要分组!

1 select wm_concat(ename), --结果为类型clob 2 to_char(wm_concat(ename)), 3 dbms_lob.substr(wm_concat(ename), 4000) 4 from emp 5 where rownum < 5;
例2:
select c, listagg(a,'') within group(order by rownum) from test group by c; with test as ( select 1 c,'西' a from dual union all select 1 c,'安' a from dual union all select 1 c,'的' a from dual union all select 2 c,'天' a from dual union all select 2 c,'气' a from dual union all select 3 c,'好' a from dual ) select c, replace(to_char(wm_concat(a)),',','') FROM test group by c;
结果:
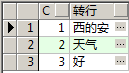
或者
select c, listagg(a,'') within group(order by rownum) from test group by c;
行转列之三 listtagg()
Oracle 转门的行转置函数 listagg()
用法就像聚合函数一样,通过Group by语句,把每个Group的一个字段,拼接起来。非常方便。
语法:
LISTAGG(<转置列列表>, '分隔符' ) WITHIN GROUP( ORDER BY <排序列列表>)
GROUP BY ...
例子:
源数据为
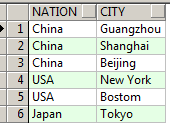
行转列:
方法1)使用group by分组
1 with temp as ( 2 select 'China' nation ,'Guangzhou' city from dual union all 3 select 'China' nation ,'Shanghai' city from dual union all 4 select 'China' nation ,'Beijing' city from dual union all 5 select 'USA' nation ,'New York' city from dual union all 6 select 'USA' nation ,'Bostom' city from dual union all 7 select 'Japan' nation ,'Tokyo' city from dual 8 ) 9 select nation,listagg(city,',') within GROUP (order by city) 10 from temp 11 group by nation;
结果:

方法2)不使用分组, 使用listagg + over ( partition by 分组列)
with temp as( select 'China' nation ,'Guangzhou' city from dual union all ... ) select --nation, listagg(city,',') within GROUP (order by city) over (partition by nation) rank --使用分析函数代替分组 distinct nation, listagg(city,',') within GROUP (order by city) over (partition by nation) rank --去重! from temp order by nation;
结果和上面SQL一致!
(转发)行转列之四 xmlagg() + xmlparse() + group by
为解决 listagg() 字符串连接的结果过长问题
语法:
listagg(<转置列>, '<连接符>') within GROUP (order by <排序列>)
等价于
xmlagg(xmlparse(content <转置列> || '<连接符>' wellformed) order by <排序列>).getstringval()
拍序列随意
例3.1:
1 with temp as( 2 select 'China' nation ,'Guangzhou' city from dual union all 3 select 'China' nation ,'Shanghai' city from dual union all 4 select 'China' nation ,'Beijing' city from dual union all 5 select 'USA' nation ,'New York' city from dual union all 6 select 'USA' nation ,'Bostom' city from dual union all 7 select 'Japan' nation ,'Tokyo' city from dual 8 ) 9 select nation, --转置列 10 listagg(city,',') within GROUP (order by city) as listagg, 11 xmlagg(xmlparse(content city || ',' wellformed) order by city).getstringval(), 12 to_char(substr(xmlagg(xmlparse(content city || ',' wellformed) order by city).getclobval(),1,4000)) --!!! 13 -- .getclobval() 结果集类型为clob 用 to_char()转置 14 from temp 15 group by nation;
结果和上面一致

例3.2:
select xmlagg(xmlparse(content wm_concat(ename) || ', ' wellformed) order by 1) .getstringval() from emp where rownum < 5 group by '必须有';
结果:

行转列之五 SYS_CONNECT_BY_PATH()
层次查询中 函数 SYS_CONNECT_BY_PATH(列名,'连接符') 能取回叶子节点到根节点的全路径
例子3.1:取一张表的所有字段
1 select max(substr(SYS_CONNECT_BY_PATH(COLUMN_NAME, ','), 2)) col 2 from (select COLUMN_NAME, column_id 3 from user_tab_columns 4 where table_name = upper('&表名')) 5 start with column_id = 1 6 connect by column_id = rownum;
其中:
- SYS_CONNECT_BY_PATH(COLUMN_NAME, ',') --取表的所有列名, ','逗号分隔
- substr(SYS_CONNECT_BY_PATH(COLUMN_NAME, ','), 2) --去除第一个多余的','
- max(substr(SYS_CONNECT_BY_PATH(COLUMN_NAME, ','), 2)) --全表分区取max,即取最长的一条,即取出表的所有列名 , 且返回的是串类型的 不是clob类型的
例3.2:源数据为
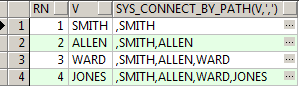
使用sys_connect_by_path() 开始"拼接"
1 with v_data as ( 2 select ename v from emp where rownum < 5 3 ) ,v_row_data as ( 4 select rownum rn,t.* FROM v_data t 5 ) select rn,v,sys_connect_by_path(v,',') FROM v_row_data r 6 start with rn = 1 7 connect by level = rn ;
start with 子句是必须的
上面结果:
随后取"转置"的行(最长的一行),start with 使用了子查询
1 with v_data as ( 2 select ename v from emp where rownum < 5 3 ) ,v_row_data as ( 4 select rownum rn,t.* FROM v_data t 5 ) select max(trim(leading ',' from sys_connect_by_path(v,','))) FROM v_row_data r 6 start with rn = (select min(rn) from v_row_data) --start with 使用了子查询 7 connect by level = rn ;
结果:

