消息队列之如何保证消息的幂等性
1.1 前言
不管是RQ还是Kafka等消息队列,在被消费者消费的时候需要防止的一个问题就是:如何防止消息被重复消费,也是就消息的幂等性。这问题通常不是 MQ 自己保证的,是由我们开发来保证的。挑一个 Kafka 来举个例子,说说怎么重复消费吧。
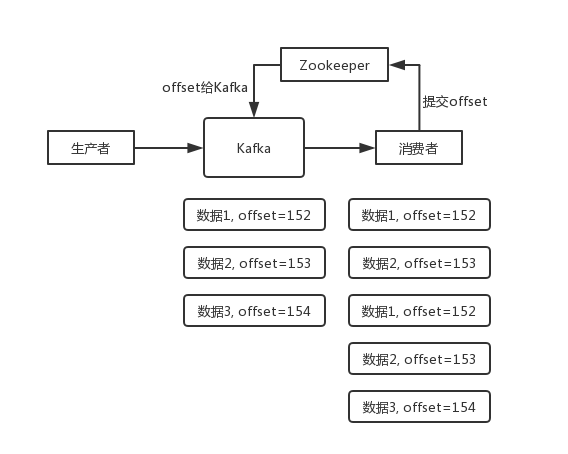
Kafka 实际上有个 offset 的概念,就是每个消息写进去,都有一个 offset,代表消息的序号,然后 consumer 消费了数据之后,每隔一段时间(定时定期),会把自己消费过的消息的 offset 提交一下,表示“我已经消费过了,下次我要是重启啥的,你就让我继续从上次消费到的 offset 来继续消费吧”。
但是凡事总有意外,比如我们之前生产经常遇到的,就是你有时候重启系统,看你怎么重启了,如果碰到点着急的,直接 kill 进程了,再重启。这会导致 consumer 有些消息处理了,但是没来得及提交 offset,尴尬了。重启之后,少数消息会再次消费一次。
注意:新版的 Kafka 已经将 offset 的存储从 Zookeeper 转移至 Kafka brokers,并使用内部位移主题 __consumer_offsets 进行存储。
2.1 解决方案
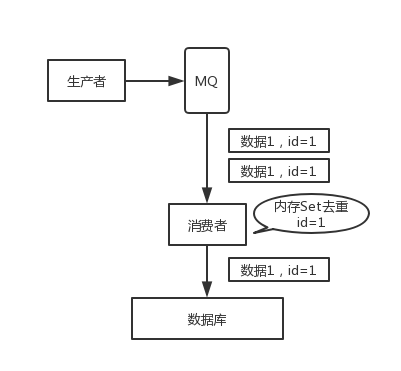
如果消费者干的事儿是拿一条数据就往数据库里写一条,会导致说,你可能就把数据 1/2 在数据库里插入了 2 次,那么数据就错啦。
其实重复消费不可怕,可怕的是你没考虑到重复消费之后,怎么保证幂等性。
举个例子吧。假设你有个系统,消费一条消息就往数据库里插入一条数据,要是你一个消息重复两次,你不就插入了两条,这数据不就错了?但是你要是消费到第二次的时候,自己判断一下是否已经消费过了,若是就直接扔了,这样不就保留了一条数据,从而保证了数据的正确性。
一条数据重复出现两次,数据库里就只有一条数据,这就保证了系统的幂等性。
幂等性,通俗点说,就一个数据,或者一个请求,给你重复来多次,你得确保对应的数据是不会改变的,不能出错。
所以第二个问题来了,怎么保证消息队列消费的幂等性?
其实还是得结合业务来思考,我这里给几个思路:
- 比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update 一下好吧。
- 比如你是写 Redis,那没问题了,反正每次都是 set,天然幂等性。
- 比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个全局唯一的 id,类似订单 id 之类的东西,然后你这里消费到了之后,先根据这个 id 去比如 Redis 里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个 id 写 Redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
- 比如基于数据库的唯一键来保证重复数据不会重复插入多条。因为有唯一键约束了,重复数据插入只会报错,不会导致数据库中出现脏数据。