
Explainability for Large Language Models: A Survey
一、引言
- 可解释性代表的是一种以人类能够理解的方式解释模型行为的能力。
- 拥有可解释性有两个好处:①可解释性可以以人类能够理解的方式来很好的解释模型预测背后的原理,使普通人可以理解LLM的能力、缺陷。②对于研究者来说,可解释性可以帮助识别出偏见、风险和一些性能改进的领域。
二、LLM的训练
- 下游微调范式:在大量的未标注文本上进行预训练,接着在一些特定领域的有标注的文本上进行微调,在微调期间,最后一层编码器层上通常都会添加一个全连接层来适应下游任务。
- 提示工程范式:1有两个不足:1)不能理解用户给出的指令;2)倾向于生成有偏见和恶意的内容(训练文本的影响)。在这个范式下根据阶段的不同模型可以有两种类型:base model和assistant model

三、针对微调范式的解释方法
局部解释:解释模型生成输出的过程,对单个样本分析如何得到预测结果的。
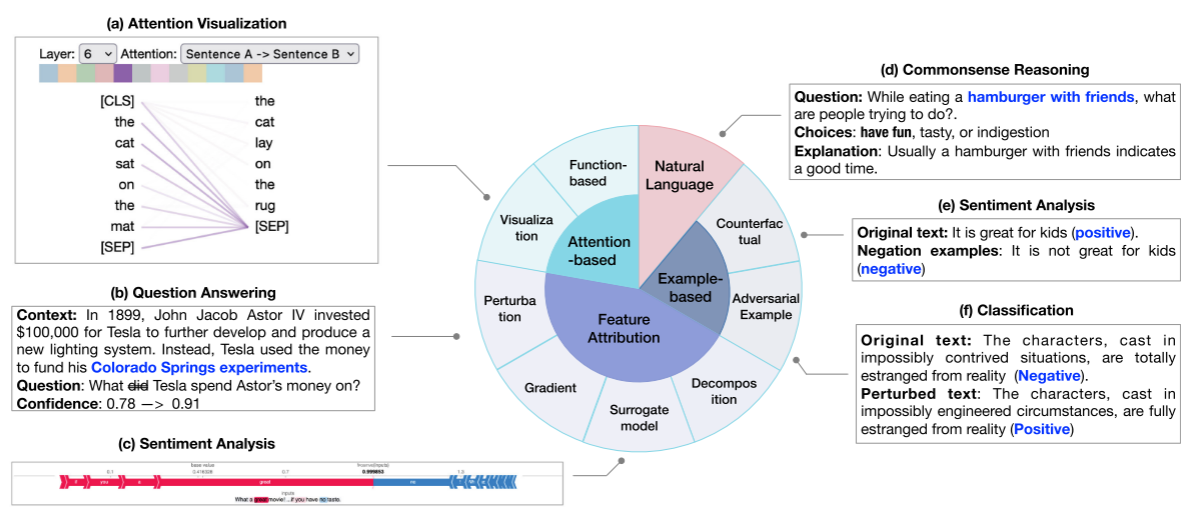
- feature attribution-based explanation:attribution方法会为每个特征计算一个相关度分数以评估该特征对最终模型输出结果的影响
- attention-based explanation:通过分析注意力权重或分析编码在注意力中的知识(有争议,有人认为注意力不可以准确地反应最重要的信息)
- example-based explanation:从实例的角度来解释模型,阐述模型的输出是如何随着输入的变化而进行变化的。(如adversarial examples通过替换输入数据中不重要的部分,旨在揭示模型的弱点;counterfactual explanations通过替换输入数据中重要的部分,可以为理想的结果提供解决方案;data influence测试训练数据是如何在测试数据上影响模型的预测)
- natural language explanation:用生成的文本来解释模型对输入数据的决策过程
全局解释:解释模型内部的细节运作,探究不同网络模块学习到的语义知识,旨在提供更高级别的语义解释。
- probing-based explanation:理解大模型捕捉到的语言知识
- neuron activation explanation:不是分析整个向量空间,而是从单个维度来进行分析
- concept-based explanation:将输入映射到一组内容,然后评估每个预定义的内容的重要性得分来建模预测。
- mechanistic interpretability:通过解释单个神经元尤其是它们之间的连接来理解大模型
可解释性方法的应用:
- 调试模型,例如,如果模型始终关注输入数据的某个特定的token而不是整个内容,那么模型可能以来于偏见而不是真正地了解了文本的含义
- 改进模型,如,explanation regularization通过将模型的machine retionale(模型关注的token)和人类的rationale进行对齐来提高模型的能力
四、提示工程
传统的微调方法模型的解释方法不适用于复杂的提示工程训练出来的模型。
- base model的解释主要有三个方面:解释in-context learning,思维链提示、表示学习都是如何影响LLM的行为
- assistant model的解释方法:1)解释微调对齐步骤的做用;2)分析产生幻觉的原因;3)不确定性量化
- 应用:
改进模型:分析LLM是否在有限的例子中学习新任务时可以从explanations中获益
下游应用:如教育、金融。
五、评估
- 评估传统微调范式下的局部解释
- 评估提示范式下的思维链解释
六、挑战和展望

 浙公网安备 33010602011771号
浙公网安备 33010602011771号