
ECPE:emotion-cause pair extraction,情感因果对抽取。
该任务来源于ECE(emotion cause extraction),情感原因抽取,顾名思义,就是给定已经注释好的情感,将引起该情感的原因从文档中抽取出来。
因为现实生活中,大多情况我们是不会特地将情感注释好放在那里的,而且先注释情感再抽取原因忽视了情感和原因的交互性。于是ECPE任务就被提出来了,ECPE的目的就是在没有事先给定已经注释好情感的情况下,我们将文档中的情感和原因,以及两者之间的关系都抽取出来成为一个因果对。具体形式是这样:(e,c),e表示的是情感emotion,c表示的是原因cause。
目前一共提出了三种类型的模型:
- two-step pipeline method
- one-step end to end model
- method based on unified sequence labeling
今天看了第一种类型的一篇论文,也就是用的是two-step pipeline method
文中提出的方法一共分为两步:
- 分别单独将情感和原因抽取出来
- 对情感和原因进行配对,然后过滤掉不存在因果关系的组队
第一步将情感和原因分别抽取出来,采用的是multi-task learning(多任务学习)(多任务学习:把多个相关任务放在一起学习,也就是同时学习多个任务)
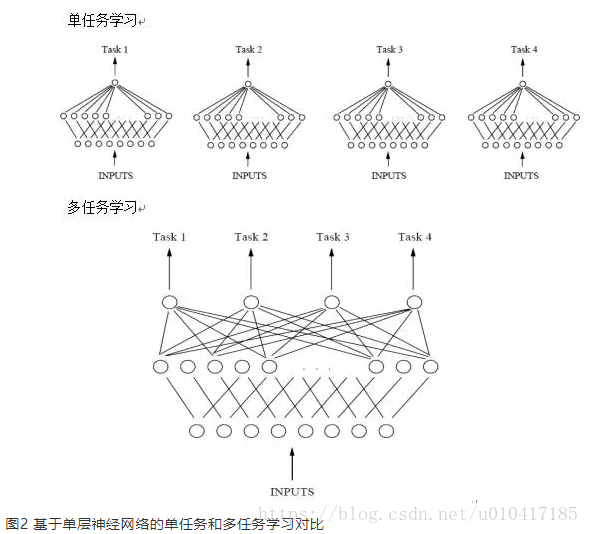
这里单任务学习中,任务彼此之间是独立的没有交互的,而多任务学习中多个任务的学习空间是共享的,这就考虑到了现实中有一些任务彼此之间是有关联的。
在本论文中为何要用到多任务学习,我的理解是抽取原因和抽取情感这两个任务不是独立的,原因和情感彼此应该共同影响,所以我们使用multi-task learing、
作者这里提出了两种多任务学习模型:
- independent multi-task learning
- interactive multi-task learning
1.independent multi-task learning
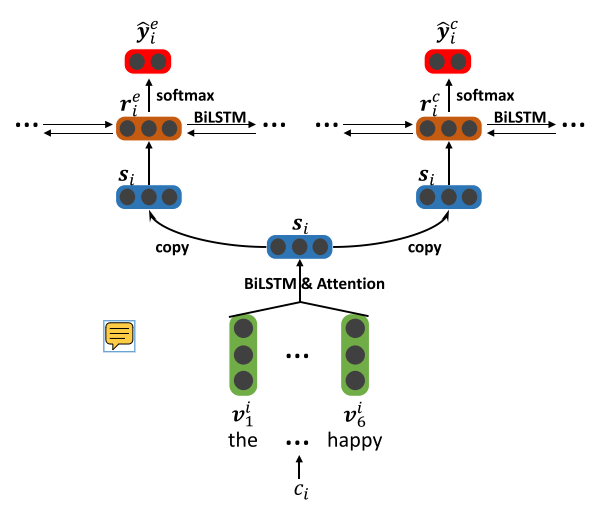
最底层由单词级别的Bi-LSTM模块组成(每一个模块对应一个子句),首先输入子句Ci,将每一个单词w映射为词向量v,接着输入Bi-LSTM层,第i个子句的第j个单词的隐藏层状态hi,j由此得到,接着使用attention来得到子句表示S。
上面的层由两部分组成:分别是情感抽取和原因抽取。每一个部分都是一个子句级别的Bi-LSTM,它接收的是子句表示[s1,s2...sn]
输入子句ci的子句表示Si,分别得到情感隐藏层状态ri,e和原因隐藏层状态ri,c(这里可以理解成是子句ci的上下文感知表示)、
最终送入softmax层分别进行情感预测和原因预测,
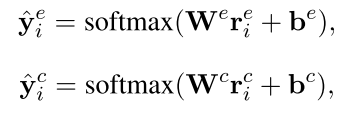
损失函数:
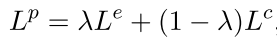
2.interactive multi-task learning
interactive交互的,它就是在多任务学习的基础上进一步的捕捉情感和原因的关系(因为在independent multi-task learning任务中,我们可以看见上面的层,也就是分别抽取情感和原因的两个子任务是互相独立的),考虑到在事先已经抽取出情感的情况下抽取出来原因的效果可能更好,反之亦然。
因此设计出了这个模型
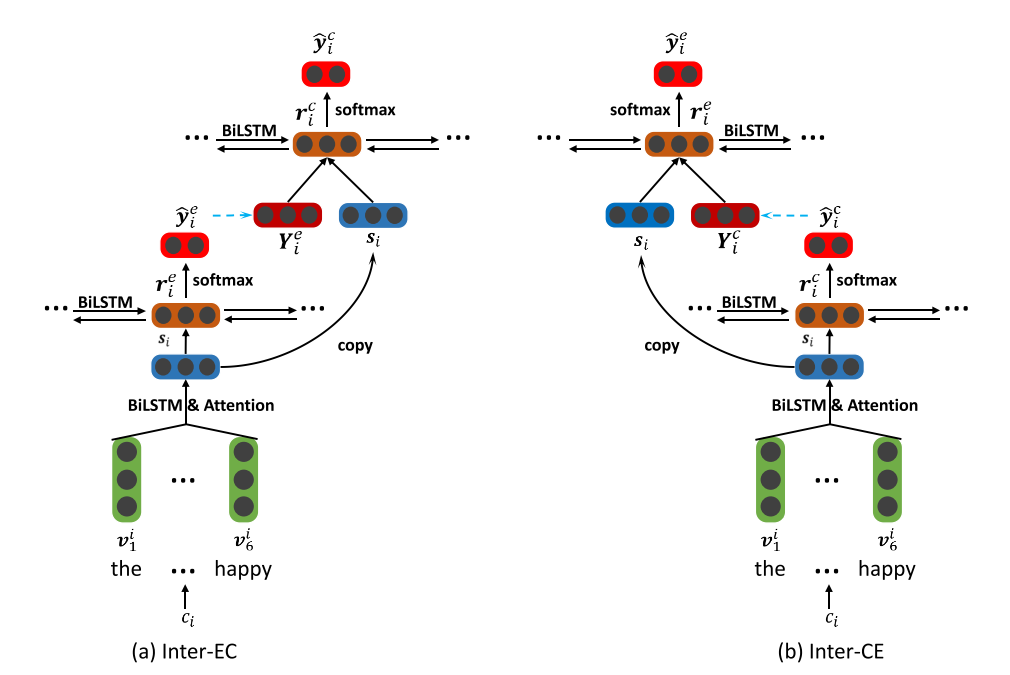
inter-EC表示的是在抽取出情感的情况下抽取原因,inter-CE同理。
与independent multi-task learning相比,底层模型并没有改变,改变的只是上面的部分。
得到的子句表示S仍然用作两部分,第一部分用于得到情感隐藏层表示用于下一步的softmax,得到最终的y,i,e概率分布,然后将预测的标签映射成向量表示,与每一个S组合(
s2,s3类似
进行重复的动作得到我们最终的目的,原因预测y,i ,c。
第二步将情感和原因进行配对:
对情感集合和原因集合里的元素进行笛卡尔积,就是所有可能的配对方式: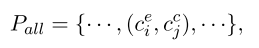
接着我们对集合里的每一对用三种特征来进行表示: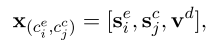
分别是情感表示,原因表示和两个子句之间的距离。
最终用一个logistic regression逻辑回归来训练,
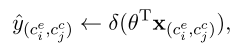
对每一个候选对来检测是否有因果关系,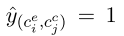
表示有因果关系,为0表示没有,最终我们移除值为0的对,也就是筛选过程。
最终得到因果对集合。
展望:
two-step表示它的目标不是直接抽取因果对的,因此不够直接。因为它第一步先分别抽取出来情感集合和原因集合,第二步进行配对和过滤。
而且会有错误累计的问题。
因此有必要尝试端到端的方式来直接提取因果对。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号