python-网络安全编程第六天(threading多线程模块&Queue模块&subprocess模块)
前言
昨天晚上9点多就睡了 2点起来没睡意。。。 那就学习吧emmmm ,拿起闲置几天的python课程学习。学习到现在5.58了 总结下 继续开始学习新的内容

多多线程?
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。在Unix System V及SunOS中也被称为轻量进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程。
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度
- 程序的运行速度可能加快
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
- 线程可以被抢占(中断)
- 在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) -- 这就是线程的退让。
python多线程-引入threading模块
threading模块用于提供线程相关的操作,线程是应用程序中工作的最小单元。python当前版本的多线程库没有实现优先级、线程组,线程也不能被停止、暂停、恢复、中断。
threading模块提供的类:
Thread, Lock, Rlock, Condition, [Bounded]Semaphore, Event, Timer, local
import threading
线程模块
Python通过两个标准库thread和threading提供对线程的支持。thread提供了低级别的、原始的线程以及一个简单的锁。
threading 模块提供的其他方法:
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
- run(): 用以表示线程活动的方法。
- start():启动线程活动。
- join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
python多线程-通过threading.Thread()创建线程
- 通过threading.Thread()创建线程。其中target接收的是要执行的函数名字,args接收传入函数的参数
- eg:
-
import threading import time def xiaohua(n): print("xiaohua:%s"%(n)) time.sleep(2)#增加延迟可以看到效果 #创建2个线程 t1=threading.Thread(target=xiaohua,args=(2,)) t2=threading.Thread(target=xiaohua,args=(3,)) #启动2个线程 t1.start() t2.start()
-
程序运行后,主线程从上到下依次执行,在t1,t2两个线程启动后,与主线程并行,抢占CPU资源。xiaohua函数内部我们增加了2秒的延迟 正常清空下我们执行依次xiaohua函数第一个print很快第二个print要等上两秒 此时我们用的是多线程 所以这两行结果同时打印。
- eg2:
import threading import time def fun(key): print("Hello %s:%s"%(key,time.ctime())) def main(): threads=[] key=['xiaohua','dawang','666'] threadscount=len(key) for i in range(threadscount): t=threading.Thread(target=fun,args=(key[i],))#创建新线程 threads.append(t)#添加线程到线程列表 for i in range(threadscount): threads[i].start() #启动线程 for i in range(threadscount): threads[i].join()#等待所有线程完成 if __name__=='__main__': main()
python-Queue模块
Python的Queue模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列PriorityQueue。这些队列都实现了锁原语,能够在多线程中直接使用。可以使用队列来实现线程间的同步。
- Queue.qsize() 返回队列的大小
- Queue.empty() 如果队列为空,返回True,反之False
- Queue.full() 如果队列满了,返回True,反之False
- Queue.full 与 maxsize 大小对应
- Queue.get([block[, timeout]])获取队列,timeout等待时间
- Queue.get_nowait() 相当Queue.get(False)
- Queue.put(item) 写入队列,timeout等待时间
- Queue.put_nowait(item) 相当Queue.put(item, False)
- Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
- Queue.join() 实际上意味着等到队列为空,再执行别的操作
Queue模块-FIFO队列
class Queue.Queue(maxsize=0)
FIFO即First in First Out,先进先出。Queue提供了一个基本的FIFO容器,使用方法很简单,maxsize是个整数,指明了队列中能存放的数据个数的上限。一旦达到上限,插入会导致阻塞,直到队列中的数据被消费掉。如果maxsize小于或者等于0,队列大小没有限制。
import queue Queue=queue.Queue() for i in range(6): Queue.put(i) while not Queue.empty(): print(Queue.get())
执行结果
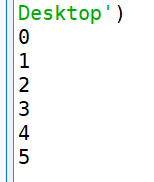
Queue模块-LIFO队列
class Queue.LifoQueue(maxsize=0)
LIFO即Last in First Out,后进先出。与栈的类似,使用也很简单,maxsize用法同上
import queue Queue=queue.LifoQueue() for i in range(6): Queue.put(i) while not Queue.empty(): print(Queue.get())
执行结果:
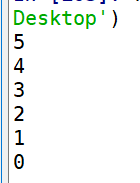
python-subprocess模块
创建Popen类的实例对象
res = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
cmd:标准像子进程传入需要执行的shell命令,如:ls -al
shell:如果这个参数被设置为True,程序将通过shell来执行。
subprocess.PIPE:在创建Popen对象时,subprocess.PIPE可以初始化为stdin, stdout或stderr的参数,表示与子进程通信的标准输入流,标准输出流以及标准错误。
subprocess.STDOUT:作为Popen对象的stderr的参数,表示将标准错误通过标准输出流输出。
import subprocess obj = subprocess.Popen(r'dir D:\flin',shell=True, # 可以执行系统命令,这里会创建独立的管道,返回其结果 stdout=subprocess.PIPE, # 输出结果 stderr=subprocess.PIPE, # 错误信息 stdin=subprocess.PIPE) # 标准输入 print(obj.stdout.read().decode('gbk')) # 打印执行结果
python综合运用
多线程C段扫描py
import threading import queue from subprocess import Popen,PIPE queue=queue.Queue() print(queue) class DoRun(threading.Thread): def __init__(self,queue): threading.Thread.__init__(self) self._queue=queue def run(self): while not self._queue.empty(): ip=self._queue.get() #print(ip) check_ping=Popen("ping "+ip,stdin=PIPE,stdout=PIPE) data=check_ping.stdout.read() if 'TTL' in str(data): print(ip+"is UP") def main(): threads=[] threads_count=10 for i in range(1,255): queue.put('101.201.65.'+str(i)) for i in range(threads_count): threads.append(DoRun(queue)) for i in threads: i.start() for i in threads: i.join() if __name__=='__main__': main()
# coding=utf-8 import threading, queue, time, urllib from urllib import request baseUrl = 'http://www.pythontab.com/html/pythonjichu/' urlQueue = queue.Queue() for i in range(2,10): url=baseUrl+str(i)+'.html' urlQueue.put(url) print(url) def fetchUrl(urlQueue): while True: try: url=urlQueue.get_nowait()#相当queue.get(False) i=urlQueue.qsize()#返回队列的大小 except Exception as e: break print('当前线程名%s,url:%s'%(threading.currentThread().name,url)); try: response=urllib.request.urlopen(url) responseCode=response.getcode() except Exception as e: continue if responseCode==200: #抓取内容的数据处理可以放到这里 # #为了突出效果, 设置延时 time.sleep(1) if __name__=='__main__': startTime=time.time() threads=[] threadNum=4 for i in range(0,threadNum): t=threading.Thread(target=fetchUrl,args=(urlQueue,)) threads.append(t) #将线程加入到容器 print(threads) for t in threads: t.start() for t in threads: t.join() endTime=time.time() print('time=%s'%(endTime-startTime))
参考学习:https://www.cnblogs.com/tkqasn/p/5700281.html
https://www.runoob.com/python/python-multithreading.html
https://www.cnblogs.com/itogo/p/5635629.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号