
Spring(10)深入Spring 数据库事务管理(一)
一、Spring 数据库事务管理器的设计
在Spring中数据库事务是通过PlatformTransactionManager 进行管理的,前面我们用到的jdbcTemplate是不支持事务的,而支持事务的是org.sringframework. transaction. support. Transaction Template 模板,它是 Spring 所提供的事务管理器的模板。
1.明确Spring事务控制
(1)JavaEE 体系进行分层开发,事务处理位于业务层,Spring 提供了分层设计业务层的事务处理解决方案。
(2)spring 框架为我们提供了一组事务控制的接口。这组接口是在spring-tx-5.0.2.RELEASE.jar 中。
(3)spring 的事务控制都是基于 AOP 的,它既可以使用编程的方式实现,也可以使用配置的方式实现。我们学习的重点是使用配置的方式实现。
2.Spring 数据库事务管理器的设计
PlatformTransactionManager 接口的源码如下:
public interface PlatformTransactionManager { //获取事务状态 TransactionStatus getTransaction(TransactionDefinition definition ) throws TransactionException ; //提交事务 void commit(TransactionStatus status) throws TransactionException ; //回滚事务 void rollback(TransactionStatus status) throws TransactionException ; }
在Spring 数据库事务管理器设计中,DataSourceTransactionManager 它继承抽象事务管理器 AbtractPlatformansactinManager,而AbstractPlatformTransactionManager又实现了PlatformTransactionManager,它们使用 PlatformTransactionManager接口方法,创建提交或者回滚事务。
3.Spring 中事务控制的API介绍
在实际开发中我们使用的都是PlatformTransactionManager具体实现类。
(1)PlatformTransactionManager
org.springframework.jdbc.datasource.DataSourceTransactionManager 使用 SpringJDBC 或 iBatis 进行持久化数据时使用
org.springframework.orm.hibernate5.HibernateTransactionManager使用Hibernate 版本进行持久化数据时使用
改接口中提供事务操作方法,包含以下3个具体操:

(2)TransactionDefinition
它是事务的定义信息对象,里面有如下方法:

二、数据库相关知识
1.数据库事务 ACID 特性
数据库事务正确执行的 个基础要素是原子性(Atomicity )、一致性( Consistency )、隔离性 Clso lation )和持久性( Durabi lity)。
(1)原子性: 整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没被执行过样。
(2)一致性:指 个事务可以改变封装状态(除非它是 个只读的〉。事务必须始终保持系统处于一致的状态,不管在任何给定的时间并发事务有多少。
(3)隔离性: 它是指两个事务之间的隔离程度。
(4)持久性: 在事务完成以后,该事务对数据库所做的更改便持久保存在数据库之中,并不会被回滚。
2.丢失更新
在如今的互联网生活中存在着秒杀、抢购等高并发场景,这样就使得数据库在一个多事务环境中运行,多个事务并发会引发一系列问题,主要问题就是丢失更新问题,一般存在两种丢失更新问题,我下面分别举例说明。
(1)第一类丢失更新(回滚丢失,Lost update)
假设这个场景,一张银行卡存在互联网消费和刷卡消费,刚好一对夫妻共用该卡进行消费,丈夫喜欢刷卡消费,妻子喜欢互联网消费,那么存在下面情景:
| 时刻 | 事务一(丈夫) | 事务二(妻子) |
| T1 | 查询余额10000元 | —— |
| T2 | —— | 查询余额10000元 |
| T3 | —— | 网购消费1000元 |
| T4 | 喝酒吃饭1000元 | —— |
| T5 | 提交事务成功,余额9000元 | —— |
| T6 | —— | 退货,回滚事务到T2时刻,余额10000元 |
第一类丢失更新
整个过程中丈夫消费1000元,卡余额9000元,而在最后T6时刻妻子退货,事务回滚,却恢复了卡余额10000元,这显然不符合事实,我们称这种现象为第一类丢失更新。好在现在大部分数据库都已经解决了该类丢失更新问题。
(2)第二类丢失更新(覆盖丢失/两次更新问题,Second lost update)
| 时刻 | 事务一(丈夫) | 事务二(妻子) |
| T1 | 查询余额10000元 | —— |
| T2 | —— | 查询余额10000元 |
| T3 | —— | 网购花费1000元 |
| T4 | 吃饭喝酒1000元 | —— |
| T5 | 提交事务成功,查询余额9000元。(消费1000元后余额为9000元) | —— |
| T6 | 提交事务,根据之前查询余额10000元,消费1000元后,余额9000元 |
第二类丢失更新
在整个场景中存在两笔交易,一笔交易是丈夫吃饭喝酒消费,一笔是妻子购物消费,但是两者都提交了事务,在不同事务中,无法预知其他事务相关操作,导致两者提交事务后余额都为9000元,实际上应该是8000元,这就是第二类丢失会更新。为了解决事务之间协助的一致性,数据库标准规范中定义了事务之间的隔离级别,从而在一定程度上减少丢失更新的可能性。
3.事务的隔离级别
隔离级别可以在不同程度上减少丢失更新,根据SQL标准规范隔离级别分为四层,分别是脏读( dirty read )、读/写提交( read commit )、可重复读( repeatable read )和序列化( Serializable )。

(1)脏读
是最低的隔离级别,表示允许 一个事务去读取另 一个事务中未提交的数据。以上面例子进行讲解:
| 时刻 | 事务一(丈夫) | 事务二(妻子) | 备注 |
| T1 | 查询余额10000元 | —— | —— |
| T2 | —— | 查询余额10000元 | —— |
| T3 | —— | 网购花费1000元,余额9000元 | —— |
| T4 | 吃饭喝酒1000元,余额8000元 | —— | 读取到事务二,未提交余额9000元事务,所以余额8000元 |
| T5 | 提交事务 | —— | 余额8000元 |
| T6 | —— | 回滚事务 |
由于第 一类丢失更新数据库己经克服,所以余额为错误的 8000元 |
由于在T3时刻妻子启动了消费,导致余额为8000 元,老公在T4时刻消费,因为用了脏读,所以能够读取老婆消费的余额(注意,这个余额是事务二未提交的)为9000元,这样余额就为8000元了,于是T5时刻丈夫提交事务,余额变为了8000 元,妻子在T6时刻回滚事务,由于数据库克服了第一类丢失更新,所以余额依旧为8000元,显然这个错误的余额,产生这个错误的根源来自于T4时刻,也就是事务一可以读取事务二未提交的事务,这样的场景被称为脏读。
(2)读/写提交
读/写提交,就是一个事务只能读取另以个事务已经提交的数据。依旧以丢失更新妻子消费为例,如表:
| 时刻 | 事务一(丈夫) | 事务二(妻子) | 备注 |
| T1 | 查询余额10000元 | —— | —— |
| T2 | —— | 查询余额10000元 | —— |
| T3 | —— | 网购消费1000元,余额9000元 | —— |
| T4 | 吃饭喝酒1000元,余额9000元 | —— |
由于事务二的余额未提交,采取读/写提 |
| T5 | 提交事务 | —— | 余额9000元 |
| T6 | —— | 回滚事务 |
由于第一类丢失更新数据库已经克服, |
在T3时刻,由于事务采取读/写提交的隔离级别,所以丈夫无法读取妻子未提交的 9000 元余额 ,他只能读到余额为 10 000 元,所以在消费后余额依旧为 9000 。在 T5 时刻提事务,而 T6 时刻妻子回滚事务,所以结果为正确9000 元,这样就消除了脏读带来的问题,但是也会引发其他的问题。接着看下面分析。
(3)可重复读
| 时刻 | 事务一(丈夫) | 事务二(妻子) | 备注 |
| T1 | 查询余额10000元 | —— | —— |
| T2 | —— | 查询余额10000元 | —— |
| T3 | —— | 网上购物花费1000元,余额9000元 | —— |
| T4 | 吃饭喝酒花费2000元,余额8000元 | —— |
由于采取读/写提交 ,不能读取事务 |
| T5 | —— | 继续购物8000元,余额1000元 |
由于采取读/写提交 ,不能读取事务 |
| T6 | —— | 提交事务,余额1000元 | 妻子提交事务,余额更新为 1000 |
| T7 |
提交事务发现余额为1000 不足以买单 |
—— |
由于采用读/写提交,因此此时事务一 |
由于 T7 时刻事务一知道事务二提交的结果余额为 1000 元,导致丈夫无钱买单的尴尬 对于老公而言,他并不知道妻子做了什么事情,但是账户余额却莫名其妙地从 10 000 元变为了1 000 元,对他来说账户余额是不能重复读取的,而是一 个会变化的值,这样的场景我们称为不可重复读( unrepeatable read ),这是读/写提交存在的问题。
为了克服不可重复读带来的错误, SQL 标准又提出了一个可重复读的隔离级别来解问题。注意,可重复读这个概念是针对数据库同一条记录而言的,换句话说,可重复读会使得同一条数据库记录的读/写按照一个序列化进行操作,不会产生交叉情况,这样就能证同一条数据的一致性,进而保证上述场景的正确性。但是由于数据库并不是只能针对一条数据进行读/写操作,在很多场景下数据库需要同时对多条记录进行读/写,这个时候就会产生下面的情况,如下表所示:
| 时刻 | 事务一(丈夫) | 事务二(妻子) | 备注 |
| T1 | —— | 查询消费记录有10条,准备打印 | 初始状态 |
| T2 | 启用消费1笔 | —— | —— |
| T3 | 提交事务 | —— | —— |
| T4 | —— | 打印消费记录得到11条 |
妻子发现打印了11条消费记录,比查询的10条多了 |
妻子在 Tl 询到 10 条记录,到 T4 打印记录时,并不知道丈夫在 T2 T3 时刻进了消费,导致多 1条(可重复读是针对同一条记录而言的,而这里不是同一 条记录)消费记录的产生 ,她会质疑这条多出来的记录是不是幻读出来的,这样的场景我们称为幻读。(phantom read)。
(4)序列化
序列化的隔离级别它是一种让SQL按照顺序读写的方式,能够消除数据库事务之间并发产生数据不一致的问题。它有效的克服了幻读。
各类隔离级别产生的现象:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 脏读 | √ | √ | √ |
| 读/写提交 | χ | √ | √ |
| 可重复读 | χ | χ | √ |
| 序列化 | χ | χ | χ |
4.选择隔离级别
在实际工作中我们不但要考虑数据库的一致性,而且还要考虑数据库的性能,一般而言,从脏读到序列化,系统性能直线下降。因此设置较高级别隔离比如序列化 会严重压制并发,从而引发大量的线程挂起,直到获得锁才能进一步操作 而恢复时又需要大量的等时间。在大部分场景应用中 ,会选择读/写提交的方式设置事务,这样既有助于提高并发,又压制士脏读,但是对于数据 致性问题并没有解决。基于应用不是所有业务都有并发操作,因此针对不需要或者并发业务少的场景可以考虑序列化级别保证数据的一致性。
5.传播行为
传播行为是指方法之间的调用事务策略的问题。大部分情况下我们希望事务能够同时成功或失败,但也有例外,比如实现信用卡还款,有一个总的调用代码逻辑一一-RepaymentBatchService batch 方法,它要实现的是记录还款成功的总卡数和对应完成的信息,每一 张卡的还款则是通过 RepaymentBatchService的repay 方法完成的。
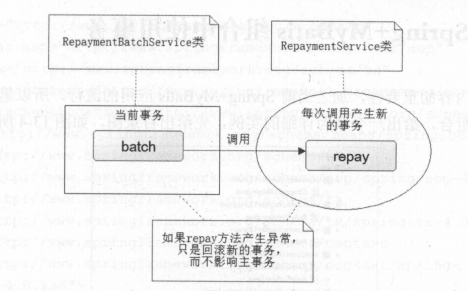
从上图分析,假如只有一条事务,那么调用-RepaymentBatchService的repay方法对某张信用卡进行还款,此时发生异常,如果此事务回滚就会造成所有相关数据进行回滚,那些正常还款的也会失败,这不是正确的结果。此时我们要求batch方法调用repay方法时,自动未repay方法创建一个新的事务,发生异常时回滚而不影响其他事务。
上面描述的batch 方法去调度 repay 方法时能产生一条新事务,去处理 一个信用卡还款 ,如果该卡还款异常,那么只会回滚这条新事务,而不是回滚主事务,类似这样一个方法调度另外一个方法时,可以对事务的特性进行传播配置,我们称为传播行为。
在Spring中 传播行为的类型,是通过一个枚 举类型去定义 的,这个枚举类是org .springfamework.transaction.annotation.Propagation,传播行为有如下几种:
(1)REQUIRED:如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。一般的选择(默认值)
(2)SUPPORTS:支持当前事务,如果当前没有事务,就以非事务方式执行(没有事务)
(3)MANDATORY:使用当前的事务,如果当前没有事务,就抛出异常
(4)REQUERS_NEW:新建事务,如果当前在事务中,把当前事务挂起。
(5)NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起
(6)NEVER:以非事务方式运行,如果当前存在事务,抛出异常
(7)NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行 REQUIRED 类似的操作。
6.超时时间
默认值是-1,没有超时限制。如果有,以秒为单位进行设置。
7.是否是只读事务
建议查询时设置为只读。
8.TransactionStatus
此接口提供的是事务具体的运行状态,方法介绍如下图:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号