

神经网络与模式识别课程报告-卷积神经网络(CNN)算法的应用
=======================================================================================
完整的神经网络与模式识别课程报告文档下载:
https://wenku.baidu.com/view/393fbc7853e2524de518964bcf84b9d528ea2c92?aggId=393fbc7853e2524de518964bcf84b9d528ea2c92&fr=catalogMain_&_wkts_=1718955412936
1 2 3 4 5 6 7 8 9 | def get_information(): ''' @方法名称: 获取资料或者源码 @作 者: PandaCode辉 @weixin公众号: PandaCode辉 @创建时间: 2024-06-21 ''' print('需要更多资料或者源码的朋友,可以关注我的weixin公众号留言找我。') return 1 |
=======================================================================================
第1章 概要设计
1.1 设计目的
人工神经网络是深度学习之母。随着深度学习技术的兴起及其在阿尔法围棋程序等实际应用的精彩表现,神经网络已经广泛地应用于图像的分割和对象的识别、分类问题中。伴随人工神经网络的发展,神经网络在模式识别领域中起着越来越重要的作用。通过本课程的学习,让大家从算法的视角,掌握神经网络与模式识别这两个彼此紧密联系的人工智能分支中的基础理论、问题、思路与方法,并理解神经网络与模式识别的研究前沿。
1.2 选题
验证码(CAPTCHA)是一种常见的用于区分人类和机器的技术,常用于网站、APP用户登陆时输入一些数字或字符以验证其身份。本文将介绍如何使用卷积神经网络(CNN)来识别常见的字符验证码。
选择使用卷积神经网络(CNN)用于验证码识别方向的原因有以下几点:
1. 强大的图像处理能力:CNN是一种特别适用于处理图像数据的深度学习模型。它具有多层结构,可以自动学习和提取图像中的特征,如边缘、纹理和形状等。这使得CNN在图像识别、分类和检测任务中表现出色。
2. 高准确率:与其他传统机器学习方法相比,CNN在验证码识别方面具有更高的准确率。这是因为CNN可以更好地捕捉图像中的局部特征和空间关系,从而提高识别性能。
3. 抗干扰能力强:验证码通常包含一定程度的噪声、变形和遮挡等干扰因素。CNN具有较强的抗干扰能力,可以通过学习大量的训练数据来适应这些变化,从而提高识别准确性。
4. 适应性强:CNN可以处理不同类型和风格的验证码,如数字、字母、混合型等。此外,它还可以轻松地扩展到其他相关任务,如文本识别和目标检测等。
5. 实时性:CNN具有较高的计算效率,可以在较短的时间内完成验证码识别任务。这对于需要实时处理大量验证码的应用场景非常重要。
综上所述,选择使用CNN用于验证码识别方向的原因是其强大的图像处理能力、高准确率、抗干扰能力强、适应性强以及实时性等优点。
1.3 CNN神经网络算法的原理
CNN(Convolutional Neural Network,卷积神经网络)神经网络算法的原理主要基于人类视觉系统的工作原理。这种算法在计算机视觉和图像分析领域中被广泛使用,并显示出强大的能力,尤其是在图像分类、物体检测、人脸识别等任务中。
CNN的基本结构包括输入层、卷积层、激活函数、池化层(有时称为下采样层或子采样层)和全连接层(通常为多层)。输入层负责接收原始图像数据。卷积层则通过卷积核对输入数据进行特征提取,这里的卷积核本质上是一个可学习的滤波器,它在输入数据上滑动并计算点积,生成新的特征图。这些特征图随后被送入激活函数(如ReLU),以增加模型的非线性表达能力。
池化层位于卷积层之后,其作用是降低数据的空间尺寸(即降维),减少计算量,同时提取主要特征。常见的池化操作包括最大池化和平均池化。卷积层和池化层的组合可以在隐藏层中多次出现,形成深层网络结构,以提取更高级别的抽象特征。
在若干卷积和池化层之后,全连接层负责将学到的特征表示映射到样本标记空间。全连接层的每一层都包含许多神经元,这些神经元与前一层中的所有神经元相连。最后一层通常使用Softmax激活函数来进行分类任务,输出每个类别的概率分布。
CNN的训练过程包括前向传播和反向传播两个阶段。在前向传播阶段,输入数据通过网络逐层传递,最终得到输出结果。在反向传播阶段,根据损失函数计算出的误差通过梯度下降等优化算法逐层反向传播,更新网络中的权重参数,以减小预测误差。
总的来说,CNN神经网络算法通过模拟人类视觉系统的工作原理,逐层提取输入数据的特征表示,并通过全连接层进行分类或回归等任务。这种算法在图像处理领域具有广泛的应用前景,并不断推动着计算机视觉技术的发展。
1.4 程序概要设计
验证码(CAPTCHA)是一种常见的用于区分人类和机器的技术,常用于网站、APP用户登陆时输入一些数字或字符以验证其身份。使用卷积神经网络(CNN)来识别常见的字符验证码,主要步骤流程如下。
第一步:准备训练数据集、测试数据集
第二步:CNN模型构建
第三步:模型训练
第四步:评估模型性能
第五步:模型预测、部署
第2章 程序整体设计说明
2.1 第一步:准备训练数据集、测试数据集
首先,我们需要收集带有字符验证码的图片数据,并将其分为训练集和测试集。确保每张图片都标记了正确的字符。
很多网站都有验证码功能,可以先写个爬取验证码图片的脚本,采集了1000份目标网站的验证码图片;80%用于训练数据集,20%用于测试数据集;然后人工打上标签,把答案作为验证码图片的文件名前4个字符。
然后需要将采集的1000份验证码图片进行字符切割预处理,分割成单个字符的图片保存,这些分割后的图片才是训练数据集和测试数据集,单个字符图片更适合于卷积神经网络算法训练,训练的模型准确度更高。
# 数据集目录结构示例:
# ├── data
# │ ├── image_train
# │ │ ├── 0
# │ │ ├── 1
# │ │ ├── 2
# │ │ ├── ...
# │ ├── image_test
# │ │ ├── 0
# │ │ ├── 1
# │ │ ├── 2
# │ │ ├── ...
# │ ├── train
# │ │ ├── 8zk4.png
# │ │ ├── 9b2w.png
# │ │ ├── 9c5n.png
# │ │ ├── ...
# │ ├── test
# │ │ ├── 2d2w.png
# │ │ ├── 2dy7.png
# │ │ ├── 2f8r.png
# │ │ ├── ...
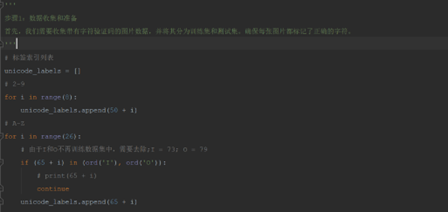
(1) 标签列表
由于使用了 sparse_categorical_crossentropy 作为损失函数。这个损失函数是为整数形式的标签设计的,而不是one-hot编码的标签。
它要求标签值必须在 0 到类别数减1(在这个案例中应该是 0 到 31,如果你有 32 个类别)的范围内。
为了解决这个问题,需要检查 train_labels 和 test_labels 中的标签值,确保它们都在正确的范围内。
这里采用unicode编码转换单个数字和字母字符,根据采集的样本类型特性,统一转换为对应列表索引值,作为样本的标签值,保证是整数形式。
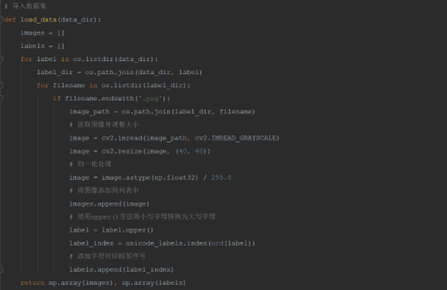
(2) 导入数据集方法
根据目录导入数据集,统一处理样本集,图片添加到图片列表中;图片标签需要统一转换下,然后添加到标签列表中返回。
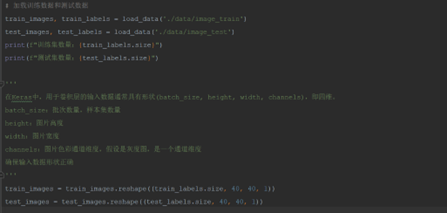
(3) 加载训练数据和测试数据
注意:在Keras中,用于卷积层的输入数据通常具有形状(batch_size, height, width, channels),即四维,确保输入数据形状正确。
batch_size:批次数量,样本集数量
height:图片高度
width:图片宽度
channels:图片色彩通道维度,假设是灰度图,是一个通道维度
2.2 第二步:CNN模型构建
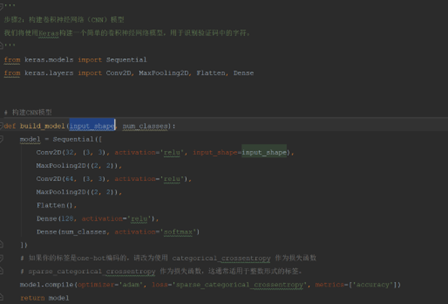
使用Keras库来构建一个卷积神经网络(CNN)模型。
input_shape: 输入数据的形状,例如,对于彩色图像,它可能是一个形如(height, width, channels)的元组,其中channels通常是3(RGB)。
num_classes: 输出的类别数,即模型需要预测的不同类别的数量。
函数内部定义了一个Sequential模型,并添加了以下层:
1.卷积层 (Conv2D):
第一个卷积层有32个过滤器(也称为卷积核),每个过滤器的大小是3x3。
激活函数是ReLU。
input_shape参数指定了输入数据的形状。
2.最大池化层 (MaxPooling2D):
池化窗口的大小是2x2。
这个层用于减少空间维度,同时保留最重要的特征。
3.第二个卷积层 (Conv2D):
有64个过滤器,每个过滤器的大小也是3x3。
激活函数仍然是ReLU。
4.第二个最大池化层 (MaxPooling2D):
与第一个最大池化层相同,窗口大小是2x2。
5.展平层 (Flatten):
用于将多维的输入一维化,以便可以连接到全连接层。
6.全连接层 (Dense):
第一个全连接层有128个神经元,激活函数是ReLU。
这个层用于学习非线性特征组合。
7.输出层 (Dense):
有num_classes个神经元,激活函数是softmax。
这个层用于输出每个类别的预测概率。
最后,模型使用Adam优化器进行编译,损失函数是稀疏分类交叉熵(sparse_categorical_crossentropy),并且监控准确性指标。
注意:sparse_categorical_crossentropy损失函数假定目标类别是整数形式,而不是one-hot编码形式。如果你的目标类别是one-hot编码的,你应该使用categorical_crossentropy作为损失函数。
返回编译后的模型,以便后续的训练和评估。
输入数据形状,然后构建模型。

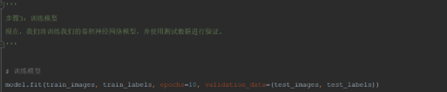
2.3 第三步:模型训练
根据训练数据集和构建的模型,训练我们的卷积神经网络模型。
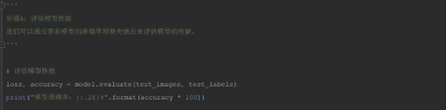
2.4 第四步:评估模型性能
评估一个训练好的模型在测试数据集上的性能。
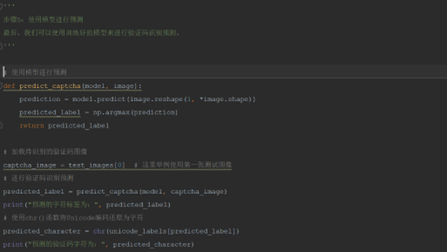
2.5 第五步:使用模型进行预测
最后,我们可以使用训练好的模型来进行验证码识别预测。
=======================================================================================
完整的神经网络与模式识别课程报告文档下载:
https://wenku.baidu.com/view/393fbc7853e2524de518964bcf84b9d528ea2c92?aggId=393fbc7853e2524de518964bcf84b9d528ea2c92&fr=catalogMain_&_wkts_=1718955412936
1 2 3 4 5 6 7 8 9 | def get_information(): ''' @方法名称: 获取资料或者源码 @作 者: PandaCode辉 @weixin公众号: PandaCode辉 @创建时间: 2024-06-21 ''' print('需要更多资料或者源码的朋友,可以关注我的weixin公众号留言找我。') return 1 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下