
PaddleOCR学习笔记3-通用识别服务
今天优化了下之前的初步识别服务的python代码和html代码。
采用flask + paddleocr+ bootstrap快速搭建OCR识别服务。
代码结构如下:
模板页面代码文件如下:
upload.html :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 | <!DOCTYPE html><html><meta charset="utf-8"><head> <title>PandaCodeOCR</title> <!--静态加载 样式--> <link rel="stylesheet" href={{ url_for('static',filename='bootstrap3/css/bootstrap.min.css') }}></link> <style> body { font-family: Arial, sans-serif; margin: 0; padding: 0; } .header { background-color: #f0f0f0; text-align: center; padding: 20px; } .title { font-size: 32px; margin-bottom: 10px; } .menu { list-style-type: none; margin: 0; padding: 0; overflow: hidden; background-color: #FFDEAD; border: 2px solid #DCDCDC; } .menu li { float: left; font-size: 24px; } .menu li a { display: block; color: #333; text-align: center; padding: 14px 16px; text-decoration: none; } .menu li a:hover { background-color: #ddd; } .content { padding: 20px; border: 2px solid blue; } </style></head><body><div class="header"> <div class="title">PandaCodeOCR</div></div><ul class="menu"> <li><a href="/upload/">通用文本识别</a></li></ul><div class="content"> <!--上传图片文件--> <div id="upload_file"> <form id="fileForm" action="/upload/" method="POST" enctype="multipart/form-data"> <div class="form-group"> <input type="file" class="form-control" id="upload_file" name="upload_file"> <label class="sr-only" for="upload_file">上传图片</label> </div> </form> </div></div></div><div id="show" style="display: none;"> <!--显示上传的图片--> <div class="col-md-6" style="border: 2px solid #ddd;"> <span class="label label-info">上传图片</span> <!--静态加载 图片, url_for() 动态生成路径 --> <img src="" alt="Image preview area..." title="preview-img" class="img-responsive"> </div> <div class="col-md-6" style="border: 2px solid #ddd;"> <!--显示识别结果JSON报文列表--> <span class="label label-info">识别结果:</span> <!-- 结果显示区 --> <div id="result_show">加载中......</div> </div></div></body></html><!--静态加载 script--><script src={{ url_for('static',filename='jquery1.3.3/jquery.min.js') }}></script><script src={{ url_for('static',filename='js/jquery-form.js') }}></script><script type="text/javascript"> var fileInput = document.querySelector('input[type=file]'); var previewImg = document.querySelector('img'); {#上传图片事件#} fileInput.addEventListener('change', function () { var file = this.files[0]; var reader = new FileReader(); //显示预览界面 $("#show").css("display", "block"); // 监听reader对象的的onload事件,当图片加载完成时,把base64编码賦值给预览图片 reader.addEventListener("load", function () { previewImg.src = reader.result; }, false); // 调用reader.readAsDataURL()方法,把图片转成base64 reader.readAsDataURL(file); //初始化输出结果信息 $("#result_show").html("加载中......"); {#上传图片识别表单事件,并显示识别结果信息#} {# ajaxSubmit 请求异步响应#} $("#fileForm").ajaxSubmit(function (data) { var inner = ""; //alert(data['recognize_time']) //循环输出返回结果,响应识别结果为每行列表 for (var i in data['result']) { var value = data['result'][i]['text']; inner += "<p class='text-left'>" + value + "</p>"; } //清空输出结果信息 $("#result_show").html(""); //添加识别结果信息 $("#result_show").append(inner); }); }, false);</script> |
主要python代码文件如下:
myapp.py:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 | import jsonimport osimport timefrom flask import Flask, render_template, request, jsonifyfrom paddleocr import PaddleOCRfrom PIL import Image, ImageDrawimport numpy as np# 应用名称,当前py名称,视图函数app = Flask(__name__)# 项目文件夹的绝对路径# BASE_DIR = os.path.dirname(os.path.abspath(__name__))# 相对路径BASE_DIR = os.path.dirname(os.path.basename(__name__))# 上传文件路径UPLOAD_DIR = os.path.join(os.path.join(BASE_DIR, 'static'), 'upload')'''PaddleOCR模型通用识别方法'''def rec_model_ocr(img): # 返回字典结果对象 result_dict = {'result': []} # paddleocr 目前支持的多语言语种可以通过修改lang参数进行切换 # 例如`ch`, `en`, `fr`, `german`, `korean`, `japan` # 使用CPU预加载,不用GPU # 模型路径下必须包含model和params文件,目前开源的v3版本模型 已经是识别率很高的了 # 还要更好的就要自己训练模型了。 ocr = PaddleOCR(det_model_dir='./inference/ch_PP-OCRv3_det_infer/', rec_model_dir='./inference/ch_PP-OCRv3_rec_infer/', cls_model_dir='./inference/ch_ppocr_mobile_v2.0_cls_infer/', use_angle_cls=True, lang="ch", use_gpu=False) # 识别图片文件 result0 = ocr.ocr(img, cls=True) result = result0[0] for index in range(len(result)): line = result[index] tmp_dict = {} points = line[0] text = line[1][0] score = line[1][1] tmp_dict['points'] = points tmp_dict['text'] = text tmp_dict['score'] = score result_dict['result'].append(tmp_dict) return result_dict# 转换图片def convert_image(image, threshold=None): # 阈值 控制二值化程度,不能超过256,[200, 256] # 适当调大阈值,可以提高文本识别率,经过测试有效。 if threshold is None: threshold = 200 print('threshold : ', threshold) # 首先进行图片灰度处理 image = image.convert("L") pixels = image.load() # 在进行二值化 for x in range(image.width): for y in range(image.height): if pixels[x, y] > threshold: pixels[x, y] = 255 else: pixels[x, y] = 0 return image@app.route('/')def upload_file(): return render_template('upload.html')@app.route('/upload/', methods=['GET', 'POST'])def upload(): if request.method == 'POST': # 每个上传的文件首先会保存在服务器上的临时位置,然后将其实际保存到它的最终位置。 filedata = request.files['upload_file'] upload_filename = filedata.filename print(upload_filename) # 保存文件到指定路径 # 目标文件的名称可以是硬编码的,也可以从 request.files[file] 对象的 filename 属性中获取。 # 但是,建议使用 secure_filename() 函数获取它的安全版本 if not os.path.exists(UPLOAD_DIR): os.makedirs(UPLOAD_DIR) img_path = os.path.join(UPLOAD_DIR, upload_filename) filedata.save(img_path) print('file uploaded successfully') start = time.time() print('=======开始OCR识别======') # 打开图片 img1 = Image.open(img_path) # 转换图片, 识别图片文本 # print('转换图片,阈值=220时,再转换为ndarray数组, 识别图片文本') # 转换图片 img2 = convert_image(img1, 220) # Image图像转换为ndarray数组 img_2 = np.array(img2) # 识别图片 result_dict = rec_model_ocr(img_2) # 识别时间 end = time.time() recognize_time = int((end - start) * 1000) result_dict["filename"] = upload_filename result_dict["recognize_time"] = str(recognize_time) result_dict["error_code"] = "000000" result_dict["error_msg"] = "识别成功" # render_template方法:渲染模板 # 参数1: 模板名称 参数n: 传到模板里的数据 # return render_template('result.html', result_dict=result_dict) # 将数据转换成JSON格式,一般用于ajax异步响应页面,不跳转页面用,等价下面方法 # return json.dumps(result_dict, ensure_ascii=False), {'Content-Type': 'application/json'} # 将数据转换成JSON格式,一般用于ajax异步响应页面,不跳转页面用 return jsonify(result_dict) else: return render_template('upload.html')if __name__ == '__main__': # 启动app<br> app.run(port=8000) |
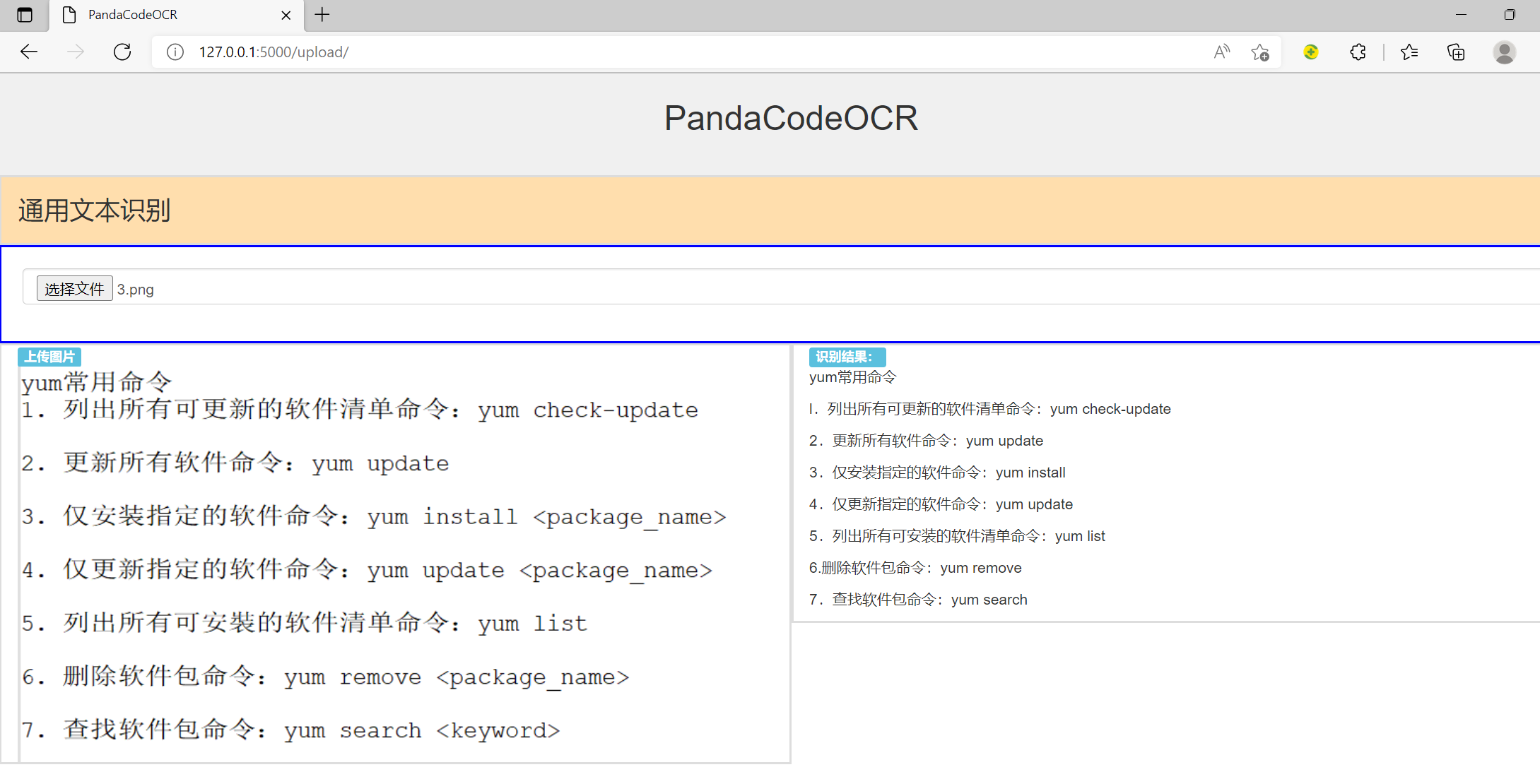
启动flask应用,测试结果如下:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App