systemverilog学习(6)并发进程与内部通信
sv提供了下列处理并发进程的能力:
fork...join并发结构,
通过mailbox实现进程间的通信,
通过semaphore实现进程互斥与仲裁,
通过event实现进程之间的同步
一:fork...join
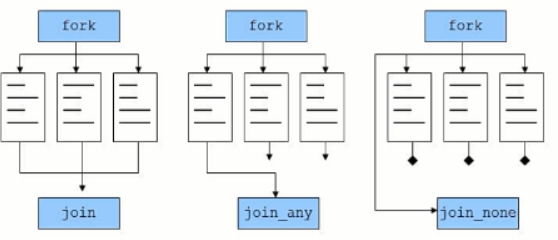
fork...join能够启动产生多个并发进程,提供三种并发方式:fork...join,fork...join_any,fork...join_none
1: fork...join
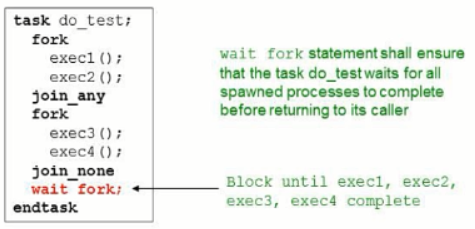
执行fork语句的进程,并阻塞父进程的执行,直到fork...join中所有进程(子进程)中止
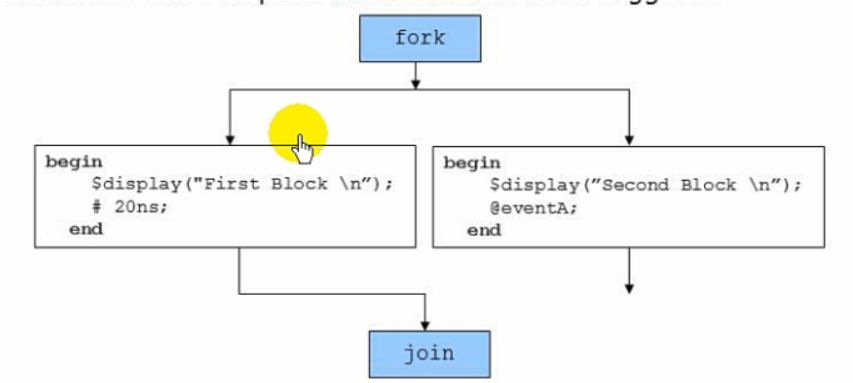
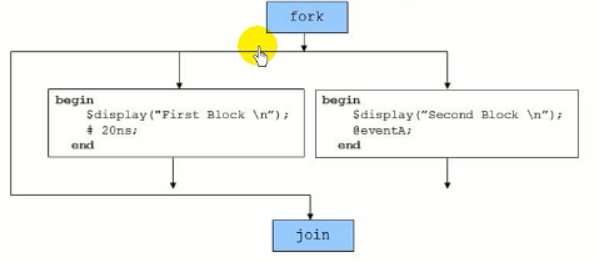
可以将子进程放在begin...end里,如下图。process1与process2同时执行;直到20ns并且eventA被触发,才结束整个fork...join的结构,执行父线程。

2:fork...join...any
父进程会被阻塞直到任意一个子进程结束
3:fork...join...none
父进程不会被阻塞,父进程会立即与产生的所有进程并发操作
4:wait fork
等待所有fork进程全部执行完
5:disable fork
用于看门狗等,在fork..join any中,任何一个fork进程执行完,其他进程被disable掉。
如下例,第一个进程结束,其他进程则不执行,跳出fork,执行下面的语句。

二:events
1:事件触发
命名事件可以通过“->”操作符触发。触发一个事件可以接触当前所有等待这个事件被阻塞的进程。当被触发后,命名事件的行为就好像一次射击,也就是说,触发状态本身是不可观测的,我们仅仅能够观测到它的效果。这种方式类似于边沿触发一个触发器,但边沿的状态却不能永远持续和获取,也就是说,if(posedge clock)是非法的。
阻塞事件用“->>”操作符触发,“->>”操作符的效果1是语句会无阻塞地执行,并且在延时控制过期或者事件控制发生的时候,会产生一个非阻塞的赋值更新事件。
状态标志位trigered:检查事件是否被触发,若以及被触发,则返回1。
2:事件等待
@ event1; wait(event1.triggered);
3:wait_order
用于看状态机由一个状态跳到另一个状态
wait_order(a,b,c)
4:事件可相互赋值,而且触发的状态也可赋给另一个值。

5:事件赋于null
event e1 = null;
事件赋值为空,则@E1;wait(E1.triggered);->E1;均无效。
6:事件比较
可用==/!=进行事件的比较。
三:semaphores(旗语)
当多个进程进行通信时,就可能出现竞争。多个进程可能需要使用一个稀缺资源,但是由于资源的约束,只有一定数量的进程才可以有访问权限。现实的例子就是:如果多个进程需要通过一个接口发送数据包,每个进程需要等待自己获取权限才可以发送(因为每次只能允许一个包在该接口上发送)。
每当出现资源竞争的时候,获取一个共享资源就必须通过仲裁。sv通过semaphore提供了仲裁的功能,提供对共享资源的访问。
从概念上讲,semaphore可以理解成一个存储桶。当为semaphore分配内存的时候,会创建一个带有一定数目key的存储桶。使用semaphore的进程在继续执行之前必须首先从存储桶中获得一个key。同时执行的进程数目与key的数目一致。所有其他进程必须等待直到足够数目的key被放回到存储桶中。如图下所示:

1:定义及其使用
semaphore smtx;
semaphore是一个内建的类,它提供下列方法:
1)创建一个具有指定数目key的semaphore:new()
原型:function new(int keyCount = 0)
semaphore使用new()方法创建。KeyCount指定了最初被分配到semaphore存储桶地key的数目。当放入存储桶的key比取出的数目多的时候,存储桶中key的数目可以超过KeyCount。KeyCount的缺省值为0。new()函数返回semaphore的句柄,如果没有产生semaphore,则返回null。
2) 从存储桶里取出一个或者多个key:get()
原型:task get(int KeyCount = 1)
get()方法被用来从一个semaphore中获得指定数目的key,KeyCount指定了需要获得的key的数目,它的缺省值为1.如果指定数目的key存在,那么方法返回并且进程会继续执行;如果不存在指定数目的key,进程会阻塞对应数量的key出现。
3) 向存储桶里放回一个或者多个key:put()
原型:task put(int KeyCount = 1)
KeyCount指定了放回到key的数目,它的缺省值为1。当调用semaphore.put任务的时候,指定数目的key被放回到semaphore中。如果一个进程已经被挂起来等待一个key,当返回了足够的key之后,这个进程可以继续执行。
4) 尝试无阻塞地获取一个或者多个key:try_get()
原型:function int try_get(int KeyCount = 1)
try_get方法用来无阻塞地获得指定数目的key,keyValue缺省值为1。如果指定数目的key存在,那么key_get方法返回1并且进程会继续执行;如果指定数目的key不存在,那么try_get方法返回0.
四:mailbox
它可以看成是一个先进先出 ( first in first out,FIFO) 的存储数组。 通常有一个或者多个进程把数据送入一个 mailbox, 有一个或者多个进程从 maibox 读出数据。 客户进程可以被挂起, 直至 mailbox有可用的数据, 也就是说, mailbox可以实现生产进程和客户进程的同步。
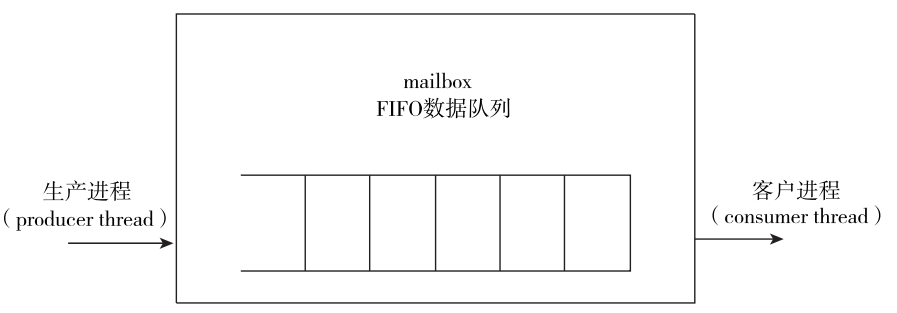
mailbox是一种通信机制,它使得数据可以在进程间传递和通信,数据被一个进程发送到另一个mailbox中,而另外一个进程可以从中可以获得。
从概念上讲,mailbox的行为相当于一个真实的邮箱。当一封信被分发并且放到邮箱的时候,另一个人可以重新取出这封信(存储在其中的任何数据)。然而,如果当这个人检查邮箱的时候,这封信还没有被分发,那么这个人必须做出选择:要么等待这封信被分发,要么在下一次检查邮箱时取出这封信。与此类似,sv的mailbox以一个可控的方式来传输和接收数据。在创建mailbox的时候,它可以是有界的队列,也可以是无边界的队列。。当一个有界mailbox存储的数据达到其边界数目时,mailbox会变满,试图向已经满了的mailbox放置数据的进程会被阻塞,直到mailbox队列有足够的空间;无边界mailbox永远也不会阻塞一个发送操作进程。
1:定义及其方法
mailbox mbxRcv;
mailbox是一个内建的类,它提供了下列方法:
1)创建一个mailbox:new()
缺省下,参数为0,表示mailbox是无边界的,此时put()操作永远不会被阻塞;如果参数不为0,那么它表示mailbox队列的长度(或者理解为FIFO的深度)。长度必须是正的;负的边界是非法的,并会导致不确定的行为。
2) 将一个数据放置到mailbox中:put()
严格按照FIFO的顺序将一个数据存储到mailbox中,如果mailbox是一个有界的队列而且队列已满,那么进程会被阻塞直到队列中有足够的空间。
3) 尝试将一个数据无阻塞地放置到mailbox中:try_put()
仅对有界mailbox有意义,如果mailbox没有满,那么指定的消息被放置mailbox当中,并且函数返回1。如果mailbox满了,那么函数返回0.
4) 从一个mailbox中获取一个数据:get() 或者 peek()
get():
从mailbox中取出一个数据并从队列中将其删除。如果mailbox是空的,那么当前的进程阻塞直到一个数据被放置到mailbox中。如果在数据变量和mailbox中的数据存在类型不匹配,那么会产生一个运行时错误。
peek():
从mailbox里复制一个数据,但不会将其从队列中删除。如果mailbox是空的,那么当前的进程会阻塞直到一个消息被放置到mailbox中。如果在数据变量和mailbox中的数据存在类型不匹配,那么会产生一个运行时错误。
5) 尝试无阻塞从一个mailbox中获取一个数据:try_get()或者try_peek()
try_get:
如果mailbox是空的,那么返回0。这里可以看出与get()的差别,try只从mailbox里获取一次,而get()如果没有获取到数据,会等待直到一个数据数据被放到mailbox。
try_peek:
从mailbox里复制一个数据,但不会将其从队列中删除。如果mailbox是空的,那么返回0。
6) 查询mailbox中数据的个数:num()
只有等到get()或者put()在mailbox上执行后才有效
2:阻塞与非阻塞操作


3:参数化mailbox
缺省的mailbox是无类型的,也就是说,单个mailbox可以发送和接收任何类型的数据。这是一个非常强大的机制,然而致命的是,它会因为存储数据与用来获取数据变量间的类型不匹配而导致运行错误,一个mailbox经常被用来传输一个特定类型的数据,在这种情况下,如果能够在编译时发现类型不匹配,那将是十分有用的。
参数化mailbox与参数化类,模块和接口使用相同的机制。其定义如下:
mailbox #(type = dynamic_type)
其中dynamic_type代表一个特殊的类型,它能够执行运行时的类型检查(缺省情况)。
一个特定类型的参数化的mailbox通过指定类型来声明。
4:举例
A: 同步mailbox
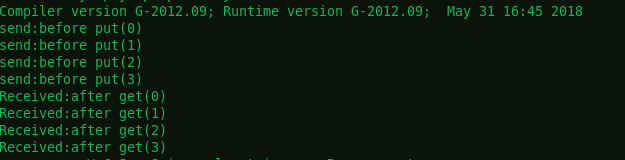
**延迟同步
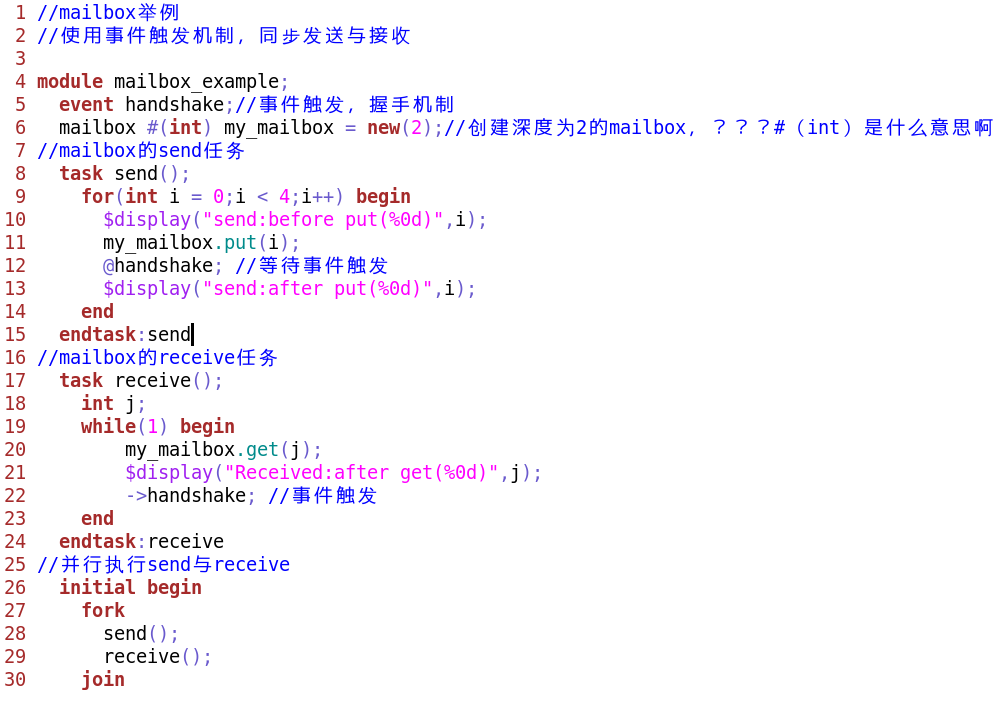
输出
**握手同步
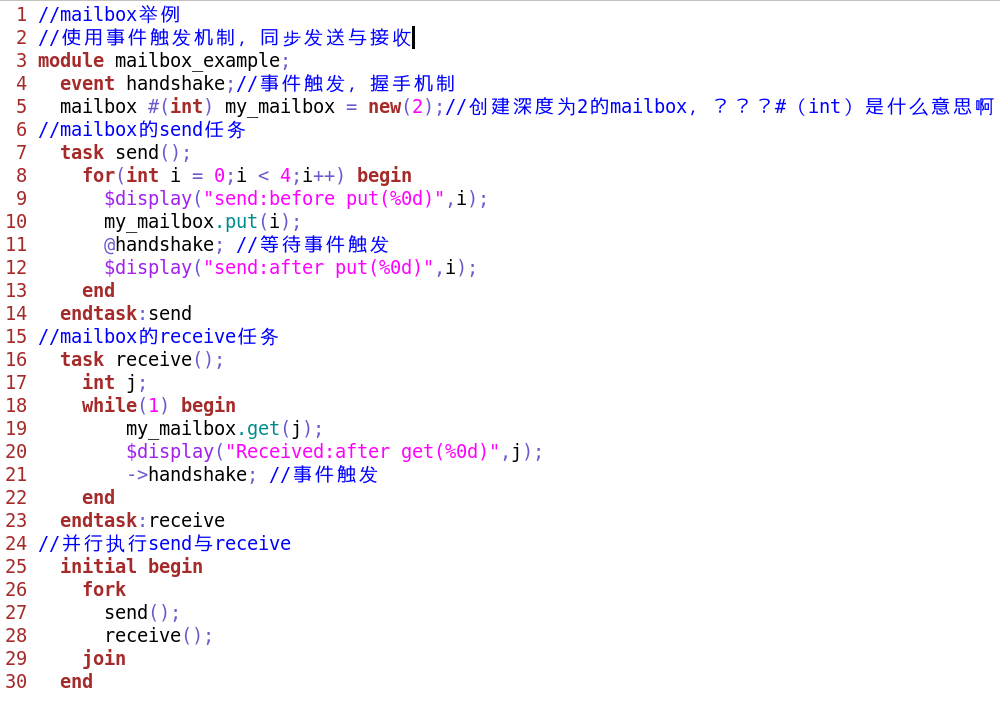
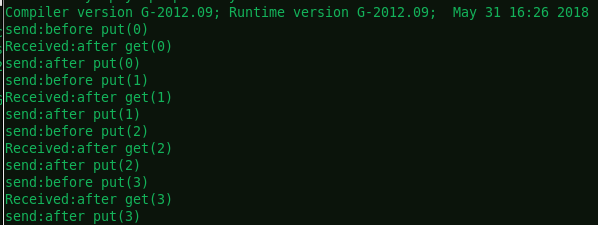
输出
**mailbox深度设为1:这种方法易导致race,并不适用于同步。
B:异步mailbox
由于mailbox产生(即send)一般不浪费时间,而处理(即receive)一般占用时间,所以不加处理的mailbox是异步的
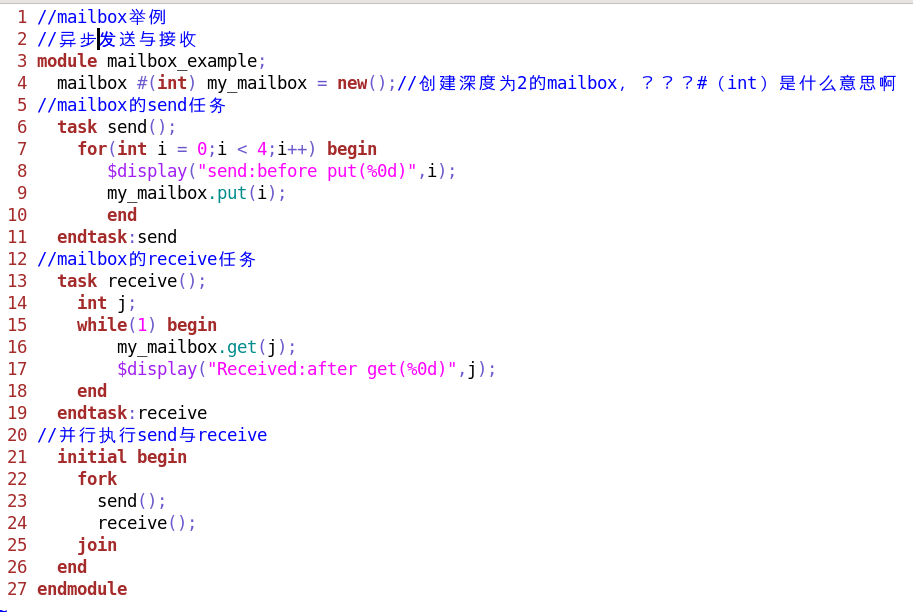
输出: