面试准备——(三)Selenium(1)基础问题及自动化测试
转载:https://www.cnblogs.com/lesleysbw/p/6413880.html
面试准备——(三)Selenium(1)基础问题及自动化测试
滴滴面试:
1. 自己负责哪部分功能?
农餐对接系统分为了两大子系统,一个是个人订餐系统,二是餐馆、个人与农产品供应商进行农产品交易系统。我主要负责组织测试人员对该系统进行测试。
我们测试分为两个阶段:
一、功能测试阶段。主要负责编写测试计划、测试用例、部署禅道BUG管理系统,进行功能测试。
首先,我们将系统分为了订餐平台、采购平台、登录注册、消费者/餐馆/供应商后台等七个模块。
其次,使用等价类划分和边界值分析法相结合,针对每个模块设计测试用例。
二、 UI层自动化测试。使用PO设计模式,工具是Selenium+Unit test+Jenkins。
2.1 目的
这个阶段,是在我们项目需求已经明确,版本已经稳定的情况下开始的,主要考虑了几个方面:
1. UI层在多平台、多浏览器下运行结果存在不同。也就是需要我们在不同平台、浏览器下运行相同的测试案例,大量的重复劳作力
2. 其次,我们项目因为前期设计不够严谨、版本部署不够规范,会出现BUG重复出现的情况,也就是需要我们每日构建后进行回归测试。
3. 同时,自己希望能够锻炼编程能力。
2.2 内容
在设计UI层自动化测试用例的时候,使用的是PO设计模式,也就是把每一个页面所需要操作的元素和步骤都封装在一个页面类中。然后 Selenium+Unit test搭建四层框架——实现数据、脚本、业务逻辑分离(关键字驱动)
1)基础层(BasePage)
设计一个基本的Page类,所有页面皆继承该类。提供了一个页面需要实现的基本功能及公共方法。
2)业务逻辑层(Pages):
按照PO设计模式,将每个页面抽象为一个类,放在Pages包里面,每个页面继承Basepage,可调用Data层数据,内容包括:
- 该页面所有的操作对象属性
- 实现的功能
3)数据层(Data)
该层存放相关数据,例如:用户数据和密码。在测试用例可通过调用数据层的数据来进行操作。
4)测试用例层(Testcases)
每一个测试用例testcase都对应Pages里面的一个页面,继承unnitest.TestCase类。通过调用对应页面类的方法,数据层的数据、增加断言(assert)来验证功能的正确性。
此外通过Jenkins自动执行测试、代码质量检测和部署到测试服务器、部署到生产服务器上
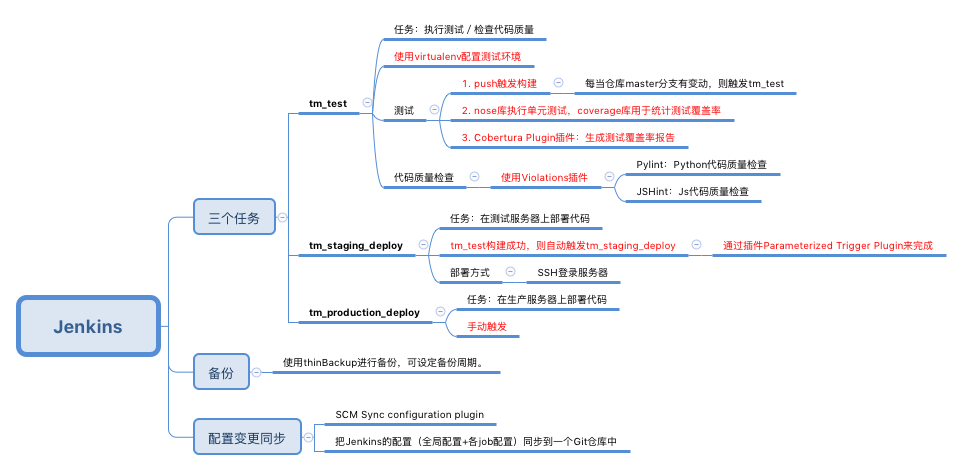
2.3 自动化测试执行策略——三个阶段
使用Jenkins持续集成工具来执行测试脚本和部署,主要设置了三个任务:
- tm_test:用于执行自动化测试脚本,检测代码质量
- tm_staging_deploy:用于在测试服务器上部署代码
- tm_deploy:用于在生产服务器上部署
我们将测试分为三个阶段:
1. 开发新的需求时,创建分支devN。当在这个分支中,需求开发完成或者Bug修复,就配合测试人员利用JUNit框架进行单元测试以及功能测试。通过测试后,合并到master上。
2. 当master有变动,则触发tm_test任务,执行自动化测试脚本和代码质量检测。如果通过则自动触发tm_staging_deploy,部署到测试服务器,如果没有通过,自动化测试脚本会将Bug截图发送给测试人员。
3. 登陆生产服务器上,对网站进行功能测试。如果通过测试,则手动触发tm_deploy,部署到生产服务器。如果没有通过,在禅道管理系统上把bug指派给相应模块的开发人员。
2. 在使用Selenium中遇到的最大的问题?如何解决?——测试用例的可靠性
http://blog.csdn.net/kufei123/article/details/47375065
误报通常是我们在使用selenium的最头疼的问题,这使得很难把selenium测试用例加入到自动构建中。有些构建是必须要成功的,如果失败将会阻塞整个发布流程。
解决方法——重试我们的解决方案是在测试步骤和测试集中都加入重试机制。
产生误报最大原因是selenium在页面加载完成之前就开始请求页面资源。
重试机制:
利用递归封装了一个等待元素的方法。其中,设置最大等待时间为1s,轮询时间为50ms,这个方法会不断轮询,直到方法执行成功或者超过设置的最大等待时间。在我们最好的一次实践中,我们把一个测试用例的误报率从10%降低到0,并且执行时间从原先的45秒降低到33秒。

@annotation.tailrec
private def retry[A](maxWaitMillis: Long, pollIntervalMillis: Long)(callback: => A): A = {
val start = System.currentTimeMillis
Try {
callback
} match {
case Success(value) => value
case Failure(thrown) => {
val timeForTest = System.currentTimeMillis - start
val maxTimeToSleep = Math.min(maxWaitMillis - pollIntervalMillis, pollIntervalMillis)
val timeLeftToSleep = maxTimeToSleep - timeForTest
if (maxTimeToSleep <= 0) { throw thrown } else { if (timeLeftToSleep > 0) {
Thread.sleep(timeLeftToSleep)
}
retry(maxWaitMillis - pollIntervalMillis, pollIntervalMillis)(callback)
}
}
}
}
其余还有元素定位问题:
我们主要通过Selenium WebDriver进行元素定位。但是会遇到两大类定位不到元素的情况:
1. ElementNotVisible元素不可见
对于这种情况,这个元素display = none/hidden,通过JS更改display = block来解决
2. NoSuchElementException没有这种元素
1)最常见的:页面没有加载完全,我们就去定位这个元素。
2)动态ID无法定位元素——1)直接使用Xpath相对路径;2)根据部分元素定位
3)Iframe——switch_to_iframe
4) Alert——switch_to_alert
5)下拉框——Select标签下拉框、二次定位
3. UI层自动化测试的作用?发现什么BUG?
他就是功能测试,使用WebDriver真实的模拟了用户的操作过程。
4.有无发现selenium的BUG
5. 与人工测试相比,Selenium测试的产出,相对的优势?
6. 有没有封装过Selenium方法?
有,在BasePage层,我们就对实现一个页面的基本功能进行了封装。
例如:
1. 设置重试机制。
2. 对webdriver各种方法进行封装。
7. JUnit如何实现,它的功能是什么?什么时候使用?
一、Selenium基本认识
1. 什么是Selenium?
Selenium是浏览器自动化工具,主要用来Web的自动化测试,以及基于Web的任务管理自动化。它支持的语言有:python、Java、ruby、JavaScript等,并且几乎能在主流的浏览器上运行。
Selenium2.0、Selenium3.0主要由三大部分组成:SeleniumIDE、Selenium WebDriver、Selenoium Grid。
- Selenium IDE:录制和回放脚本,可以模拟用户对页面的真实操作,区别于其他工具:是通过拦截http请求。
- 一般只把录制脚本当作一个辅助功能,因为一个UI节点的细微变化,都可能导致自动化测试工具无法识别,当测试项目项目大时,定位、更新十分困难。
- 其次,录制的脚本有时候人工难以理解。
- Selenium Grid:实现在多台机器上、和异构环境中并行执行测试用例。并行执行不仅节省时间,而且可以同时在不同的浏览器、平台上运行自动化测试脚本。
- Selenium Web Driver:针对各个浏览器而开发,通过原生浏览器支持或者扩展(Chrome webDrive、FireFox WebDriver)直接控制浏览器
VS Selenium RC(Selenium1.0):在浏览器中运行javaScript,使用浏览器内置的JavaScript来翻译和执行selense
2. Selenium的特点有:
- 支持录制和回放(Selenium IDE)
- 通过WebDriver,直接控制浏览器,而不是通过拦截HTTP请求,实现真正模仿了用户的操作;同时使用WebDriver能够灵活的获取页面元素(WebDriver),并且提供执行JS的接口
- 能够分布式运行在不同机器和异构环境中(不同浏览器)
3. Selenium的内部运行机制?如何能够跨浏览器使用?——WebDriver原理(&RC原理)
1)RC原理
在Selenium1.0中,是通过Selenium RC服务器作为代理服务器去访问应用从而达到测试的目的。
Selenium RC分为三个部分,Launcher、HttpProxy、Core。
- Launcher用于启动浏览器,把Selenium Core加载到浏览器中,并且把浏览器的代理设置为Selenium Server的Http Proxy。
- Core是一堆JavaScript的集合,所以本质相当于运行这些JavaScript函数来实现对Html页面的操作。——这也是为什么可以运行在几乎所有主流的浏览器上。
然而直接运行JavaScript会有极大的安全漏洞,所以会受到“同源限制”,在这个基础上,Selenium2.0引入了WebDriver。
2)Web Driver原理
webDriver是按照client/server模式设计的。client是我们的测试脚本,发送请求;server就是打开的浏览器,用来接收client的请求并作出响应。
具体的工作流程:
- webDriver打开浏览器并绑定到指定端口。启动的浏览器作为远程服务器remote server
- client通过CommandExecuter发送http请求给远程服务器的侦听端口(the wire protocal)
- 远程服务器根据原生的浏览器组件来转化为浏览器的本地(native)调用
所以web Driver用到的协议:
- 打开浏览器时:HTTP协议
- client端发送http请求到远程服务器的侦听端口:the wire protocol
其中:
- 有线协议:指的是从点到点获取数据的方式,是应用层的协议。
- HTTP协议:是用于从服务器传输超文本标记语言HTML到客户端的通信协议。是一个应用层协议,由请求/响应构成,是一个标准的客户/服务器模式。是一个无状态的协议。(无状态:对事务没有记忆能力,不会保存这次传输的信息——节约内存)
4. 如何提高selenium脚本的执行速度?
1)优化测试用例。
- 尽可能不用sleep、减少使用implicityWait,而使用WebDriverWait/FluentWait,这样可以优化等待时间
- 减少不必要的操作步骤。
2)使用Selenium grid,通过testNG实现并发执行。
说到这里,在编写测试用例的时候,一定要实现松耦合,然后再服务器允许的情况下,尽量设置多线程实现并发运行。
3)设置等待时间、中断页面加载。如果页面加载内容太多,我们可以查看一下加载缓慢的原因,在不影响测试的情况下,可以设置超时时间,中断页面加载。
5. 提高自动化脚本稳定性
首先我们要分析出不稳定的原因,然后有针对的去解决。
1)页面加载内容太多。如果页面加载内容太多,在不影响测试的情况下,我们可以设置超时时间,中断页面加载。
2)网络原因。设置等待时间,如果在响应时间内没有加载成功,则重新执行测试。
3)优化代码,减少容易冲突的函数。
4)多线程运行时,测试用例间相互影响。在并发操作时,如果用例之间的耦合性没有设计好,就会有影响。
综上所述,我们就可以用线程的方式来监控测试进程的WEB加载执行状态。
- 在页面会发生跳转时,启动一个Thread来监控进程的状况。
- 在Thread的run方法中定义一个计时器。
- 如果计时器超时,则可以刷新页面,计时器清零;
- 若此时刷新页面再次超时,则关闭当前浏览器进程,fail掉这个测试用例,继续执行其他的测试用例。
6. 高质量自动化脚本特点
- 业务和代码分离,封装性好。
- 用例之间耦合性低,独立性强,易于扩展维护
7. 你觉得自动化测试最大的缺陷是什么?
1. 一旦项目发生变化,测试用例就需要改进,工作量大。
2. 验证的范围有限,操作更加复杂,比如说简单的一个验证验证码,如果是人工识别很快就可以输入,但是自动化测试中会增添很多困难。那么这个时候速度也不如人工。
3. 不稳定
4. 可靠性不强
5. 成本与收益
8. Selenium用JavaScript去操作页面元素会碰到什么问题?Selenium是如何解决这个问题的?
然而直接在浏览器中运行JavaScript会有很大的安全漏洞,所以就会受到“同源策略”的限制。也就是,当你去要运行一个脚本的时候,会进行同源检查,只有和被操控网页同源的脚本才能被运行。
Selenium1.0是通过采用代理模式来解决这个问题的。
- 首先测试脚本向Selenium Server发出Http请求建立,那么Selenium Server通过Launcher来启动服务器,将Core加载到浏览器页面中,并将浏览器代理设置为Http Proxy。
- 其次,测试脚本发送Http请求,Selenium Server对这个Http进行解析,然后通过代理服务器发送JS命令通知Core执行操作浏览器的动作,Core接受到指令后,执行操作。
- Selenium Server得到浏览器的Http的请求后,重组请求,获取对应的页面。
- 最后代理服务器将这个页面返回给浏览器。
在这个基础上,Selenium2.0是通过webDriver来时先跨平台的。WebDriver是针对各个浏览器来开发,是一个远程控制界面,提供了一组接口来发现和操作Web文档中的DOM元素并控制用户代理的行为。
二、自动化测试设计
1. 为什么想到做UI自动化测试?
在前期,我们也配合了开发人员使用JUnit框架进行单元测试,测试覆盖率从0提升到50%。
但是随着版本的稳定,我们开始考虑UI层是与客户交互最多的界面,如果要提高用户体验,必须从UI层入手。其次,大量并且重复的劳动力都集中在UI层,所以我们考虑到进行UI层自动化测试解放劳动力。
2. 如何设计Selenium的自动化测试脚本?
我们从以下几个方面来回答:
1. 自动化测试的内容?
2. 自动化测试用例设计的原则
3. 使用的框架/设计模式

3. PO设计模式,四层框架——数据、业务逻辑、测试脚本分离(关键字驱动)
2.1 PO设计模式:
将一个页面内的操作对象(按钮框、输入框等)和操作的步骤封装在每个Page里面,也Page为单位进行管理。这样Selenium测试用例能够通过调用页面类来获取页面元素,从而巧妙的避开了当页面元素的ID等属性发生变化时,修改代码的情况。——>提高了代码的复用性、可读性及减少工作量。
2.2 四层架构:
1. 基础层(BasePage)
设计一个基本的Page类,所有页面皆继承该类。提供了一个类需要实现的基本功能及公共方法。
2. 业务逻辑层(Pages):
按照PO设计模式,将每个页面抽象为一个类,放在Pages包里面,每个页面继承Basepage,可调用Data层数据,内容包括:
- 该页面所有的操作对象属性
- 实现的功能
3. 数据层(Data)
该层存放相关数据,例如:用户数据和密码。在业务逻辑层可通过调用数据层的数据来进行操作。
4. 测试层(Testcases)
每一个测试用例testcase都对应Pages里面的一个页面,继承unnitest.TestCase类。通过调用对应页面类的方法,增加断言(assert)来验证功能的正确性。其中每个测试用例都以test_开头。
此外通过Jenkins自动执行测试、代码质量检测和部署到测试服务器、部署到生产服务器上
4. 自动化测试执行策略
自动化测试用例的执行主要是通过Jenkins来实现的。而执行的策略是根据测试用例的类别、目的来设计的。
在Jenkins中,我们设定了三个任务:
- tm_test:用于执行自动化测试脚本,检测代码质量
- tm_staging_deploy:用于在测试服务器上部署代码
- tm_deploy:用于在生产服务器上部署
测试用例的目的分为三种情况:
1)用来监控。
在此目的下,我们就把自动化测试用例设置成定时执行的,如果每五分钟或是一个小时执行一次,在jenkins上创建一个定时任务即可。
2)必须回归的用例
当修复了新功能或者Bug以后,首先开发人员进行冒烟测试,如果通过了JUnit单元测试,交给测试人员进行功能测试。通过测试后,合并到master。
master一旦有变化,则触发tm_test任务,执行自动化测试脚本和代码质量检测。如果通过,则自动触发tm_staging_deploy,部署到staging服务器上,没有通过的话,自动化测试脚本会自动发送Bug截图给测试人员。
3)不需要经常执行的测试用例/生产服务器上的代码
有些非主要业务线的代码,或者生产服务器上的代码已经很稳定了,不需要时时回归,所以我们采用人工执行,在jenkins创建一个任务,需要执行的时候人工去构建即可。
三、Jenkins
Jenkins是持续集成的工具,能够自动执行测试和代码检测,以及部署到服务器上。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号