Openstack+Kubernetes+Docker微服务实践之路--服务发布
结合上文,我们的服务已经可以正常运行了,但它的访问方式只能通过服务器IP加上端口来访问,如何通过域名的方式来访问到我们服务,本来想使用Kubernetes的Ingress来做,折腾一天感觉比较麻烦,Ingress还得搭配Nginx使用,而且目前还是Beta版,就打算另辟蹊径,想到了之前用的Haproxy。
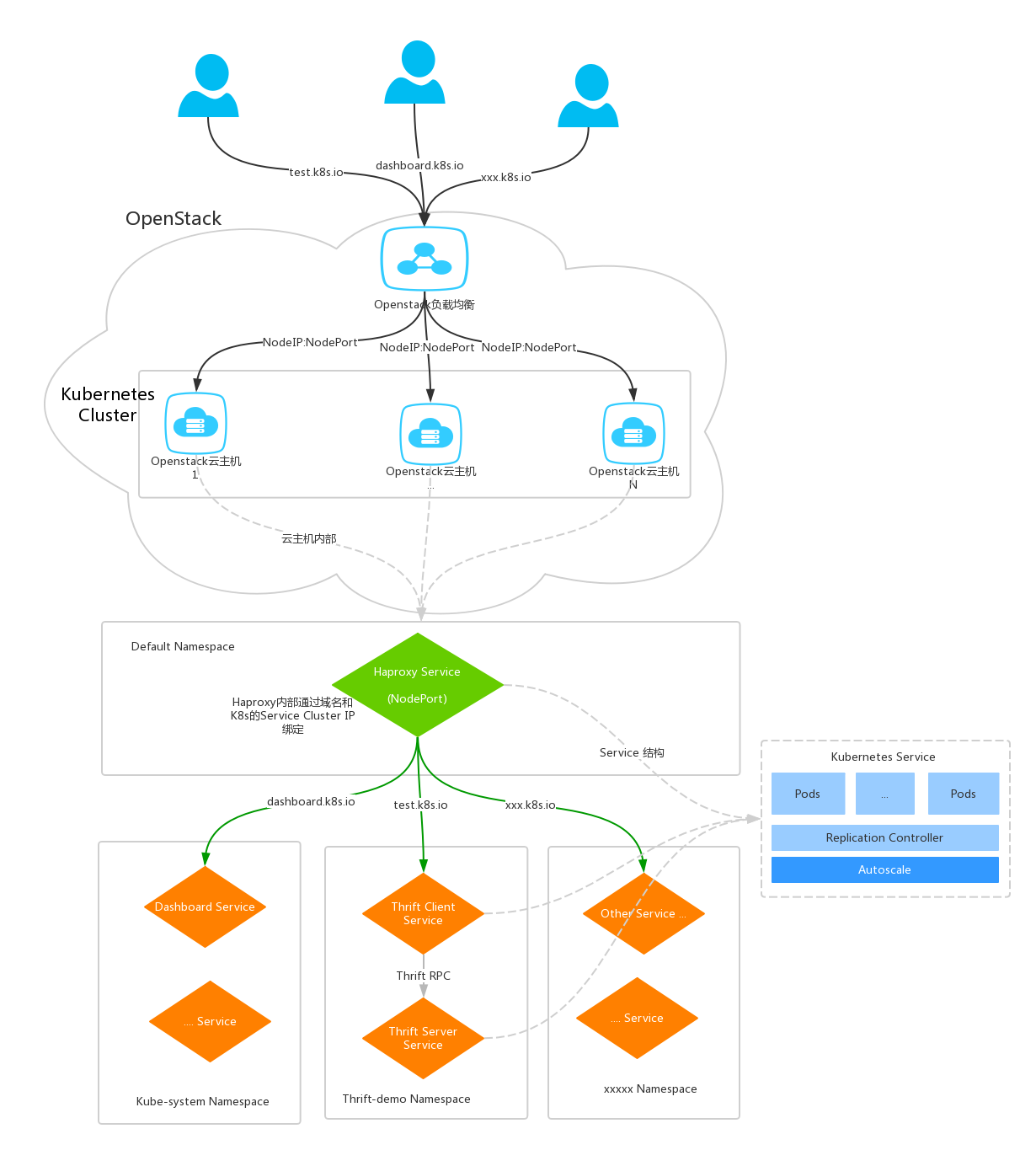
本文就结合OpenStack的负载和Haproxy来实现通过域名的方式访问K8s内部要发布的服务,用到的组件有OpenStack的负载均衡和Haproxy。
OpenStack负载配置到所有的K8s云主机上的一个端口,这个端口由Haproxy的K8s Service来监听,有请求过来时Haproxy根据不同的域名转发到对应的H8s Servie的Cluster IP。
整体拓扑图
具体的配置
OpenStack负载配置:
添加一个负载

注意它的IP地址,需要给它分配一个浮动IP,这样外部才能访问到

负载均衡池

30008 是Haproxy Service配置的NodePort
Haproxy配置
通过Kubernetes来运行Haproxy
haproxy-service.yml
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "haproxy-service"
},
"spec": {
"type": "NodePort",
"selector": {
"app": "haproxy"
},
"ports": [
{
"name": "proxy",
"protocol": "TCP",
"port": 80,
"nodePort": 30008,
"targetPort": 80
},
{
"name": "admin",
"protocol": "TCP",
"port": 8888,
"targetPort": 8888,
"nodePort": 30001
}
]
}
}
haproxy.cfg
global
maxconn 51200
chroot /usr/local/haproxy
uid 99
gid 99
daemon
nbproc 1
pidfile /var/run/haproxy-private.pid
defaults
mode http
option redispatch
option abortonclose
timeout connect 5000ms
timeout client 30000ms
timeout server 30000ms
log 127.0.0.1 local0 err
balance roundrobin
listen admin_stats
bind 0.0.0.0:8888
option httplog
stats refresh 30s
stats uri /stats
stats realm Haproxy Manager
stats auth admin:1
frontend thrift-app
bind *:80
option forwardfor
maxconn 1000
acl dashboard hdr(host) -i dashboard.k8s.io
acl scope hdr(host) -i scope.k8s.io
acl thrift_test hdr(host) -i test.k8s.io
use_backend dashboard_app if dashboard
use_backend scope_app if scope
use_backend thrift_app_1 if thrift_test
backend dashboard_app
balance roundrobin
option forwardfor
option httpclose
retries 3
server s1 10.12.48.203:80
backend scope_app
balance roundrobin
option forwardfor
option httpclose
retries 3
server s2 10.1.125.203:80
backend thrift_app_1
balance roundrobin
option forwardfor
option httpclose
retries 3
server s3 10.0.100.1:9091
需要注意的是backend的server后面的ip可以是集群服务的cluster ip也可以通过dns来访问,如thrift-c-app,如果是跨namespace需要完整的domain,如:
thrift-c-app.thrift-demo.svc.cluster.local:9091
Haproxy运行在K8s集群,所以不用担心haproxy的压力,可以随时扩容Pods来解决。这里有一个问题是如何把 haproxy.cfg 配置文件做成动态的,不用每次修改后还要生成Image重新启动服务,解决办法可以参考https://hub.docker.com/_/haproxy/ 的 Reloading config.
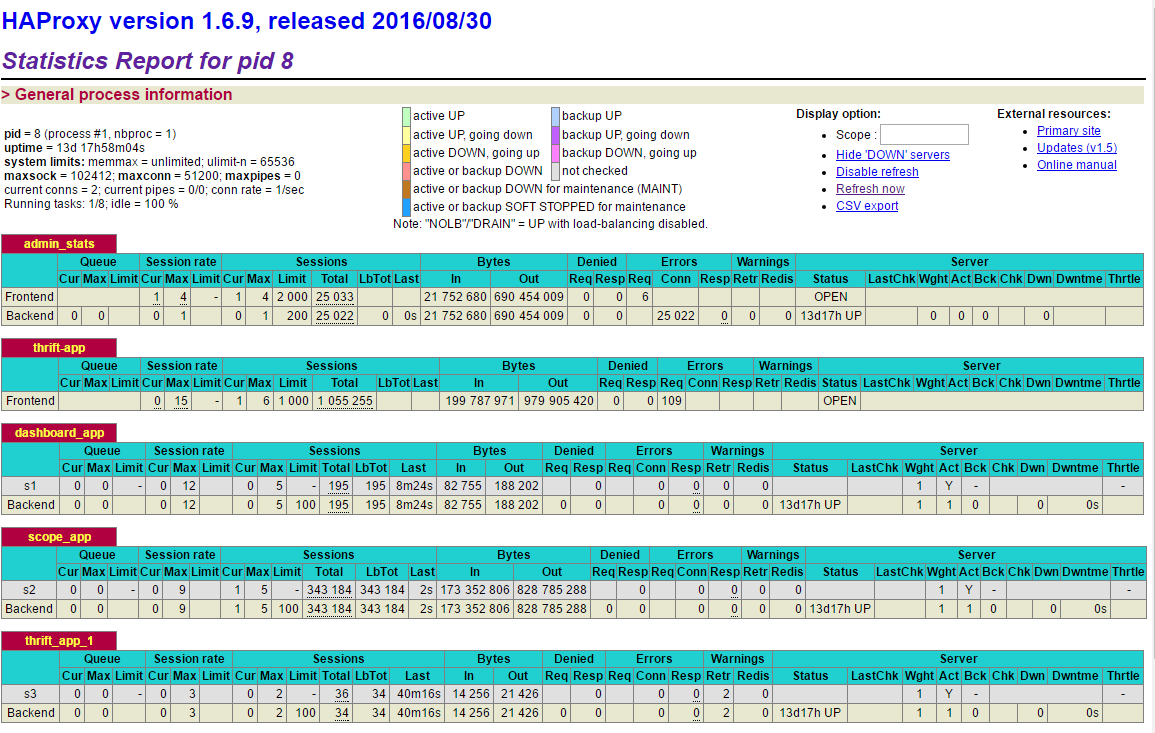
我们来看一下Haproxy的管理界面,访问http://192.196.1.160:30267/stats
测试
先配置本地的Hosts,将所有的域名都指向负载的浮动IP上
192.196.1.156 dashboard.k8s.io
192.196.1.156 scope.k8s.io
192.196.1.156 test.k8s.io
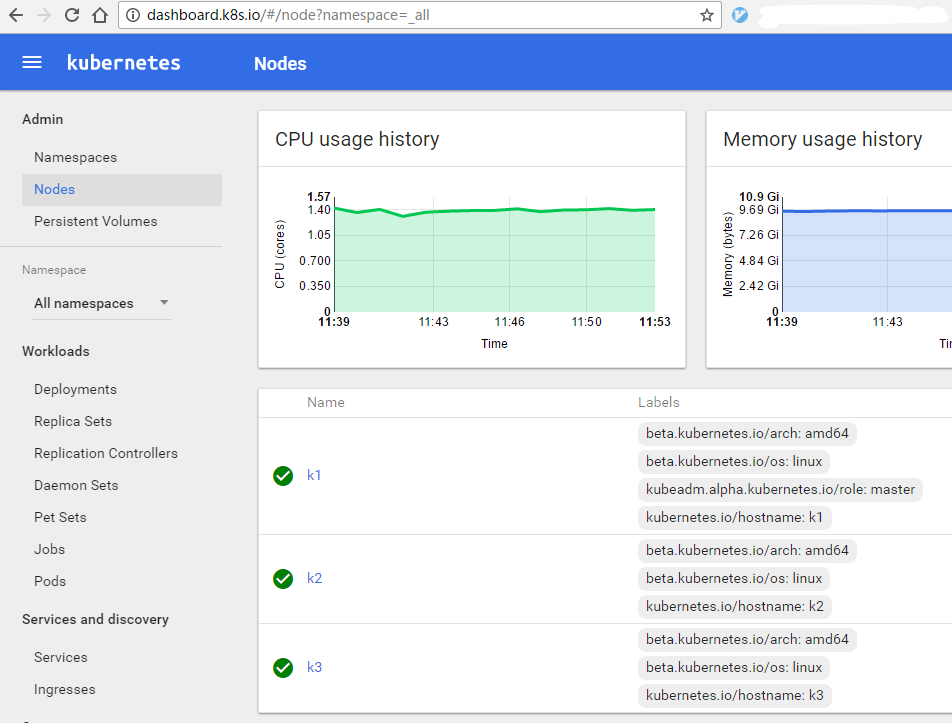
然后访问域名,如dashboard.k8s.io
还有我们的测试服务
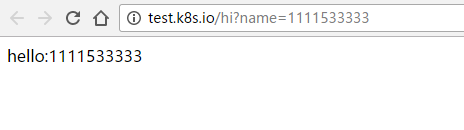
如预期一样,正常返回。这样所有要发布的WEB应用都通过一个端口来对外提供服务,所有集群里的云主机都可以做为负载资源,而且Haproxy本身可以扩容,目前来看不会有什么瓶颈而且用起来也比较顺手。
现在看起来一切都可以正常使用了,那还差什么呢? 想一想在并发压力大的情况下如何弹性扩容是个问题,这将在下文中讲解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号