分布式事务?咱先弄明白本地事务再说 - ACID
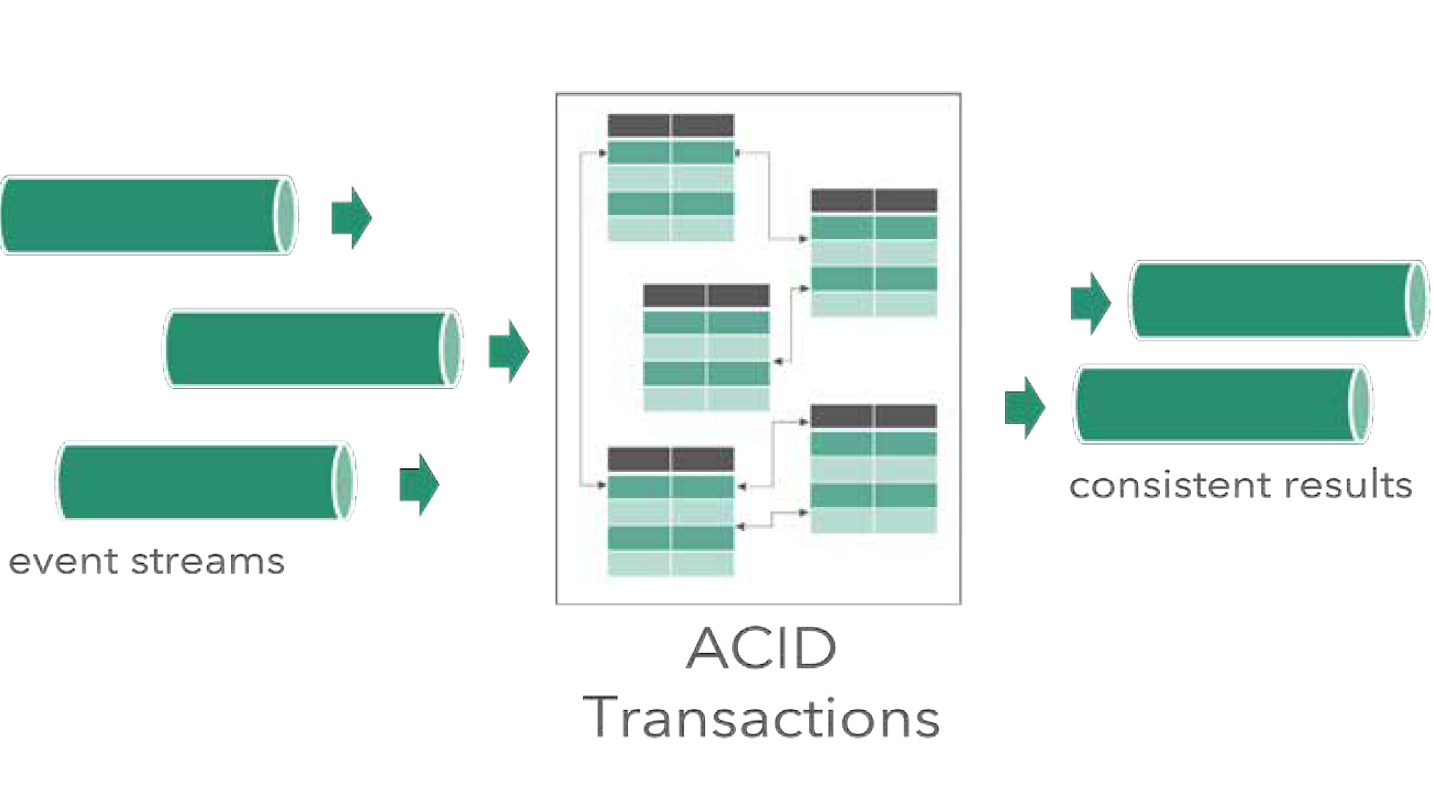
过去一段时间面试的同学,对于数据库事务,可以按照配置正常使用,但很多都无法讲清楚和理解数据库事务这个东西真正的意义,以及互联网兴起以后,当今数据库在ACID面前面临怎样的问题和抉择。
事务,是各大单机SQL数据库厂商包括Oracle、IBM DB2等,早在上世纪80年代提出的一个解决 数据并发操作处理的模型 ,旨在满足多用户(多线程、进程)对数据操作的场景下,依然能保证逻辑正确执行,状体持久,且各大厂商提出,并在事务实现上都遵循事务的 ACID 4个特性。
回顾ACID
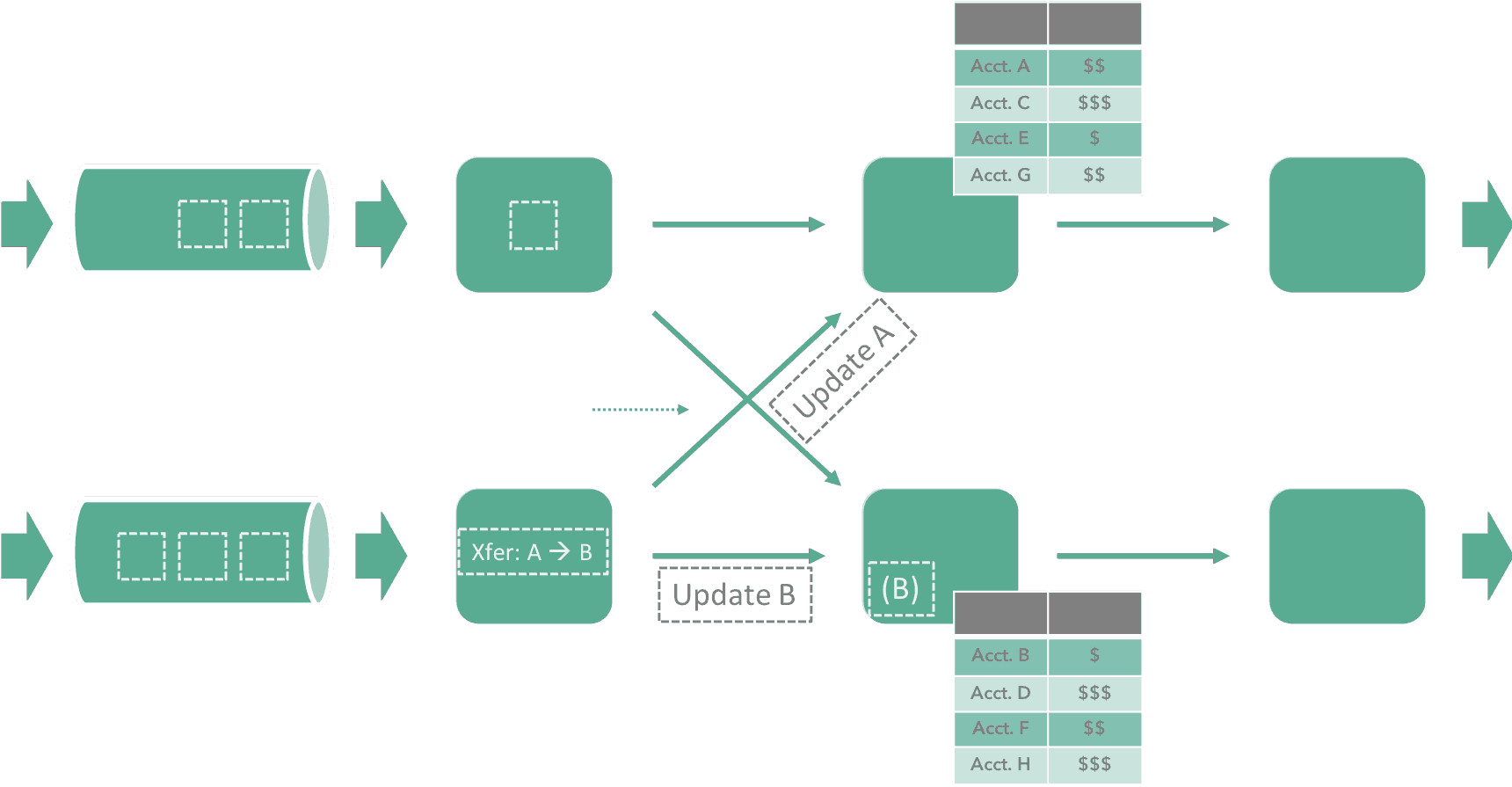
一个模块,是多个独立的功能逻辑的组合,每个功能包含多个操作步骤,包括IO、计算、数据库等操作,必须保证每一步都被执行,且执行正确,这个功能和模块才是可用,可交付的。

那么,如何保证这些操作的完整性,就是Atomic,定义为一个原子操作,全部执行且成功,或者全部失败都不执行(回滚),原子操作如果成功,那状态就必须持久,被称为数据库的Durability,持久性。
原子性A、持久性D,这俩个都比较好理解,定义了事务的边界,行为的开始和行为的结束。
A、D定义了事务的边界,那一致性C、隔离性I,就是对事务中间状态的管理,
一致性,也可以理解为是数据的完整性,数据的有效性,我们举例来说明什么是一致性,以及事务是如何保证一致性的,
- 一个账户减100,另一个账户加100的时候,程序异常crash了,这时候就出现数据的不一致情况,破坏了有效性,这个问题可以由Atomic来保证;
- 一个原子操作在执行的过程中,涉及多个数据变更的中间状态的保护,例如把A账户减100,在加到B账户完成这个原子操作之前,此时,其他线程对A读的操作就有可能获取到A少100的这个中间状态,这种情况是否允许发生,由Isolation来保证;
- 数据库延迟约束,例如数据字段的类型、空值、关系、数据范围、主键唯一性等这些合法性的检查都是由Durability来保证,在事务commit时,发现数据不合法,是无法提交成功的。
所以,综上所述,一致性C,是数据状态的正确变换的保证,AID,是实现C的手段,也是我们真正要追求的目标。
而,隔离性I的设定,就是对一致性C不同程度的破坏,事实上,如果我们顺序对数据进行读写,ACD是完全可用保证的,但这样效率会非常的低下,那,我们是要严格的一致性,还是更高的效率,数据库专家们把这个决定权交给了用户,所以,我们看到,ACID当中,只有隔离性I是用户可以选择的,可以自定义的。
隔离性包括 串行读、读已提交、重复读、读未提交 等几种策略,性能由低到高,让用户在不同的使用场景,选择合适的隔离策略,在一致性和性能之间平衡,取得最好的综合表现。
小结
本文主要介绍了事务和事务的几个特性,解释了ACID的由来和之间的关系,
总的来说,ACID的核心是C,大家其实都是为得到C而提出的不同纬度的限制和规范,A确定一个功能的完整性,D对状态负责,I可以说是C的等级系数,不同的I的策略,会出现不同的级别的C,AID是数据库本身的功能特性,C由业务层把控,要严格的C,就设置完整的数据库约束和串行隔离,反之,要宽松的C,就放开数据库的约束,使用读未提交的隔离策略,存在即合理,后者更适用于互联网高并发对一致性要求不高的场景,例如分布式的AP系统,可以保证服务整体的响应时间和服务的可用性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号