Zookeeper和Curator-Framework实践之:分布式消息队列
之前写过:
本文说的是ZK另一个重要使用场景,消息队列!
场景
一个典型的生产消费者模型,如下图:
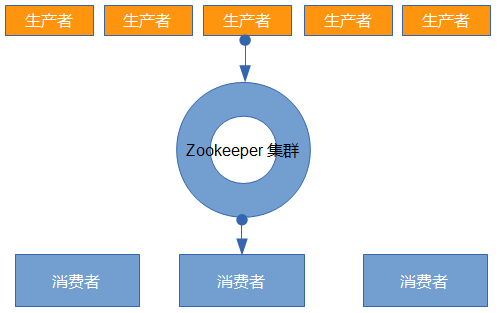
WEB点提交要处理的数据,注意是多结点的也就是多个生产者,数量可能比较大。在后台有个处理者也就是消费者,注意前后是分开的,生产者应用本身不做消费,而Curator提供的API好像默认是一起的,一个应用既是生产者又可以做消费。
配置
一切都基于前面的示例Zookeeper和Curator-Framework实践系列之: 配置管理,下面只说不一样的地方。
applicationContext.xml
同样与Zookeeper和Curator-Framework实践系列之: 配置管理相同,只需配置一下zookeeperFactoryBean的listeners增加或修改成DistributedQueueDemo
<bean id="zookeeperFactoryBean" class="cn.bg.zk.core.ZookeeperFactoryBean" lazy-init="false">
<property name="zkConnectionString" value="zookeepermaster:2181"/>
<property name="listeners">
<list>
<bean class="cn.bg.zk.queues.DistributedQueueDemo"></bean>
</list>
</property>
</bean>
添加一个bean,指定CuratorFramework,充当生产者时需用用它来添加数据到队列
<bean id="mainController" class="cn.bg.controller.MainController">
<constructor-arg ref="zookeeperFactoryBean" />
</bean>
代码
DistributedQueueDemo.java
分布式队列处理类
package cn.bg.zk.queues;
public class DistributedQueueDemo implements IZKListener{
//申明两个队列实例
private DistributedQueue<String> queue1 = null;
private DistributedQueue<String> queue2 = null;
//数据系列化转换工具类
private QueueSerializer<String> serializer = new QueueItemSerializer();
//消费者处理方法
private QueueConsumer<String> consumer = new QueueConsumer<String>() {
@Override
public void consumeMessage(String message) throws Exception {
//线程等待5秒,模拟数据处理,以达到数据抢夺的目的
Thread.sleep(5000);
//打印出是哪个线程处理了哪些数据
System.out.println(Thread.currentThread().getId() + " consume: " + message);
}
@Override
public void stateChanged(CuratorFramework client, ConnectionState newState) {
System.out.println("new state: " + newState);
}
};
//Spring启动时调用此方法以启动所有队列实例
@Override
public void executor(CuratorFramework client) {
//实例化所有队列,指定ZK队列数据获取地址,和其它参数
//由于它们的地址是相同的,都是*/zk_queue_test*,所以Curator会根据它们的空闲状态来分配新的任务,上面通过线程暂停5秒来拉开它们的处理间隔。
queue1 = QueueBuilder.builder(client, consumer, serializer, "/zk_queue_test").buildQueue();
queue2 = QueueBuilder.builder(client, consumer, serializer, "/zk_queue_test").buildQueue();
try {
//启动所有队列实例,让它们开始工作,注意所有指定的动作只有在调用了queue1.start()方法之后才会被执行,比如queue.put()等。
//Curator提供了queue.put()方法来往队列里添加数据,但它同时也会处理,但我们不想这样,所以添加的过程我们通过其它的方式来实现。
queue1.start();
queue2.start();
System.out.println("Queues started!");
} catch (Exception e) {
}
}
}
QueueSerializer.java
数据系列化处理工具类
package cn.bg.zk.queues;
public class QueueItemSerializer implements QueueSerializer<String>
{
@Override
public byte[] serialize(String item)
{
return item.getBytes();
}
@Override
public String deserialize(byte[] bytes)
{
return new String(new String(bytes));
}
}
上面的是消息队列处理的部分,下面开始消息添加,也就是生产者部分:
生产者是一个Controller,也就是通过用户提交数据来做为生产者
MainController.java
package cn.bg.controller;
@Controller
public class MainController {
private final CuratorFramework zkClient;
//通过Spring注入CuratorFramework实例
public MainController(final CuratorFramework zkClient) {
Assert.notNull(zkClient, "zkClient cannot be null");
this.zkClient = zkClient;
}
//简单的使用传递值来做数据处理的实体
@RequestMapping("/put/{val}")
@ResponseBody
public String put(@PathVariable String val) throws Exception {
//需要使用特定的格式来添加数据到队列,使用ItemSerializer来做格式化生成byte。
byte[] bytes = ItemSerializer.serialize(val, new QueueItemSerializer());
String path = "" ;
//创建znode并添加数据
path = zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath("/zk_queue_test/queue-");
zkClient.setData().forPath(path, bytes);
return path;
}
}
ItemSerializer.java
这个类是格式化数据,也就是设置一些znode的属性,并生成byte
此类来自Curator源码的简化版,主要目的是分离Curator Queue来添加队列数据用到。
package cn.bg.zk.queues;
public class ItemSerializer {
private static final int VERSION = 0x00010001;
private static final byte ITEM_OPCODE = 0x01;
private static final byte EOF_OPCODE = 0x02;
private static final int INITIAL_BUFFER_SIZE = 0x1000;
public static <T> byte[] serialize(T item, QueueSerializer<T> serializer) throws Exception {
ByteArrayOutputStream bytes = new ByteArrayOutputStream(INITIAL_BUFFER_SIZE);
DataOutputStream out = new DataOutputStream(bytes);
out.writeInt(VERSION);
byte[] itemBytes = serializer.serialize(item);
out.writeByte(ITEM_OPCODE);
out.writeInt(itemBytes.length);
if (itemBytes.length > 0) {
out.write(itemBytes);
}
out.writeByte(EOF_OPCODE);
out.close();
return bytes.toByteArray();
}
}
运行
启动应用后所有队列都已处理待命状态,理论上只要在ZK目录/zk_queue_test/添加数据就会被处理掉,只是它有固定的添加格式。
通过访问/put/{?}等这样路径数据{?}就会被添加到队列并处理,所以可以刷多条数据到队列来观察队列的处理状态,基本的输出应该是这样的:
17 consume: 111
18 consume: 222
17 consume: 111
18 consume: 222
17 consume: 111
17 consume: 111
整个过程基本完成,经测试运行状态良好,Curator自己维护与ZK集群的连接,本人通过JMX将应用与ZK的连接强制断开后Curator主动识别并重新连接,基本不用担心一些基础问题上处理,可以专心解决我们的业务需要。


