国内网站域名备案信息查询平台 All In One
国内网站域名备案信息查询平台 All In One
网站备案查询 / 域名备案查询
公安机关互联网站安全管理服务平台
联网备案信息
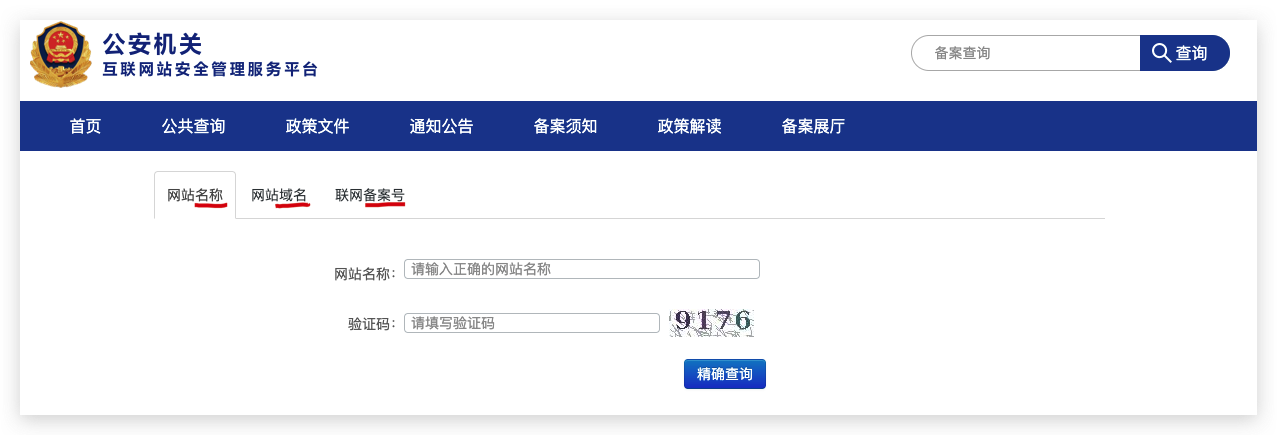
https://www.beian.gov.cn/portal/recordQuery
ICP/IP地址/域名信息备案管理系统
中华人民共和国工业和信息化部 / 工信部
https://beian.miit.gov.cn/#/Integrated/recordQuery
全国咨询电话: 010-66411166
demos
镀金的天空-GlidedSky
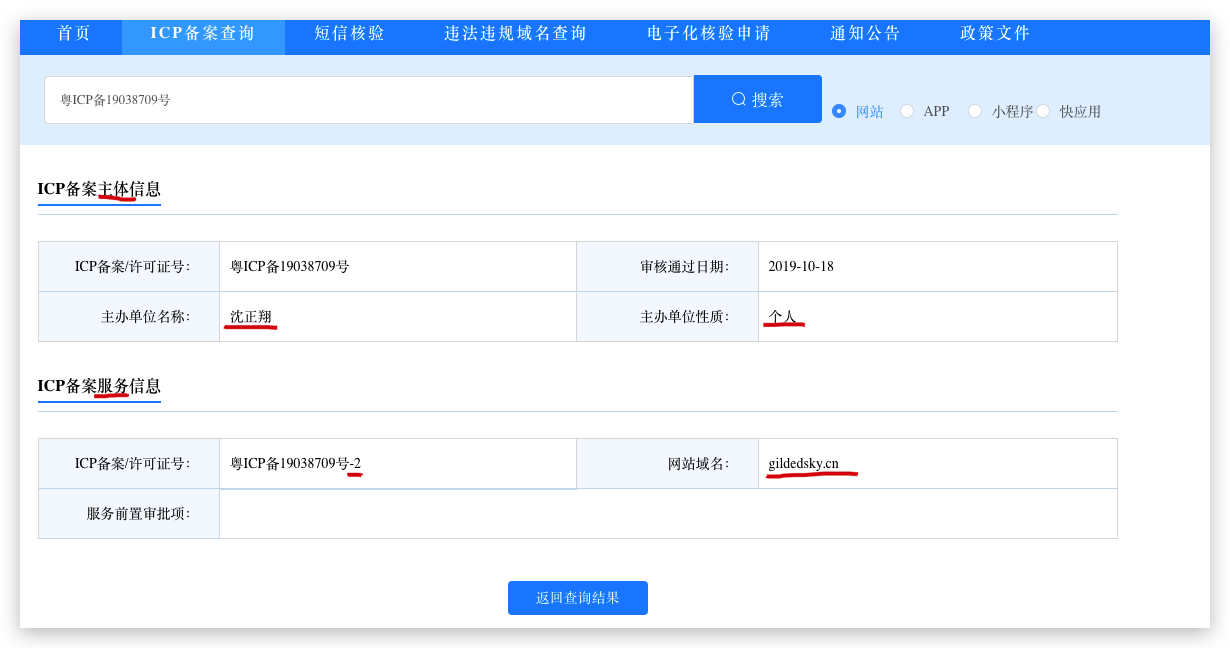
粤ICP备19038709号
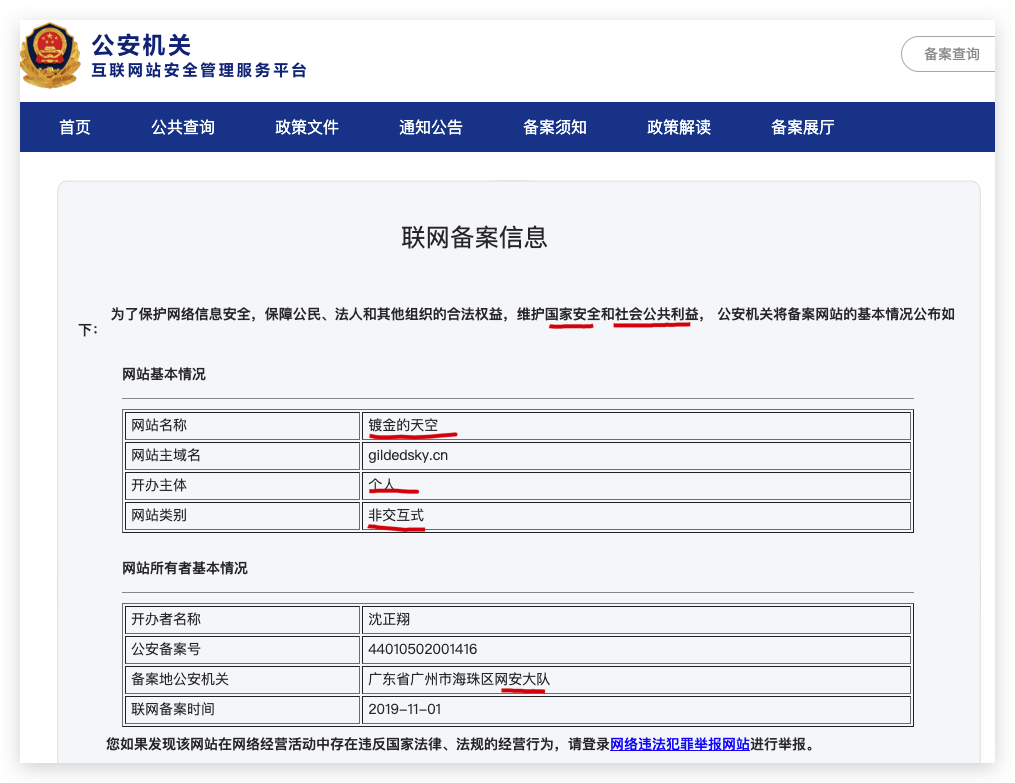
https://www.beian.gov.cn/portal/registerSystemInfo
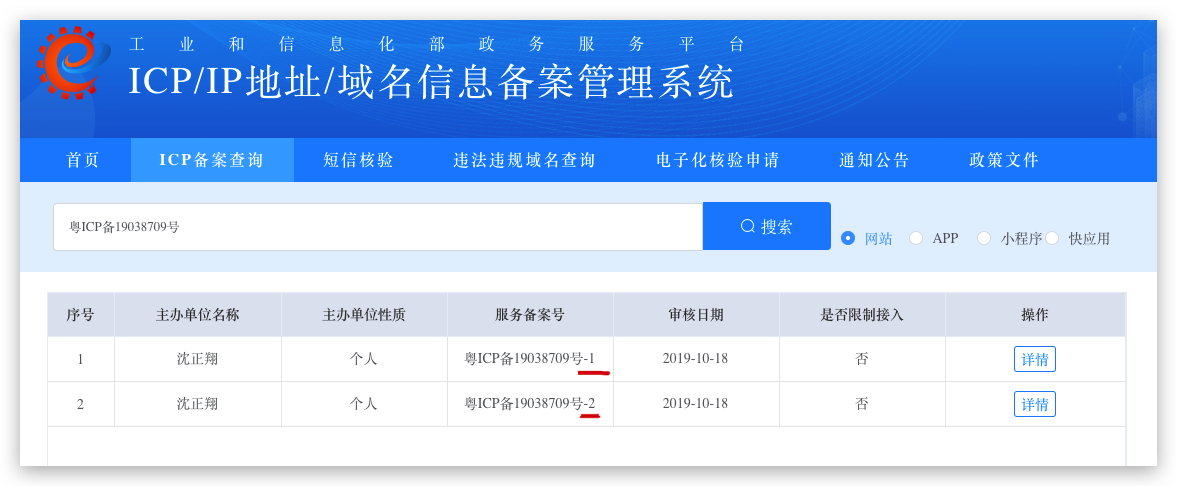
| 序号 | 主办单位名称 | 主办单位性质 | 服务备案号 | 审核日期 | 是否限制接入 | 操作 |
|---|---|---|---|---|---|---|
| 1 | 沈正翔 | 个人 | 粤ICP备19038709号-1 | 2019-10-18 | 否 | 详情 |
| 2 | 沈正翔 | 个人 | 粤ICP备19038709号-2 | 2019-10-18 | 否 | 详情 |
https://beian.miit.gov.cn/#/Integrated/recordQuery
Python 爬虫测试网站
http://www.glidedsky.com/level/web/crawler-basic-1
#!/usr/bin/env python3
import requests
from bs4 import BeautifulSoup
def crawler(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36"
}
# Cookie
# _gid=GA1.2.954003430.1695806925; Hm_lvt_020fbaad6104bcddd1db12d6b78812f6=1695806925; Hm_lpvt_020fbaad6104bcddd1db12d6b78812f6=1695808472; footprints=eyJpdiI6IlFOTzV5SnY2amxMbmRJSEpxMW4xN1E9PSIsInZhbHVlIjoiMWZKZUZBeFpycElra1ljcE4zYWMwK2tTdXZtb0JvWDM3c3EyZ0lRbVM0Nm5SYndkRjZPeWRcLzRUXC84VkFcL1ZkMyIsIm1hYyI6ImU3YmVmNWExODYwNTA5NWFhM2E4MWE0YmNlN2ZmNWIxOTFjZDkzMTYwN2FhYmQyODUyNTdjYTMwZGVmNjgwMDYifQ%3D%3D; _ga=GA1.1.330116705.1695805515; remember_web_59ba36addc2b2f9401580f014c7f58ea4e30989d=eyJpdiI6IkFMc2RjTndENENFcFBKcVREYnh2Wmc9PSIsInZhbHVlIjoiT2JHY0xaZ2hpZlhlRzFrMGx1a3ZOVDlhekdlM21MZWRpR3ZtRldTUXRyTDFrTWQrTmpPYXArR1JpVlZHV0FtYW96MmVTcWp6V0ZORE9oSkgxRTIzZGVaRVduMnFQOGN6eExuMGwzVVM4a3dNRkcyam9Ldm0wcHFHR0l3YkJud0NTa1YrWFJkeWRhbWEzUWVzR2s4NU1NdHNOY2c1ZEFiSG05QTcwdGtUd1NvPSIsIm1hYyI6IjU1Mjc1ZjgyMzY2NGM3OTQ4YWQyNDYyODVlYjUxN2FmOTYzNDUyNTE3OGVjNmVhY2U2YTE4MDJmZDBhZmZiNDkifQ%3D%3D; _ga_YF6WY50PGC=GS1.1.1695817454.3.1.1695818822.0.0.0; XSRF-TOKEN=eyJpdiI6IlwvMEFrR0ptbVlob3JcL0RHakxKY0JlQT09IiwidmFsdWUiOiJLWSswSXFXNklJYTAwb3hBaERHZ2RvYVh4eWUzSzhZcE1hNDV0OTlWdVM3RHFYNTVqMTJYSWpQZ3Nmdk1DSStYIiwibWFjIjoiMTliNmNhZWI1YTUwOTM1MTJhZmEyYjkyMDMwMGNkYTE3YzY1NzU1NWU4YjY1ODAxMmI2MDg5NGY3NjI1MTNkMiJ9; glidedsky_session=eyJpdiI6IlwvKyswb2RsRmN4VEw4R0pLeGxUWXZ3PT0iLCJ2YWx1ZSI6ImhuQVhYK0RIVHNhR3NhRmxmZnVkMWdybTZYUWJFWnNwS1RMcDkrUnYrR29rQm9cL1RObmM0TnB5cmV1YlRpUlF2IiwibWFjIjoiMDcyMDY3ZmJjODlkZDUwNTE0OWY1OGI0ODRkNmY5MDdiMGYwN2RlMDY4MDk2NThlOTg1OGY2NDk2NTRkZjM0ZCJ9
cookies = {
"_gid": "GA1.2.954003430.1695806925",
"_ga": "GA1.1.330116705.1695805515",
"Hm_lvt_020fbaad6104bcddd1db12d6b78812f6": "1695806925",
"Hm_lpvt_020fbaad6104bcddd1db12d6b78812f6": "1695808472",
"XSRF-TOKEN": "eyJpdiI6IktiRDlVYXl1TmFuYXF0aUtNWkF4Y3c9PSIsInZhbHVlIjoiU0srYzhyM3p3S0dnQ1NTdmYzMUNST3JlblRtYmNrU0NhVkpxXC9sKzBmcFVpdG9kQSsyaVRjK1FxVDFYZTlpRmIiLCJtYWMiOiJlNzhkNWRkNzU0NjUxMmYxZTRmYjA2MGZjMmE0NTdmOGE1YjliNGQ0MDFkOTVkYTM0NmZiNTFkZmJkMzM0YmRkIn0%3D",
"glidedsky_session": "eyJpdiI6IlwvKyswb2RsRmN4VEw4R0pLeGxUWXZ3PT0iLCJ2YWx1ZSI6ImhuQVhYK0RIVHNhR3NhRmxmZnVkMWdybTZYUWJFWnNwS1RMcDkrUnYrR29rQm9cL1RObmM0TnB5cmV1YlRpUlF2IiwibWFjIjoiMDcyMDY3ZmJjODlkZDUwNTE0OWY1OGI0ODRkNmY5MDdiMGYwN2RlMDY4MDk2NThlOTg1OGY2NDk2NTRkZjM0ZCJ9",
"footprints": "eyJpdiI6IlFOTzV5SnY2amxMbmRJSEpxMW4xN1E9PSIsInZhbHVlIjoiMWZKZUZBeFpycElra1ljcE4zYWMwK2tTdXZtb0JvWDM3c3EyZ0lRbVM0Nm5SYndkRjZPeWRcLzRUXC84VkFcL1ZkMyIsIm1hYyI6ImU3YmVmNWExODYwNTA5NWFhM2E4MWE0YmNlN2ZmNWIxOTFjZDkzMTYwN2FhYmQyODUyNTdjYTMwZGVmNjgwMDYifQ%3D%3D"
}
# res.cookies <RequestsCookieJar[<Cookie XSRF-TOKEN=eyJpdiI6IlR5cFcrNVFoVndWeU51dnpFa2NMM1E9PSIsInZhbHVlIjoidUt2M2xSNXFuSG9oY0xNNHN4aXJNVENPQVdUSDZpT2lIYnJDVjdRSGhpR3VMOFJYNHVmK1htazhIS3pWRDViWiIsIm1hYyI6ImVkMTg3MTMzNzFhOWE4OTYwMmVjNzA5Mjk3YmM5NmJlMGFkMjRhZTYxNjQ3OTg4N2Y2ZTQwMTA5MjMyZWQ3NDkifQ%3D%3D for www.glidedsky.com/>, <Cookie footprints=eyJpdiI6IkNQdmNYWG00QU9FMWZPZVRoZWVCd1E9PSIsInZhbHVlIjoiVWJZcjBYbWhqZkRxVHlyS3BEQmVqZ0lDQ2xuYnZPQ2ZUYjZZNDdtNjNBTlZ3TDhlMmFETURIRlJ0N0d1MTBVaiIsIm1hYyI6IjhmMGE4OGU0YmQxMWU0MjhmMWIyYmRmNWZiYzAxYTMzZTg3ZDY5NDc0ZjFkMDFjNjQ0YjVjOTI1NTQwZGMzYjIifQ%3D%3D for www.glidedsky.com/>, <Cookie glidedsky_session=eyJpdiI6IlJ4RU5sMEptSUhRbFdyZXA2b0x6Vmc9PSIsInZhbHVlIjoiWEF5Vm1Hb1I1MTBQRjRwUVYraU0wUHk0aVFsK3U5SXd6dHp4SEpjdFZDc3NDNkwwYWtzcFo0aGJsK3FUVXhwdCIsIm1hYyI6IjhlMzBiMGEyODQ4MmFmMGQyNjZiMGRiMGNkZDQ4YzMxODFlMzU3NmJkYjk0NWFkMTlmNWIwYjc2NmNkOWM4NTcifQ%3D%3D for www.glidedsky.com/>]>
# '_gid=; Hm_lvt_020fbaad6104bcddd1db12d6b78812f6=1695806925; Hm_lpvt_020fbaad6104bcddd1db12d6b78812f6=1695808472; _ga=GA1.1.330116705.1695805515; _ga_YF6WY50PGC=GS1.1.1695817454.3.1.1695818822.0.0.0; XSRF-TOKEN=eyJpdiI6IktiRDlVYXl1TmFuYXF0aUtNWkF4Y3c9PSIsInZhbHVlIjoiU0srYzhyM3p3S0dnQ1NTdmYzMUNST3JlblRtYmNrU0NhVkpxXC9sKzBmcFVpdG9kQSsyaVRjK1FxVDFYZTlpRmIiLCJtYWMiOiJlNzhkNWRkNzU0NjUxMmYxZTRmYjA2MGZjMmE0NTdmOGE1YjliNGQ0MDFkOTVkYTM0NmZiNTFkZmJkMzM0YmRkIn0%3D'
res = requests.get(url, auth=('noreply@gqfrms.xyz', '1234567'))
# res = requests.get(url, headers=headers, cookies=cookies)
print('res.cookies', res.cookies)
print('res.text', res.text)
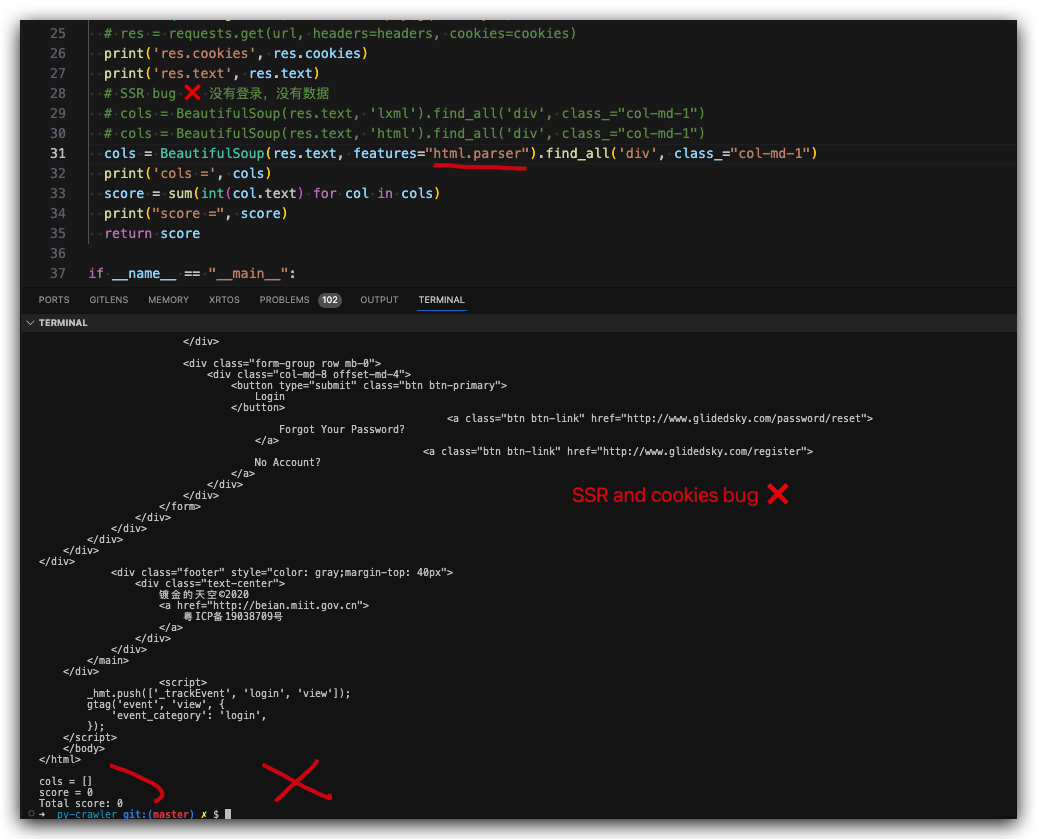
# SSR bug ❌ 没有登录,没有数据
# ??? html / xml
# cols = BeautifulSoup(res.text, 'lxml').find_all('div', class_="col-md-1")
# cols = BeautifulSoup(res.text, 'xml').find_all('div', class_="col-md-1")
# cols = BeautifulSoup(res.text, 'html').find_all('div', class_="col-md-1")
cols = BeautifulSoup(res.text, features="html.parser").find_all('div', class_="col-md-1")
print('cols =', cols)
score = sum(int(col.text) for col in cols)
print("score =", score)
return score
if __name__ == "__main__":
url = f'http://www.glidedsky.com/level/web/crawler-basic-1'
score = crawler(url)
print(f'Total score: {score}')
# if __name__ == "__main__":
# base_url = f'http://www.glidedsky.com/level/web/crawler-basic-1?page='
# total_score = 0
# for page in range(1, 11):
# url = base_url + str(page)
# score = crawler(url)
# total_score += score
# print(f'Page {page}: {score}')
# print(f'Total score: {total_score}')
"""
$ pip3 install beautifulsoup4
https://pypi.org/project/beautifulsoup4/
https://scrapeops.io/python-web-scraping-playbook/installing-beautifulsoup/
"""
(🐞 反爬虫测试!打击盗版⚠️)如果你看到这个信息, 说明这是一篇剽窃的文章,请访问 https://www.cnblogs.com/xgqfrms/ 查看原创文章!
beautifulsoup4 / bs4
Beautiful Soupis a library that makes it easy to scrape information from web pages.
It sits atop anHTMLorXMLparser, providing Pythonic idioms for iterating, searching, and modifying the parse tree.
$ pip3 install beautifulsoup4
https://pypi.org/project/beautifulsoup4/
https://scrapeops.io/python-web-scraping-playbook/installing-beautifulsoup/
requests
cookies
$ pip3 install requests
https://pypi.org/project/requests/
requests.request(method, url, **kwargs)
# Lower-Level Classes
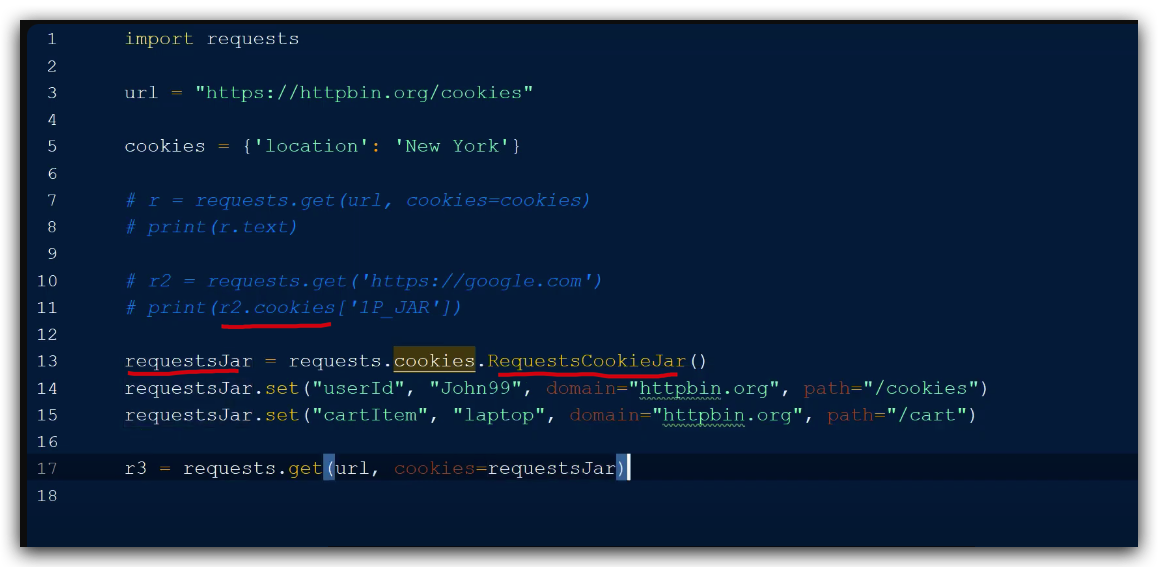
class requests.Request(method=None, url=None, headers=None, files=None, data=None, params=None, auth=None, cookies=None, hooks=None, json=None)[source]
cookies – (optional) Dict or CookieJar object to send with the Request.

https://requests.readthedocs.io/en/latest/api/#requests.Request
import requests
req = requests.Request('GET', 'https://xgqfrms.xyz/api/get')
req.prepare()
#!/usr/bin/env python3
import requests
from bs4 import BeautifulSoup
res = requests.get(url, auth=('noreply@gqfrms.xyz', '1234567'))
# res = requests.get(url, headers=headers, cookies=cookies)
# res = requests.Request('GET', url, auth=('noreply@gqfrms.xyz', '1234567'), headers=headers, cookies=cookies)
res = requests.get(url, auth=('noreply@gqfrms.xyz', '1234567'))
# res = requests.get(url, headers=headers, cookies=cookies)
print('res.cookies', res.cookies)
print('res.text', res.text)
# ❌ AttributeError: 'Request' object has no attribute 'text'
https://requests.readthedocs.io/en/latest/api/#cookies
https://github.com/psf/requests#requests
errors
bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?
# LXML parser
$ pip3 install lxml
lxml is a Pythonic, mature binding for the libxml2 and libxslt libraries.
It provides safe and convenient access to these libraries using the ElementTree API.
https://pypi.org/project/lxml/
cookies
CookieJarobject
https://www.youtube.com/watch?v=Km28G1Sl1fY
regexp
js regexp replace
\t
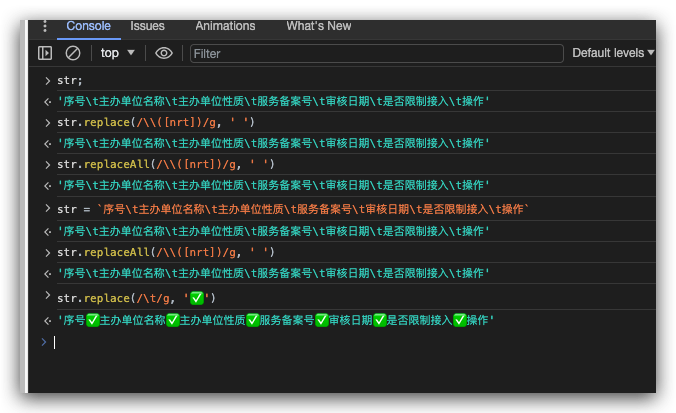
str = `序号\t主办单位名称\t主办单位性质\t服务备案号\t审核日期\t是否限制接入\t操作`;
str.replace(/\\([nrt])/g, ' ')
'序号\t主办单位名称\t主办单位性质\t服务备案号\t审核日期\t是否限制接入\t操作'
str.replaceAll(/([\\t])/g, ' ')
'序号\t主办单位名称\t主办单位性质\t服务备案号\t审核日期\t是否限制接入\t操作'
str = `序号\t主办单位名称\t主办单位性质\t服务备案号\t审核日期\t是否限制接入\t操作`;
str.replace(/\t/g, '✅')
'序号✅主办单位名称✅主办单位性质✅服务备案号✅审核日期✅是否限制接入✅操作'
str.replaceAll(/([\t])/g, '❌')
'序号❌主办单位名称❌主办单位性质❌服务备案号❌审核日期❌是否限制接入❌操作'
str.replaceAll(/(\t)/g, ' ')
'序号 主办单位名称 主办单位性质 服务备案号 审核日期 是否限制接入 操作'
- group
() - flag
g
https://stackoverflow.com/questions/9018015/remove-tab-t-from-string-javascript
\\n=>\n
const dict = {'n': '\n', 't': '\t', 'r': '\r'};
let str = `value1\\rvalue2\\tvalue3\\nvalue4`;
str = str.replace(/\\([nrt])/g, macth => dict[macth[1]]);
console.log(`str`, str);
/**/
JSON.stringify(str)
'"value1\\rvalue2\\tvalue3\\nvalue4"'
refs
©xgqfrms 2012-2021
www.cnblogs.com/xgqfrms 发布文章使用:只允许注册用户才可以访问!
原创文章,版权所有©️xgqfrms, 禁止转载 🈲️,侵权必究⚠️!
本文首发于博客园,作者:xgqfrms,原文链接:https://www.cnblogs.com/xgqfrms/p/17734681.html
未经授权禁止转载,违者必究!

