Linux shell command cut All In One
Linux shell command cut All In One
cut截取指定符号后面的字符串
cut 截取等号后面的字符串
# 获取 env
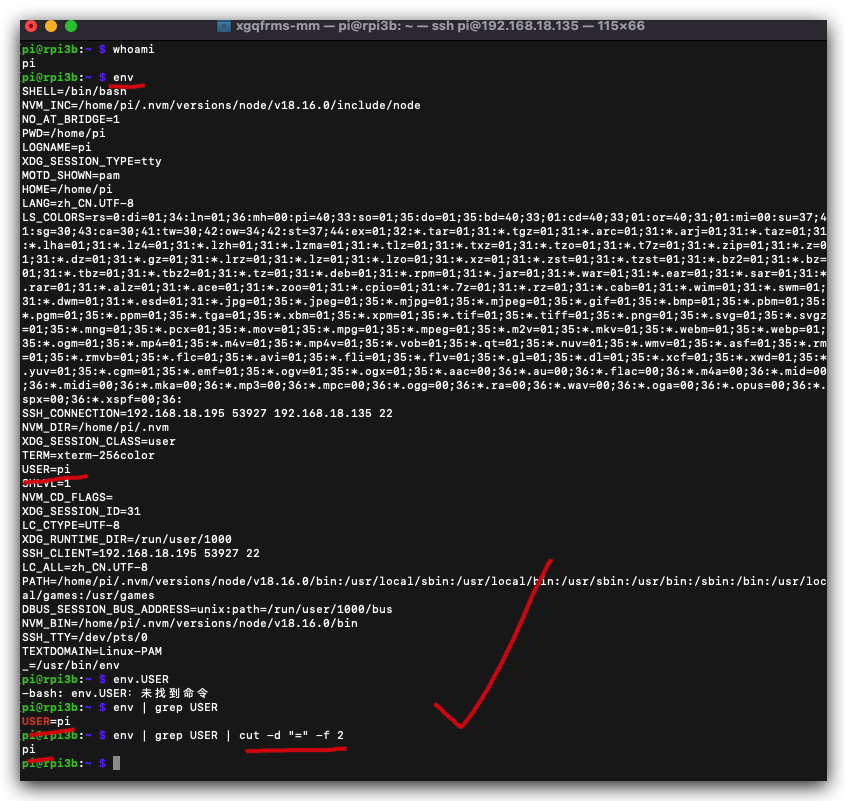
$ env
# 获取登录当前用户信息
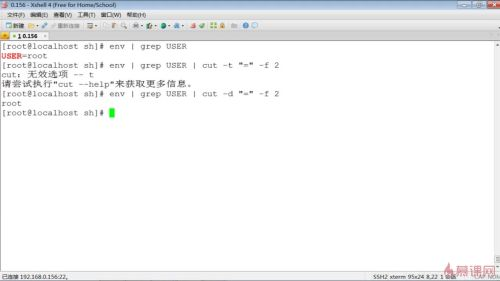
$ env | grep USER
$ env | grep USER | cut -d "=" -f 2
$ man cut
$ man cut > ./man-docs/cut.md
$ cat ./man-docs/cut.md
$ cat ./man-docs/cut.md
CUT(1) User Commands CUT(1)
NAME
cut - remove sections from each line of files
SYNOPSIS
cut OPTION... [FILE]...
DESCRIPTION
Print selected parts of lines from each FILE to standard output.
With no FILE, or when FILE is -, read standard input.
Mandatory arguments to long options are mandatory for short options too.
-b, --bytes=LIST
select only these bytes
-c, --characters=LIST
select only these characters
-d, --delimiter=DELIM # 分隔符 ✅
use DELIM instead of TAB for field delimiter
-f, --fields=LIST # 字段 ✅
select only these fields; also print any line that contains no delimiter character, unless the -s
option is specified
-n (ignored)
--complement
complement the set of selected bytes, characters or fields
-s, --only-delimited
do not print lines not containing delimiters
--output-delimiter=STRING
use STRING as the output delimiter the default is to use the input delimiter
-z, --zero-terminated
line delimiter is NUL, not newline
--help display this help and exit
--version
output version information and exit
Use one, and only one of -b, -c or -f. Each LIST is made up of one range, or many ranges separated by
commas. Selected input is written in the same order that it is read, and is written exactly once. Each
range is one of:
N N'th byte, character or field, counted from 1
N- from N'th byte, character or field, to end of line
N-M from N'th to M'th (included) byte, character or field
-M from first to M'th (included) byte, character or field
AUTHOR
Written by David M. Ihnat, David MacKenzie, and Jim Meyering.
REPORTING BUGS
GNU coreutils online help: <https://www.gnu.org/software/coreutils/>
Report any translation bugs to <https://translationproject.org/team/>
COPYRIGHT
Copyright © 2020 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later
<https://gnu.org/licenses/gpl.html>.
This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent
permitted by law.
SEE ALSO
Full documentation <https://www.gnu.org/software/coreutils/cut>
or available locally via: info '(coreutils) cut invocation'
GNU coreutils 8.32 September 2020 CUT(1)
user
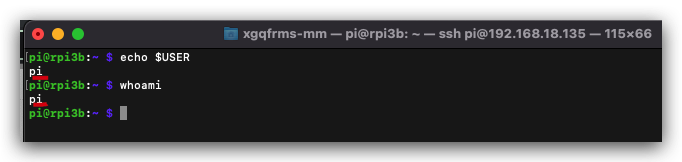
# 获取登录当前用户信息
$ whomai
$ echo $USER
demos
#!/usr/bin/env bash
# coding: utf8
bug='throttled=0x50005'
state=$(vcgencmd get_throttled)
# echo $state
# 没有空格 bug ❌
# if [$state == $bug]
# 有空格 OK ✅
# if [ $state == $bug ]
# 有空格 OK ✅
if [ $state == 'throttled=0x50005' ]
then
echo "❌ Error"
else
echo "✅ OK"
fi
WIFI=$(ifconfig | grep "192.168")
echo $WIFI
(🐞 反爬虫测试!打击盗版⚠️)如果你看到这个信息, 说明这是一篇剽窃的文章,请访问 https://www.cnblogs.com/xgqfrms/ 查看原创文章!
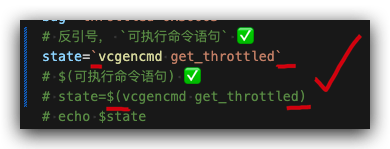
shell script 中写可执行命令的语句方法
- 反引号,
可执行命令语句 - 美元符号 + 小括号,
$(可执行命令语句)
#!/usr/bin/env bash
# coding: utf8
bug='throttled=0x50005'
# $(可执行命令语句) ✅
# state=$(vcgencmd get_throttled)
# echo $state
# 有空格 OK ✅
# if [ $state == $bug ]
# 有空格 OK ✅
if [ $state == 'throttled=0x50005' ]
then
echo "❌ Error"
else
echo "✅ OK"
fi
#!/usr/bin/env bash
# coding: utf8
bug='throttled=0x50005'
# 反引号, `可执行命令语句` ✅
state=`vcgencmd get_throttled`
# echo $state
# 有空格 OK ✅
# if [ $state == $bug ]
# 有空格 OK ✅
if [ $state == 'throttled=0x50005' ]
then
echo "❌ Error"
else
echo "✅ OK"
fi
cut
[root@www ~]# cut -d'分隔字元' -f fields <==用於有特定分隔字元
[root@www ~]# cut -c 字元區間 <==用於排列整齊的訊息
選項與參數:
-d :後面接分隔字元。與 -f 一起使用;
-f :依據 -d 的分隔字元將一段訊息分割成為數段,用 -f 取出第幾段的意思;
-c :以字元 (characters) 的單位取出固定字元區間;
範例一:將 PATH 變數取出,我要找出第五個路徑。
[root@www ~]# echo $PATH
/bin:/usr/bin:/sbin:/usr/sbin:/usr/local/bin:/usr/X11R6/bin:/usr/games:
# 1 | 2 | 3 | 4 | 5 | 6 | 7
[root@www ~]# echo $PATH | cut -d ':' -f 5
# 如同上面的數字顯示,我們是以『 : 』作為分隔,因此會出現 /usr/local/bin
# 那麼如果想要列出第 3 與第 5 呢?,就是這樣:
[root@www ~]# echo $PATH | cut -d ':' -f 3,5
範例二:將 export 輸出的訊息,取得第 12 字元以後的所有字串
[root@www ~]# export
declare -x HISTSIZE="1000"
declare -x INPUTRC="/etc/inputrc"
declare -x KDEDIR="/usr"
declare -x LANG="zh_TW.big5"
.....(其他省略).....
# 注意看,每個資料都是排列整齊的輸出!如果我們不想要『 declare -x 』時,
# 就得這麼做:
[root@www ~]# export | cut -c 12-
HISTSIZE="1000"
INPUTRC="/etc/inputrc"
KDEDIR="/usr"
LANG="zh_TW.big5"
.....(其他省略).....
# 知道怎麼回事了吧?用 -c 可以處理比較具有格式的輸出資料!
# 我們還可以指定某個範圍的值,例如第 12-20 的字元,就是 cut -c 12-20 等等!
範例三:用 last 將顯示的登入者的資訊中,僅留下使用者大名
[root@www ~]# last
root pts/1 192.168.201.101 Sat Feb 7 12:35 still logged in
root pts/1 192.168.201.101 Fri Feb 6 12:13 - 18:46 (06:33)
root pts/1 192.168.201.254 Thu Feb 5 22:37 - 23:53 (01:16)
# last 可以輸出『帳號/終端機/來源/日期時間』的資料,並且是排列整齊的
[root@www ~]# last | cut -d ' ' -f 1
# 由輸出的結果我們可以發現第一個空白分隔的欄位代表帳號,所以使用如上指令:
# 但是因為 root pts/1 之間空格有好幾個,並非僅有一個,所以,如果要找出
# pts/1 其實不能以 cut -d ' ' -f 1,2 喔!輸出的結果會不是我們想要的。
https://linux.xgqfrms.xyz/linux_basic/0320bash.htm#cut
https://linux.xgqfrms.xyz/linux_basic/1010index.htm
refs
https://www.imooc.com/video/7953
©xgqfrms 2012-2021
www.cnblogs.com/xgqfrms 发布文章使用:只允许注册用户才可以访问!
原创文章,版权所有©️xgqfrms, 禁止转载 🈲️,侵权必究⚠️!
本文首发于博客园,作者:xgqfrms,原文链接:https://www.cnblogs.com/xgqfrms/p/17456013.html
未经授权禁止转载,违者必究!

