


33、buffer_cache_3(redo的产生、LRBA、buffer cache里的等待事件)
CTAS方式(create table as)创建数据表时,使用nologging子句的情况
1、查询当前会话的sid:
SQL> select sid from v$mystat where rownum = 1;
SID
----------
929
2、查询当前会话redo的信息:
select * from v$sesstat b,v$statname c where b.STATISTIC# = c.STATISTIC# and b.SID=929 and c.NAME like '%redo%';

现在,redo的数量很少
3、CTAS方式建一张表:
SQL> create table t2 as select * from dba_objects;
Table created.
4、查询会话的redo信息:
select * from v$sesstat b,v$statname c where b.STATISTIC# = c.STATISTIC# and b.SID=929 and c.NAME like '%redo%';

涨了10M的redo
5、CTAS方式建另外一张表(加上nologging):
SQL> create table t3 as select * from dba_objects nologging;
Table created.
6、再次查询会话的redo信息:
select * from v$sesstat b,v$statname c where b.STATISTIC# = c.STATISTIC# and b.SID=929 and c.NAME like '%redo%';
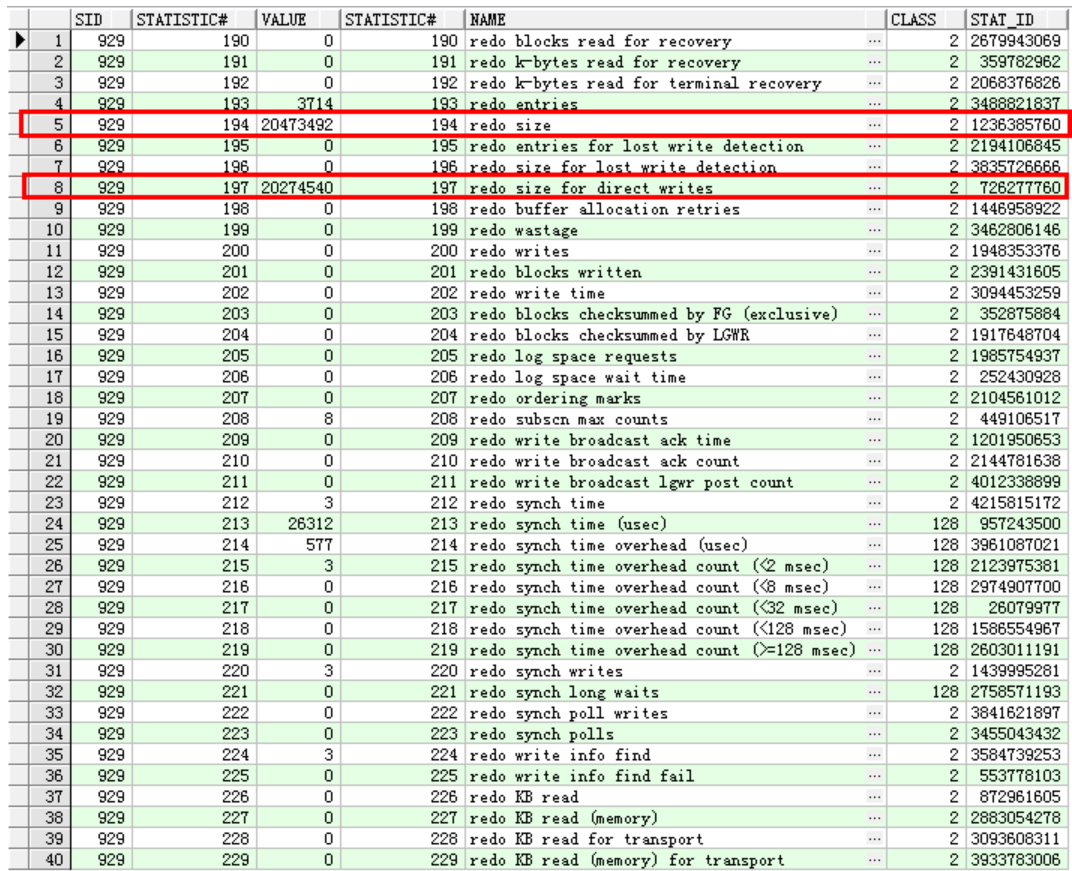
redo又涨了10M;理论上:加上nologging之后,redo应该是不涨的,但是它同样涨了10M
所以:CTAS方式同样会产生等量的日志
注意:CTAS方式,只有在非归档模式下,加nologging的时候,才不会产生redo日志
模拟一个实验,看看oracle的redo是如何产生的?
1、查看当前的redo是第几组:
select * from v$log;

当前使用第三组
切换日志:
SQL> alter system switch logfile;
System altered.

切换到第一组了
2、删除表的数据:
删除一行数据:
SQL> delete from t3 where object_id = 25;
1 row deleted.
再删除一行数据:
SQL> delete from t3 where object_id = 41;
1 row deleted.
SQL> commit;
Commit complete.
3、切换日志,然后dump出第一组日志来(或者挖掘出第一组日志):
切换日志:
SQL> alter system switch logfile;
System altered.
dump日志:
select * from v$logfile;

SQL> connect / as sysdba
Connected.
SQL> ALTER SYSTEM DUMP LOGFILE '/oradata/orcl/redo01.log';
System altered.
查看dump出来的日志:


模拟一个例子,查看日志信息(重做记录、改变向量)
SQL> alter system switch logfile;
System altered.
SQL> select GROUP#,SEQUENCE#,STATUS,FIRST_CHANGE#,NEXT_CHANGE# from v$log;
GROUP# SEQUENCE# STATUS FIRST_CHANGE# NEXT_CHANGE#
---------- ---------- ---------------- ------------- ------------
1 82 INACTIVE 1044519 1045380
2 83 ACTIVE 1045380 1045541
3 84 CURRENT 1045541 2.8147E+14
1、首先创建一张表t21
SQL> create table t21(id number,name varchar2(20));
Table created.
2、插入一行数据
SQL> insert into t21 values(1,'zyr');
1 row created.
3、删除表t21,并提交事务
SQL> delete from t21;
1 row deleted.
SQL> commit;
Commit complete.
4、切换日志
SQL> alter system switch logfile;
System altered.
SQL> select GROUP#,SEQUENCE#,STATUS,FIRST_CHANGE#,NEXT_CHANGE# from v$log;
GROUP# SEQUENCE# STATUS FIRST_CHANGE# NEXT_CHANGE#
---------- ---------- ---------------- ------------- ------------
1 85 CURRENT 1045594 2.8147E+14
2 83 ACTIVE 1045380 1045541
3 84 ACTIVE 1045541 1045594
5、dump出序列号为84的日志
SQL> select * from v$logfile;
GROUP# STATUS TYPE
---------- ------- -------
MEMBER
--------------------------------------------------------------------------------
IS_
---
3 ONLINE
/oradata/orcl/redo03.log
NO
2 ONLINE
/oradata/orcl/redo02.log
NO
1 ONLINE
/oradata/orcl/redo01.log
NO
SQL> ALTER SYSTEM DUMP LOGFILE '/oradata/orcl/redo03.log';
System altered.
查看日志内容:



redo日志文件
1、redo record:
一个 redo record 由多个 chang# 组成(可以认为:一个chang#就是修改了一个数据块)
重做记录:通常由一组改变向量组成,是一个改变向量的集合
重做记录:代表一个数据库的变更(INSERT、UPDATE、DELETE等操作),构成数据库变更的最小恢复单位
例如:一个Update的重做记录包括相应的回滚段的改变向量和相应的数据块的改变向量等
2、chang#:改变向量
改变向量:表示对数据库内某一个数据块所做的一次变更(一个改变向量对应一个数据块)
改变向量中:包含了变更的数据块的版本号、事务操作代码、变更从属数据块的地址(DBA)以及更新后的数据
例如:一个update事务包含一系列的改变向量,对于数据块的修改是一个向量,对于回滚段的修改又是一个向量
3、ALTER SYSTEM DUMP LOGFILE '/oradata/orcl/redo01.log';
dump出日志的内容
/oradata/orcl/redo01.log:日志成员地址
buffer cache
增量检查点
将控制文件dump出来,因为控制文件中记录着增量检查点的信息
SQL> alter session set events 'immediate trace name controlf level 2';
Session altered.
查看控制文件内容:


检查点信息:
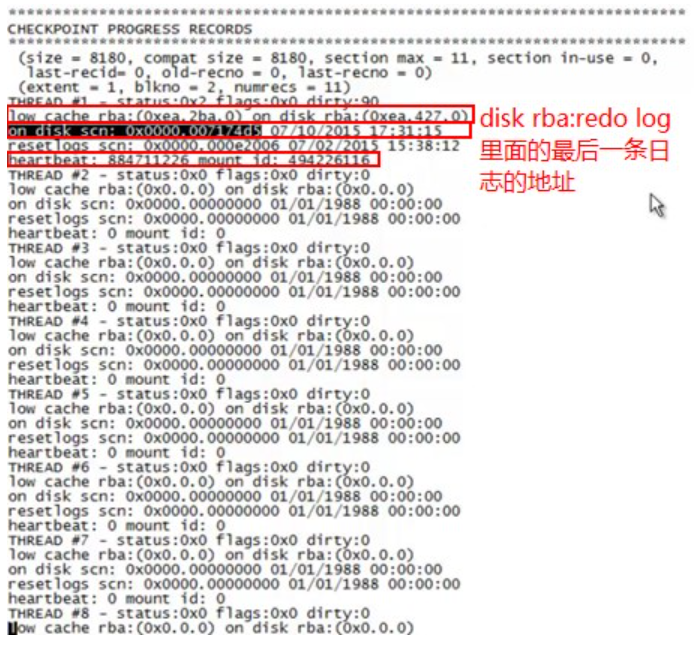
LRBA:
1、脏数据块里面有LRBA
2、控制文件里有LRBA:
1、LRBA
2、on disk rba
3、heartbeat
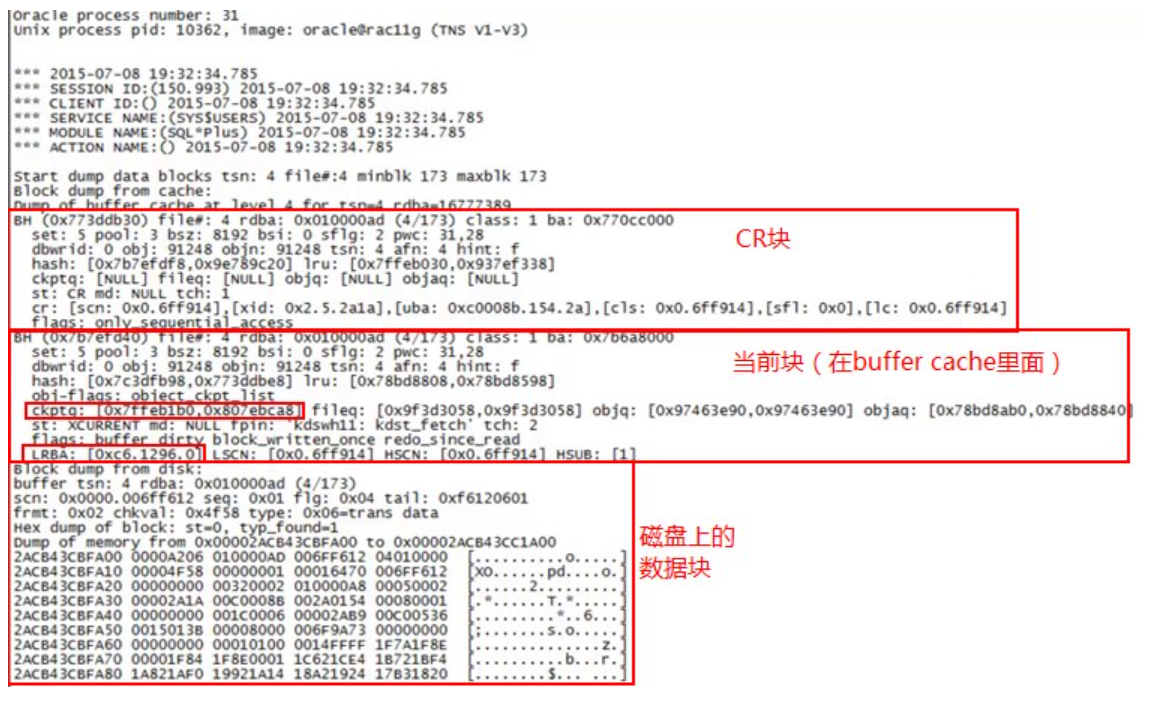
dump一个数据块出来:
SQL> alter system dump datafile 4 block 173;
System altered.
查看数据块信息:
关于检查点的一个参数
log_checkpoints_to_alert,这个参数我们一般不要设置
buffer cache里的等待事件
1、free buffer waits
有三种情况会发生这个等待事件:
1、比如想要把一个数据文件(只读的)改为读写的状态,这时候oracle会将buffer cache里面所有的数据块全部冻结,冻结以后改为invalid(无效的),这时候想要把数据从磁盘读到buffer里去,就找不到空闲的buffer,因为都已经冻结了(这种情况很少出现)
2、一个会话修改了一些数据块,脏块的链上有太多的脏块,因为修改之后的数据块变成了脏块,就要往脏块的链上挂,但是链上脏块太多,就挂不上去,这时候就会产生等待事件free buffer waits
3、把数据从磁盘读到buffer的时候,在buffer cache里面找空闲的buffer,找半天没找到,这时候会产生free buffer waits
大量的脏块产生,跑批处理的时候,加载数据的时候,会产生free buffer waits(解决办法:采用直接路径加载,不要等buffer cache)
buffer cache太小,会产生free buffer waits(解决办法:增大buffer cache的大小,增加dbwr的数量)
2、read by other session
就是说:一个会话要读一个数据块,从磁盘往buffer cache里面读,还没读完,这时候,正好另外一个会话也要读这个数据块,这时候会认为这个数据块已经在buffer cache里了,但是这个块正在往buffer cache里面读,但是还没有读完,这时候就会产生read by other session等待事件
buffer cache太小,会产生read by other session等待事件
全表扫描,也会产生read by other session等待事件
3、buffer busy waits
两种情况:
1、现在buffer cache里面有一个buffer,一个会话在修改这个buffer,在修改的那瞬间,另外一个会话上来要读它,这时候就会产生buffer busy waits
2、一个会话正在往buffer cache里读一个数据块,这时候,另外一个会话也想往buffer cache里读同一个数据块,这时候也会产生buffer busy waits
这种时候,往往意味着有热块
4、log file sync
一个会话要提交一个事务的时候,lgwr会把日志往redo log里写,就是说:一个事务提交的那一刻就开始等,等到lgwr把日志往redo log里写完的时候,给会话一个响应,提交到返回响应的这段时间就是:log file sync等待事件
redo io性能差,会产生log file sync等待事件
提交过于频繁,也会产生log file sync等待事件
5、log file parallel write
就是:lgwr把日志往redo log里写的总体时间
redo io性能差,会产生log file parallel write
6、log buffer space
就是说:很多会话,修改数据之后,产生很多的日志,但是log buffer满了,日志写不进去了,这时候就会产生log buffer space
redo 的 io 性能差,会产生log buffer space
7、log file switch (archiving needed)(经常出现的)
比如:现在有4个redo log日志,现在正在用1号,然后2、3、4号redo log都没有归档成功(可能归档日志空间满了),这时候1号redo log写满以后,要覆盖2号,但是还没有归档,就覆盖不了,就会产生log file switch (archiving needed),这时候就不能做任何的DML操作了,不然会导致数据库hang住了
8、log file switch (checkpoint incomplete)
比如:现在有4个redo log日志,现在正在用1号(current),然后2、3、4号redo log都是active,这时候1号redo log写满以后,要覆盖2号,就覆盖不了,因为active的redo log不能被覆盖,这时候就要等dbwr把脏块写完之后,redo log变为inactive才能被覆盖
DBWR性能差,会产生log file switch (checkpoint incomplete)
IO性能差,会产生log file switch (checkpoint incomplete)
解决办法:
调整IO:
增加redo log的大小
增加redo log的组数
buffer cache里的CBC latch
查询buffer cache里面latch的数量:
select a.ksppinm name, b.ksppstvl value, a.ksppdesc description
from x$ksppi a, x$ksppcv b
where a.indx = b.indx and a.ksppinm like '_db_block_hash_latches';

查询buffer cache里面链的数量:
select a.ksppinm name, b.ksppstvl value, a.ksppdesc description
from x$ksppi a, x$ksppcv b
where a.indx = b.indx and a.ksppinm like '_db_block_hash_buckets';

链和latch的关系:3倍的关系,就是三个链用一个latch
bucket数量的默认值是大于2倍的buffer数量的最小的2的幂的值的公式
模拟cbc latch争用
一个会话,建一个表,然后反复的访问这个表:
SQL> create table t21(id number,name varchar2(20));
Table created.
SQL> insert into t21 values(1,'zyr');
1 row created.
SQL> commit;
Commit complete.
SQL> select rowid,t21.* from t21;
ROWID ID NAME
------------------ ---------- --------------------
AAAVVWAAEAAAAYuAAA 1 zyr
SQL> declare
aa varchar2(100);
begin
for i in 1..1000000 loop
select name into aa from t21 where rowid='AAAVVWAAEAAAAYuAAA';
end loop;
end;
/
另外一个会话,反复的更新这个表:
SQL> declare
begin
for i in 1..20000 loop
update t21 set id=15 where rowid='AAAVVWAAEAAAAYuAAA';
commit;
end loop;
end;
/
查询会话:
select * from v$session a where a.USERNAME='U1';

查询会话相关的等待事件:
select sid ,event,total_waits,total_timeouts,time_waited_micro
from v$session_event where sid in(912,931) and event like '%buffer%';

查询数据库里目前有多少CBC latch:
select * from v$latch_children where name like '%cache buffers chains%';

......
select * from v$latch_children where name like '%cache buffers chains%'order by sleeps desc;

查询latch下面挂着的数据块:
select a.dbarfil,dbablk,class,state,tch from x$bh a where a.hladdr='00000000B9141B90' order by tch desc;

class:表示buffer header对应block的类型:
1=data block, 9=2nd level bmb,
2=sort block, 10=3rd level bmb,
3=save undo block, 11=bitmap block,
4=segment header, 12=bitmap index block,
5=save undo header, 13=unused,
6=free list, 14=undo header,
7=extent map, 15=undo block
state:
0, FREE, no valid block image
1, XCUR, a current mode block, exclusive to this instance 正在被当前的instance独占
2, SCUR, a current mode block, shared with other instances正在被当前的instance共享
3, CR, a consistent read (stale) block image 一致读
4, READ, buffer is reserved for a block being read from disk 正在从磁盘上读取块
5, MREC, a block in media recovery mode 处于介质恢复模式
6, IREC, a block in instance (crash) recovery mode处于实例恢复模式
查询数据块对应着哪个对象(生产里尽量不要做这个操作):
select * from dba_extents x where 1582 between x.block_id and x.block_id+x.blocks;

查询t21这个表被访问对应的SQL:
select * from v$sql b where b.SQL_TEXT like '%t21%';



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· [翻译] 为什么 Tracebit 用 C# 开发
· Deepseek官网太卡,教你白嫖阿里云的Deepseek-R1满血版
· 2分钟学会 DeepSeek API,竟然比官方更好用!
· .NET 使用 DeepSeek R1 开发智能 AI 客户端
· 刚刚!百度搜索“换脑”引爆AI圈,正式接入DeepSeek R1满血版