


28、undo_1_2(undo参数、undo段、事务)
关于undo的几个参数:
1、undo_management:
undo段的管理方式(AUTO)
2、undo_retention:
一个事务提交以后,事务所对应的undo数据尽量保留900秒
查询参数:
SQL> show parameter undo
NAME TYPE VALUE
------------------------------------ ----------- -----------
undo_management string AUTO -- undo段是自动管理的
undo_retention integer 900 -- 一个事务提交以后,事务所对应的undu数据,尽量保证在900秒以内不被覆盖,这个参数我们经常会改为24小时
undo_tablespace string UNDOTBS1
undo_retention:
这个参数改了以后,还不能保证它确确实实能够把一个事务提交以后,事务所对应的undo数据保留900秒;如果要确认能保留的话,还需要做几件事:
1、查询undo表空间,里面有一个参数 RETENTION 必须是:GUARANTEE
select * from dba_tablespaces where tablespace_name='UNDOTBS1';

修改retention参数:
SQL> alter tablespace UNDOTBS1 retention guarantee;
Tablespace altered.
select * from dba_tablespaces where tablespace_name='UNDOTBS1';

2、还要确认UNDOTBS1表空间,所对应的数据文件是可以自动扩展的:
select * from dba_data_files;

查询undo表空间里面的undo段(默认11个undo段):
select * from v$rollname;

随着事务越来越繁忙,undo段会自己增加(这是因为段的自动管理方式)
或者(这个信息更多一些):
select * from dba_rollback_segs

查询一个undo段里面的区的组成:
select * from dba_extents where segment_name='_SYSSMU1_3724004606$'

使用EM,看一下undo相关的一些维护:








undo表空间大小的影响因素:
1、undo数据的生成速度
2、最大select的执行时间
一个事务的开始和结束(挖掘日志分析:DDL、commit、rollback):
SQL> create user u1 identified by u1 default tablespace testtb1;
User created.
SQL> grant connect,resource,dba to u1;
Grant succeeded.
SQL> connect u1/u1
Connected.
SQL> select sid from v$mystat where rownum=1;
SID
----------
932
SQL> select group#,status from v$log;
GROUP# STATUS
---------- ----------------
1 CURRENT
2 INACTIVE
3 INACTIVE
切换一下日志(希望所有的操作都在同一个日志里面):
SQL> alter system switch logfile;
System altered.
SQL> alter system flush buffer_cache; -- 清空buffer cache里面的脏块(也就是将所有脏块写入到磁盘)
System altered.
现在系统用2号redo log日志:
SQL> select group#,status from v$log;
GROUP# STATUS
---------- ----------------
1 INACTIVE
2 CURRENT
3 INACTIVE
然后建一个表t1,插入一行数据:
SQL> create table t1(id int,name varchar2(20));
Table created.
SQL> insert into t1 values(1,'zyr');
1 row created.
SQL> commit;
Commit complete.
SQL> update t1 set id=2 where id=1;
1 row updated.
SQL> rollback;
Rollback complete.
SQL> update t1 set id=2 where id=1;
1 row updated.
SQL> create table t2(id int);
Table created.
查看日志状态:
SQL> select group#,status from v$log;
GROUP# STATUS
---------- ----------------
1 INACTIVE
2 CURRENT -- 还是2号日志
3 INACTIVE
切换日志,让刚才的这些操作都在2号日志里,方便查看:
SQL> alter system switch logfile;
System altered.
SQL> select group#,status from v$log;
GROUP# STATUS
---------- ----------------
1 INACTIVE
2 ACTIVE
3 CURRENT
挖掘日志,查看2号日志的内容:

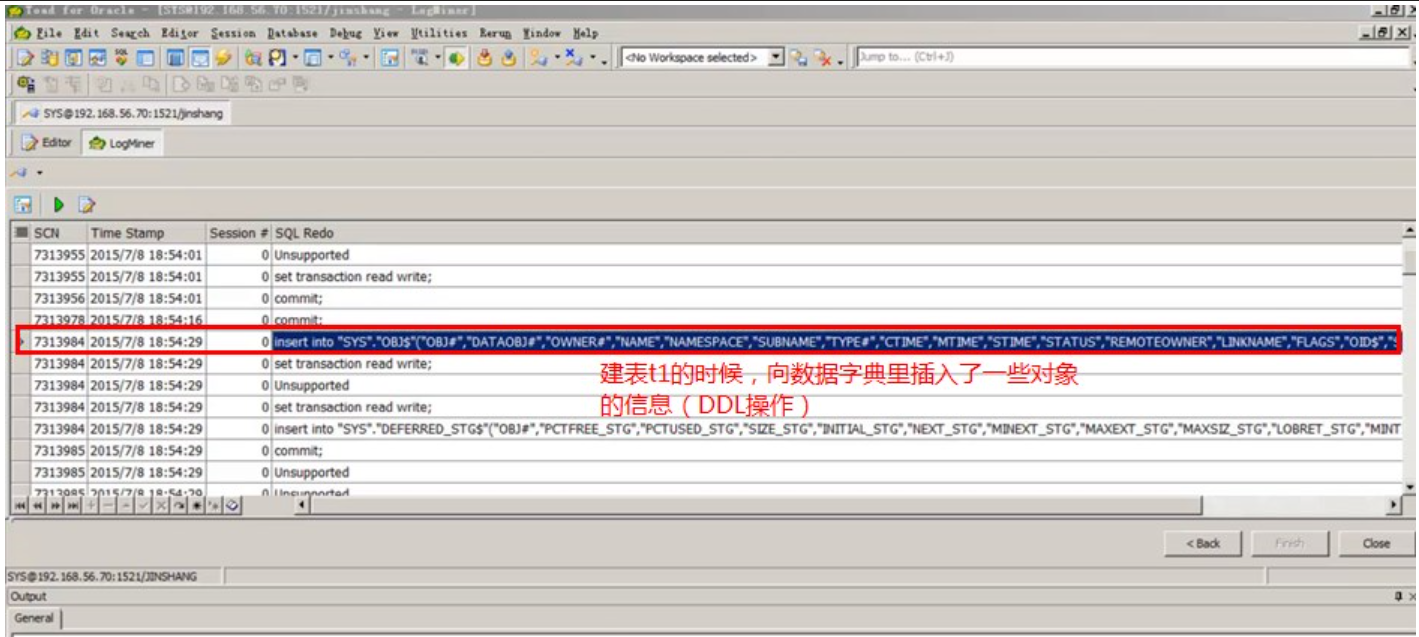




启用日志的追加功能,挖掘的信息就会多一些了
模拟一个事务(大事务)没有提交,数据库突然崩溃,数据库重新启动,select访问这个表,查看日志、以及执行时统计信息
查看日志状态:
SQL> select group#,status from v$log;
GROUP# STATUS
---------- ----------------
1 INACTIVE
2 INACTIVE
3 CURRENT
SQL> select GROUP#,BYTES/1024/1024,FIRST_CHANGE#,NEXT_CHANGE# from v$log;
GROUP# BYTES/1024/1024 FIRST_CHANGE# NEXT_CHANGE#
---------- --------------- ------------- ------------
1 50 1295995 1314696
2 50 1314696 1318831
3 50 1318831 2.8147E+14
添加日志组:
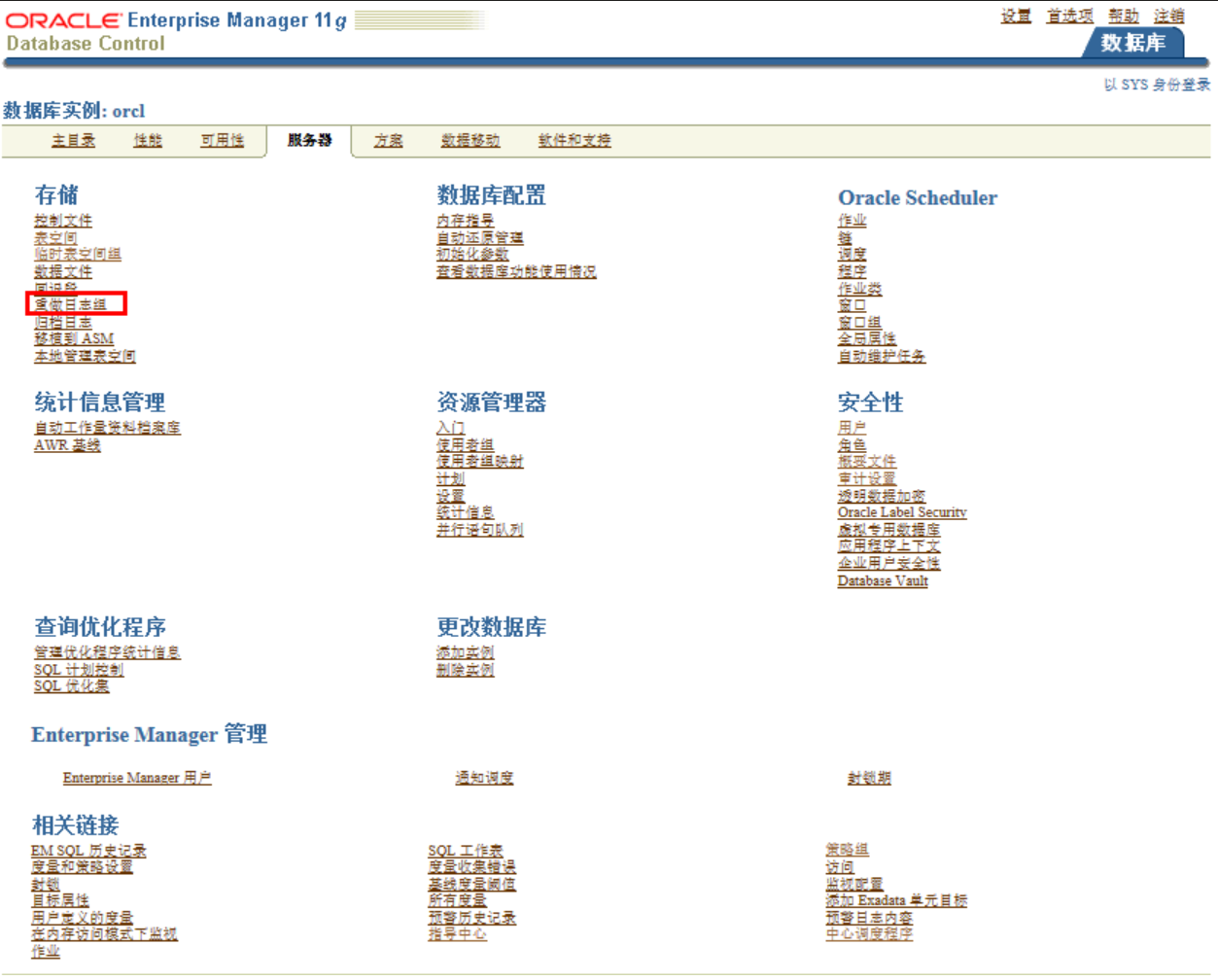
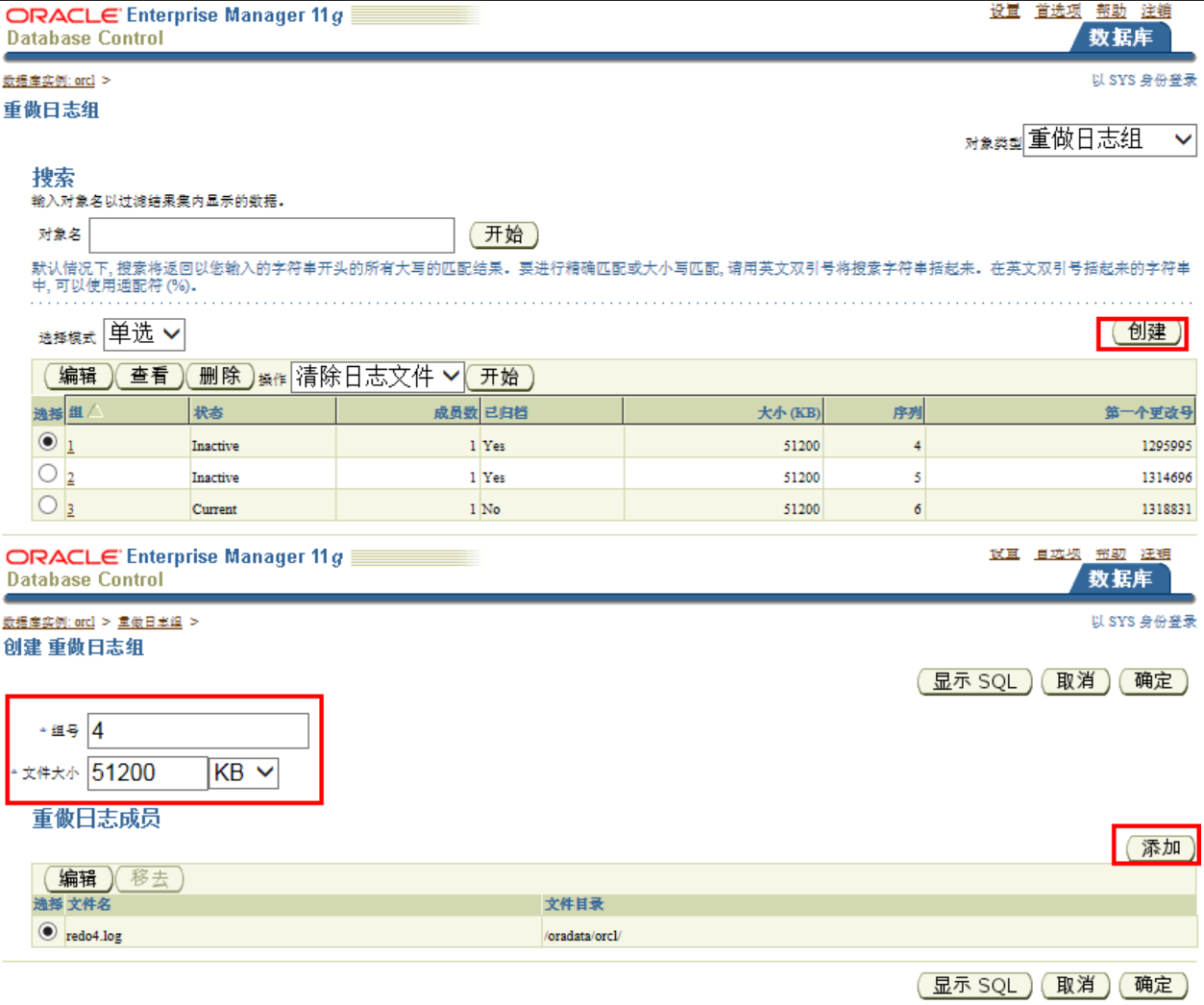

查询日志状态:
SQL> select GROUP#,BYTES/1024/1024,FIRST_CHANGE#,NEXT_CHANGE# from v$log;
GROUP# BYTES/1024/1024 FIRST_CHANGE# NEXT_CHANGE#
---------- --------------- ------------- ------------
1 50 1295995 1314696
2 50 1314696 1318831
3 50 1318831 2.8147E+14
4 100 0 0
5 100 0 0
建一个表:
SQL> show user;
USER is "U1"
SQL> create table t3 as select a.* from dba_objects a,dba_objects b where rownum<=1000000; -- 创建了t3表,有1000000行Table created.
再次查询日志状态:
SQL> select GROUP#,BYTES/1024/1024,FIRST_CHANGE#,NEXT_CHANGE# from v$log;
GROUP# BYTES/1024/1024 FIRST_CHANGE# NEXT_CHANGE#
---------- --------------- ------------- ------------
1 50 1295995 1314696
2 50 1314696 1318831
3 50 1318831 1321928
4 100 1321928 2.8147E+14 -- 现在用第四组日志了
5 100 0 0
删除t3表(相当于一个大事务,t3表有1000000行):
SQL> delete from t3;
1000000 rows deleted.
这时候,事务没有提交
查看日志状态:
SQL> select GROUP#,BYTES/1024/1024,FIRST_CHANGE#,NEXT_CHANGE# from v$log;
GROUP# BYTES/1024/1024 FIRST_CHANGE# NEXT_CHANGE#
---------- --------------- ------------- ------------
1 50 1322555 1322591
2 50 1322591 1322624
3 50 1322624 1322661
4 100 1322661 2.8147E+14
5 100 1322473 1322555
5组日志已经循环使用了一遍
SQL> select GROUP#,BYTES/1024/1024,FIRST_CHANGE#,NEXT_CHANGE# from v$log;
GROUP# BYTES/1024/1024 FIRST_CHANGE# NEXT_CHANGE#
---------- --------------- ------------- ------------
1 50 1322555 1322591
2 50 1322591 1322624
3 50 1322624 1322661
4 100 1322661 1322755
5 100 1322755 2.8147E+14
现在日志又切换到第5组了
关闭数据库(模拟一个事务未提交,数据库崩溃了):
SQL> shutdown abort;
ORACLE instance shut down.
重新启动数据库,速度会有点慢,因为要进行大量的前滚和回滚(之前数据库有事务未提交,数据库崩溃了):
SQL> startup
ORACLE instance started.
Total System Global Area 1603411968 bytes
Fixed Size 2253664 bytes
Variable Size 1375734944 bytes
Database Buffers 218103808 bytes
Redo Buffers 7319552 bytes
Database mounted.
Database opened.
查询日志状态:
SQL> select GROUP#,SEQUENCE#,FIRST_CHANGE#,NEXT_CHANGE#,STATUS from v$log;
GROUP# SEQUENCE# FIRST_CHANGE# NEXT_CHANGE# STATUS
---------- ---------- ------------- ------------ ----------------
1 14 1343262 1343624 INACTIVE
2 15 1343624 1343714 INACTIVE
3 16 1343714 1343766 ACTIVE
4 17 1343766 1343859 ACTIVE
5 18 1343859 2.8147E+14 CURRENT
数据库重启过程中,产生了好多日志,redo log又被循环使用了一遍
================================================================================================================
undo表空间全新认识:
1、undo段、undo extent、undo表空间最佳实践、undo表空间监控(EM)
2、rollback、commit
3、事务的开始和结束、挖掘日志分析
DDL、commit、rollback
4、模拟一个事务没有提交,数据库突然崩溃,数据库重新启动,select访问这个表,查看日志、以及执行时统计信息
5、dump undo段头块分析事务表、dump表的数据库分析事务槽(整个操作在一个事务模拟中分析)
6、分析xid、v$transaction
7、模拟ORA-01555错误及MOS解决方案
8、模拟insert、update、delete对资源的消耗

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步